Deterministic AI Architecture: Let the Model Judge
Deterministic AI architecture means the model extracts facts and code computes every number. Here's the line I draw to make AI safe with money.
By Mike Hodgen
The one rule that earned its keep across five different systems
I've built five systems that touch money, and they couldn't be more different on the surface. A payment-waterfall tool that decides who gets paid in what order when there isn't enough to go around. A legal-intake scorer that ranks incoming cases. A labor-compliance engine. A returns recommender for a retail operation. And a payroll engine that has to be penny-perfect or it's a lawsuit.
Five industries. Completely different inputs. And the exact same rule kept surfacing on every single one.
The model extracts facts and makes judgments. Deterministic code computes every number, every deadline, every penalty. That's it. That's the whole pattern. The word "deterministic" belongs to the arithmetic, never to the model's opinion.
This is the single design decision that lets AI get trusted with money. Get it right and you can put an AI system in front of a CFO, an auditor, or a judge. Get it wrong and you've built a very confident liar.
I didn't arrive at this from a whitepaper. I arrived at it because an LLM once did $52,000 of arithmetic wrong, confidently, with no error message and no hesitation. It added up a set of claims, produced a clean-looking total, and the total was just wrong. Not flagged-wrong. Not maybe-wrong. Silently, plausibly wrong.
That was enough. I rebuilt the entire flow around the idea that the model never touches a number that matters.
A deterministic ai architecture isn't an academic preference. It's the boundary that separates an AI demo from a production system you can defend. The model is brilliant at reading the mess a human used to read. It is dangerous the moment you let it be the calculator. Everything below is how I draw that line, why it holds, and how you can find it in your own systems before it costs you fifty grand.
What deterministic AI architecture actually means
"Deterministic" gets thrown around a lot, so let me make it concrete. A deterministic system means the same inputs always produce the same outputs. Run it a thousand times, you get the same answer a thousand times. No probabilistic step ever touches a number that matters.
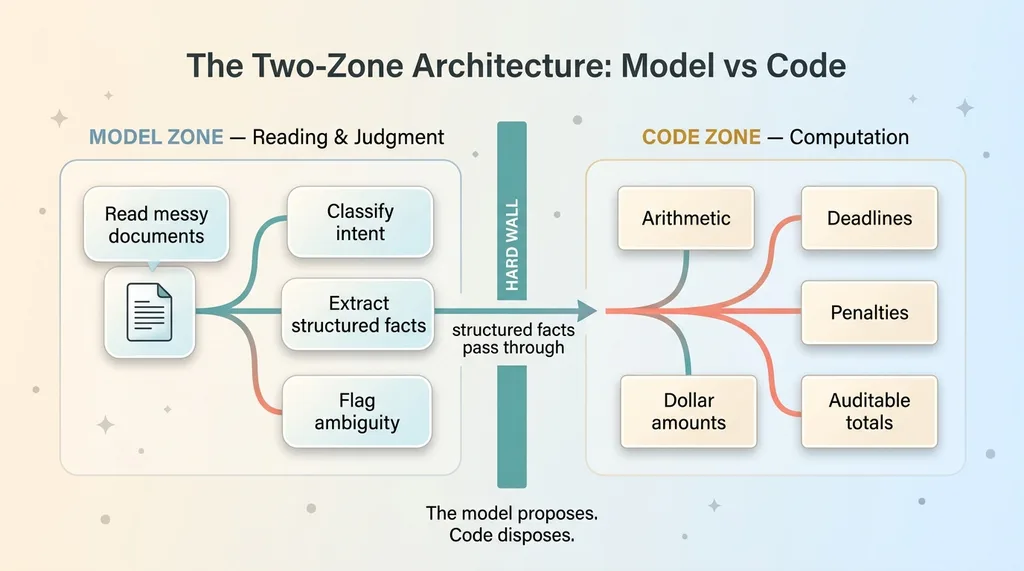 The Two-Zone Architecture: Model vs Code
The Two-Zone Architecture: Model vs Code
That's the test. Once you accept it, your architecture splits into two zones.
Where the model is allowed to operate
The model is allowed to read messy documents a human would otherwise read by hand. It can classify intent, extract structured facts from unstructured text, decide which category an edge case falls into, and flag ambiguity it isn't sure about.
