Adversarial AI Review: 11 Agents Attacked My Spec
How I ran an adversarial AI review with 11 agents against a high-stakes intake spec, found 33 landmines, and fixed them before writing a line of code.
By Mike Hodgen
Why I Don't Trust a Spec That Looks Good
A few months ago I was designing an AI intake system for a law firm. The first draft looked clever. Elegant, even. It scored leads, surfaced the strong cases, gave the firm a clean ranked list of who to call first.
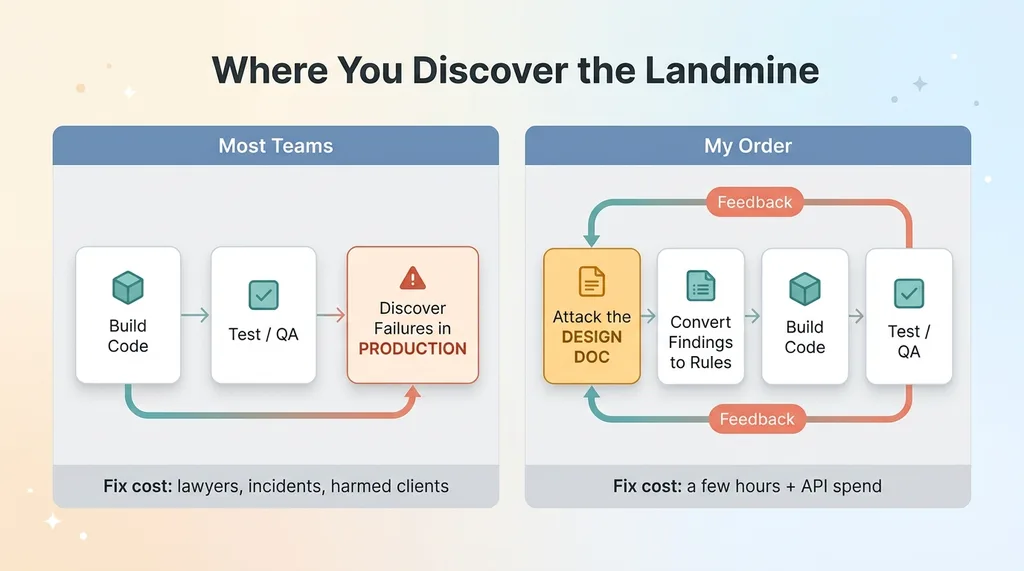 The adversarial review process: build order flipped
The adversarial review process: build order flipped
That is exactly what scared me.
In a regulated domain, a clever design hides its failure modes until a real person gets hurt. And by then the cost is irreversible. A redlined client who actually had a strong claim. A malpractice exposure. An ethics complaint that does not go away because you patched the code. You do not get a do-over with a real client and a real statute of limitations.
So before I wrote a single line of code, I put the design itself on trial.
I ran an adversarial AI review: a structured process where multiple AI agents attack a design for its worst-case failure modes before it ships. Not one model giving polite feedback. Eleven agents, each assigned to break the spec from a different angle.
They came back with 33 findings.
Some were noise. But the ones that mattered would never have shown up in QA, because they were not bugs. They were design decisions that looked completely reasonable on paper and would have quietly failed in production. The spec went from clever to deployable, and it happened before code existed, when every change was free.
This is the step most teams skip. They build first, test second, and discover the landmines in production third. I have learned to flip that order on anything regulated. Attack the design while it is still just a document.
Here is exactly how that works, what the agents found, and why I now run this on every build where a mistake can actually hurt someone.
What an Adversarial AI Review Actually Is
The panel, not the prompt
Most people think AI feedback means asking one model "is this good?" That gets you a thumbs up and some vague suggestions. Useless.
