I Built an AI That Rejects Its Own Bad Work
How I built an AI quality control system that scores content on 8 criteria, auto-rejects failures, and passed 6 articles first try.
By Mike Hodgen
The Problem: AI Produces Garbage Unless You Make It Care
AI doesn't care if it writes terrible content. It'll happily generate bland, generic, factually wrong output all day long if you let it.
I learned this the hard way when I first started automating our blog at my DTC fashion brand. Early AI drafts would open with gems like "In today's fast-paced digital landscape, businesses are increasingly turning to artificial intelligence..." Pure slop. Or worse — product descriptions that confidently stated features our products didn't have, or blog articles citing statistics I couldn't verify.
The obvious solution is human QA. I could review every piece of AI output before it goes live. And I did, for a while. But when you're generating 100+ pieces of content monthly across blog articles, product descriptions, SEO meta tags, and customer service responses, human review becomes the bottleneck. I was spending 15-20 hours a week just checking AI output for quality.
So I built an AI quality control system that evaluates its own work against real standards. Not a human asking "does this look good?" — an automated evaluation AI that scores content on specific criteria and rejects anything below threshold. The system has already evaluated this article you're reading right now. It passed first attempt with an 8.2/10.
This isn't theoretical. This is production infrastructure running across multiple content pipelines at my DTC fashion brand. And it works.
How the Self-Evaluation System Actually Works
The core architecture is simple: separate the AI that generates content from the AI that judges it.
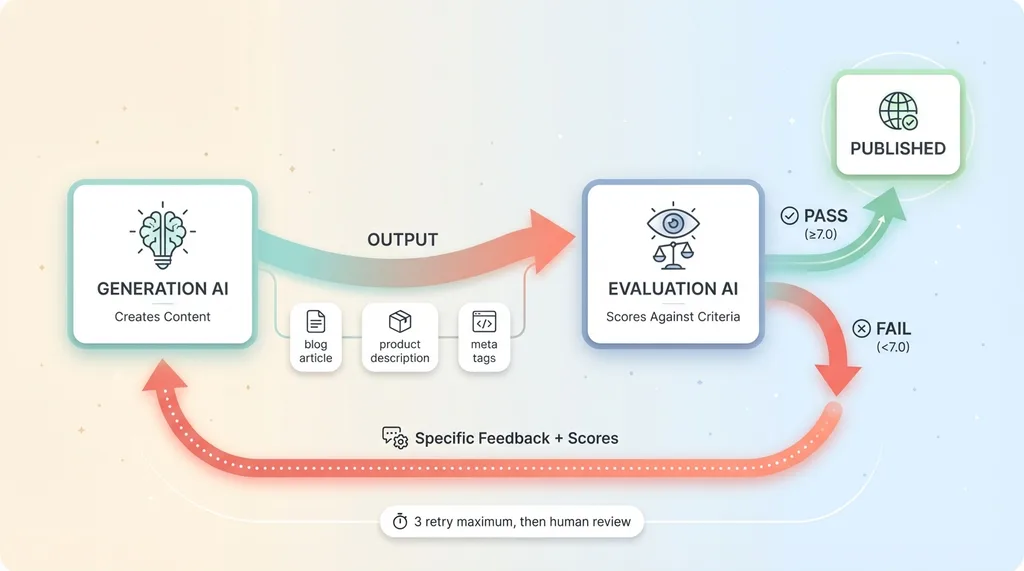 Dual-AI Quality Control Architecture
Dual-AI Quality Control Architecture
When my content generation AI produces output — a blog article, product description, whatever — it doesn't go straight to publication. It gets sent to an evaluation AI with a completely different prompt and objective. That evaluator scores the content on eight specific criteria, each on a 1-10 scale.
The 8-Point Scoring Rubric (Without Giving Away the Secret Sauce)
I'm not publishing the exact prompts because they're competitive advantage, but the categories are straightforward: accuracy, relevance, structure, tone, actionability, depth, originality, and technical quality.
 8-Point Scoring Rubric Breakdown
8-Point Scoring Rubric Breakdown
Accuracy checks for factual errors, unsupported claims, or made-up statistics. Relevance measures whether the content actually addresses the intended topic or wanders off target. Structure evaluates organization, flow, and readability. Tone assesses whether the voice matches my actual writing style — not generic AI corporate speak.
Actionability measures whether the content gives readers something concrete they can do or understand, not just abstract concepts. Depth checks for substantive insights versus surface-level filler. Originality flags content that sounds like every other AI-generated article on the topic. Technical quality catches grammar issues, awkward phrasing, or formatting problems.
