I Built a Custom Returns Management System
How I built a custom returns management system that scans the box, credits only what arrived, and restocks the rest, replacing a returns SaaS.
By Mike Hodgen
Why Returns Are the Workflow Software Always Gets Wrong
Returns look like the simplest part of running my DTC fashion brand in San Diego. A customer ships something back, you credit them, you put it back on the shelf. On a slide, it's three boxes and two arrows.
 Intent vs Reality: What the label says vs what's in the box
Intent vs Reality: What the label says vs what's in the box
In a warehouse, it's chaos in a cardboard box.
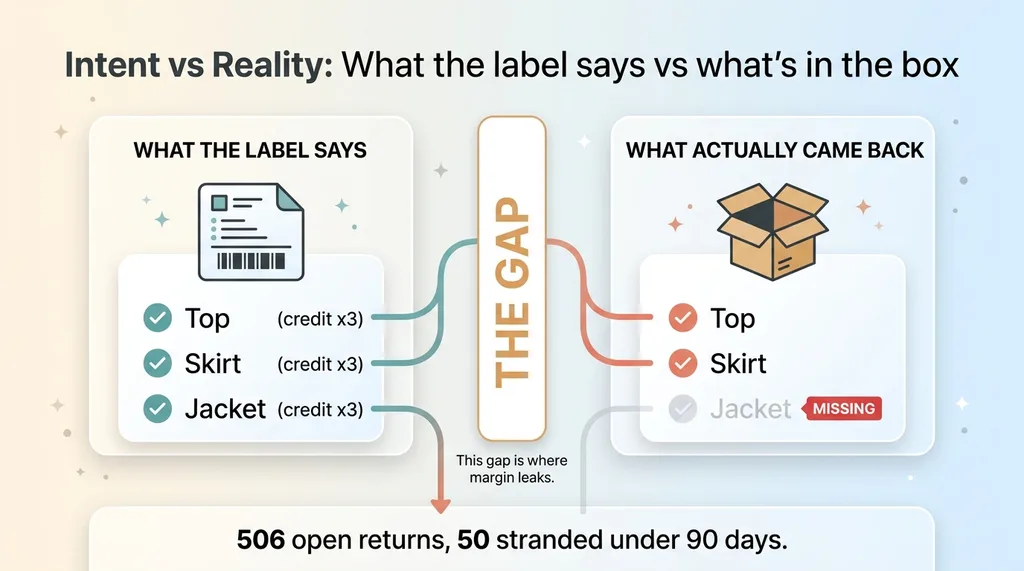
Here's the lie that every returns SaaS tells, and I mean every one I've used: it assumes that what the customer said they're returning is what actually shows up in the box. It isn't. Items go missing in transit. The wrong size comes back. A customer returns two of three pieces from a set and the tool credits them for all three because the label says three.
That gap between intent and reality is where money leaks. And it's exactly why CEOs are right to be skeptical of returns software. Most tools credit based on the label, not the box.
I learned this the hard way. When I went to audit my own returns operation, I found 506 open returns sitting in the system. Of those, 50 were stranded under 90 days and could not be scanned in at all. Not "hadn't been scanned." Could not be. The software physically had no way to receive them.
That's not a customer problem. That's a software problem.
A custom returns management system has to start from physical reality, not customer intent. It has to answer one question before it does anything else: what actually came back in the box? Then it credits, restocks, and reconciles off that answer, not off the order the customer placed three weeks ago.
This article is the story of how I rebuilt mine, the specific bugs that broke it first, and how to know whether you should build your own or keep paying the SaaS bill.
The Bug That Broke Receiving: Scanning Only Searched One Table
The first failure was the worst kind. It was silent.
My receiving scan worked perfectly, as long as the return had been created inside my own in-house returns table. The operator scanned the box, the system found the return, everyone was happy.
Returns created in other tools were invisible
The problem was that not every return lived in that table.
For years we ran a returns SaaS, and we also let customers start returns directly in the storefront admin. Both of those created legitimate, real returns. But neither of them wrote to my internal table. So when an operator scanned a real box for one of those returns, the system searched the only place it knew to look, found nothing, and stopped.
