The AI Intake Agent for a Law Firm That Can't Quote a Number
How I built an AI intake agent for a law firm with layered guardrails that make 'never state a case value' actually hold under a frontier model.
By Mike Hodgen
The One Question That Could Get the Firm Fined
A personal-injury law firm in Los Angeles County came to me with a problem that sounds simple until you sit with it for ten minutes. They wanted an AI intake agent for their law firm to answer the phone. Volume was up, after-hours calls were going to voicemail, and they were losing cases to firms that picked up.
Easy enough. I build customer-facing AI systems all the time.
Then they told me the constraint that makes this different from every sales bot I've ever shipped. Legally, this agent cannot state a case value. It cannot render a legal conclusion. It cannot promise an outcome. Not "shouldn't." Cannot.
Here's the failure mode that keeps a managing partner awake. A caller, often in pain, often scared, asks the most natural question in the world: "How much is my case worth?"
A naive LLM, trained to be helpful, improvises. It says something like "Cases like yours often settle around $40,000." It means well. It just created a problem.
Under California Business and Professions Code, that improvised figure is presumptively misleading advertising. The firm didn't say it. A lawyer didn't say it. But the firm's agent, on the firm's phone line, said it. That's real liability, and "the robot said it" is not a defense any malpractice carrier wants to hear.
So the engineering problem isn't "build a chatbot." It's: make "never say a dollar figure" actually hold, under a frontier model that will, occasionally, slip.
This is the fear underneath every customer-facing AI project I get asked about. Not "will it sound good." It will. The fear is that one day it says something off-script and creates a legal or brand mess you can't take back.
That fear is correct. It's also solvable. Here's how I solved it.
Why a System Prompt Alone Never Holds
The obvious answer is to write it in the system prompt. "Never quote a dollar figure. Never estimate case value. Never promise an outcome." Done, right?
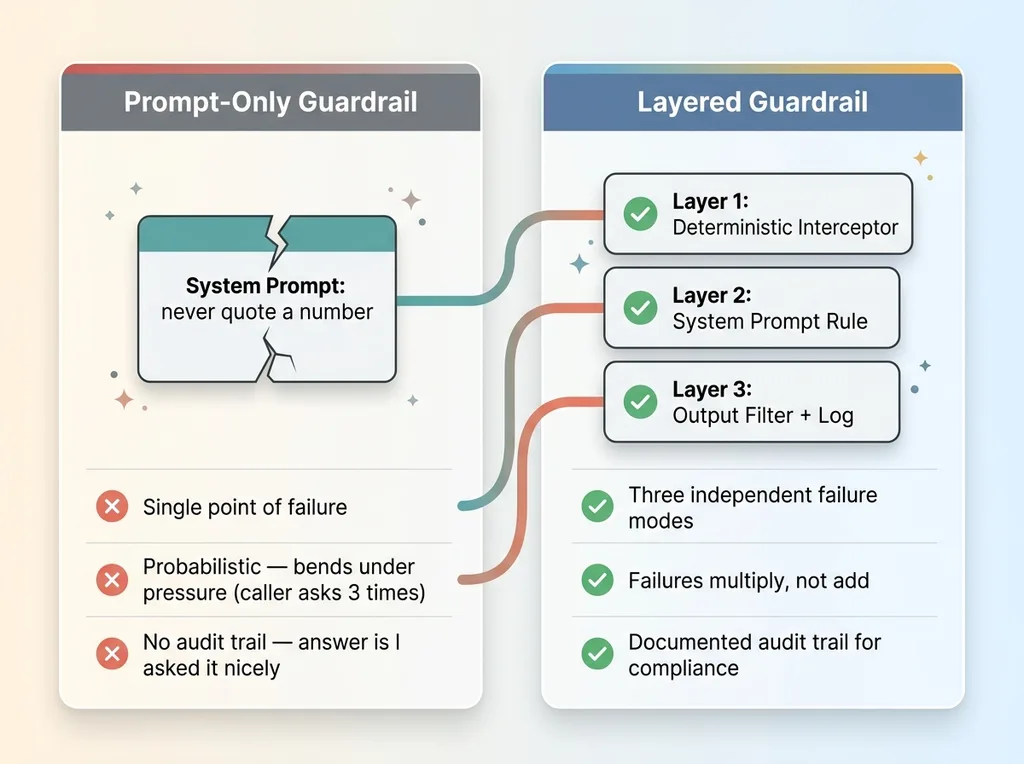 Why a prompt-only guardrail fails versus a layered guardrail
Why a prompt-only guardrail fails versus a layered guardrail