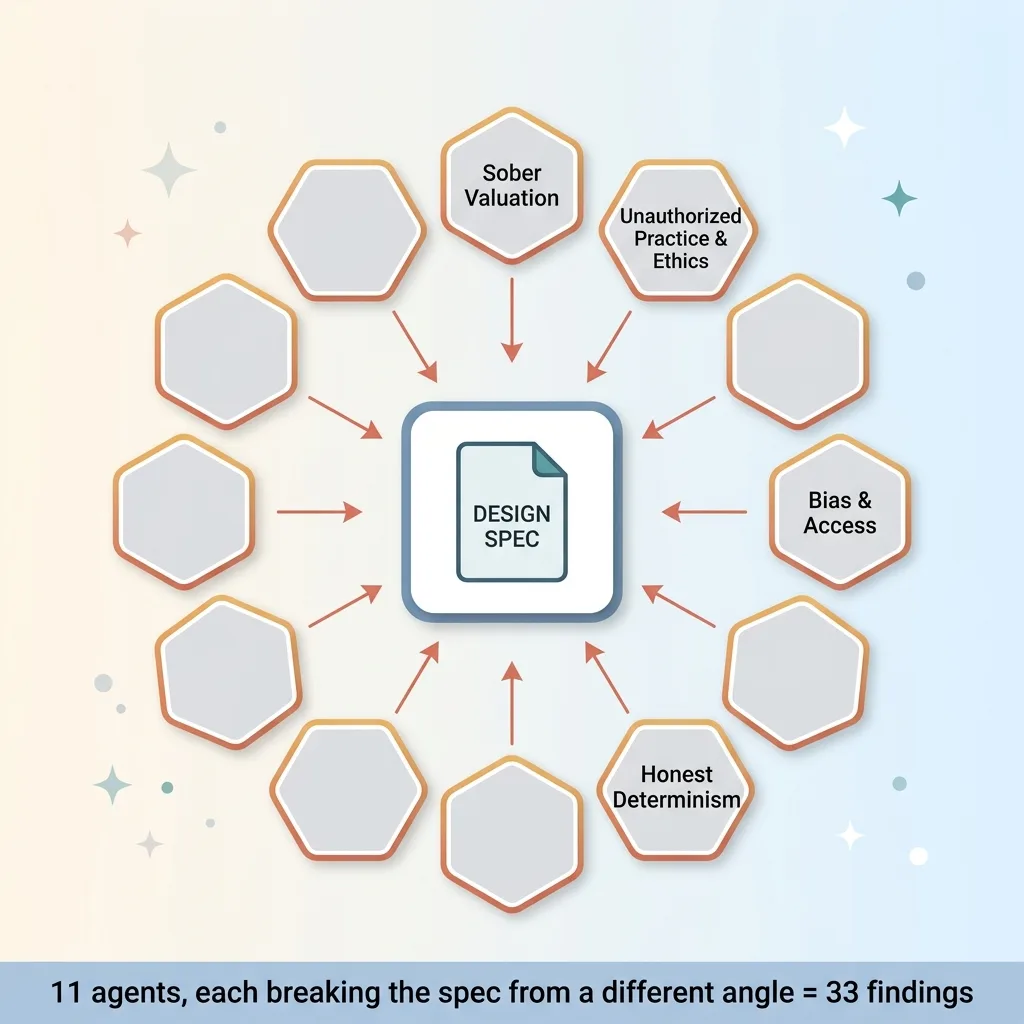 The 11-agent adversarial panel attacking a spec
The 11-agent adversarial panel attacking a spec
An adversarial review is a panel. Each agent gets a specific lens tied to the failure modes that matter in that domain. For the law firm intake system, I assigned agents to attack along lines like:
- Sober valuation, is the model overpromising on what a case is worth?
- Unauthorized practice of law and ethics, does the system cross a line it has no business crossing?
- Bias and access, who gets redlined, and on what evidence?
- Honest determinism, is the model pretending to be precise when it is actually guessing?
Each agent's job is to break the spec, not bless it. I tell them explicitly: find the worst-case outcome this design enables. Assume a real client on the other end. Show me how it fails.
This is the difference between a multi-agent design review and a single model's opinion. One model averages toward "looks fine." A panel of adversaries each pushes hard on its own narrow concern, and the sharp edges show up.
Attack the design, not the code
The other key: this happens against a written design document, before code exists.
The usual approach is build, then test, then find the landmines in production. By then the failure mode is baked into a thousand lines of code and a deployment your client is already using. Fixing it is expensive and political.
