AI Product Safety and Liability: Building a Defensible Child App
AI product safety and liability when your app talks to customers directly. The four-layer protection pass I built: risk classification, consent logging, assumption-of-risk.
By Mike Hodgen
The Liability Nobody Warns You About When AI Talks to Customers
I built a consumer app that generates daily developmental activities for babies and toddlers. A parent opens it, and the AI suggests something to do with their kid that morning. Tummy time variations. Sensory play. Gross motor games.
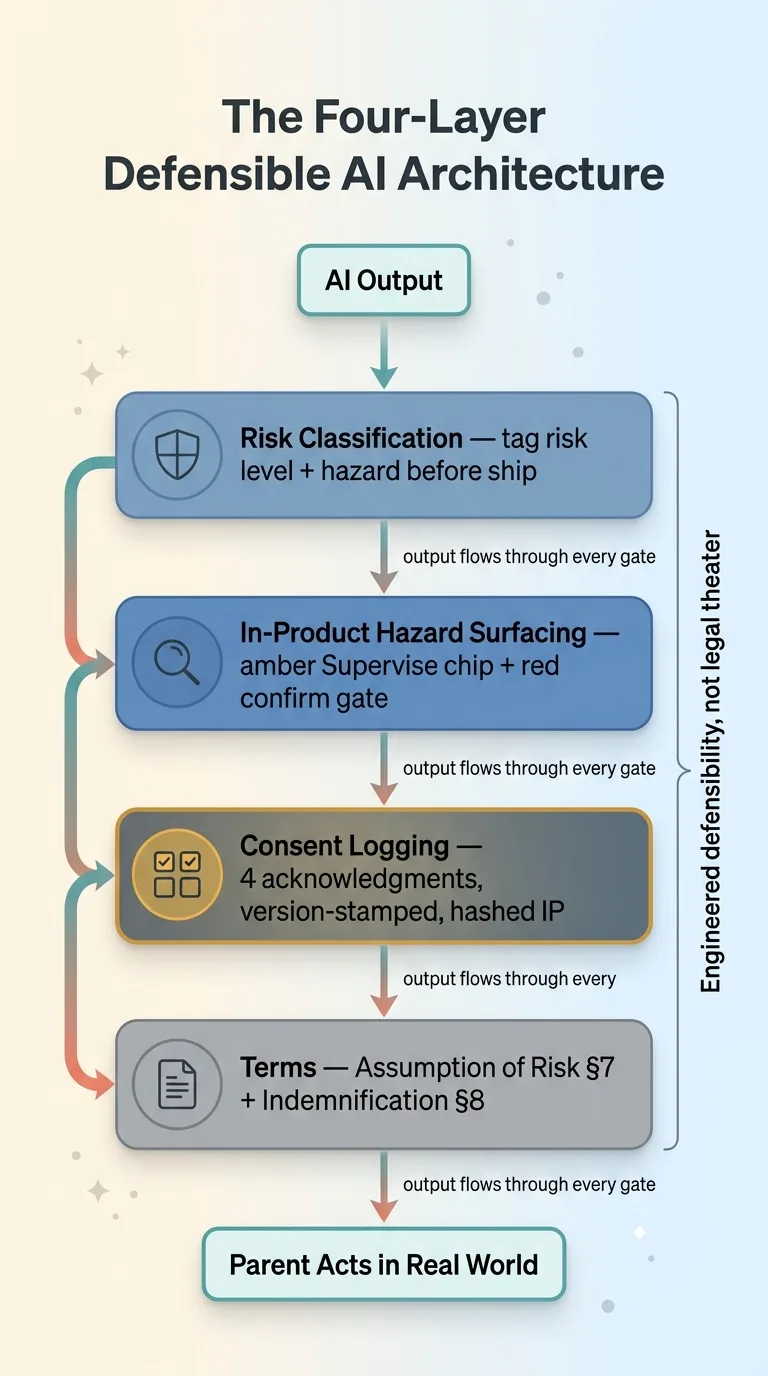 The Four-Layer Defensible AI Architecture
The Four-Layer Defensible AI Architecture
Then one day I read an activity the AI had generated and felt my stomach drop.