This is real, valuable work. An LLM can take a pasted creditor email and tell me "this is a secured claim for $40,000, filed March 3rd, under California jurisdiction." That used to take a paralegal twenty minutes per document. The model does it in seconds and does it well.
Where it is forbidden
The model is forbidden from doing arithmetic. From computing a deadline. From calculating a penalty. From deciding a dollar amount. From being the final word on anything auditable.
Here's the contrast that makes it click. The LLM is great at reading that one creditor email and extracting the claim. It is terrible at then taking 200 of those claims, adding them up, and ordering the payout waterfall correctly. The first part is reading. The second part is math.
Code does the second part. Every time. No exceptions. The model proposes structured facts; deterministic code disposes of them into numbers, dates, and consequences. Two zones, one hard wall between them.
Why models cannot be trusted with the math
Here's the thing people misunderstand about large language models: they don't compute. They predict tokens. When you ask an LLM to add 200 numbers, it isn't running addition, it's generating the most statistically likely sequence of characters that looks like an answer.
Most of the time that's close. Sometimes it's exactly right. And sometimes it's confidently, catastrophically wrong with no error message to tell you so.
Think about what that means in the payroll engine. California wage law has daily overtime, meal premiums, double-time thresholds, all of it stacked with hard rules. "Approximately right" on a meal premium isn't a rounding issue. It's a wage claim with statutory penalties attached. The pay has to be penny-perfect, and a model that's 99% accurate is still producing wrong paychecks 1% of the time.
Or the payment waterfall. If the model misorders a single secured claim, real money goes to the wrong party. There's no "oops" in that scenario. Someone got paid who shouldn't have.
Now look at what code gives you instead. The payroll engine has 172 unit tests. I can replay it against historical results and confirm it produces the same answers it did six months ago. Same input gives the same output forever. That's not a feature, it's the entire point.
The honest limitation: even with retrieval and tool-calling, the moment you let the model be the calculator, you've introduced non-determinism into a place that has to be auditable. Tool-calling helps, but the model still decides when and how to call the tool, and that decision isn't deterministic either.
On some systems I ban the model from the money-moving logic entirely. I wrote about exactly that when I made risk management fully deterministic. When the stakes are high enough, the model doesn't get a vote.
The handoff: how the model's judgment becomes a number safely
So how does the model's judgment actually become a trustworthy number? There's a clean three-step flow, and it works in both directions depending on the system.
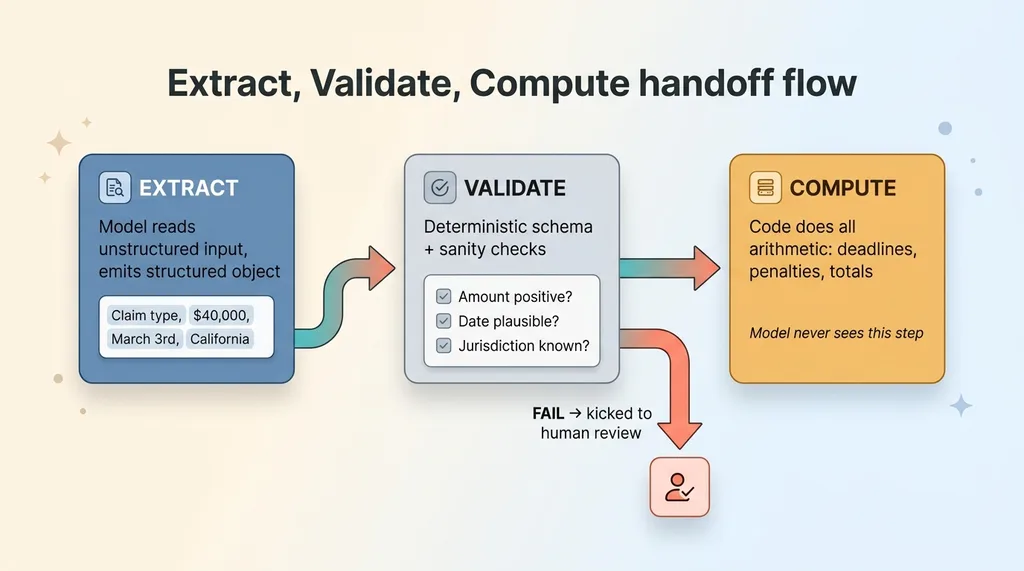
Extract, then validate, then compute
Step one: the model reads the unstructured input and emits a structured object. Claim type, amount, date, jurisdiction. Nothing more. It's not computing anything, it's translating mess into structure.
