Building a 7-Specialist AI Medical Team for Health Monitoring
How I built a multi-agent AI healthcare system with 7 specialists that catch errors a single AI misses. Real architecture, real safety lessons.
By Mike Hodgen
When someone you love has health problems that span multiple specialists, you realize fast how broken the coordination is. My mom takes several medications, wears an Oura ring, sees a cardiologist, an endocrinologist, a GP, and a couple of other specialists. None of them have the full picture. Her cardiologist doesn't know what her endocrinologist prescribed last month. Her GP gets a faxed summary six weeks late. I started thinking about multi-agent AI healthcare not because it was an interesting technical challenge — though it is — but because I needed something that actually worked for someone I care about.
I built a health monitoring system that treats AI like a medical team rather than a single all-knowing oracle. Seven specialist agents, each scoped to a narrow domain, feeding into a Chief Medical Officer synthesis layer, validated against published research. It's not a medical device. It doesn't diagnose anything. It's a research and monitoring tool that helps me walk into her doctor's appointments with organized, evidence-backed questions instead of scattered notes from five different patient portals.
I want to be upfront: this article is about the architecture and the reasoning behind it. I'll keep the technical depth accessible because the design principles here apply far beyond health — they apply to any business where a single AI confidently getting something wrong could cause real damage.
Why a Single AI Hallucinates Medications (And a Committee Catches It)
The Confidence Problem
Ask a general-purpose AI, "My mom takes metformin and lisinopril — should she also take this supplement her friend recommended?" You'll get a confident, well-structured answer. It might even sound medically authoritative. The problem is that answer might be completely fabricated.
I've tested this. I asked a single LLM about a specific drug interaction and it confidently cited a contraindication that doesn't exist. Reversed the question slightly, and it missed a real interaction that any pharmacist would flag in seconds. The issue isn't that the AI is stupid — it's that a general model has no internal mechanism to check itself. It generates plausible text. Plausible and accurate are not the same thing when you're talking about someone's medications.
Better prompting doesn't fix this. You can add "be careful" and "cite sources" to your system prompt all day. The model will still hallucinate citations that look real but aren't. I've seen it invent PubMed study IDs that return 404s.
How Specialists Create Natural Guardrails
The fix is architectural, not procedural. This is the same principle behind why I use multiple AI models instead of one — specialization reduces the surface area for hallucination.
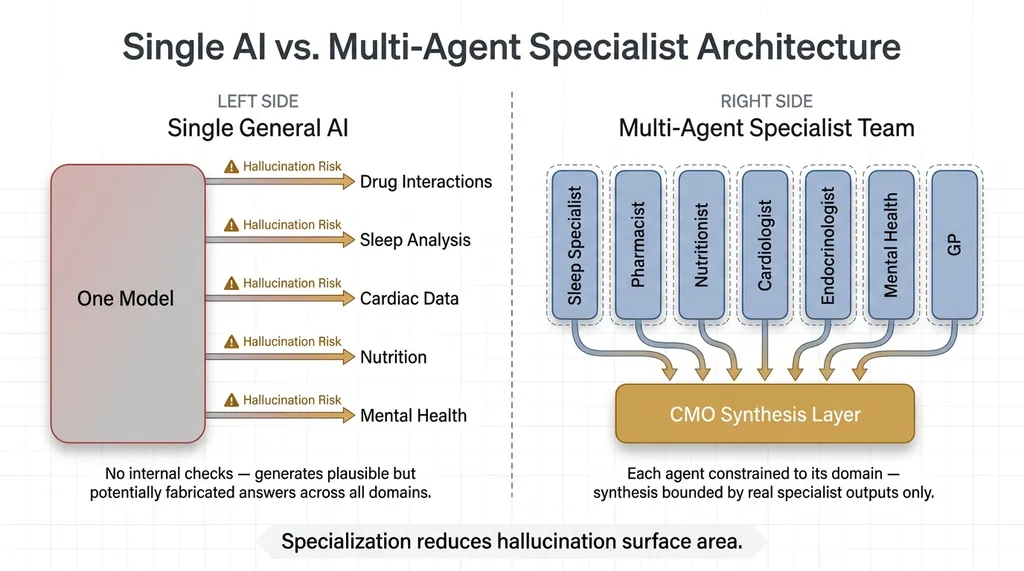 Single AI vs. Multi-Agent Specialist Architecture
Single AI vs. Multi-Agent Specialist Architecture
When you have a Pharmacist agent that only evaluates medications against known interaction databases, it's not trying to also interpret sleep data or guess about metabolic markers. It stays in its lane. A Sleep Specialist that only analyzes Oura ring data isn't opining on drug interactions. Neither agent is tempted to fill gaps in its knowledge with confident nonsense because its scope literally prevents it.