The instruction involved lifting the baby overhead. Harmless in theory. But the AI had written it in vague, breezy language that a sleep-deprived parent could easily misread. And it hit me: an AI could tell a parent to do something with water, with elevation, with small parts, with heat, and a real kid could get hurt. Not hypothetically. In someone's living room, that morning, because my software said so.
A "consult your doctor" disclaimer at the bottom of the page does nothing here. It's legal theater. Nobody reads it, and even if they did, it doesn't address the specific thing the AI just told them to do.
This is the part of building consumer AI that nobody blogs about. Everyone wants to talk about prompts and models and how fast you can ship. Almost nobody talks about ai product safety and liability when the AI is generating instructions that real people physically act on.
So here's the buyer doubt, stated plainly: if you let AI talk directly to your customers, are you opening yourself to liability you can't see?
Yes. Unless you engineer against it.
I've written before about the fears CEOs have about letting AI talk to customers, and this is the one that should keep you up at night more than tone or accuracy. It's the actionable-instruction risk.
So I built four layers between the AI and the parent. Each one does a different job. Together they turn invisible liability into something defensible. Here's how all four work.
Layer One: Classify Every AI Output by Risk Before It Ships
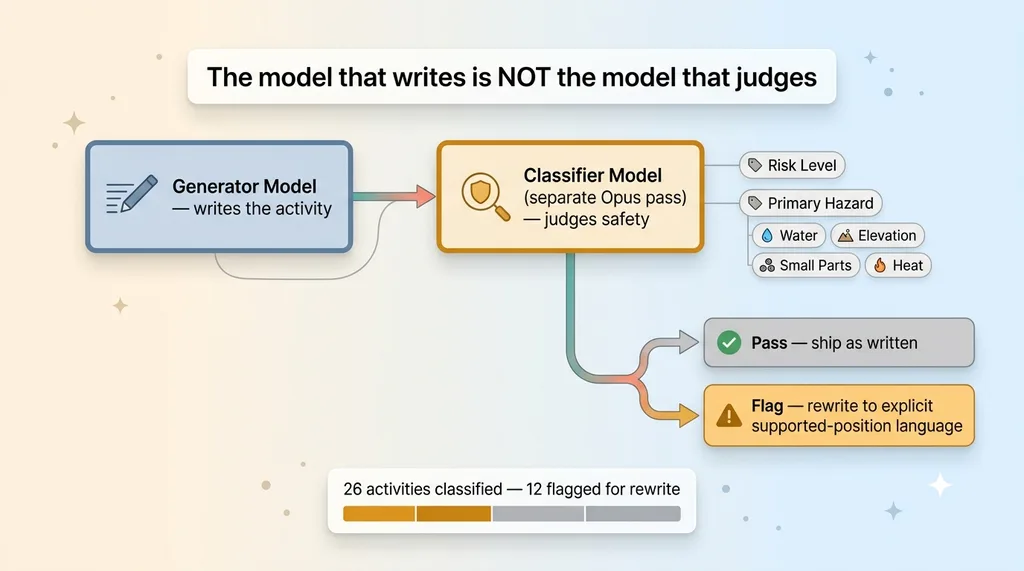 Separate Generation Model vs Separate Safety Classifier
Separate Generation Model vs Separate Safety Classifier
The classification pass
Before I touched the UI, I ran a content audit on every activity the app could surface.
I built a separate Opus pass whose only job is to classify. It reads each activity and tags two things: a risk level, and a primary hazard. The hazard categories are concrete: water, elevation, small parts, heat. Not abstract "this might be risky" hand-waving. Specific failure modes a parent needs to know about.
The result on the first pass: 26 activities classified, 12 flagged for rewrite.
What I rewrote and why
The classifier doesn't just flag. It rewrites.
A vague instruction like "hold baby up high" became explicit supported-position language with a named caution about keeping the head and neck stable and staying over a soft surface. The difference between those two sentences is the difference between a fun memory and an ER visit.
Here's the part most teams get wrong: the model that generates the content is not the model that judges its safety. Separate pass, separate job, separate prompt. If you let the same model that wrote the activity also grade its own safety, it'll mark its own homework. You want an adversarial second opinion, not a rubber stamp.
This is deterministic-adjacent thinking. I can't make an LLM perfectly deterministic, but I can wrap it in a structured classification step that behaves predictably and produces an auditable label every time.