That's the 50 stranded returns. Real boxes, real customers, real refunds owed, and an operator standing there scanning into a void. The 506 open returns backlog was partly this same disconnect compounding over months.
The fix was a scan-fallback. On a miss, instead of giving up, the system reaches out to the storefront, finds the open return there, and imports it on the fly. The operator never knows it happened. They scan, it works.
Why importing the whole order made it worse
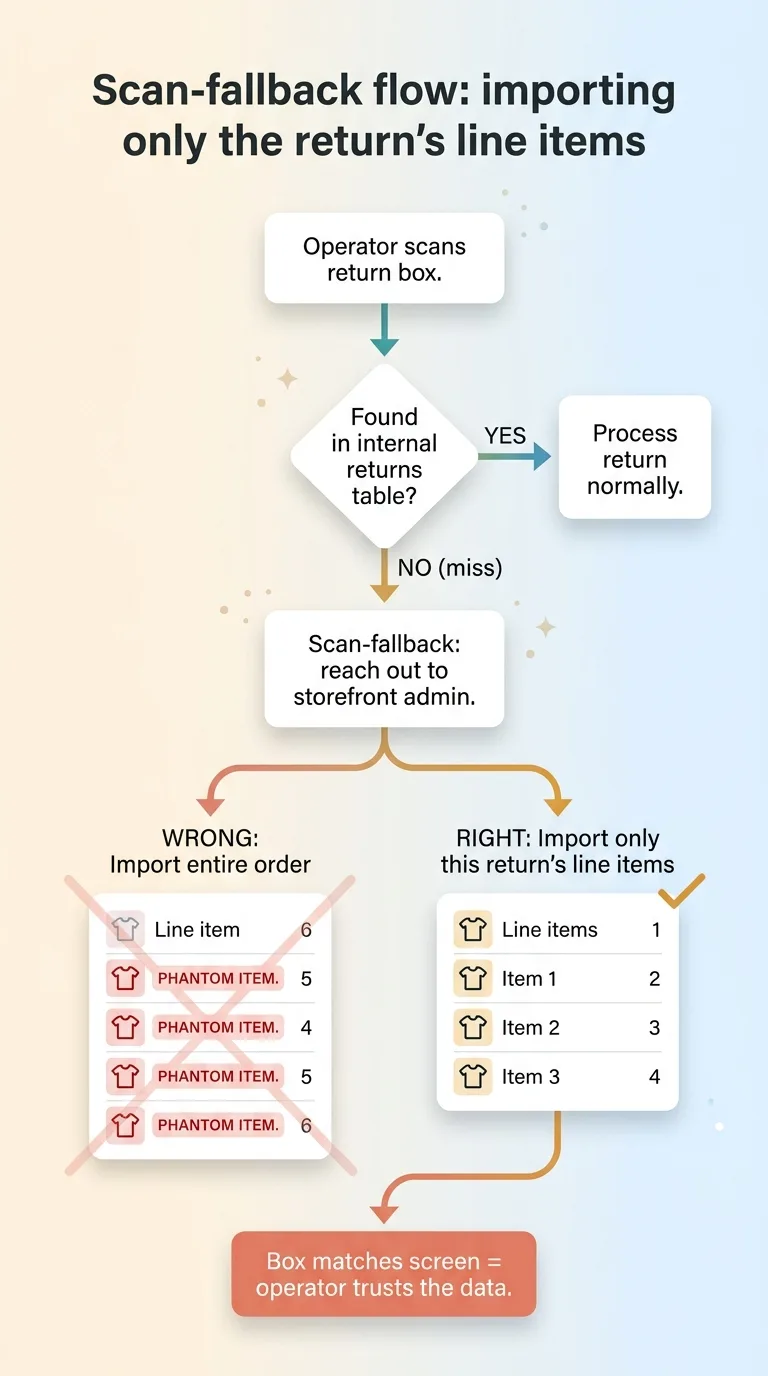
My first version of that fallback imported the entire order. That was a mistake, and it taught me something important.