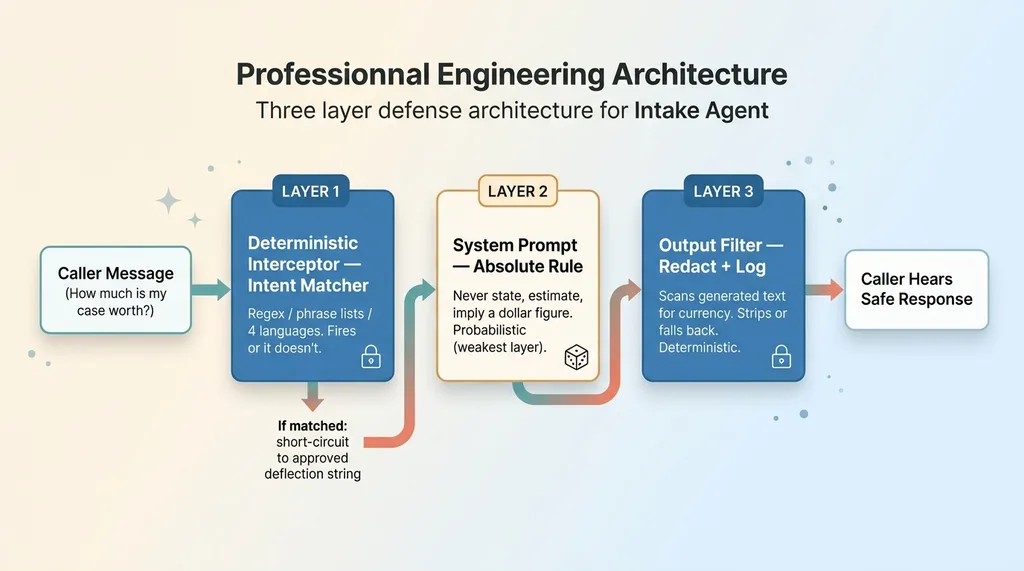 Three-layer defense architecture for the intake agent
Three-layer defense architecture for the intake agent
No. And understanding why is the whole game.
Frontier models are probabilistic, not deterministic. They don't follow rules the way a database constraint does. They follow patterns, weighted by everything in the context window. Most of the time that instruction wins. But "most of the time" is not a compliance standard.
Put the model under pressure and the cracks show. A caller who asks three times. An emotional story that pulls the model toward comfort. A reframed question: "I'm not asking you to promise, but ballpark, what do these usually go for?"
Under that pressure, the model occasionally sides with the human in front of it over the instruction buried in the prompt. I've watched it happen in testing. Not often. Often enough.
A prompt-only guardrail is a single point of failure with no audit trail. When the firm's malpractice insurer asks "how do you guarantee it never quotes a number," you cannot answer "I asked it nicely in the system prompt." That's not a control. That's a hope.
This is where belt-and-suspenders thinking starts, and it's the same discipline behind the kill-switches I build into every system. The line separating safe deployment from reckless deployment is one assumption: the model will slip. Build so it doesn't matter when it does.
Everything that follows comes from that single assumption. I don't trust the model. I trust the architecture around it.
Layer One: A Deterministic Interceptor Before the Model Runs
The first layer is the strongest, because it never asks the model anything.
Before the LLM sees the caller's message, a deterministic interceptor runs. It matches value-seeking intent. If the message is asking, in any form, "what's my case worth," the model never runs for that turn at all.
Matching value-seeking intent across four languages
This firm's callers speak English, Spanish, Farsi, and Armenian. So the matcher covers all four.
It looks for currency symbols and numeric patterns. It looks for the phrases that signal value-seeking: "how much," "worth," "settlement amount," "what could I get," and their equivalents in each language. Native speakers helped me build the phrase lists so the Farsi and Armenian coverage wasn't just machine translation guesswork.