Risk classification is the foundation everyone skips, because it's unglamorous. There's no demo. No screenshot. It's the same discipline I use when I lock the AI to the catalog so it can't embarrass a client: constrain and inspect the output before it ever reaches a human. Boring work. It's also the layer that makes the next three possible.
Layer Two: Surface the Hazard Before the Parent Acts
Classification is useless if the customer never sees it.
I've seen teams do all the safety tagging work and then bury the result in metadata nobody renders. A risk label sitting in your database does not protect anyone. The hazard has to reach the parent's eyes, and it has to reach them before they act.
So I built it into the UI at the moment of decision.
Moderate-risk activities get an amber "Supervise" chip, right on the card, before the parent reads the instructions. High-risk activities get a red confirm-before-you-proceed gate. The parent has to actively acknowledge the hazard before the full instructions even unlock.
The label shows before the action, not in fine print after it. That sequencing is the whole point.
A warning the user has to actively dismiss carries far more legal and practical weight than a passive footer disclaimer. Courts care about whether a reasonable person was actually warned. A chip they tapped through is evidence. A footer they never scrolled to is not.
This is human-in-the-loop, applied to the consumer instead of the operator. It's the same instinct behind the kill-switches I build into every system, just pointed outward. When the stakes are high, you put a human gate in the path and make someone confirm.
And here's the thing nobody expects: surfacing risk builds trust. When a parent sees that my app proactively flags the water activity as needing supervision, they trust everything else more. The warning signals that someone thought carefully about their kid. Defensive engineering and good product design turn out to be the same thing here.
Layer Three: Consent Logging That Actually Holds Up
This is the most important layer and the least understood.
The undismissable consent gate
I didn't use a single "I agree" checkbox. I used four.
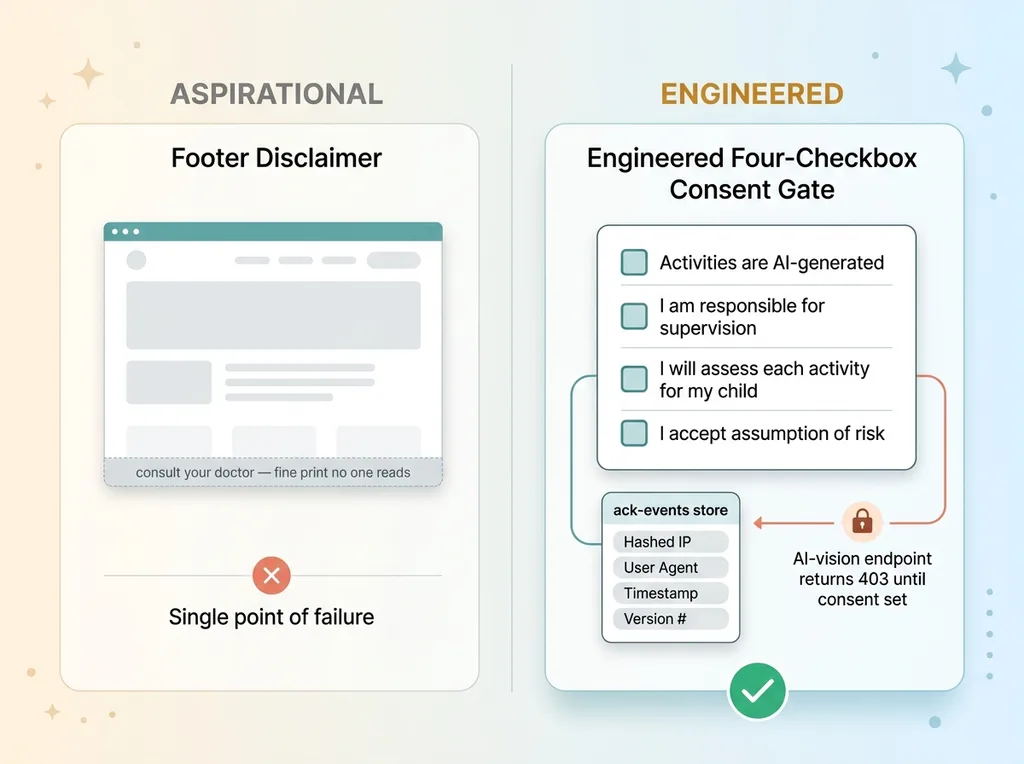 Footer Disclaimer vs Engineered Four-Checkbox Consent Gate
Footer Disclaimer vs Engineered Four-Checkbox Consent Gate
The consent gate requires the parent to acknowledge four distinct things separately: that activities are AI-generated, that they're responsible for supervision, that they'll assess each activity for their specific child, and that they accept the assumption of risk. Four checkboxes, four deliberate actions. You cannot tick one box and move on.
