Verifiable AI Medical Advice: How I Made AI Cite PubMed
How I built verifiable AI medical advice: seven specialists argue, a chief flags conflicts, the system cites real PubMed studies, and a board grades confidence.
By Mike Hodgen
Why One AI Giving Health Advice Is a Confident Guess
I built a private AI medical team for a family member. The first version was one model answering health questions, and it taught me exactly why verifiable AI medical advice is so hard to get right.
The early build was fluent. It was fast. And it was completely unverifiable.
The single-model trap
A single LLM has no second opinion. It can't flag when it's unsure, because it doesn't actually know what it doesn't know. It generates the next likely word, and the next, until it produces something that reads like medical authority.
There's no record you can defend later. No way to check why it said what it said. When you ask one model a health question, you get one answer delivered with the same calm confidence whether the evidence is overwhelming or nonexistent.
That's the trap. The output sounds like an expert. The process behind it is a guess.
Confident is not the same as correct
Here's the doubt every serious buyer has, and it's the right one: how do I get AI advice I can actually trust and defend, not a confident guess?
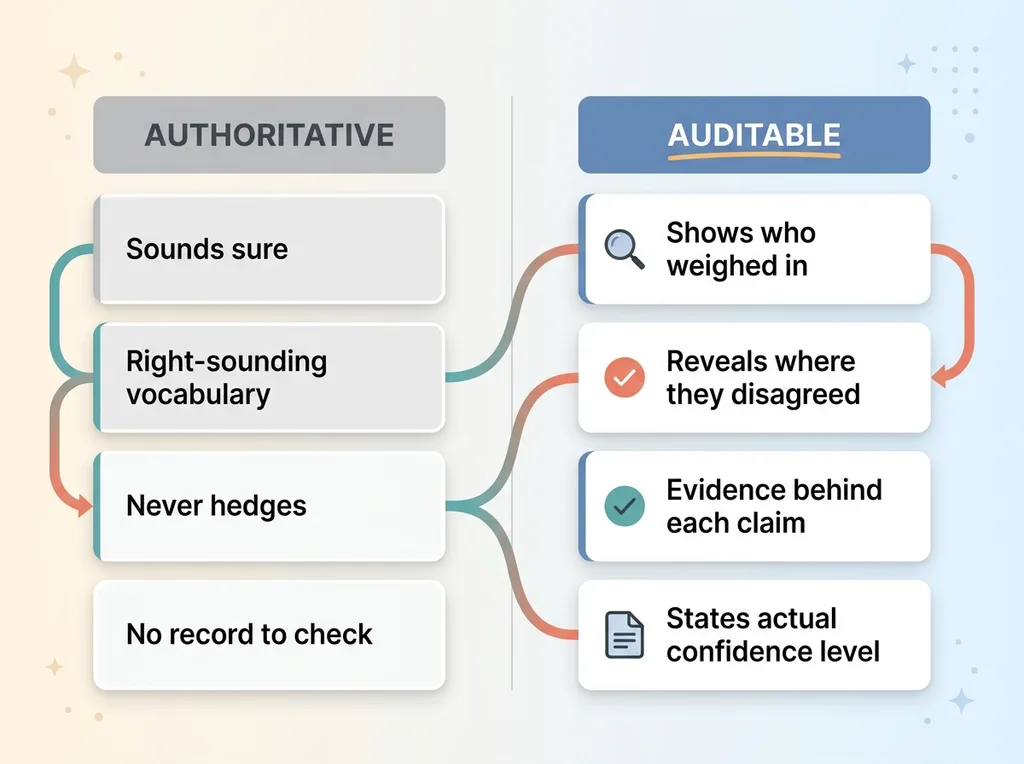 Authoritative vs Auditable AI output
Authoritative vs Auditable AI output
The distinction I kept coming back to is authoritative versus auditable.
Authoritative output sounds sure. It uses the right vocabulary, cites the right-sounding concepts, and never hedges. It feels trustworthy, which is exactly the problem.
Auditable output lets you check the work. You can see who weighed in, where they disagreed, what evidence backs the claim, and how confident the system actually is.