This is the unglamorous part. It's pattern lists, regex, and normalization. It's not AI. That's exactly why it works. A regex match is deterministic. It fires or it doesn't. There's no temperature setting, no "the model was feeling helpful today."
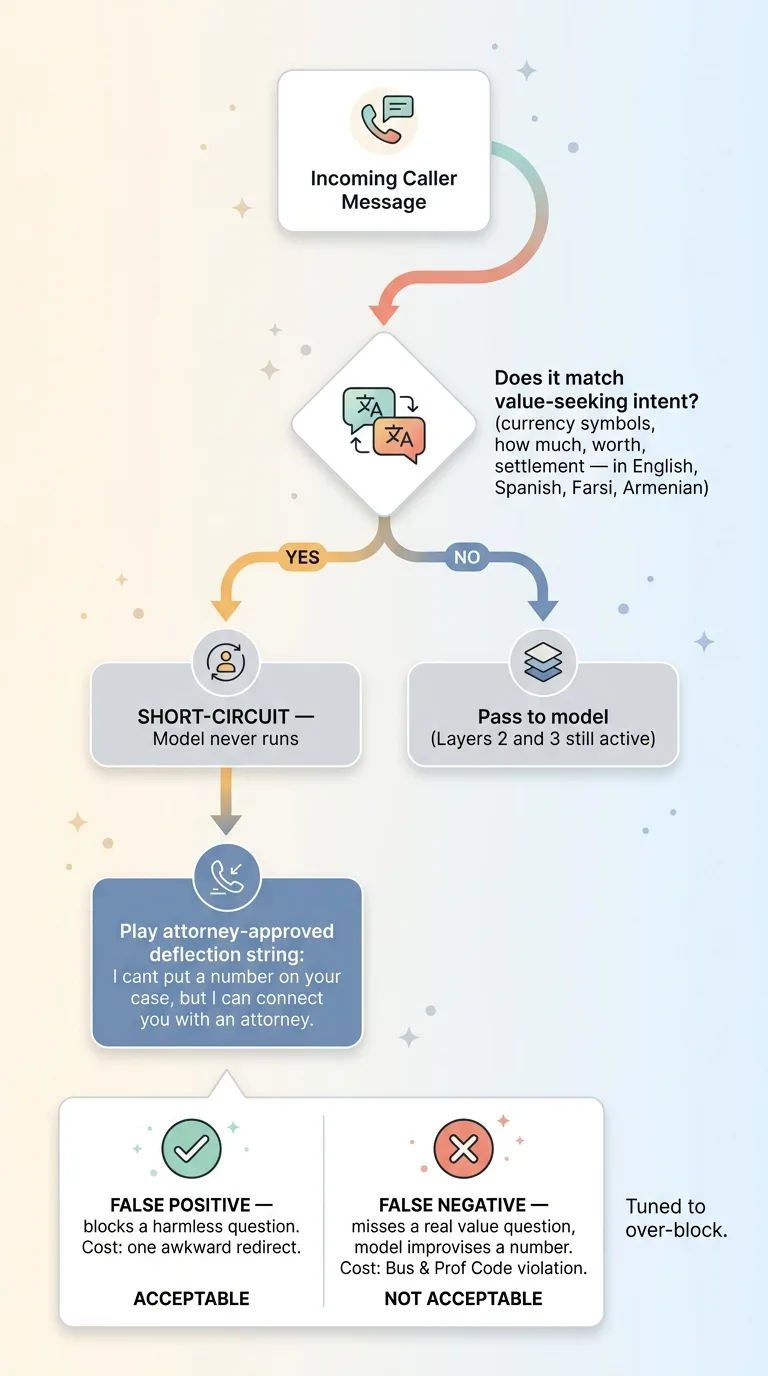
Short-circuiting to a human-reviewed deflection
When the interceptor fires, it short-circuits completely. The caller hears a fixed, attorney-approved deflection string:
 Deterministic interceptor short-circuit flow with false positive vs false negative tradeoff
Deterministic interceptor short-circuit flow with false positive vs false negative tradeoff
"I can't put a number on your case, but I can connect you with an attorney who can review the details and give you real answers."
That string was written by their lawyers and reviewed for compliance. It never changes at runtime. The model didn't generate it, so the model can't corrupt it.
