AI Kill Switch in Production: Where I Pull the Plug
Why I never run AI fully autonomous in production. The kill-switches and human gates I build into every system so AI can't do anything irreversible.
By Mike Hodgen
I Don't Run AI Fully Autonomous. On Purpose.
Across 29 automation modes and 15+ AI systems I've put into production, almost none of them run end-to-end without a human gate or an ai kill switch in production somewhere in the chain. That's not an accident. It's the whole design philosophy.
Here's what I've learned talking to CEOs about AI: they're not actually afraid the technology won't work. They're afraid it WILL work, and then do something irreversible at machine speed.
Send the wrong email to 5,000 customers before anyone notices. Auto-issue refunds against a buggy rule. Blow the entire month's ad budget overnight while everyone's asleep. That's the real fear, and it's a rational one.
The principle that runs through every system I build is simple: autonomy is earned, not assumed. A system starts fully restrained. It gets more freedom only after it proves, in production-grade conditions, that it deserves more freedom. Most never graduate to full autonomy, and that's the correct outcome.
I know this is unfashionable. The market right now is selling "fully autonomous agents" like the goal is to remove humans entirely. Vendors demo a system that books meetings, sends invoices, and updates your CRM with zero clicks, and it looks magical on a Zoom call.
But a demo runs once, in a controlled environment, with someone watching. Production runs thousands of times, unsupervised, against messy real-world data. Those are different worlds.
I'd rather have a system that asks permission and gets it right than a system that acts confidently and gets it wrong at scale. So let me walk you through exactly where I pull the plug, with real examples from systems running in production right now.
What a Kill-Switch Actually Means in Production
A kill-switch isn't a big red button on a wall. In real systems it takes four distinct shapes, and knowing the difference matters.
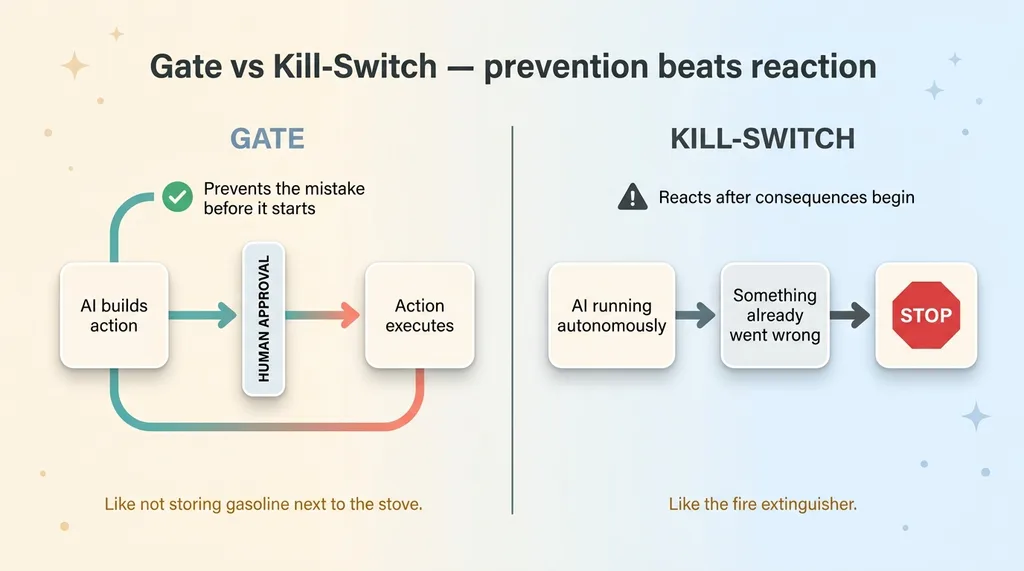 Gate vs Kill-Switch, prevention beats reaction