 Scan-fallback flow: importing only the return's line items
Scan-fallback flow: importing only the return's line items
When you import the whole order, you surface phantom items. The system would show pieces as receivable that the customer never intended to return, things they were keeping. Now the operator is looking at a return that claims six items when the customer only sent back one.
That is exactly the kind of garbage data that destroys trust in a system. Once an operator sees one wrong line, they stop trusting all of them and go back to eyeballing everything by hand.
So I changed it to import only the return's line items. Just the pieces tied to that specific return, nothing else. The box matches the screen, and the operator believes what they see. That trust is the whole point of ecommerce returns automation. If the data is wrong, automation just produces wrong answers faster.
Credit Only What Showed Up: Received vs Missing Per Item
This is the heart of the system, and it's the part every buyer doubts the most.
Most returns tools operate at the return level. The return comes in, you accept it, the customer gets credited for everything on the return. One button.
Mine operates at the line-item level.
Marking each line item
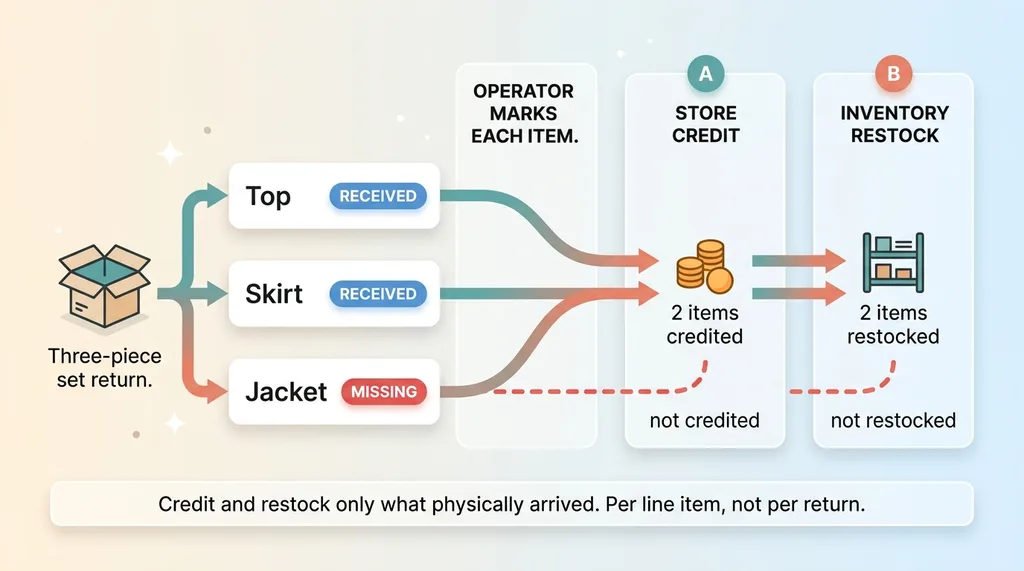
When a box arrives, the operator marks each individual item as Received or Missing. Not the return. The item.
Say a customer returns a three-piece set: a top, a skirt, and a jacket. The box arrives with the top and the skirt. The jacket isn't there. Maybe it never got packed, maybe it fell out, maybe the customer kept it. Doesn't matter why.
The operator marks the top and skirt Received, and the jacket Missing.
Credit and restock skip what never arrived
Here's what that changes. The customer gets store credit for two items, not three. And only the top and skirt get restocked back into inventory. The jacket never arrived, so it's never paid for and never added back to stock.
 Per-item Received vs Missing crediting and restocking
Per-item Received vs Missing crediting and restocking
This is the difference between software that handles messy reality and software that just trusts the label.
Per-item granularity matters because every wrongly-credited missing item is a straight loss off your margin. If your tool credits the full return on the label, you just paid a customer for a jacket you never got back. Do that a few hundred times a year and it's real money. It was real money for me before I tracked it, which is the scary part. I had no idea how much I was losing because nothing measured it.
Restocking only what arrived also keeps inventory honest. My returns table, my inventory, and my store credit all read from a single source of truth for inventory, so when an item gets marked Received and restocked, the count is right the second it happens. No nightly sync, no drift between what the shelf says and what the system says.