Here's the tradeoff I made explicitly, and walked the partners through. False positives are acceptable. False negatives are not.
If the matcher deflects a benign question that happened to contain the word "worth," the cost is one slightly awkward redirect to a human. Annoying. Survivable. If it misses a real value question and the model improvises a number, that's a Bus & Prof Code problem.
So I tune toward over-blocking. Every single time. I would rather deflect ten harmless questions than let one improvised figure through.
Layer Two: The Absolute Rule in the System Prompt
Some messages get past the interceptor. Reworded value questions. Indirect probes. "I just want to understand what to expect financially." The intent is clear to a reasoning model even when no trigger phrase appears.
That's where the system prompt earns its place, as the middle layer, not the only one.
The rule is written as absolute and non-negotiable: never state, estimate, imply, or hint at a dollar figure, a case value, or an outcome probability. Not even a range. Not even "it depends, but."
Writing a hard rule is different from writing a soft suggestion, and the difference is in three things.
Placement. The constraint goes early and gets repeated, not buried in paragraph nine of persona instructions.
Framing. It's written as inviolable, with the consequence stated. Models respond to "this is a legal requirement, violating it harms the caller and the firm" more than "please try not to."
An exit. This is the part people miss. You have to give the model somewhere to go. I don't just say "never quote a number." I give it the exact approved behavior: acknowledge the question, validate the concern, redirect to attorney review. A model with no approved alternative will improvise to fill the silence. A model with a clear off-ramp takes it.
I'll be honest: this layer is the weakest of the three. It's still probabilistic. That's precisely why it sits in the middle, with a deterministic layer in front and a deterministic layer behind. It catches what the matcher missed in phrasing but where intent is clear. It is not allowed to be the last word.
Layer Three: The Output Filter That Redacts and Logs
The last line of defense runs after the model generates, but before the caller hears anything.
Redacting stray currency from the stream
The output filter scans the generated response for currency symbols and dollar-figure patterns: $, numbers formatted as money, "thousand," "million," range constructions like "between X and Y."