Gate vs Kill-Switch, prevention beats reaction
The four shapes a restraint takes
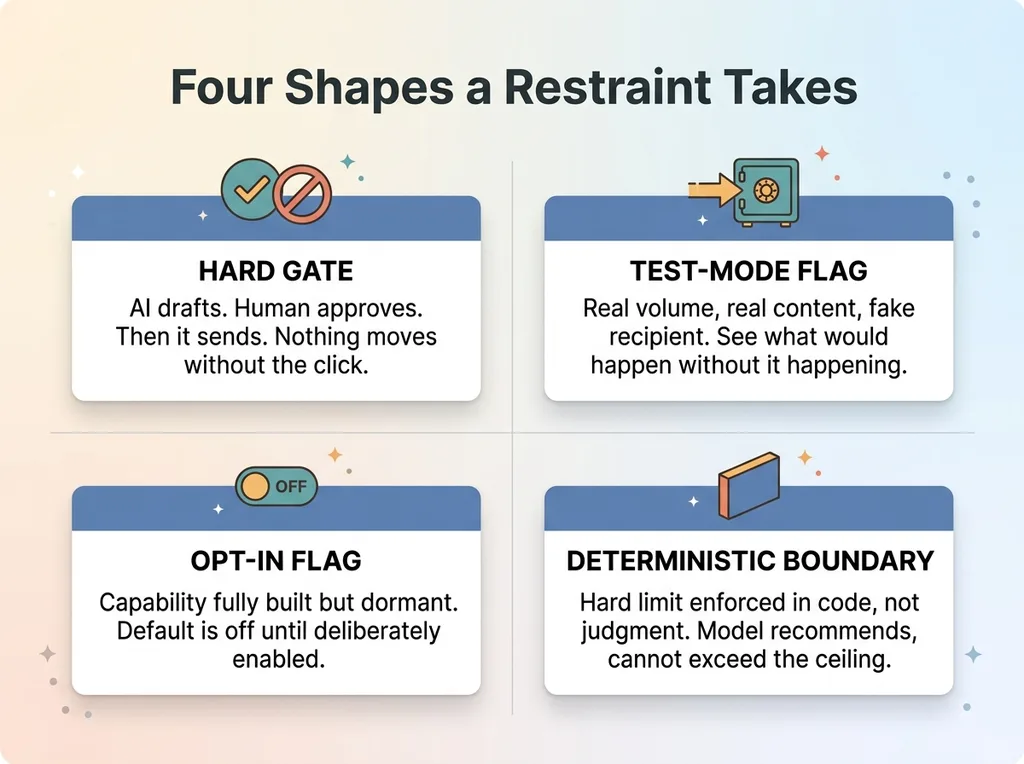
1. A hard gate. The system builds the action but will not execute it until a human gives explicit approval. The AI drafts, a person signs off, then it sends. Nothing moves without that click.
 The four shapes of a restraint (gate, test-mode, opt-in, deterministic boundary)
The four shapes of a restraint (gate, test-mode, opt-in, deterministic boundary)
2. A test-mode flag. Instead of sending output to the real destination, the system redirects it somewhere safe. Real volume, real content, fake recipient. You see exactly what would have happened without anything actually happening.
3. An opt-in flag. A feature is fully built but sits dormant in production until someone deliberately turns it on. The capability exists. The default is off.
4. A deterministic boundary. A hard limit the AI is structurally not allowed to cross, enforced in code rather than judgment. The model can recommend, but it cannot exceed the ceiling.
Now the distinction that trips people up: a kill-switch stops a running system. A gate prevents it from starting in the first place.
Most of my systems use gates, not kill-switches. Because by the time you're reaching for the kill-switch, something has already gone wrong and you're reacting. A gate means it never got that far.
Prevention beats reaction every single time. A kill-switch is the fire extinguisher. A gate is not storing gasoline next to the stove.
When I architect ai safety controls for a business, I'm mostly designing gates. The question I'm always asking is: what's the smallest possible point at which a human can catch a mistake before it has consequences? That point is where the gate goes.
The rest of this article is four real gates and one boundary, pulled straight from production.
The Notification System That Emails Only Me
For a DTC fashion brand I run in San Diego, I built a transactional notification system. It sends order confirmations, shipping updates, and support replies. Standard customer communication, automated.