Then a CMO agent synthesizes the specialist outputs — but it can only work with what the specialists actually provided. It can't invent findings. If the Pharmacist didn't flag an interaction, the CMO doesn't get to make one up. This creates a natural error-correction pipeline. Each specialist constrains the others, and the synthesis layer is bounded by real outputs, not open-ended generation.
Think of it this way: you'd never walk into a hospital and ask one doctor to be your cardiologist, pharmacist, nutritionist, and sleep specialist simultaneously. You'd get a team. The AI medical team approach works the same way.
The 7 Specialists and What Each One Does
Each agent has a strict system prompt defining its scope. The critical rule: if something falls outside its domain, it must say "outside my scope" rather than guess. Here's what each one covers.
 The 7-Specialist AI Medical Team Roles and Scope Boundaries
The 7-Specialist AI Medical Team Roles and Scope Boundaries
Sleep Specialist
Ingests Oura ring data — sleep stages, HRV during sleep, respiratory rate trends, sleep latency, wake-after-sleep-onset. Evaluates patterns over time, not single nights. Flags degradation trends that correlate with medication changes or lifestyle shifts. Cannot interpret lab results or recommend medications.
Pharmacist
Maintains the complete medication list with dosages and timing. Checks interactions against known databases. Flags timing conflicts — medications that shouldn't be taken together or that interact with specific foods. Cannot diagnose conditions or recommend adding or removing medications.
Nutritionist
Tracks dietary patterns and supplement intake. Evaluates supplement-medication interactions. Identifies nutritional gaps that might correlate with reported symptoms. Cannot prescribe diets for medical conditions or override the Pharmacist on supplement safety.
Cardiologist
Monitors resting heart rate data, HRV trends over weeks, and flags cardiovascular anomalies in the biometric data. Correlates cardiac data with medication changes flagged by the Pharmacist. Cannot interpret non-cardiac lab results.
Endocrinologist
Tracks metabolic markers from lab results — A1C, thyroid panels, fasting glucose. Correlates with energy levels, weight data, and patterns reported by other specialists. Cannot evaluate cardiac-specific concerns or mental health symptoms directly.
Mental Health Specialist
Evaluates mood patterns, sleep-mood correlations from the Sleep Specialist's data, and known mental health side effects of current medications. Flags concerning trends. Cannot prescribe psychiatric medications or override the Pharmacist's interaction assessments.
General Practitioner
The intake agent. When new data or a new concern comes in, the GP routes it to the appropriate specialists. It also handles anything that doesn't fit neatly into one specialist's domain — general wellness trends, appointment preparation, and making sure nothing falls through the cracks between specialties. This is the agent that most closely mirrors what a good primary care doctor does: coordinate.
The Team Review Pipeline: Parallel Analysis to CMO Synthesis
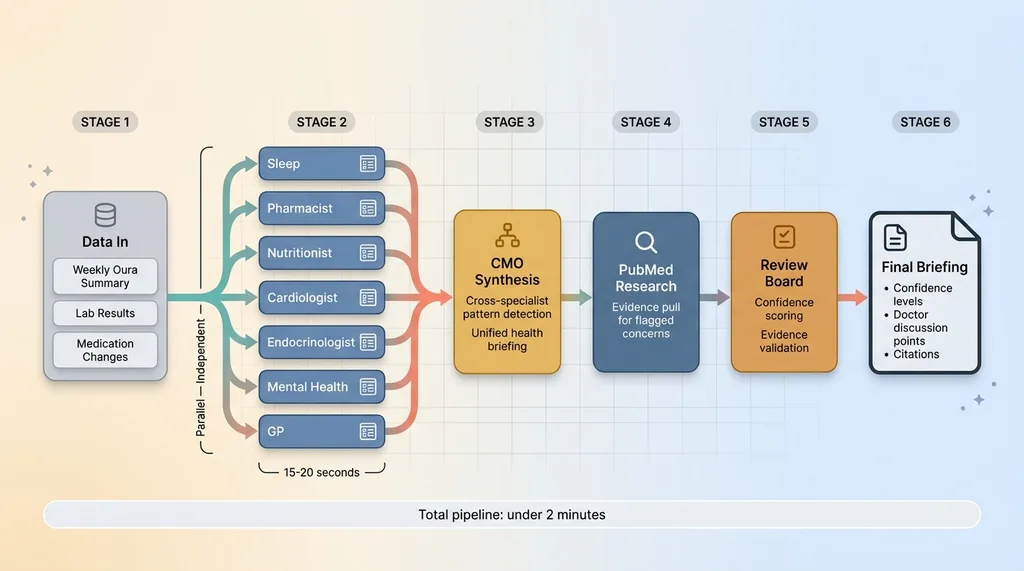 Team Review Pipeline: Data to Final Briefing
Team Review Pipeline: Data to Final Briefing
Specialists Run in Parallel
When new health data comes in — a weekly Oura summary, new lab results, a medication change — all 7 specialists analyze it simultaneously. This isn't sequential. Each agent receives the data relevant to its domain and produces a structured assessment independently.