When you attack the design instead, changes are free. You are arguing with a document. Nobody has shipped anything. The whole point of putting AI into regulated industries safely is to move the risk discovery as early as possible, to the cheapest moment to fix it.
The review is a few hours and some API spend. The alternative is finding out after a client is harmed.
The 33 Findings That Mattered (Anonymized)
Four of those findings would have shipped a system that looked great in a demo and failed in the field. Here is each one as the problem, then why it was dangerous.
 The four critical findings and their dangers
The four critical findings and their dangers
Collapsing scores that quietly redline clients
The spec produced a single collapsed intake score. One number, ranked, sorted. Clean.
The problem: that number was going to redline entire categories of clients on thin signals. A weak phone connection, a vague description of an injury, a client who is not articulate under stress, all of it would compress into a low score, and a low score meant nobody called back.
This is a bias and access problem dressed up as efficiency. The firm would never see the clients it was dropping. The system would look like it was working perfectly because the only feedback it got came from the clients it chose to pursue. A silent filter that gets worse over time and leaves no fingerprints.
Forced authority citations that make hallucination worse
The spec required the model to cite legal authority on every answer. Sounds rigorous. It is the opposite.
When you force a model to produce a citation it does not actually have, it invents one. The requirement does not make the model more accurate. It makes it more confidently wrong, because now it is fabricating case names and statute numbers to satisfy a rule.
A mandatory-citation field is a hallucination factory. The design was manufacturing the exact problem it was trying to prevent.
A 'confidential' CTA that creates a duty the firm can't honor
There was a call-to-action promising a "confidential review" of the prospect's situation.
The word confidential is not marketing in a legal context. It can create an attorney-client duty. At the intake stage, before any engagement, the firm could not actually honor that duty for every person who typed into a form. The copy was writing a check the firm's ethical obligations could not cash.
Nobody on a normal QA pass catches this. It is not a bug. It is a sentence that looks like good conversion copy and is actually a liability.
Model-emitted enums that pretend to be facts
The model was emitting statute-of-limitations-style values as structured enums, as if they were reliable facts. They were guesses.