A single model gives you the first and almost none of the second. Closing that gap, turning confident guesses into checkable decisions, is what the rest of this is about.
Seven Specialists Answer in Parallel, Not One Generalist
The fix wasn't a better prompt. It was a better structure.
Instead of one model answering everything, I built a 7-specialist AI medical team where seven specialist agents answer the same question in parallel, each scoped to its own domain.
Running specialists at the same time
When a health question comes in, it doesn't go to one generalist. It goes to all seven specialists simultaneously. Each one is constrained to its lane and answers from that perspective only.
You get seven independent reads on the same question, produced at the same time, before anything gets combined.
This matters because a generalist model averages everything internally and hands you a single blended answer. You never see the components. You never know if it confidently merged two contradictory ideas into one smooth-sounding response.
Why parallel beats a single prompt
The payoff is disagreement.
When you ask one model, it smooths over conflict by design. It wants to give you a coherent answer, so internal tension disappears into the final text. You never know it was there.
When seven specialists answer separately, disagreement becomes visible. If five agree and two diverge, that divergence is signal, not noise. It tells you exactly where the question is harder than it looks.
That's the first layer of verification: range of perspective. A single model can be confidently wrong in one direction with nothing to check it. Seven scoped specialists give you a spread, and the spread itself is information.
Parallel isn't just faster. It surfaces the exact places where a single answer would have lied to you by being too clean.
A Chief Synthesizes, Flags Conflicts, and Verifies Every Claim
Seven answers aren't useful on their own. Somebody has to make sense of them. That's the synthesis layer, the chief medical role in the system.
But it doesn't just average the specialists. Averaging is how you launder confidence and call it consensus.
Agreements, conflicts, and gaps
The synthesis layer explicitly surfaces three things.
Agreements. Where the specialists line up, that's noted as agreement, not assumed. Consensus is recorded, not silently absorbed.
Conflicts. Where they diverge, the conflict is preserved and flagged, not resolved by quietly picking one. If two specialists disagree with five, you see that, along with what each side claimed.
Gaps. Where nobody covered something, the synthesis layer names the gap. A missing perspective is its own kind of risk, and pretending it isn't there is how you get blindsided.
Most systems stop at "here's the combined answer." This one tells you the shape of the agreement underneath it.
Checking claims against the actual record
Here's the part that actually grounds it. The synthesis layer verifies each specialist's claims against the actual health record instead of letting them assert freely.
A specialist might confidently reference a condition or a medication. The chief layer checks that against what's true for this specific person, the same way I constrain AI from inventing things in my other systems by locking it to real data.
This is the difference that matters. Synthesis without verification is just a more elaborate guess wearing a lab coat. You've taken seven plausible answers and combined them into one very plausible answer, with no more truth than before.
Verification is where claims get pinned to reality. The specialists propose. The chief checks each proposal against the actual record. Anything that can't be grounded gets flagged rather than passed through.
That's the layer that turns a panel of opinions into something you can stand behind.
Pulling Real PubMed Citations, Not Invented Ones
Now the part that breaks most AI medical tools quietly: sources.
If you ask an LLM to cite its claims, it will happily produce citations. Author names, journal titles, years, even DOI numbers. They look real. A meaningful share of them don't exist.
Why hallucinated citations are the worst kind
Hallucinated citations are the most dangerous failure mode in the whole system, worse than a wrong answer with no sources.
A wrong answer with no citation at least feels like an opinion. A wrong answer with five official-looking references feels like settled science. The fake sources don't reduce trust, they manufacture it.
You can't catch this by reading. The format is perfect. You catch it only by trying to click through, and most people never do.
So I stopped trusting the model to remember sources at all.
Using PubMed E-utilities for real sources
Instead, the system queries PubMed's E-utilities API to pull actual studies tied to the claims. It retrieves real records, not generated reference strings.