Issuing Store Credit Without Paying Twice
Once you decide to credit only what showed up, you've created a new risk. You're now issuing money in software. And software does things more than once.
A double-click. A network retry. An operator re-scanning a box they already processed because they weren't sure it went through. Any of those can issue store credit twice for the same return. That's not a bug that costs a few minutes. That's handing money away.
Idempotency locks on credit issuance
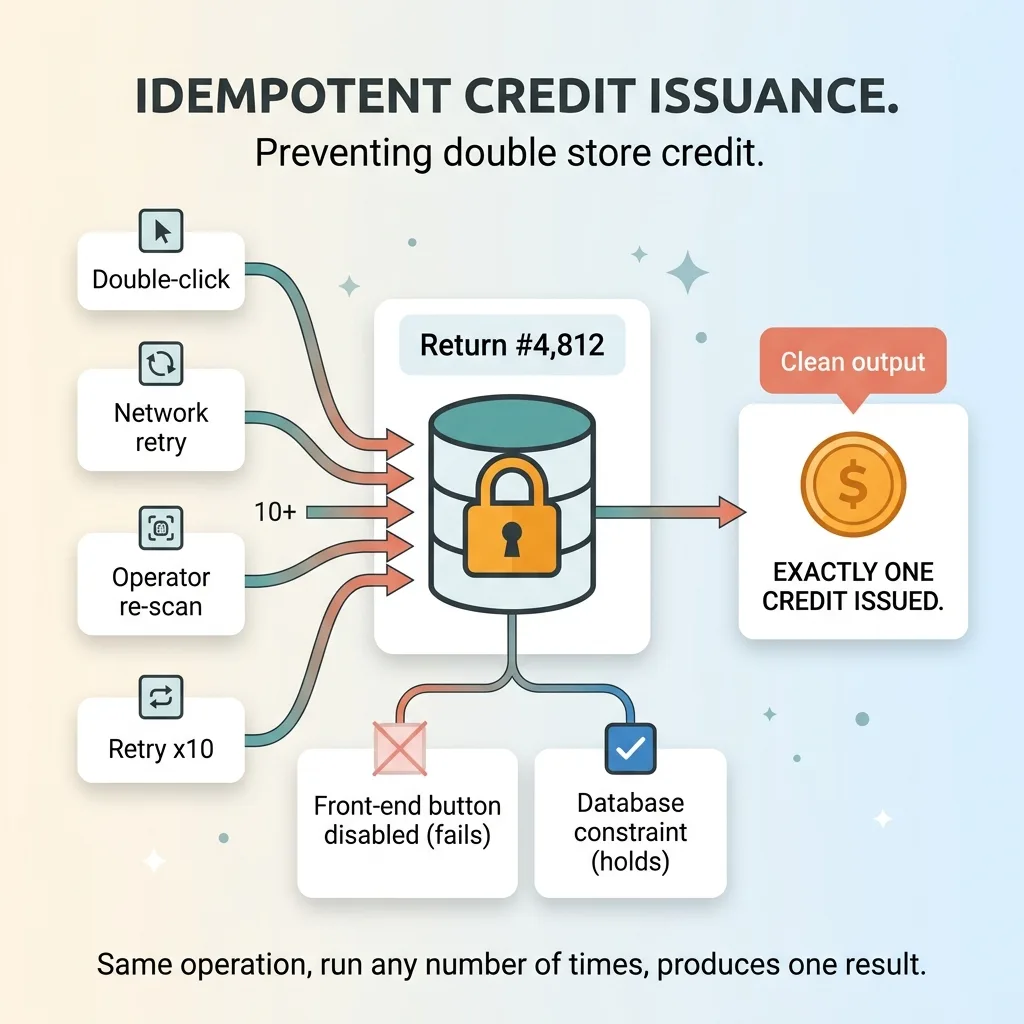
I lock credit issuance with idempotency.
 Idempotency lock preventing double store credit
Idempotency lock preventing double store credit
In plain terms, idempotency means the operation produces the same result no matter how many times it runs. Issue credit for return number 4,812 once, you get one credit. Run that exact same operation ten more times because of retries or double-clicks, you still get exactly one credit. The system recognizes it already did the job and refuses to do it again.