 Extract, Validate, Compute handoff flow
Extract, Validate, Compute handoff flow
Step two: a deterministic validation layer checks that object against a schema and a set of sanity rules before anything downstream touches it. Is the amount a positive number? Is the date in a plausible range? Does the jurisdiction match a known list? If the object fails validation, it gets kicked to a human, not passed forward.
Step three: code does all the arithmetic. Deadlines, penalties, ordering, totals. The model never sees this step. By the time we're computing, we're working with validated structured data, not model output.
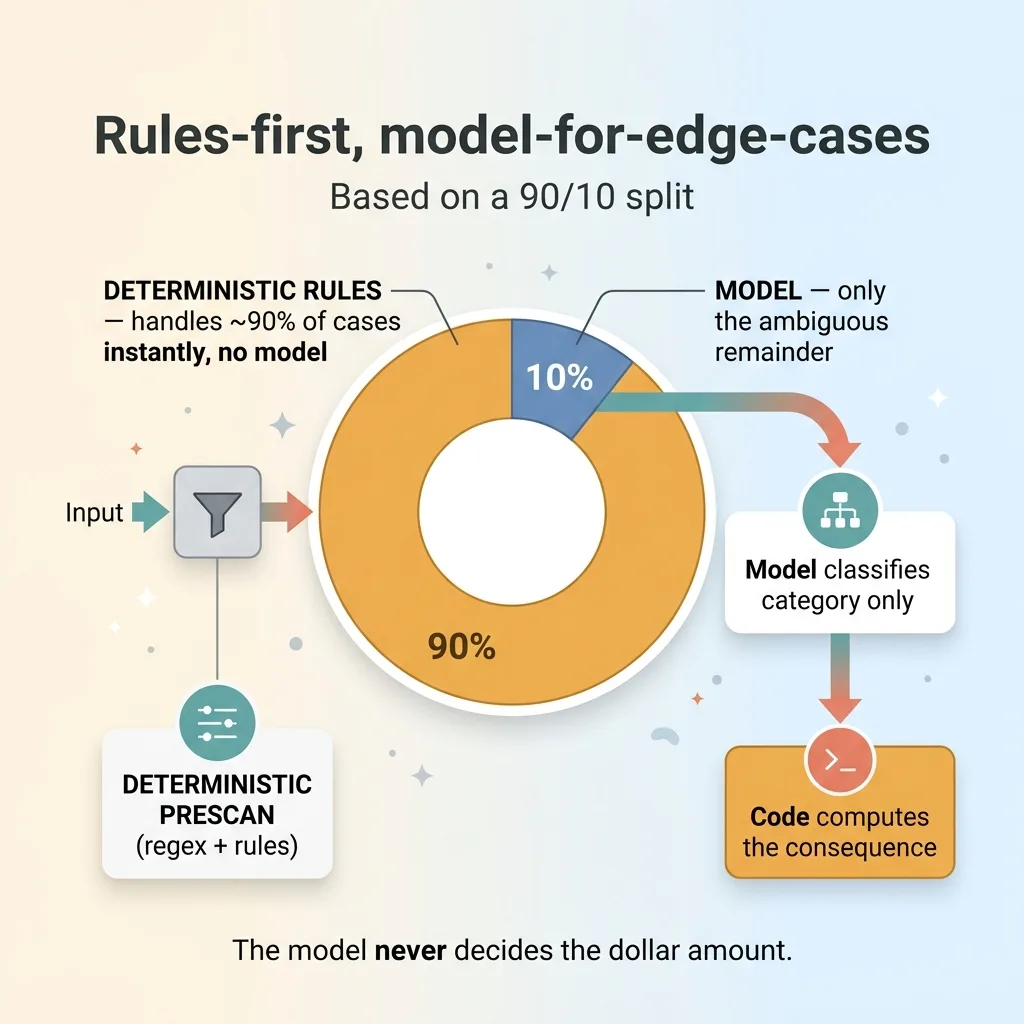
Rules first, model for the edge cases
The returns recommender and the labor-compliance engine run the inverse pattern, and it's just as important. Here, deterministic rules run FIRST and handle about 90% of cases. Most returns fit a clear policy. Most shifts fit a clear compliance category. Code resolves those instantly with no model involved at all.