Why four instead of one? Because "I agree to the terms" proves almost nothing about what the person actually understood. Four specific acknowledgments prove they were confronted with four specific concepts and affirmed each.
What gets logged and why version numbers matter
Every acknowledgment event gets written to a dedicated ack-events store. Each record holds a hashed IP, the user agent, a timestamp, and a version number.
I hash the IP on purpose. I get proof-of-acknowledgment without storing raw PII I'd then have to defend, secure, and explain in a privacy audit. You'd be shocked how many teams create new liability while trying to reduce it, by hoarding personal data they don't need. Hash what you can.
The version number is the quiet hero here. When I update the acknowledgment language, the system re-prompts any user whose consent is on an old version. They have to re-acknowledge the new wording.
That means I can prove who agreed to what wording and when. Not "they accepted some terms once." The exact language, the exact person, the exact timestamp.
Then there's the enforcement piece. The AI-vision endpoint returns a 403 until the detailed acknowledgment is set. The AI literally will not function for a user who hasn't consented. There's no path through the product that skips the gate, because the gate is wired into the backend, not just the front end.
This is ai consent logging done as engineering, not as a legal checkbox someone copy-pasted from a template. The consent isn't a formality. It's a precondition the system enforces.
Layer Four: Assumption of Risk and Indemnification in the Terms
The fourth layer is the legal document that ties everything together.
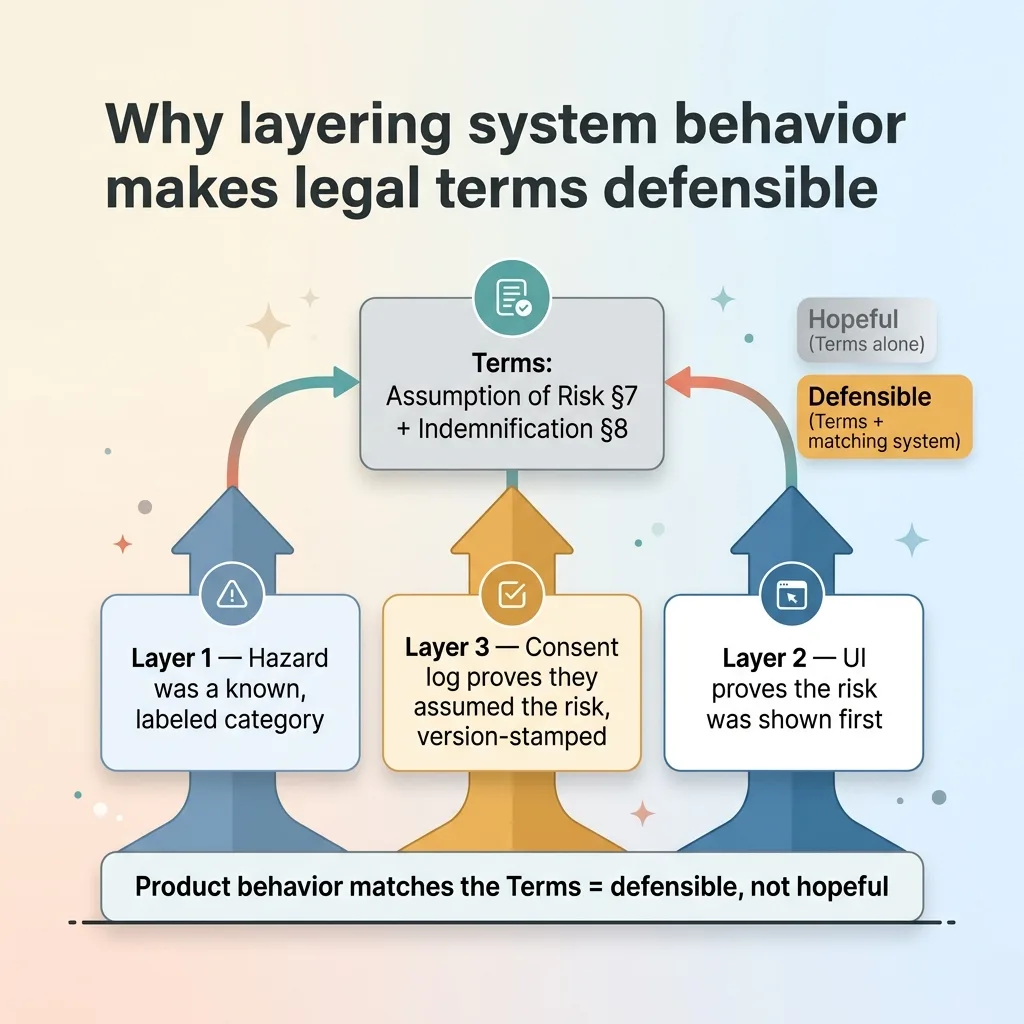 Why the Layers Make the Legal Terms Defensible
Why the Layers Make the Legal Terms Defensible
I had the Terms rewritten with enumerated assumption-of-risk language in §7 and indemnification in §8. The Privacy section was updated to describe the hashed-IP retention, so the consent-logging mechanism from Layer Three is actually disclosed and consistent with what the product does.
That consistency is the whole game.