For the technical readers, I went deep on how I build idempotent financial writes at the database level. The short version: the safety lives in the data layer, not in a button being disabled on the front end. Front-end guards fail. Database constraints don't.
There's an honest tradeoff baked into this section that's worth naming. I made store credit the default instead of a cash refund. That keeps the revenue inside the brand instead of going back out to a card.
That is a business decision, not a technical one. The software enforces it, but I chose it. A cash refund would have been the same amount of engineering. I went with store credit because for a DTC brand, keeping that money working in the store beats sending it back to Visa. Your call might be different, and the system should bend to your call, not the vendor's default.
Return-to-Sender and Retiring Stale Returns
A returns system rots if you only ever add records and never clean them up. Two paths keep mine honest.
Netting items minus a flat fee
Sometimes an item shouldn't be accepted back at all. It's the wrong item entirely, or it's ineligible under the return policy, or it came back damaged in a way that disqualifies it.
For those, the system routes the item back to the customer. Return-to-sender. But it nets the items minus a flat fee, so the brand isn't eating shipping in both directions.
This matters because the alternative is the brand silently absorbing the cost of every wrong or ineligible item that comes through. You ship it back out of goodwill, you pay for it twice, and nobody tracks it. The flat fee makes the exception path sustainable instead of a quiet drain.
A closeout cron for the long tail
Then there's the long tail. Returns that get started and never finish. The customer changed their mind, never shipped the box, or shipped it somewhere that fell through a crack.
If you never retire those, they sit open forever and distort every metric you have. Your open return count looks terrifying. Your refund liability looks inflated. Remember those 506 open returns and 50 stranded ones I opened with? That backlog existed precisely because there was no automatic retirement. Returns piled up because nothing ever closed them out.
So I run a closeout cron, a scheduled job that automatically retires stale returns after they've sat too long. Now the open count reflects reality, not abandoned intent.
This connects to a principle I apply to every automation I build: the automation has to clean up after itself. Creating records is the easy half. The hard half, the half most tools skip, is retiring the records that no longer mean anything. A system that only ever grows is a system that eventually lies to you.
Build vs Buy: Why I Replaced the Returns SaaS
Let me be fair to the SaaS I used to pay for. A returns SaaS is genuinely fine, right up until your returns reality stops matching its assumptions.
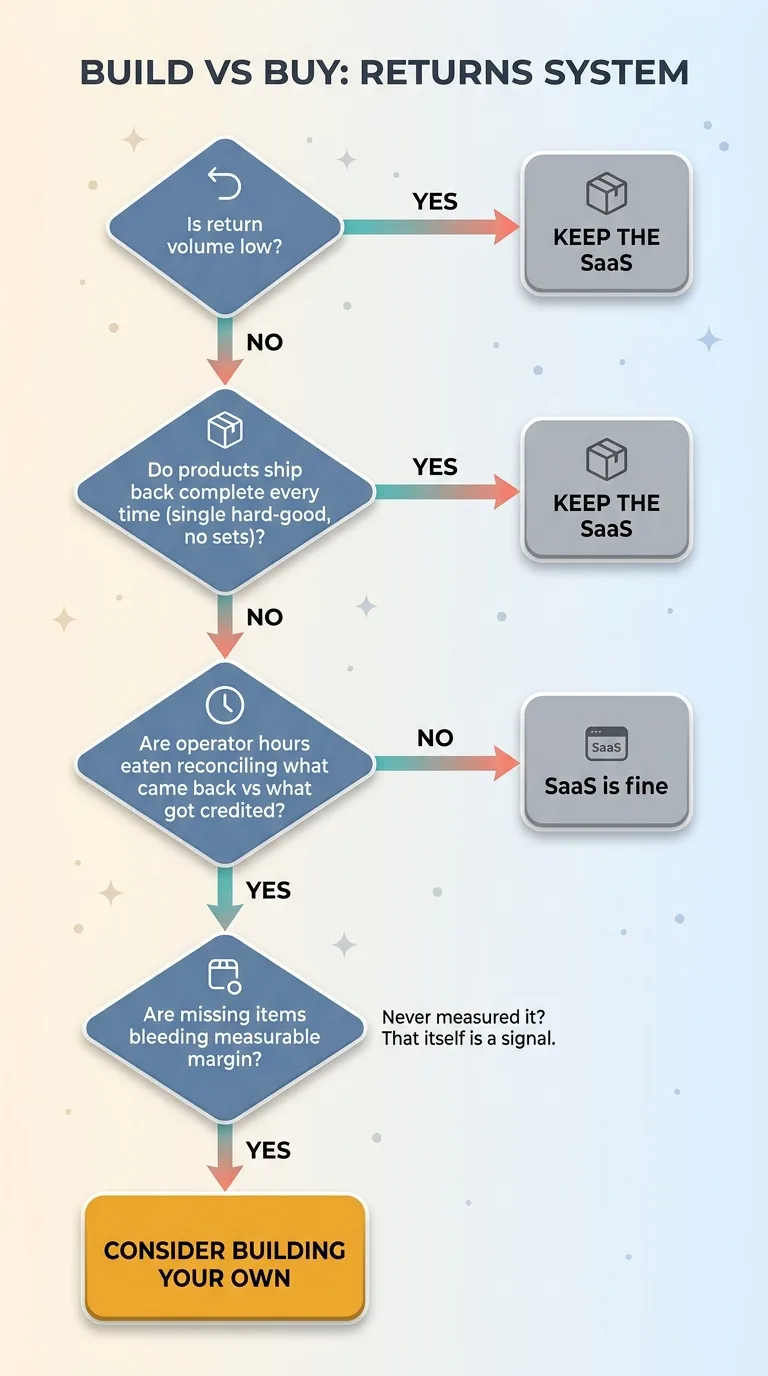 Build vs Buy decision tree for returns systems
Build vs Buy decision tree for returns systems