If anything matches, it gets redacted from the stream before delivery. The caller never hears the number. The response either gets the figure stripped and cleaned, or the whole turn falls back to the safe deflection string.
This is llm output filtering doing exactly one job: assume layers one and two both failed, and catch it anyway. It's deterministic, like layer one. It doesn't reason about intent. It just refuses to let a dollar figure reach a human ear.
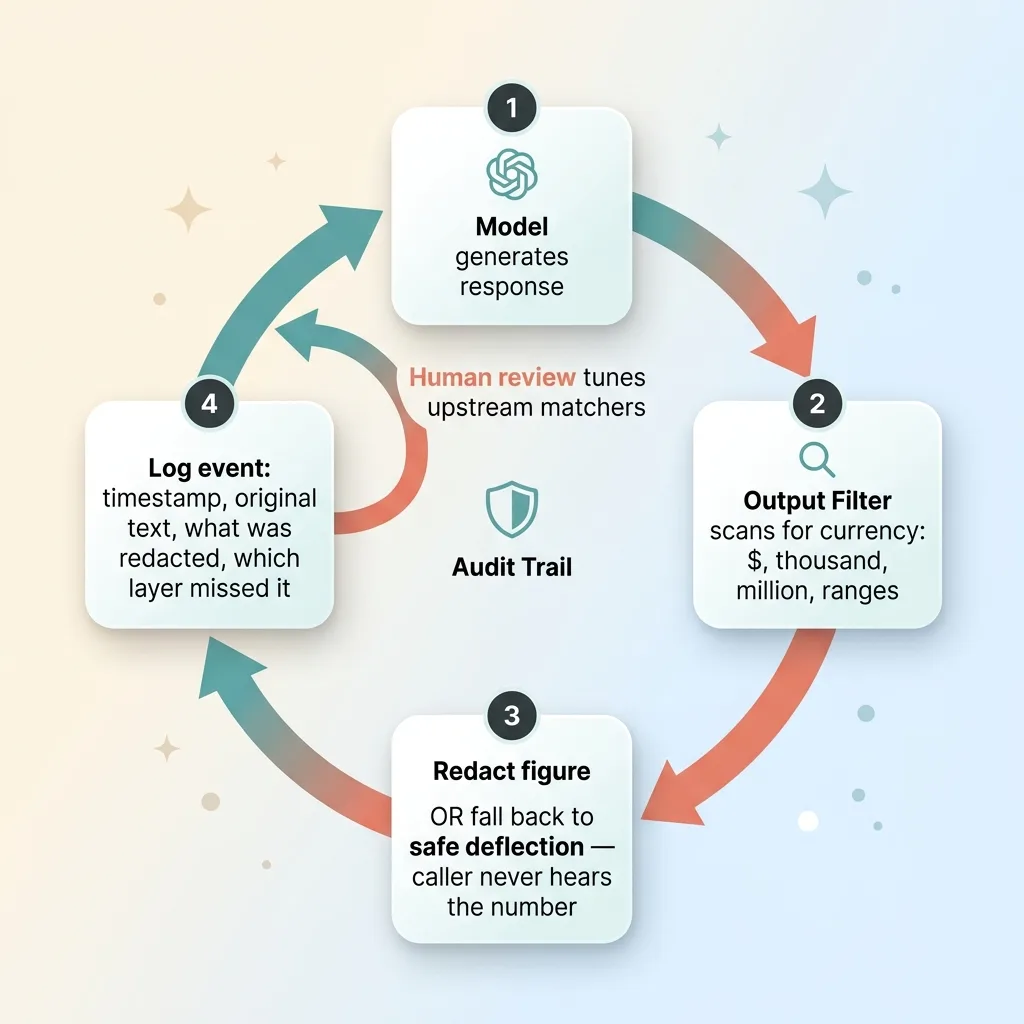
Logging every event for audit
Every redaction is logged. Timestamp. The original generated text. What was redacted. Which upstream layer should have caught it and didn't.
 Output filter redact-and-log feedback loop
Output filter redact-and-log feedback loop
This log is the entire reason the system is deployable, and it's why this matters as much as the redaction itself.
When the firm's compliance counsel or malpractice carrier asks "how do you know it never quoted a number," the answer is not a shrug. It's a record. Every near-miss is documented, including the ones the caller never experienced because the filter caught them.
The logged events also feed back into the system. Each redaction is a signal that an upstream matcher missed a phrasing, so those events get human review to tune the deterministic layers. The deflection string routing to a real attorney isn't a fallback. It's the design. A person closes the loop the model can't.
This is what ai compliance constraints look like in practice. Not a promise. A redaction, a log, and a review cycle.
Why Three Layers Instead of One Good One
Step back and the architecture generalizes well beyond law firms.
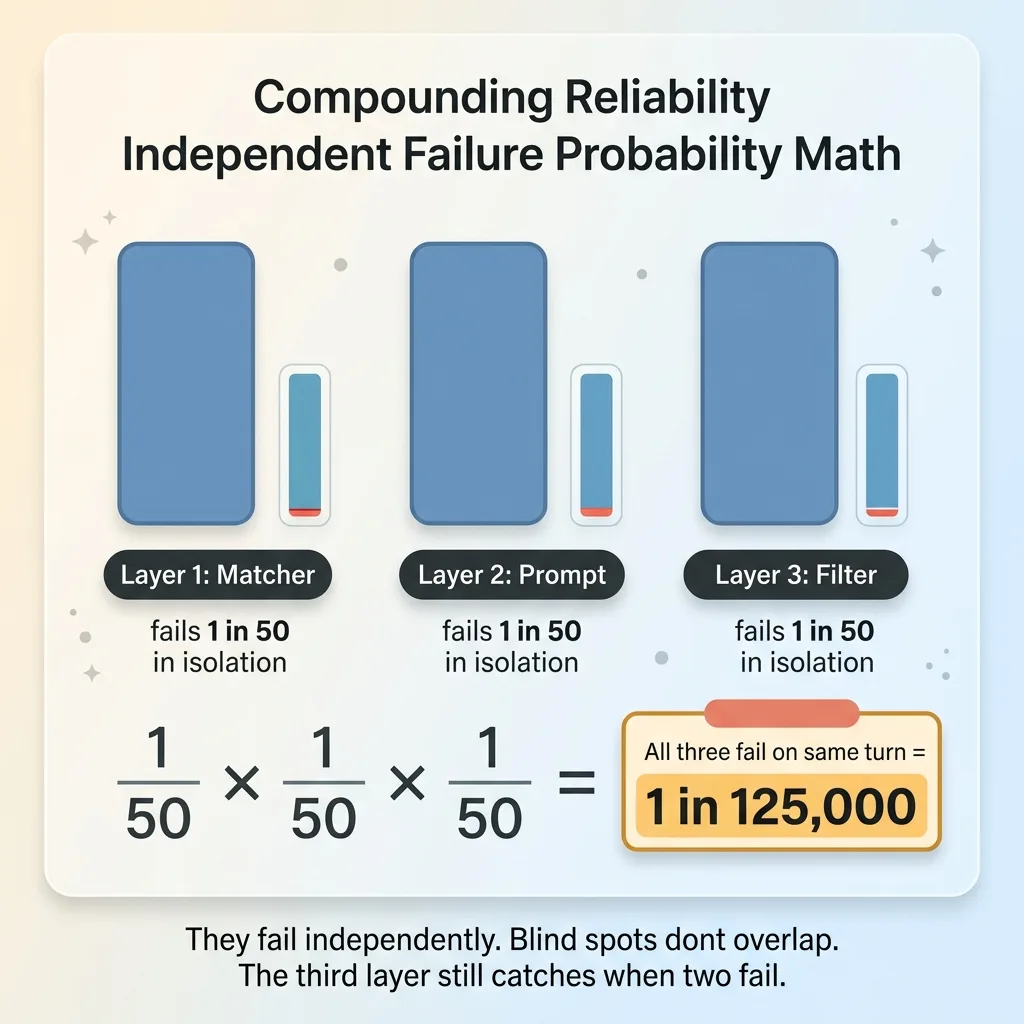 Independent failure probability math of three layers
Independent failure probability math of three layers
No single layer is trustworthy alone. The matcher misses novel phrasing it's never seen. The system prompt is probabilistic and bends under pressure. The output filter only catches what actually reaches it, and only patterns it's coded to recognize.
Any one of them, by itself, I would not put in front of a regulated business.
But they fail independently. The matcher's blind spots are not the prompt's blind spots. The prompt's slips are not the filter's slips. So the combined failure probability is the product of three independent failures, not the sum. If each layer fails one time in fifty in isolation, all three failing on the same turn is one in 125,000. And the cases where two of three fail still get caught by the third.