 Rules-first, model-for-edge-cases (90/10 split)
Rules-first, model-for-edge-cases (90/10 split)
The LLM only gets invoked for the weird 10% the rules can't cleanly classify. And even then, the model classifies, code still computes the consequence. The model never decides the dollar amount of a refund or the size of a compliance penalty. It just says "this ambiguous case looks like category B," and the deterministic engine takes it from there.
I call the front end of this a deterministic prescan. Regex and rules screen the input first, and the model only gets the ambiguous remainder. That cuts API cost dramatically and slashes false positives, because you're not asking the model to re-decide things the rules already nailed. The model proposes, code disposes. Always in that order.
Why this is exactly what makes AI trustworthy with money
Here's the business reality. A CFO will never sign off on "the AI calculated the payroll." Ever. Say that sentence in a finance meeting and watch the room go cold.
 CFO trust contrast: AI calculated vs AI read and tested engine computed
CFO trust contrast: AI calculated vs AI read and tested engine computed
But "the AI read the timecards and classified the shifts, and a tested engine computed the pay" is a sentence a CFO can live with. That distinction is the entire difference between an experiment and a production system you can defend in an audit or a courtroom.
The waterfall tool produces a defensible payment order because every number is reproducible. I can hand someone the inputs and the code and they can re-derive the exact output. The payroll engine passes review because it's penny-perfect and replayable. When someone asks "how did you get this number," the answer is "here's the rule, here's the test, run it yourself."
None of this diminishes what the model contributes. The model eliminates the hours of human reading and data entry that used to bottleneck these systems. That's enormous value. It just never owns the math. This is the same boundary I keep coming back to, the one I wrote about in AI replaced the typing, not the strategy. The AI does the reading and the typing. The judgment about what the numbers mean, and the computation of the numbers themselves, stays where it can be trusted.
And before anything irreversible happens, the model's judgments get surfaced for a human to review. That's not a nice-to-have, it's structural. I build every AI system I ship to stop for a human at the points that matter, and I design the kill-switches into every system from the start. Trustworthy automation isn't automation without humans. It's automation that knows exactly when to ask one.
How to find the line in your own systems
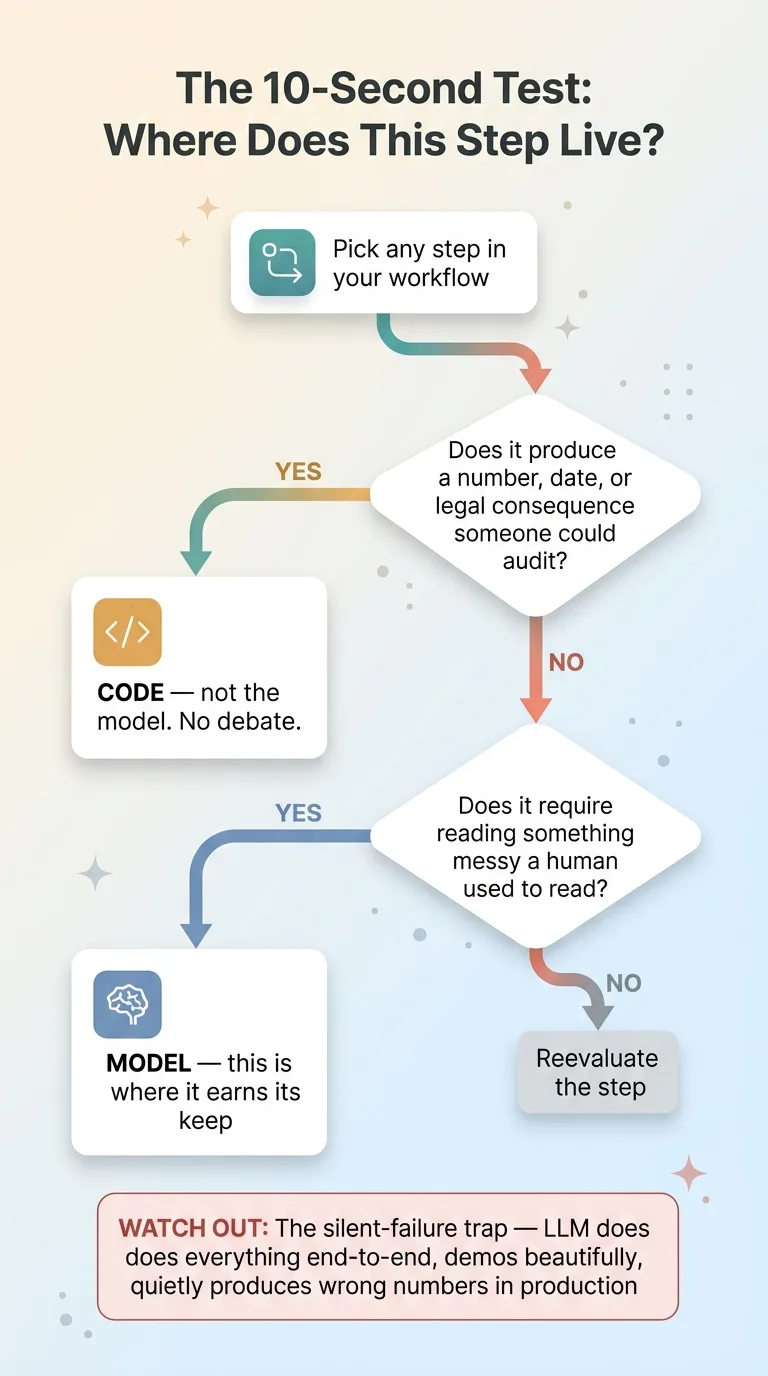
If you're evaluating an AI build, your own or a vendor's, here's the test I use. It takes about ten seconds per step.
 The ten-second test for finding the line
The ten-second test for finding the line