The reason I replaced ours wasn't cost first. It was that the box never matched the label, and the tool had no concept of partial physical receipt. It could accept a return or reject a return. It could not say "two of these three showed up, credit two, restock two, ignore the third." That single missing capability was bleeding margin on every incomplete return, and there was no setting to turn on to fix it.
Building it myself solved the deeper problem too. Now my returns table, my inventory, and my store credit all share one system of record. No syncing across vendors, no reconciliation lag, no two systems disagreeing about whether a jacket made it back. This was part of a larger effort where I replaced four e-commerce SaaS subscriptions with software I own, and returns was one of the clearest wins because the data finally lived in one place.
Now the honest part. A build does not justify itself in every case.
If your return volume is low, keep paying the SaaS. If your products ship back complete every time, like a single hard-good with no multi-item sets, the partial-receipt problem barely exists for you and the off-the-shelf tool is fine.
The inflection point is specific. You should consider building when reconciling "what came back" against "what got credited" is eating real operator hours, and when missing items are bleeding margin you can actually measure. If you've never measured that loss, that's a signal in itself. It means your current tool isn't tracking it, which usually means it's bigger than you'd guess.
What This Looks Like Inside Your Own Operation
Strip out my specific products and the pattern transfers to almost any brand with a leaky returns workflow.
Scan against reality, not intent. Credit per item, not per return. Lock the money operation so it can't run twice. Route the exceptions back instead of absorbing them. And auto-retire the long tail so your numbers stay honest.
Those five moves are the whole engine. None of them are exotic. What's exotic is a tool that actually does all five, because most stop at "accept the return and credit the label."
The returns engine also doesn't live alone. It plugs into my AI customer support system that handles returns and exchanges, so the customer-facing side and the warehouse side read from the same data. When a customer asks "where's my refund," the answer comes from what actually got received, not from what they claimed to send. The two sides stop contradicting each other.
Here's the honest bridge. Most brands have no idea how much they're losing to missing-item credits, because their tool never tracked the gap between what was credited and what came back. The loss is invisible until you measure it, and then it's uncomfortable.
If that sounds like your operation, I'll look at where your own returns workflow is leaking money. No deck. Just a look at the actual gap between what your customers say they're returning and what your warehouse actually receives.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call