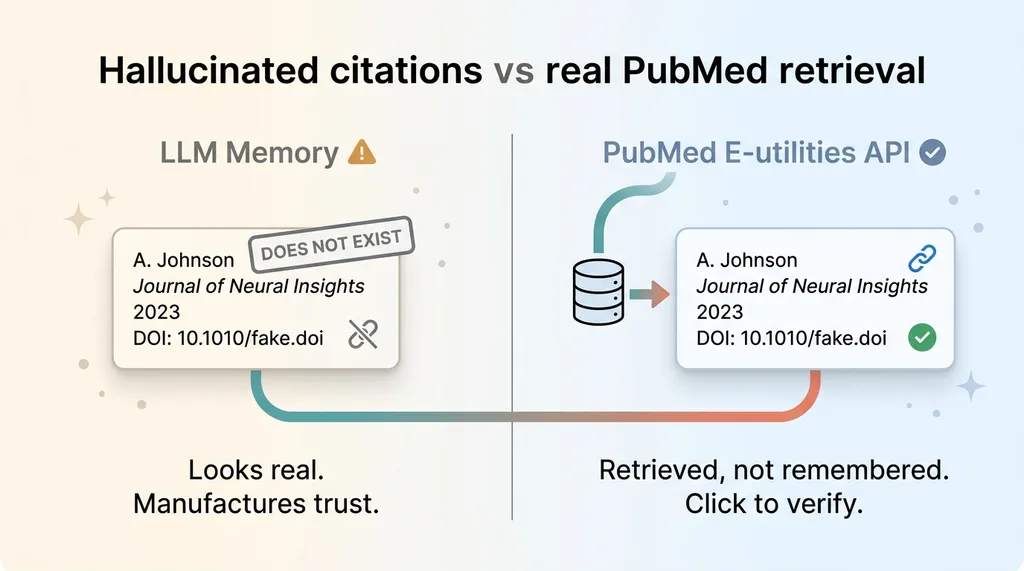 Hallucinated citations vs real PubMed retrieval
Hallucinated citations vs real PubMed retrieval
This is the same principle behind why I stopped trusting RAG for facts that matter. When the cost of being wrong is high, you don't ask the model what it remembers. You retrieve the fact from a source that exists and inject it.
A citation you can click and verify is the entire difference between advice and a guess. If the link resolves to a real study you can read, the claim has something behind it. If it doesn't, you caught the problem before it reached anyone.
I'll be honest about the limit here. Real citations are necessary but not sufficient. PubMed returns actual studies, but a study being real doesn't make it relevant, recent, or high quality. Someone still has to judge whether the right paper got pulled.
That judgment is why the next layer exists. Real sources are step one. Grading their strength is step two.
A Review Board That Grades Confidence: HIGH, MODERATE, LOW, CAUTION
Before anything gets acted on, an evidence-based review board attaches an explicit confidence level to the final output. This is the multi-agent AI review board layer, and it's where the system stops sounding sure and starts being honest.
Why explicit confidence levels matter
The review board assigns one of four levels.
 Four-level confidence grading scale
Four-level confidence grading scale
HIGH. Strong evidence, specialists in agreement, solid citations. This is as close to settled as the system gets.
MODERATE. Reasonable evidence, mostly aligned, but with some divergence or thinner sourcing. Worth acting on with awareness.
LOW. Weak or limited evidence, meaningful specialist disagreement, or sparse citations. Treat as a lead, not a conclusion.
CAUTION. Conflicting evidence, significant disagreement, or a topic where a wrong call carries real risk. Stop and involve a human before anything happens.
These ai confidence levels aren't decoration. They change what you're allowed to do with the output.
Making advice auditable instead of authoritative
This is exactly the auditable AI decisions payload I was missing in version one.
An output that says "MODERATE confidence, two specialists disagreed on dosing, here are the three studies that informed this" is something you can defend. You know how sure the system is, why, and what it's standing on.
An output that just sounds sure is not defensible. It gives you no handle, no record, nothing to check.
The confidence grade turns a black box into a record. Six months later, you can look back and see not just what the system advised, but how strongly and on what basis. If something went wrong, you can trace it. If something went right, you can trust it more next time.
That's the whole shift. From advice that performs authority to advice that documents itself.
Nothing Touches the Calendar Without a Full Team Review
Reading advice is one thing. Letting AI change someone's actual health schedule is another entirely. So actions clear a higher bar than answers.