Parallel execution matters for two reasons. First, speed. Running 7 analyses sequentially would take minutes. In parallel, the whole specialist layer completes in roughly the time of the slowest individual agent — usually 15-20 seconds. Second, independence. No specialist sees another specialist's output before forming its own assessment. This prevents cascade errors where one bad analysis contaminates the rest.
Each specialist produces a structured output: findings within scope, confidence level, flagged concerns, and explicit "outside my scope" declarations for anything it noticed but won't evaluate.
The CMO Synthesis Layer
The Chief Medical Officer agent receives all 7 assessments and synthesizes them into a unified health briefing. This is where the real value emerges — the CMO identifies connections that no single specialist would catch on its own.
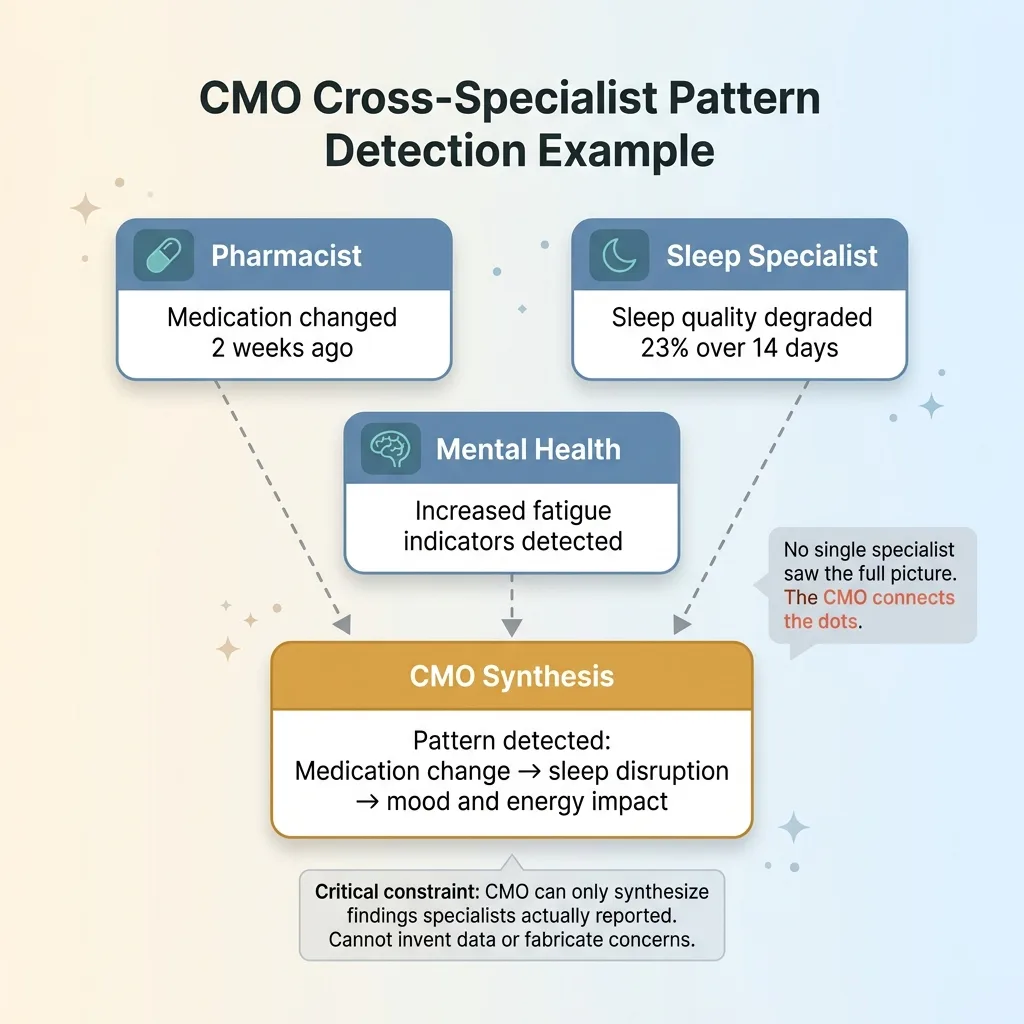 CMO Cross-Specialist Pattern Detection Example
CMO Cross-Specialist Pattern Detection Example
For example: the Pharmacist reports that a medication was recently changed. The Sleep Specialist reports that sleep quality degraded 23% over the past two weeks. The Mental Health Specialist reports increased fatigue indicators. No single specialist would connect all three, but the CMO can see the pattern: the medication change may be affecting sleep, which is affecting mood and energy.