Here's the key argument: the Terms only hold up because the product behavior matches them. Assumption-of-risk language is dramatically stronger when you can show the user actively acknowledged specific risks (Layer Three) that were surfaced in-product before the action (Layer Two) after the content was classified by hazard (Layer One).
A lawyer can write you beautiful assumption-of-risk language. But if your product never surfaces the risks, never logs the acknowledgment, and lets users act before they consent, that language is hopeful, not defensible. The other side's attorney will point at the gap between what your Terms claim and what your software actually did.
When the layers reinforce each other, the legal document stops being aspirational. The Terms say the user assumed the risk. The consent log proves they did, with version-stamped specificity. The UI proves the risk was shown to them first. The classification proves the hazard was a known, labeled category, not a surprise.
Now I'll be honest, because pretending otherwise would be the kind of overpromising I can't stand: I'm not a lawyer. Real attorney review still matters, and I had this reviewed. Don't ship assumption-of-risk language you pulled from a blog post. What the engineering does is make the legal defensible instead of hopeful. It gives your attorney something real to stand on.
Why Four Layers Beat One Big Disclaimer
One disclaimer is a single point of failure.
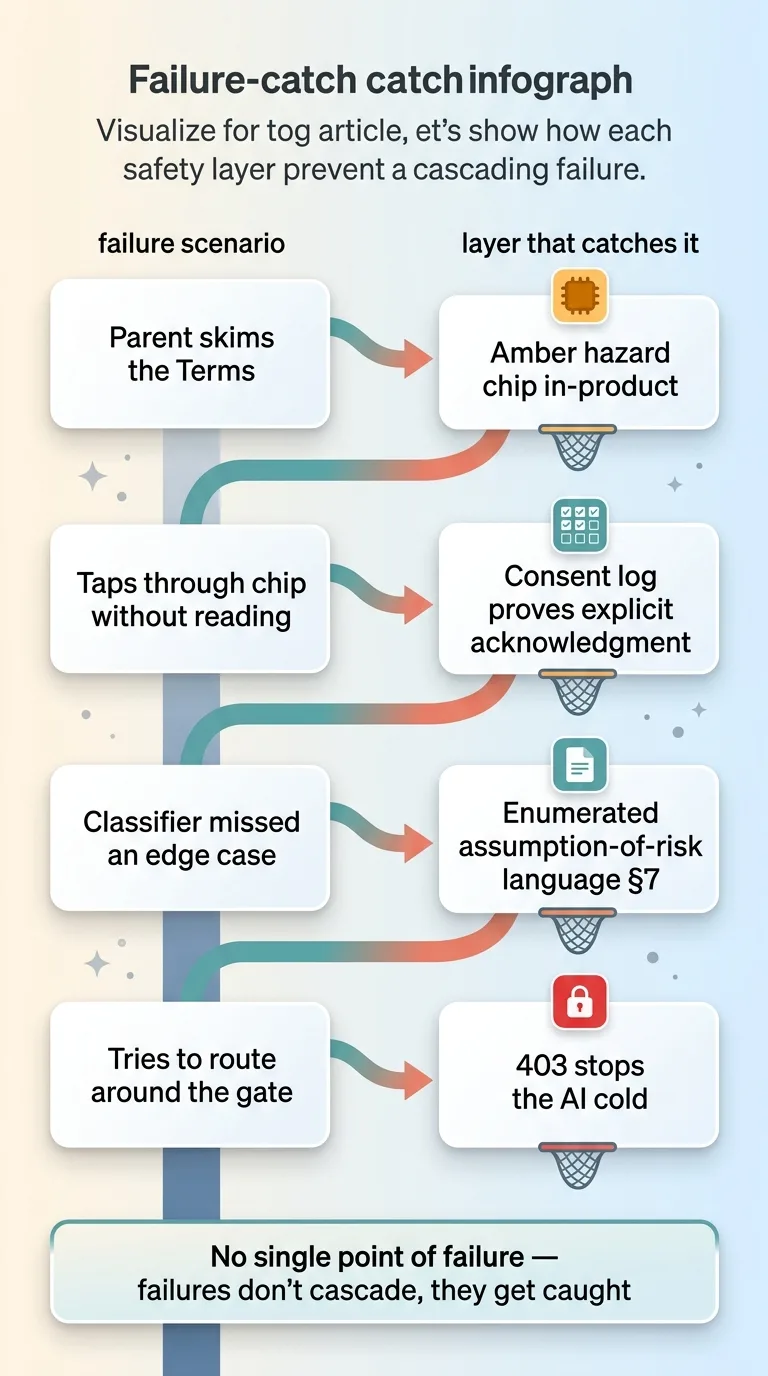 How Each Layer Catches the Failure of the Previous One
How Each Layer Catches the Failure of the Previous One
If your entire consumer ai legal risk strategy is a paragraph at the bottom of the page, then the moment a parent skims past it, you have nothing. Every protection you have depends on someone reading fine print they were never going to read.
Four layers means the failures don't cascade. They get caught.
- A parent skims the Terms? The amber hazard chip caught them in-product.
- They tap through the chip without reading? The consent log proves they were explicitly warned and acknowledged it.
- The classifier missed an edge case? The enumerated assumption of risk language covers the broader known-risk category.
- Someone tries to route around the gate? The 403 stops the AI cold until consent exists.