 The 'Hi null' test-mode catch, redirect prevents brand damage
The 'Hi null' test-mode catch, redirect prevents brand damage
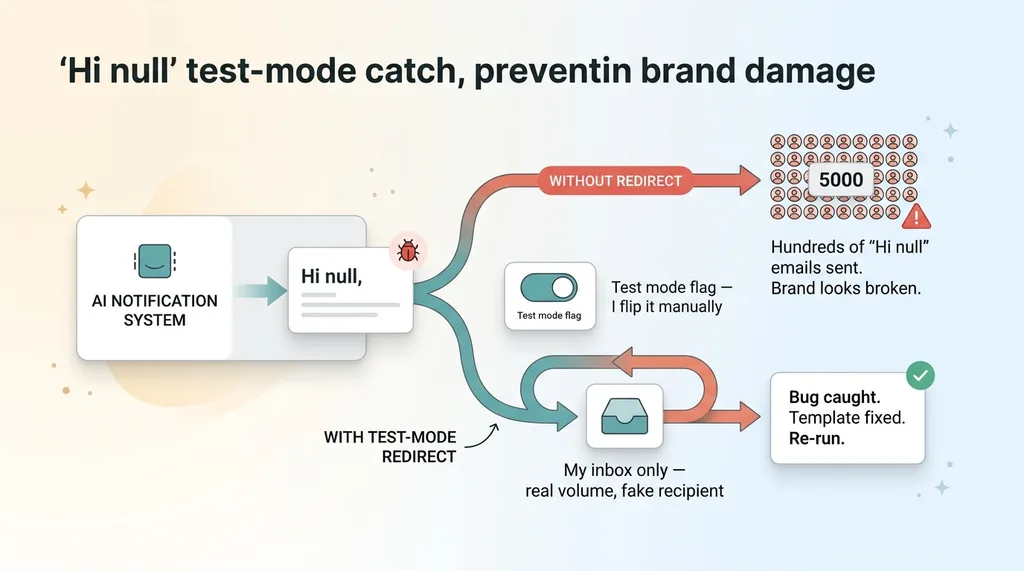
Before it went live, it sat in a hard-coded test mode that redirected every single outbound customer email to my own inbox. Not a sample. Not a percentage. Every one.
Nothing reached a real customer until I personally flipped the flag. For days, I watched the system run at full production volume, sending me what it would have sent thousands of buyers.
Here's why this matters more than any clever feature. The most common catastrophic AI failure isn't a wrong decision. It's a right decision sent to the wrong people, or sent 10,000 times.
The redirect let me watch exactly what the system would do, at real volume, before any of it left the building. I could read actual generated emails against actual order data and catch problems no test environment would surface.
And I caught one. A template bug was personalizing the greeting line. Instead of "Hi Sarah," it was rendering "Hi null" for any customer where the first-name field was empty or formatted oddly.
Without the redirect, that bug ships to every buyer with a blank name field. Hundreds of "Hi null" emails go out, and the brand looks broken and careless to the exact people who just paid money. With the redirect, I saw "Hi null" in my own inbox, fixed the template, and re-ran it before anyone external saw a thing.
That's the entire value of test mode as a kill-switch. It costs almost nothing to build. It turns a public, brand-damaging incident into a quiet afternoon fix. The system was capable of sending the moment I built it. I just didn't let it.
Features I Built and Then Deliberately Turned Off
Here's the counterintuitive part most people miss. Building the capability is cheap. Granting it autonomy is the expensive decision.
I have multiple features running in production that are fully built and deliberately turned off. Not because they don't work. Because I haven't decided they've earned the right to act on their own yet.
The returns subsystem nobody can trigger yet
For that same DTC brand, I built a complete returns and exchanges subsystem. It can evaluate a return request, check it against policy, and approve or deny it automatically.
It's gated off in production. Nobody, including the system itself, can trigger an auto-approval.
Why? Because returns touch two things I will not let AI move without a human: money and inventory. Auto-approving a return issues a refund and adjusts stock. Get the rules wrong and you're refunding fraudulent claims or marking sold inventory as available.
So the capability sits dark until the rules are proven against enough real cases that I trust the pattern. A human approves every return today. The AI just prepares the recommendation.
The e-signature feature gated as an upsell
I built an e-signature feature for document workflows. It shipped as an opt-in upsell that an account owner has to deliberately enable, not as something auto-turned-on for every account.
A document workflow that fires signature requests on its own creates real legal exposure. Wrong document, wrong recipient, wrong timing, and now you've got a contract problem. That's not a risk I auto-accept on someone's behalf.