Each criterion gets scored independently. The evaluator AI provides a numerical score and brief justification for each one. Then all eight scores average into a final quality score.
Why 7.0 Is the Minimum (And What Happens Below That)
I set the quality threshold at 7.0 out of 10 after testing dozens of articles. Below 7.0, there's always something wrong that I'd catch in human review. Above 7.0, the content is publication-ready or needs only minor edits.
The math matters here. With eight criteria, a 7.0 average means the content can have one or two weak areas (5-6 scores) as long as everything else is solid (7-9 scores). But if multiple criteria score below 6, the average drops below threshold and the content fails.
Here's what happens when content scores below 7.0: automatic rejection and revision.
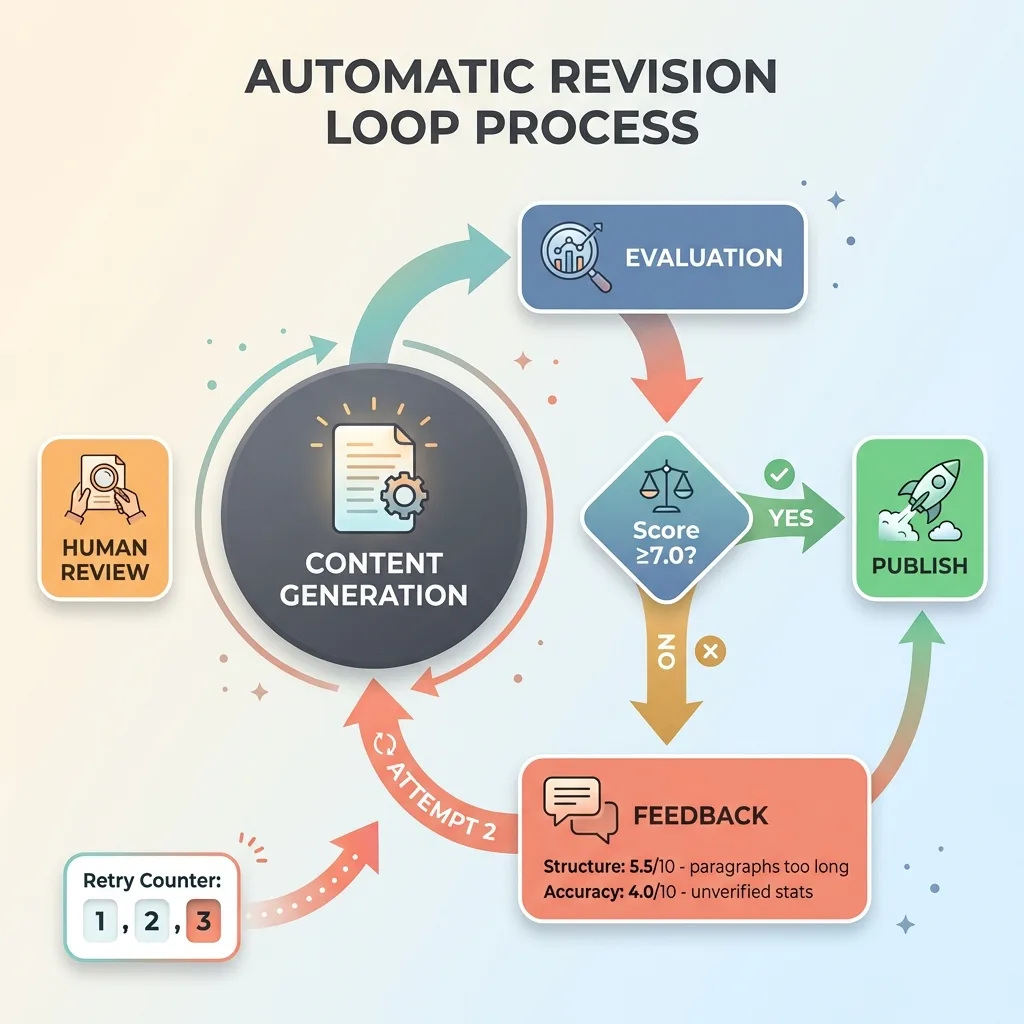
The Automatic Revision Loop
When content fails QA, the evaluation AI sends its score breakdown back to the generation AI as feedback. Not just "this is bad" — specific scores with explanations like "Structure: 5.5/10 — Paragraphs too long, lacks clear section transitions" or "Accuracy: 4.0/10 — Cites unverifiable statistics, makes unsupported claims about market size."