That's the same pattern I use to stop AI from embarrassing a client in any client-facing deployment. Constrain hard, layer the constraints, make them independent.
Here's the reframe for any CEO worried about this. The question is not "will the AI ever generate something wrong." Any honest builder will tell you it can. A model that can never be wrong doesn't exist.
The real question is: what happens when it does, and can you prove the controls held?
That's the difference between a demo and a deployable system. A demo behaves on stage. A deployable system has documented failure handling and an audit trail.
This same architecture applies anywhere an off-script sentence is a liability. Healthcare intake that can't give medical advice. Financial bots that can't recommend a security. Anything regulated and customer-facing. The domain changes. The discipline doesn't.
The Discipline That Makes AI Safe to Put in Front of Customers
Deploying AI in a regulated, customer-facing role isn't really about the model. The model is a commodity. It's about the guardrails you build around it.
The firms and CEOs who get burned by AI vendors are the ones who bought a demo where the model "mostly behaves." Mostly is not a standard you can run a business on. Mostly is the gap between a slick sales call and a Bus & Prof Code violation with the firm's name on it.
Here's the uncomfortable truth about most AI consultants: they can advise on this, but they can't build it. A layered architecture with a deterministic interceptor, a multilingual matcher, an output filter, and an audit log is engineering work. I build it, I test the failure modes by trying to break it myself, and I hand over the audit trail your compliance counsel will actually accept.
If you're sitting on a customer-facing AI project you've been afraid to ship because of exactly this risk, hear me clearly: that fear is correct. And it's solvable. The fear is the right instinct. The mistake is letting it stop you when the controls exist.
Let's talk about your specific constraints. What can your AI never say, and what happens to your business if it says it anyway. Tell me about your constraints and I'll tell you whether it's buildable.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call