The pattern across both: I'd rather ship a feature that's dark and turn it on slowly than ship it hot and scramble to turn it off.
Turning something on is a calm, deliberate decision. Turning something off mid-incident is panic. This is the same instinct behind building an AI that rejects its own bad work: the restraint is part of the product, not a patch you add later.
Ad Autopilot Behind an Opt-In Flag (And When I Didn't Ship It)
I built ad management automation that can analyze campaign performance and recommend changes. The autopilot mode, the one that actually adjusts budgets and pauses campaigns without asking, sits behind an opt-in flag that defaults to off.
By default, the system tells you what it would do. It doesn't do it. You have to consciously hand it the keys.
Now the harder admission, because this is where trust gets built. There were cases where the honest answer was not to ship autopilot at all.
The math was straightforward. The cost of one bad autonomous decision, burning a chunk of ad spend overnight before anyone could intervene, outweighed the convenience of not having to approve changes manually. When that's the tradeoff, manual approval wins. Every time.
I could have shipped autopilot. The capability was built and working. I chose not to flip it on, because the blast radius of a wrong call was money I couldn't get back.
This is the part that should matter to you as a buyer. Trust me not because I claim everything works. Trust me because I've chosen restraint when full capability was sitting right there, available, tempting to ship.
Rushing to autonomy is one of the most documented reasons why most AI projects fail. Teams get a working agent and immediately hand it the keys, then spend the next three months cleaning up decisions they never reviewed. I've watched it happen. I build to avoid it.
The autonomous ai risks people worry about aren't hypothetical. They're what happens when capability ships faster than judgment about whether it should.
Some Logic Should Never Touch AI
The strongest restraint isn't a gate or a kill-switch. It's keeping certain decisions out of the model entirely.
Risk limits. Refund caps. Spend ceilings. Compliance rules. None of these run as AI judgment calls in my systems. They run as deterministic code with hard limits.
Here's the reasoning. AI is probabilistic by design. Ask the same question twice and you might get slightly different answers, and that variability is often a feature. For creative work, for drafting, for analysis, that flexibility is exactly what you want.
But there are decisions where you cannot tolerate a probability distribution. A refund cap of $200 has to mean $200 every single time, not "$200 unless the model talks itself into $250 on a Tuesday."
When I built a trading system, I made risk management deterministic for exactly this reason. The AI could analyze and suggest. It could not override the position limits. Those were hardcoded, and the AI was structurally unable to cross them.
The rule of thumb I use: if a wrong answer is irreversible or expensive, it gets a hard boundary, not a prompt.
A prompt is a suggestion to a probabilistic system. A boundary is a wall. For anything touching money, legal exposure, or compliance, I want a wall that behaves identically every time, no matter how the model is feeling that day.
This is the deterministic kill-switch. The AI never even gets the chance to make the catastrophic decision, because the catastrophic decision was never delegated to it.
How I Decide What Earns Autonomy
You can apply this without me. Here's the framework I run before any system goes autonomous.
 The four stages of earning autonomy
The four stages of earning autonomy
Three questions:
-
Is the action reversible? Can I undo it cleanly, or is it permanent the moment it executes? An email sent can't be unsent. A draft saved can.
-
What's the blast radius if it's wrong? Does a mistake affect one record or ten thousand? A single internal task and a customer-wide email broadcast are not the same risk, even if the code is identical.
-
Has it run in shadow or test mode long enough to trust the pattern? Has it proven itself against real production data, not just a clean test set? Days of "Hi null" caught quietly buys a lot of confidence.