 Automatic Revision Loop Process
Automatic Revision Loop Process
The generation AI takes that feedback and produces a revised version. It knows exactly what failed and why. The revision goes back through the same evaluation process.
I built in a maximum retry limit of three attempts to prevent infinite loops. If content fails three times, it escalates to human review. In practice, that almost never happens.
Out of the last six blog articles published, all six passed evaluation on the first attempt. Average scores ranged from 7.8 to 8.4. The system works because the evaluation criteria are specific and the feedback loop is direct.
Image QA: A Completely Different Beast
Text evaluation relies on analyzing words, structure, facts. Image quality control requires actually looking at visual output and judging composition, relevance, technical quality. Completely different problem.
Why Image Evaluation Needs Its Own AI
I use vision-capable AI models to evaluate generated images. The evaluator receives the image file, the original prompt, and context about intended use (blog featured image, product photo, social media graphic, etc.). It scores based on prompt adherence, visual quality, composition, and appropriateness.
This runs on a different model than text evaluation because the requirements are different. I use Gemini for image generation and Claude with vision capabilities for evaluation. As I explained in my article about why I use multiple AI models, different models have different strengths. Claude's vision analysis is more reliable than Gemini evaluating its own output.
The scoring rubric for images covers: prompt adherence (does it show what was requested?), technical quality (resolution, artifacts, distortion), composition (visual balance, focal point, professional look), and brand alignment (appropriate tone, style consistency).
The Three-Strike Escalation System
Image generation is less deterministic than text. Same prompt, different results every time. So the QA system uses escalating intervention when images fail.
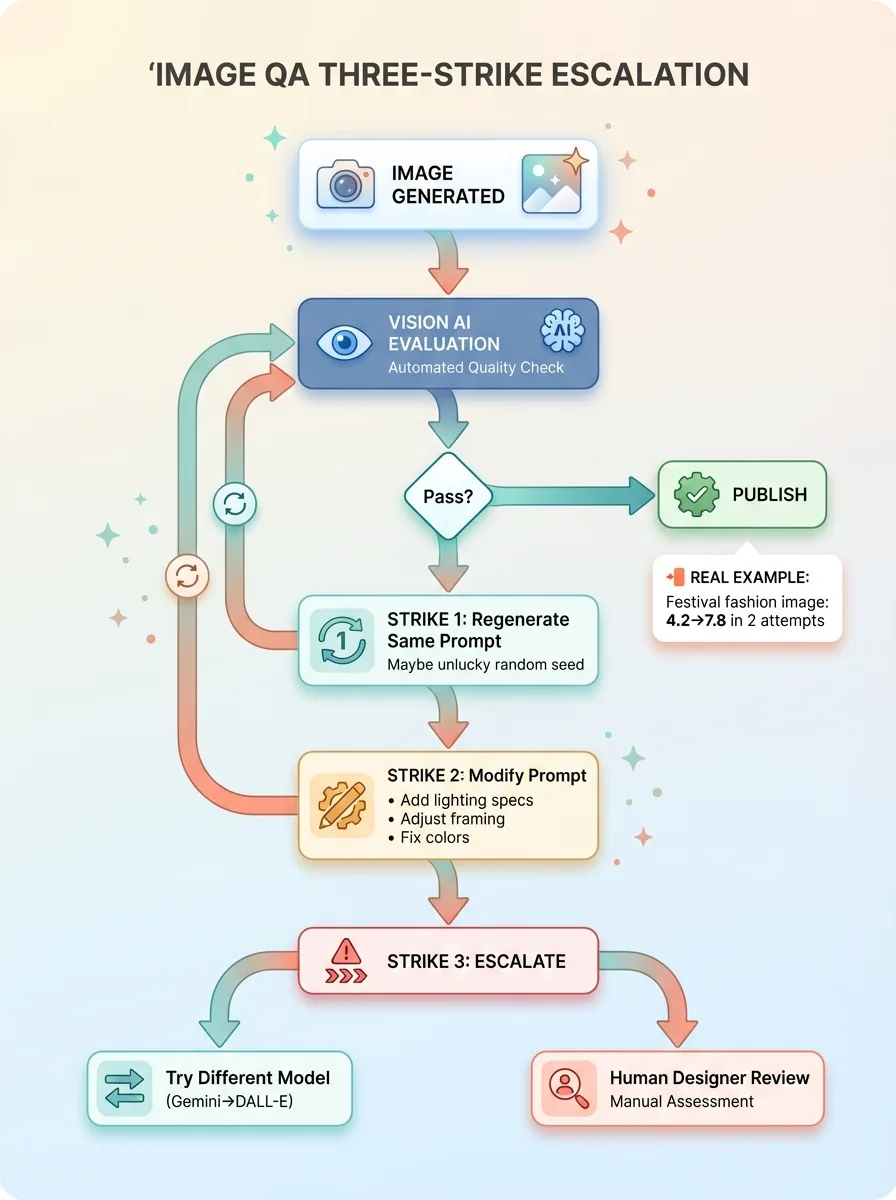 Image QA Three-Strike Escalation
Image QA Three-Strike Escalation
Strike one: regenerate with the same model and prompt. Sometimes you just got unlucky with the random seed and a second attempt works fine. If the new image passes evaluation, we're done.