The critical constraint: the CMO cannot invent findings that no specialist reported. It synthesizes. It connects. It identifies conflicts — like the Pharmacist saying a medication timing is optimal while the Sleep Specialist's data suggests it's disrupting sleep onset. But it cannot fabricate data or generate concerns from nothing.
PubMed Research and the Evidence-Based Review Board
After CMO synthesis, any flagged concern triggers a PubMed research step. This pulls actual published studies relevant to the specific concerns identified — not generic health information, but targeted evidence for the exact drug combinations, symptom patterns, or biometric trends in question.
The evidence-based review board is the final layer. It evaluates the CMO's synthesis against the PubMed evidence and scores confidence levels. This is the same pattern as AI that rejects its own bad work, applied to health monitoring. Any recommendation without supporting published evidence gets downgraded. It doesn't get presented as advice — it gets flagged as "discuss with your doctor" with the relevant data formatted so you can actually have that conversation productively.
The full pipeline:
- Data in → weekly Oura summary, lab results, medication changes
- 7 Specialists → parallel independent analysis
- CMO Synthesis → unified briefing, cross-specialist pattern detection
- PubMed Research → evidence pull for flagged concerns
- Review Board → confidence scoring, evidence validation
- Final Briefing → output with confidence levels, doctor discussion points, and citations
The whole pipeline runs in under two minutes. My mom's health data goes from scattered across five apps and three doctor portals to a single, organized, evidence-backed briefing.
Safety Decisions That Shaped the Architecture
What the System Will Never Do
I want to be blunt about the boundaries because this is where most AI health projects go wrong — they blur the line between monitoring and diagnosis.
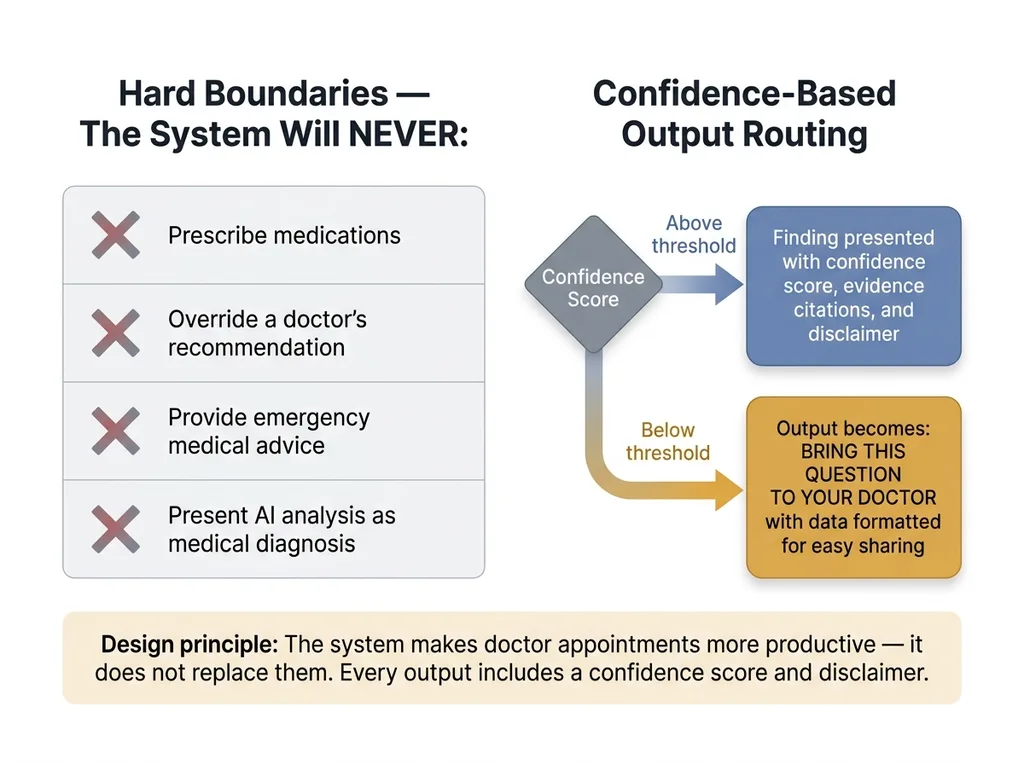 Safety Architecture: Hard Boundaries and Confidence Thresholds
Safety Architecture: Hard Boundaries and Confidence Thresholds
This system will never prescribe medications. It will never override a doctor's recommendation. It will never provide emergency medical advice. It will never present AI analysis as medical diagnosis. Every single output includes a confidence score and a disclaimer. If confidence is below the threshold, the output isn't a softened recommendation — it's literally "Bring this question to your doctor" with the data formatted for easy sharing.