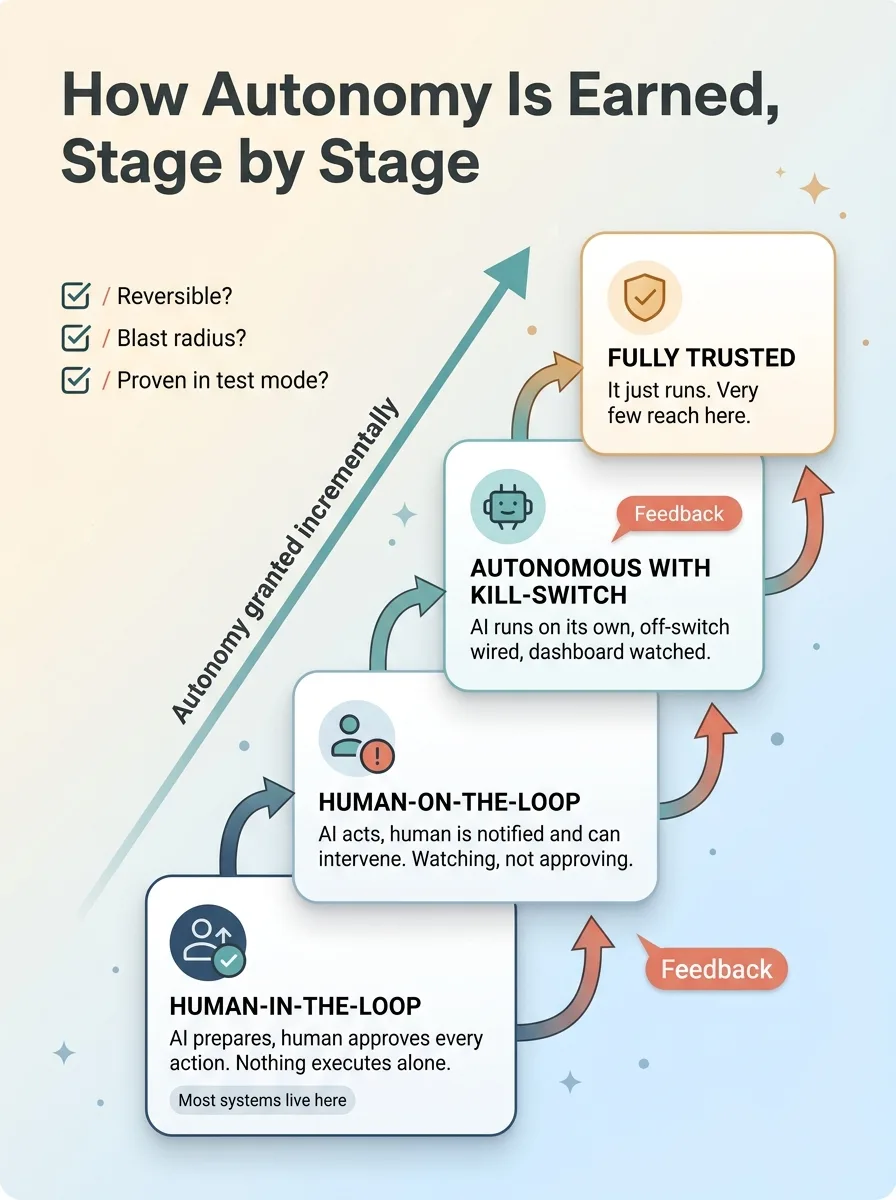
Then autonomy gets granted incrementally, in four stages:
- Human-in-the-loop. AI prepares, human approves every action. Nothing executes alone.
- Human-on-the-loop. AI acts, human is notified and can intervene. Watching, not approving.
- Autonomous with kill-switch. AI runs on its own, but the off-switch is wired and someone's watching the dashboard.
- Fully trusted. It just runs.
Most of my systems live at stage one or two. Very few reach stage four, and that's not a failure. That's the design working.
This is the real answer to the CEO's actual question. AI won't do anything irreversible to your business, not if you architect the gates in from day one. The fear is legitimate. The solution is structural, and it's available the moment you decide restraint is part of the build.
Restraint Is a Design Decision, Not an Afterthought
The vendors selling fully autonomous agents are optimizing for the demo. I'm optimizing for the 3am incident that the demo never shows you.
I build the off-switch before I build the feature. The gate comes first. The autonomy comes later, slowly, only after the system earns it. That ordering isn't caution for its own sake. It's the difference between a system you can trust in production and one you're constantly nervous about.
If you've been burned by an AI vendor who overpromised, or your board is asking about AI and you're quietly nervous about what could go wrong, the answer isn't to avoid AI. It's to deploy it with gates from the start.
When I come into a business, the first thing I map is where the kill-switches and gates need to go, before I build a single feature. I want to know your irreversible actions and your blast radii before I write any code. That map is the foundation everything else sits on.
If that's the conversation you want to have, let's talk about where the gates should go.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call