When a model hands code a clean enum, the code downstream treats it as ground truth. There is no asterisk. The system would have made routing and prioritization decisions on values the model essentially invented, and presented them with the false confidence of a database lookup.
None of these four are things you find in testing. They are design-level decisions that look completely fine until a real client is on the other side.
Turning Findings Into Binding Rules
A finding is worthless if it stays a suggestion. Every one that mattered became a hard rule baked into the spec. Here are the four fixes.
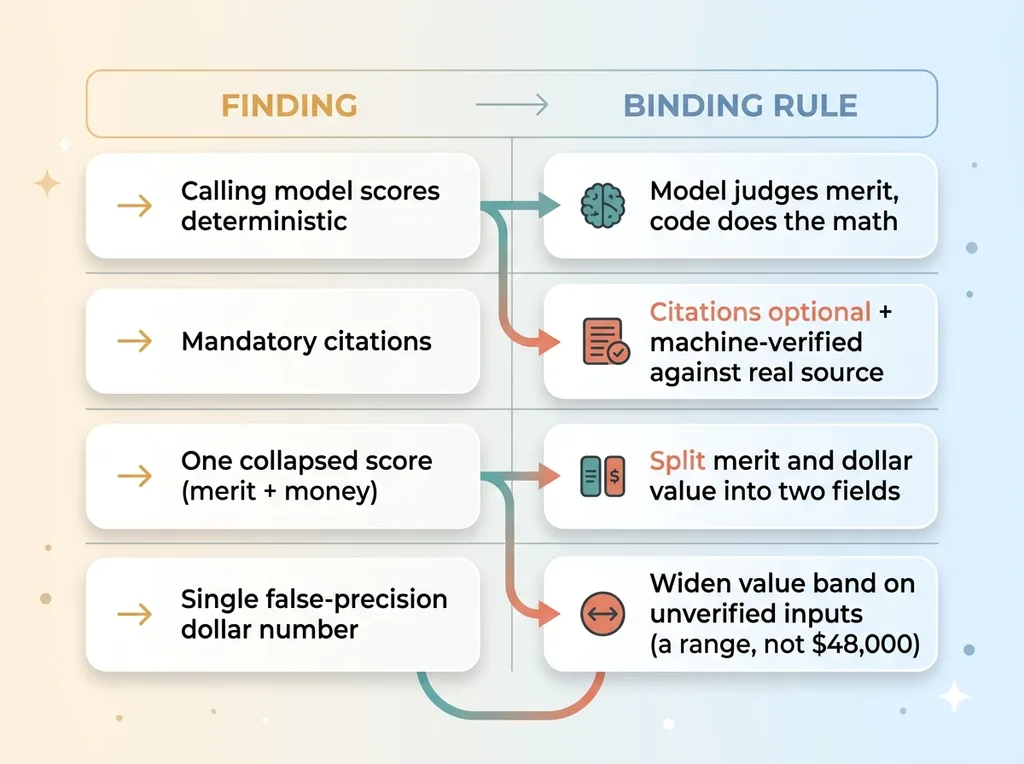 Findings converted into binding rules (problem to fix)
Findings converted into binding rules (problem to fix)
Retire 'deterministic' for the model's numbers
We stopped calling the model's scoring deterministic, because it was not. The model is a judgment engine, not a calculator.
So we split the jobs. The model judges qualitative merit. Any actual math runs in code. This is the principle I apply everywhere: let the model judge, let the code compute. The moment you ask an LLM to be your arithmetic, you have built false precision into the foundation.
Make authority optional and machine-verified
Citations went from mandatory to optional. And any citation the model does produce gets machine-verified against a real source before it is ever shown to anyone. If it does not check out, it gets dropped.
This is the same discipline as stopping AI from inventing things by locking it to verified sources. The model can suggest. It cannot assert a legal authority that does not exist in a real database.
Split merit from money
We separated the assessment of case merit from any estimate of dollar value. Two different questions, two different fields.
A strong claim with a low expected payout should not get buried. A weak claim with a big number should not get prioritized. Collapsing both into one score quietly traded justice for revenue. Splitting them forced the firm to make that tradeoff consciously instead of letting the model make it invisibly.
Widen the value band on unverified inputs
Most intake is unverified. The client said something on a form; nobody confirmed it.
So when inputs are unverified, the system widens the value band dramatically instead of emitting a single false-precision number. Not "$48,000." A range wide enough to honestly represent how little the system actually knows yet.
The throughline: every finding became a constraint. And the constraints are exactly what make the system deployable. A model with no rules is a liability. A model fenced in by rules earned through adversarial review is a tool.
Why This Is a Repeatable Process, Not a One-Off
This was not luck. It is now a standard step I run before any AI touches a regulated client.