For any step in your workflow, ask: does this produce a number, a date, or a legal consequence that someone could audit? If yes, that step is code, not model. No debate. The moment a step generates something an auditor, a regulator, or a judge could examine, a probabilistic model has no business owning it.
Then ask the inverse: does this require reading something messy a human used to read? If yes, that's exactly where the model earns its keep. Unstructured documents, free-text fields, inconsistent formatting, the stuff that used to eat hours of staff time. Point the model there and it shines.
Watch out for the common failure mode. Plenty of vendors let the LLM do everything end-to-end because it demos beautifully. The demo runs once, produces clean output, everyone nods. Then in production it quietly generates wrong numbers and nobody notices until something breaks downstream. That's the silent-failure trap, and it's the most expensive kind of bug because there's no error to catch.
Practical advice: separate extraction from computation as two distinct layers in your codebase. Keep them physically apart. That way you can test the math independently of the model, and you can swap models without touching the arithmetic. When I rebuild a system, the computation layer barely changes even as the extraction layer evolves.
This is a design choice you make on day one, not a patch you bolt on after the first wrong number shows up. By then it's already in production, already touched real money, and already a problem.
The systems that move money should be boring on purpose
Here's the part nobody puts on a sales slide. The most exciting part of these systems is the AI. The part that lets them touch real money is the boring, tested, deterministic plumbing underneath.
That's the trade I make on purpose. The reading is smart. The math is dull. The dull part is what earns the trust.
I've now drawn this same line across payment waterfalls, payroll, compliance, intake scoring, and returns. Five industries, completely different problems, one rule that held every single time. The model extracts and judges. Code computes. When those two zones stay separate, you get a system you can put in front of a finance team, an auditor, or a courtroom and defend line by line.
So if you're building or buying an AI system that calculates anything that matters, the question isn't "how smart is the model." Smart models are a commodity now. The question is "where does the math live." Get that answer wrong and the smartest model in the world will confidently hand you a wrong number with a straight face.
If you're not sure where that line should sit in your business, that's exactly the kind of architecture decision I make before writing a line of code. It's cheaper to draw the boundary now than to discover it after the first $52,000 mistake. Let's talk about where the line should sit in your systems.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call