Strike two: modify the prompt based on what failed in evaluation. If the image was too dark, add lighting instructions. If composition was off, specify camera angle or framing. Regenerate and re-evaluate.
Strike three: escalate to a different model or flag for human review. If Gemini keeps producing unusable images even with prompt adjustments, try DALL-E or Midjourney. Or if the use case is critical (product page hero image, for example), send to human designer.
Real example from last month: generating a featured image for a blog article about festival fashion trends. First attempt came back with an AI evaluation score of 4.2/10 — composition was cluttered, colors clashed, didn't match the brand aesthetic. Second attempt with modified prompt (specific color palette, cleaner composition instructions) scored 7.8/10. Published without human intervention.
The cost tradeoff is clear. Spending an extra $0.03 in AI tokens to evaluate and regenerate an image is cheaper than publishing a bad image that damages brand perception or doesn't convert. And way cheaper than paying a human designer $50 to create every image from scratch.
What I Learned Building This (And What Still Breaks)
Separating evaluation from generation was the key insight that made this work. When I first tried AI quality control, I asked the generation AI to evaluate its own output. Predictably, it graded itself too generously. Everything was "great" or "excellent." No useful signal.
Using a separate evaluation AI with different instructions eliminated that bias. The evaluator doesn't care about defending its work because it didn't create it. It just scores against criteria.
Multi-criteria scoring catches different failure modes that a single "overall quality" score would miss. An article might have perfect grammar and structure (high technical quality score) but make unsupported claims (low accuracy score). The average drops below threshold and it gets rejected, which is correct.
The automatic feedback loop actually improves output quality over time. When the generation AI sees consistent patterns in evaluation feedback — "structure scores keep coming back low because paragraphs are too long" — it adjusts. I've watched average scores drift upward as the system learns what passes evaluation.
But defining "good enough" in quantitative terms remains hard. A 7.0 threshold works for blog content and product descriptions. Customer service responses need higher standards — I use 8.0 minimum there because wrong information damages trust. Creative content for social media might accept 6.5 because originality matters more than polish.
The system can be gamed, theoretically. If the generation AI "learned" the exact evaluation rubric, it could optimize for scoring high without actually improving quality. I haven't seen this happen yet, but I watch for it. The fix would be periodically rotating evaluation criteria or adding randomization.
Edge cases still need human review. The system occasionally passes content that scores well on individual criteria but feels off when you read it as a whole. Or it rejects perfectly good content because the evaluator AI misunderstood context. Maybe 5% of output still gets human eyes before publication.
False positives and false negatives happen. An article might score 7.3 but still have a subtle factual error the evaluator missed. Or score 6.8 and be perfectly fine. The system reduces QA burden by 90%, not 100%.
I'm okay with that tradeoff.
The Real Win: Speed Without Sacrificing Standards
Before I built this QA system, I was the bottleneck. Every piece of AI-generated content needed my review before going live. That meant 15-20 hours weekly spent reading blog drafts, checking product descriptions, reviewing meta tags.
 ROI and Time Savings Breakdown
ROI and Time Savings Breakdown
My hourly rate as CEO is effectively $200 when you divide annual compensation by working hours. So 20 hours of weekly QA cost the business $4,000 in opportunity cost. Monthly: $16,000. Annually: $192,000.
Now automated QA handles first-pass review. Only edge cases escalate to me — about 5% of total output. That's one hour weekly instead of twenty. I saved 19 hours per week, which is 988 hours annually.
At $200/hour opportunity cost, the AI QA system creates $197,600 in annual value. The infrastructure cost to run it is roughly $400/month in API fees ($4,800/year). ROI of 41x.