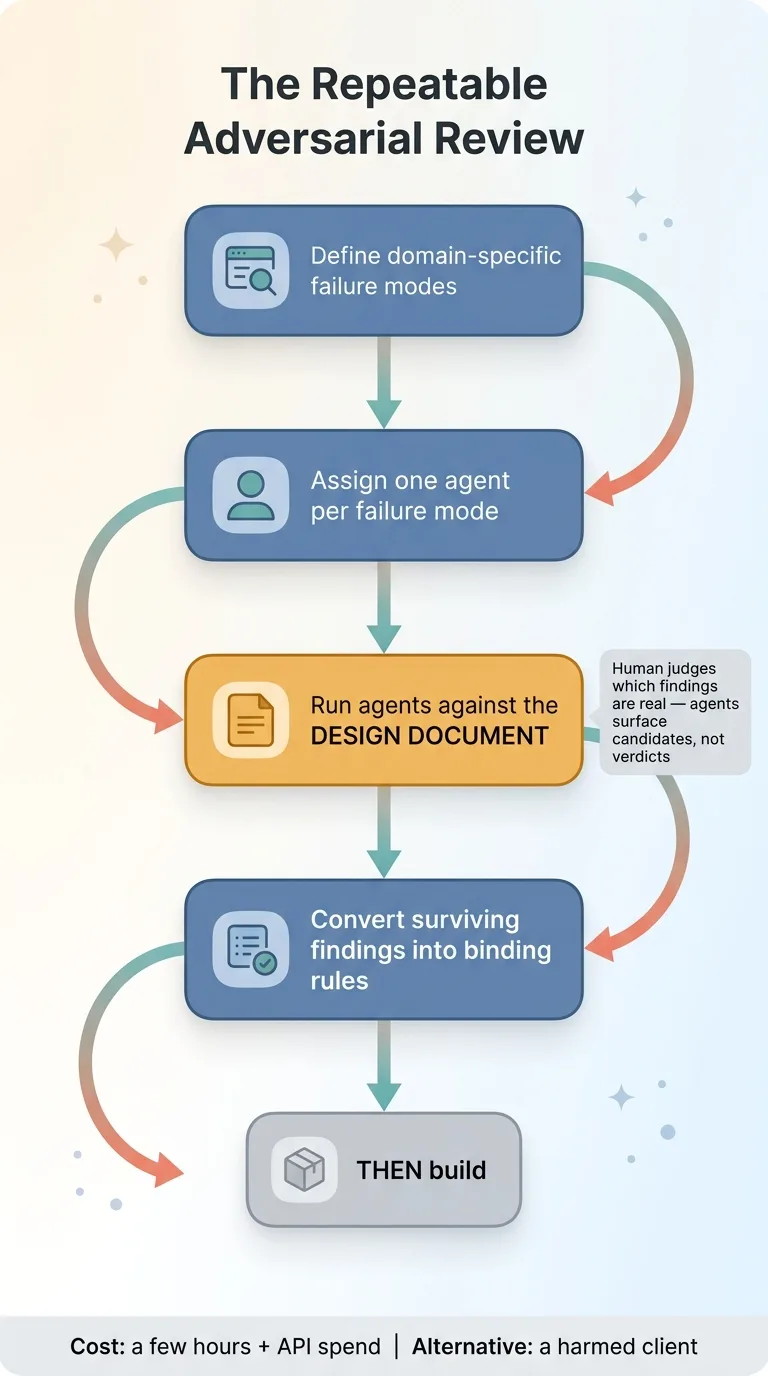 The repeatable adversarial review sequence
The repeatable adversarial review sequence
The sequence is always the same. Define the domain-specific failure modes. Assign an agent to each one. Run them against the design document. Convert the findings into binding rules. Then, and only then, build.
The cost is a few hours and a bit of API spend. The alternative is finding the landmine after a client is harmed, when fixing it means lawyers, not commits.
I want to be honest about the limits. The agents do not catch everything. Some of those 33 findings were noise, and a human still has to judge which ones matter. The "honest determinism" agent flagged things that were genuinely fine. An agent will happily generate a confident objection to a non-problem because that is what you asked it to do.
So this does not replace judgment. It feeds it. The agents surface candidates; I decide which are real.
But here is what the process reliably does that nothing else does: it finds the design-level mistakes that QA and code review never see. A code reviewer checks whether the code does what the spec says. They do not question whether the spec itself encodes a redlining bias or an ethics violation. That is not their job, and the failure mode is invisible at the code level.
This is what de-risking AI deployment actually looks like. Not a confidence score in a vendor deck. A structured attack on your own design, before the risk is real, run by something cheap enough to do every time.
What This Means If You're About to Deploy AI Somewhere It Can Hurt You
If you run a business in legal, health, finance, or compliance, you already know a single AI mistake can be unrecoverable. You are right to worry. One bad output to one real client is not a bug ticket. It is an incident.
The wrong response is to avoid AI and watch a competitor out-execute you. The other wrong response is to trust a vendor's demo, because a demo is engineered to show you the happy path and hide exactly the failure modes this review is built to expose.
The right answer is to attack the design before it goes live. AI red teaming a spec is not exotic. It is a few hours of structured adversarial pressure that turns a clever-looking design into one you can actually defend when something goes wrong.
This is how I ship every regulated build. Not as a slide. As the first real step. I define the failure modes, assign the agents, run the attack against the design document, and convert what survives into binding rules. The build comes after.
If you are staring at an AI project where a mistake is costly, the review comes before the build, not after the incident. That ordering is the whole game.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call