Each layer covers the failure mode of the one before it. That's the entire framework, and it's reusable by any CEO putting AI in front of customers.
Back to the buyer doubt. Letting AI talk to your customers does not have to mean invisible liability. It means you instrument the seam between the AI and the customer, the exact point where an output becomes an action someone takes in the real world.
The cost of all this? Maybe a few extra days on the build. The classification pass, the chips, the consent gate and logging, the Terms rewrite. A few days. Against the cost of a single incident with a hurt kid and no defensible record, that's the cheapest insurance you'll ever buy.
And this pattern isn't specific to a baby app. It applies anywhere AI gives consumers instructions they'll physically act on. Health. Finance. Fitness. Anything regulated or physical. If your AI tells someone to do something, the four layers apply.
Before You Let AI Speak to Your Customers
Most teams shipping consumer AI treat the legal surface as an afterthought. A footer template. Something the founder pastes in the night before launch and never thinks about again.
The liability is real, and it stays invisible right up until the moment it isn't. By then it's a claim, not a code change.
If you're putting AI in front of customers, recommendations, instructions, advice, anything actionable, the question isn't whether you need protection layers. You do. The real question is whether yours are engineered or aspirational.
A disclaimer is aspirational. A classification pass plus an in-product hazard gate plus version-stamped consent logging plus matching Terms is engineered. One hopes the law protects you. The other gives you a record that proves it.
I build these into the system from the start, not bolted on after an incident. The safe ai for children work I described above wasn't a separate project. It was part of building the app right.
If you're about to let AI talk directly to your customers, and you can't yet describe your own four layers, that's worth a conversation. Let's talk about your liability surface before it becomes someone's claim.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call