I built a separate schedule pipeline that enforces the same discipline on actions, with five distinct stages.
The 5-stage schedule pipeline
Stage one. Two specialists propose a change. Not the whole team, just the two most relevant to the proposed adjustment.
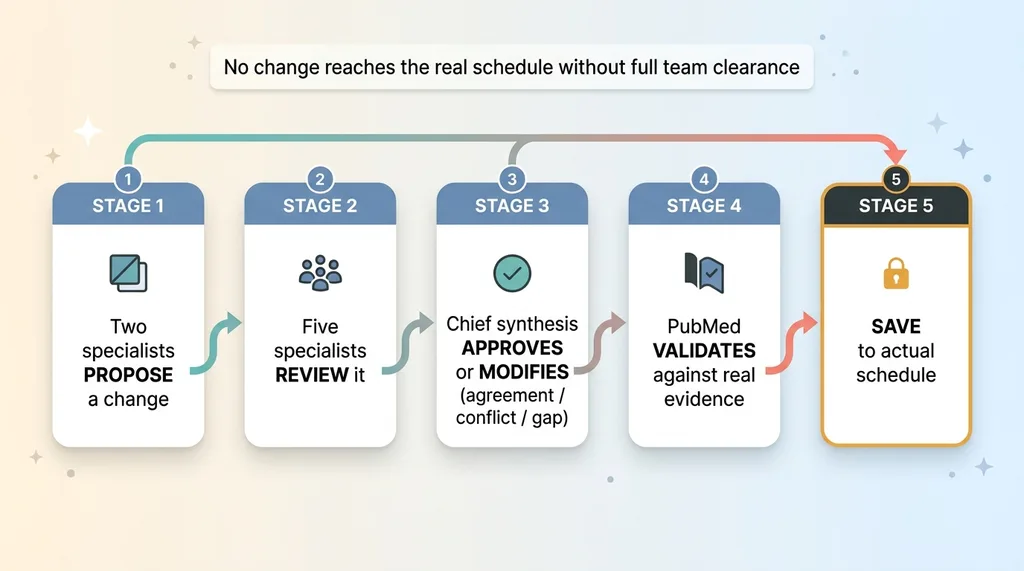 5-stage schedule action pipeline
5-stage schedule action pipeline
Stage two. Five specialists review the proposal. The proposers don't get to wave their own idea through.
Stage three. The chief synthesis layer approves or modifies the change, applying the same agreement-conflict-gap analysis to the proposed action.
Stage four. PubMed validates the change against real evidence, the same retrieval discipline applied to actions instead of advice.
Stage five. Only then does it save to the actual plan.
No AI-proposed change reaches the user's real schedule without the full team clearing it.
The same gate applies to every action
This is the principle that every AI system I ship stops for a human, applied with extra weight where the stakes climb.
Advice you read, you can ignore. An AI silently editing a health schedule is a different category of risk, and it should clear a higher bar, not the same one. So the action pipeline is deliberately heavier than the advice pipeline.
This is the design choice that separates a toy from a system you'd let near someone you care about. A demo auto-applies changes because it's impressive. A real system makes every change earn its way through review, because the downside isn't a bad demo, it's a person.
If an AI is going to act, not just talk, the gate gets stricter. Always.
What This Architecture Means for Any High-Stakes AI Decision
Step back from medicine, because none of this is actually about medicine.