And that's just time savings. The harder-to-quantify win is consistency. Human review quality varies with my energy level, how busy I am, whether I'm traveling. I might carefully read one article and skim the next. The AI evaluator applies the same standards to every piece of content, every time.
This runs on both the blog pipeline (detailed in my AI blog automation article) and the product description enhancer. Two different content types, same quality control infrastructure. That's the value of building systems instead of one-off solutions.
I could have hired a QA person for $50,000/year to review AI content. They'd be slower than the automated system, apply inconsistent standards, and still miss things. The AI approach scales better and costs less.
Why Most Companies Get AI Quality Control Wrong
The most common mistake: treating AI output as final draft. They generate content with ChatGPT, maybe skim it quickly, and publish. No evaluation, no quality gates, no standards. Then they wonder why their AI-generated blog gets no traffic or their chatbot gives wrong answers.
Second mistake: having no quality control at all until something breaks. They'll use AI for months with no QA, then a customer complains about incorrect information from their chatbot, and suddenly they're scrambling to implement review processes. Reactive instead of proactive.
Third mistake: relying only on human spot-checks. Someone reviews 10% of AI output and assumes the other 90% is fine. But AI failures aren't randomly distributed — certain content types or topics fail more often. Sampling misses systematic problems.
Fourth mistake: using generic quality checks. They'll ask AI "Is this good?" or "Does this make sense?" with no specific criteria. The AI says yes because it has no standards to evaluate against. Garbage in, garbage out.
The mindset shift required: AI quality control isn't about perfection. It's about consistent minimums and catching obvious failures before they reach customers.
A bad AI-generated product description that claims features your product doesn't have will kill conversion and potentially create legal liability. A chatbot confidently giving customers wrong shipping information creates support nightmares. A blog post citing made-up statistics damages your credibility when someone fact-checks.
These failures are preventable with proper QA infrastructure. You don't need every piece of content to be perfect — you need it to meet minimum standards consistently.
Most companies I talk to want to use AI for content, customer service, internal docs, whatever. But they're worried about quality. Rightfully so. They've seen generic AI slop and don't want to publish it under their brand name.
This QA system is the answer to that concern. You can move fast with AI and maintain quality standards. The two aren't mutually exclusive if you build the right infrastructure.
Building Quality Control Into Your AI Systems
If you want to implement something similar, start with these principles:
Separate evaluation from generation. Don't ask the AI to grade its own work. Use a different model or different prompt with different objectives. The evaluator's job is finding problems, not defending output.
Define quality criteria before building. Don't start with "we'll know good content when we see it." Specify exactly what good means: accuracy, relevance, tone, structure, whatever matters for your use case. Make it measurable.
Measure everything. Log all quality scores, track pass/fail rates, monitor which criteria most often cause failures. You can't improve what you don't measure. I have dashboards showing evaluation score distributions over time.
Start strict and loosen later. It's easier to lower quality thresholds if you're being too harsh than to raise them after you've been publishing mediocre content. I started at 7.5 minimum, dropped to 7.0 after seeing the system worked.
What this looks like varies by use case. Customer-facing content needs tighter QA than internal documentation. A product description going on your website should meet higher standards than an internal process note.
Financial or legal content needs human review no matter what. I don't care if the AI scores 10/10 — if it's anything involving money, compliance, or legal risk, a human reads it before publication. AI QA catches obvious errors but can't replace domain expertise in high-stakes areas.
Creative content might have different criteria than technical writing. A social media post optimizing for engagement might accept more informal language and looser structure than a technical guide. Adjust your rubric accordingly.
This is complex infrastructure work, not a weekend project. Building reliable evaluation prompts takes iteration and testing. Setting up automatic feedback loops requires proper error handling. Integrating it into existing content pipelines means understanding your whole system.
I spent about 40 hours building the initial version, then another 60 hours refining evaluation criteria and testing edge cases. Now it runs automatically across multiple content types and rarely breaks.
If you want this level of AI quality control in your systems, let's talk about building it. I've done this once for my own business and I can do it for yours.
Let's talk about building one for your business.
Want to See If AI Can Actually Help Your Business?
If this resonated with you — if you're thinking "we need better quality control on our AI systems" or "we should be using AI but we're worried about output quality" — let's have a conversation.
I do free 30-minute discovery calls where we look at your operations and identify where AI could actually move the needle. No sales pitch, no pressure. Just a real conversation about whether AI makes sense for your specific situation.
Sometimes the answer is "not yet" or "not for that use case." I'll tell you if I don't think AI will help. But if there's a real opportunity to automate processes, improve quality, or save time, I'll explain exactly how it would work.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call