The system is explicitly designed to make doctor's appointments more productive, not to replace them. The best outcome is my mom's cardiologist saying, "That's a good question, I hadn't seen that sleep data — let me look into it." That's the bar. Not "the AI told me to change my dosage."
Privacy and Data Handling
Health data demands a higher standard. All data is encrypted at rest using AES-256. No health data leaves the system to third-party APIs beyond the LLM inference calls themselves, and those calls are structured to avoid transmitting identifying information. The prompts contain health metrics and medication names — not names, dates of birth, or insurance information.
I made a deliberate choice to keep this as a personal project rather than building it into a SaaS product. The liability and regulatory landscape for AI health tools is serious, and rightly so. HIPAA compliance for a multi-agent system processing PHI across multiple LLM providers is a genuine engineering challenge — solvable, but not something to hand-wave past. This is a tool I built for my family. That's the scope, and I'm comfortable with that boundary.
This honesty about limitations isn't a weakness in the system design. It is the system design. Every guardrail, every "outside my scope" declaration, every confidence threshold — they're all features, not compromises.
What This Architecture Reveals About Multi-Agent Systems
The multi-agent AI healthcare pattern isn't unique to health. It works anywhere the stakes are high and a single AI hallucinating could cause real damage.
Financial analysis. Legal review. Manufacturing quality control. Compliance. Any domain where you'd never trust one person's unsupervised opinion, you shouldn't trust one AI's unsupervised output either.
The design principles transfer directly:
- Scope each agent narrowly — specialists that stay in their lane hallucinate less
- Run them in parallel — speed plus independence
- Synthesize with a dedicated coordinator — the CMO pattern, not a free-for-all
- Validate against external evidence — PubMed for health, industry databases for business
- Build in rejection — the system must be able to say "I don't know" rather than guess
I've applied this same pattern across my DTC brand — pricing agents, quality control agents, content agents, each specialized, each constrained. The 38% revenue-per-employee improvement I've seen didn't come from one brilliant AI. It came from 29 specialized agents that check each other's work. The health monitoring system is the same philosophy applied to something more personal.
For anyone building AI systems that touch anything consequential: a single-agent approach is a liability. A multi-agent approach with built-in disagreement and evidence checking is how you build AI you can actually trust with real decisions.
Building AI Systems You'd Trust With Your Family's Health
I built this because I needed it. My mom's health data was scattered across five doctor's offices, an Oura ring app, and a medication list held to her fridge with a magnet. Now it's synthesized weekly by an AI medical team of 7 specialists, reviewed against published research, and delivered as a briefing I can actually bring to her appointments.
The bar I set for this system — and every system I build — is simple: would I trust this with my family? If the answer is no, the architecture isn't done yet. That standard pushed every design decision. The scoping. The parallel analysis. The evidence validation. The hard limits on what the system will and won't do. None of that came from best practices in a textbook. It came from the fact that my mom's health is on the other end of the output.
Whether you're building AI for health tech, financial services, or day-to-day operations, the architecture matters more than the model. A well-structured multi-agent system with proper guardrails running a mid-tier model will outperform a single call to the most advanced model on the market — and it'll be safer.
I build these systems. If you're thinking about what yours should look like, let's talk.
Thinking About AI for Your Business?
If any of this resonated — the multi-agent architecture, the built-in quality checks, the principle that AI should be constrained by design rather than trusted by default — I'd like to hear what you're working on. I do free 30-minute discovery calls where we look at your operations and identify where AI could actually move the needle.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call