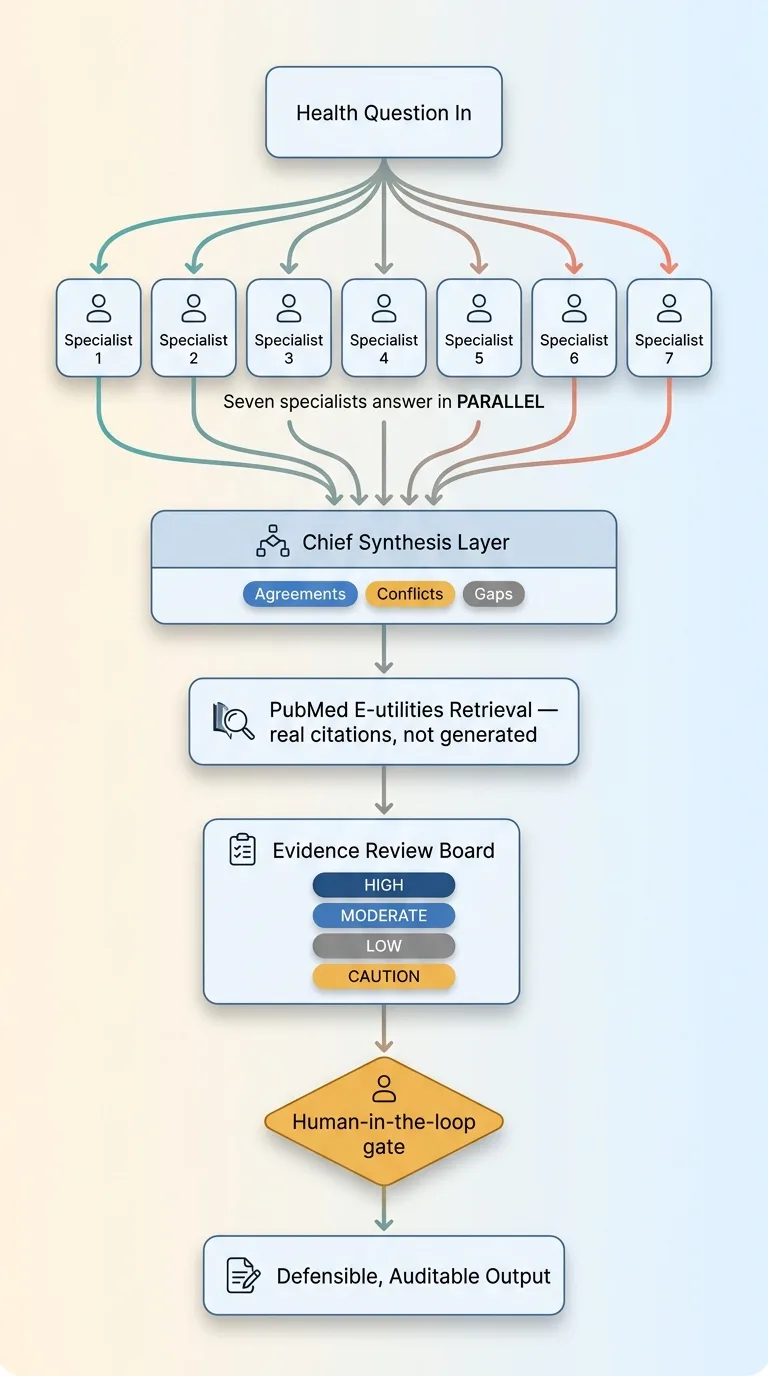 Full Verifiable AI Medical Architecture (end-to-end)
Full Verifiable AI Medical Architecture (end-to-end)
The pattern is general: parallel perspectives instead of one answer, a synthesis layer that flags conflict instead of hiding it, real retrieval for sources instead of trusting memory, explicit confidence grading instead of false certainty, and a hard gate before any action.
That's the answer to every CEO who asks me "how do I trust AI on a decision that actually matters?"
Swap the domain and the structure holds. A pricing change that affects margin across hundreds of products. A compliance call where being wrong means a fine. A customer action that can't be undone. The same architecture makes the output defensible, because it shows its work and grades its own certainty.
I'll be honest about the cost. This is more compute and more latency than a single prompt. Seven specialists, a synthesis pass, a PubMed query, a review board, and an action gate add up. One model would be faster and cheaper.
That's the point. High-stakes decisions earn the overhead. You don't run the full board to answer "what's the weather." You run it when a wrong answer is expensive.
The trick is knowing which decisions deserve which level of rigor, and building the structure to match. That's the work.
Want to explore what AI could do for your business?
If you're trying to put AI somewhere a wrong answer is genuinely expensive, this is the kind of architecture I build, and the kind of judgment that goes into deciding how much rigor each decision earns.
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call