Deterministic AI Architecture: Let the Model Judge, Not Compute
Why I let AI extract facts but never compute numbers. The deterministic AI architecture pattern that prevents hallucinated penalties, deadlines, and cites.
By Mike Hodgen
The Failure That Made the Rule Obvious
A model once handed me a number that was perfectly formatted, completely plausible, and dead wrong.
The context was a personal-injury law firm. The system was supposed to read intake notes and flag how much time was left before the statute of limitations ran out. I made the mistake of letting the model emit a deadline directly, as a clean enum value. It came back confident: a specific number of days remaining. It looked authoritative. It was authoritative-looking the way a forged signature is.
It was off by months.
Here is what made my stomach drop. The output had no tell. No stack trace, no malformed JSON, no "I'm not sure." Just a tidy, well-structured value that any reasonable person would have trusted. In a legal context, a wrong deadline that looks right isn't a bug. It's the kind of thing that ends a case and a firm.
This is the danger nobody warns you about with deterministic ai architecture being absent: a wrong number that looks right is worse than an error message. An error you catch. A confident fabrication you ship.
The model wasn't broken. It was doing exactly what language models do. It pattern-matched its way to something that reads like a deadline and presented it with the same fluency it presents everything. Confabulation isn't a typo. A typo is a slip. Confabulation is the model fulfilling its actual job, which is to produce plausible text, in a place where plausible isn't good enough.
The model is excellent at reading and judging. It is terrible at being trusted with arithmetic. The failure wasn't the model's fault. I had pointed a brilliant reader at a job that needed a calculator.
What Deterministic AI Architecture Actually Means
Deterministic AI architecture is a simple division of labor: the model makes judgments and extracts facts from messy input, and ordinary code does every calculation that has a single correct answer.
That's the whole pattern. It sounds obvious written down. Almost nobody builds this way.
The model's job vs. the code's job
Here's the mental model I draw on a whiteboard before I write a line of anything.
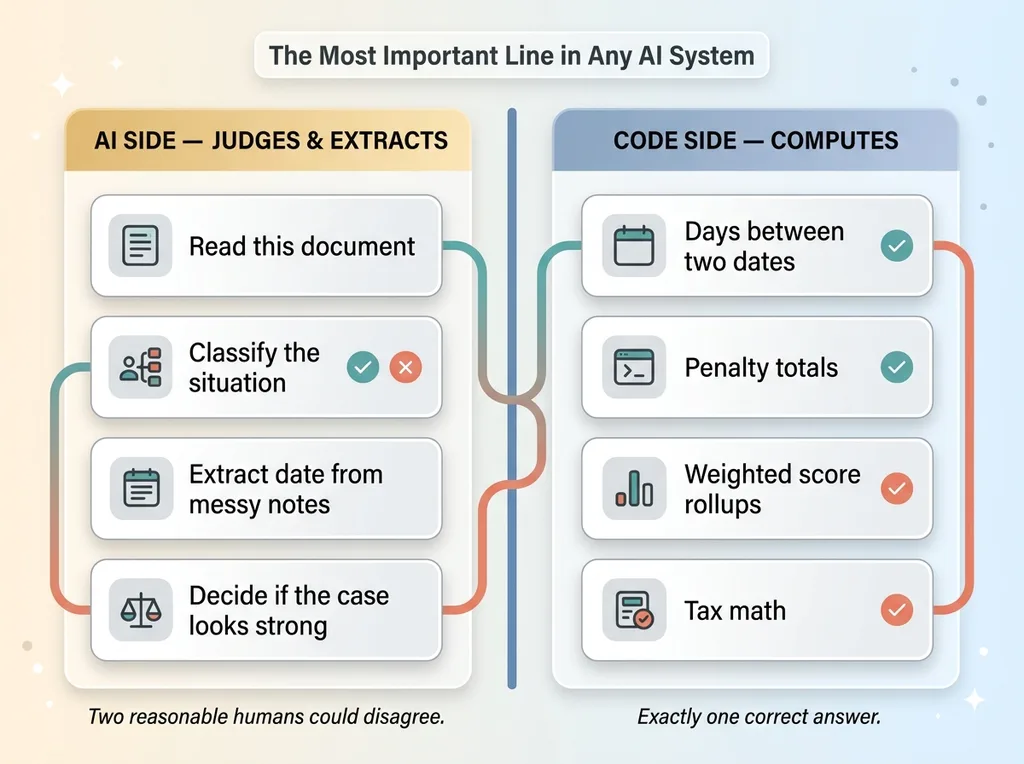 Model judges vs. Code computes division of labor
Model judges vs. Code computes division of labor
AI side: Read this document. Classify this situation. Pull the date someone got hurt out of a paragraph of rambling intake notes. Summarize a transcript. Decide whether this case looks strong. Anything where two reasonable humans could look at the same input and disagree.
Code side: Days between two dates. Penalty totals. Weighted score rollups. Tax math. Anything where there is exactly one correct answer and being wrong has consequences.
The line between those two columns is the most important architectural decision in any serious AI system. I wrote a whole companion piece on how to draw it: let the model judge and let the code compute. If you only internalize one idea from my work, make it that one.
Why 'deterministic' belongs to the math, not the model
The word "deterministic" describes the transport and arithmetic layer. It never describes the model's opinions.
A deterministic system gives the same output for the same input, every time, and you can trace exactly why. Language models are the opposite by design. Temperature, sampling, context drift, model version changes. That variability is a feature when you want creative judgment. It's a catastrophe when you want a number a court will see.
So I never try to make the model deterministic. I wrap it. The model produces facts and judgments. Code turns those into numbers.
This isn't a complaint about today's models. Better models confabulate more convincingly, not less. The discipline holds no matter how good they get, because the problem isn't capability. It's accountability.
Computing Deadlines Without Trusting the Model
Back to that law firm. Here is how I rebuilt the deadline system the right way.
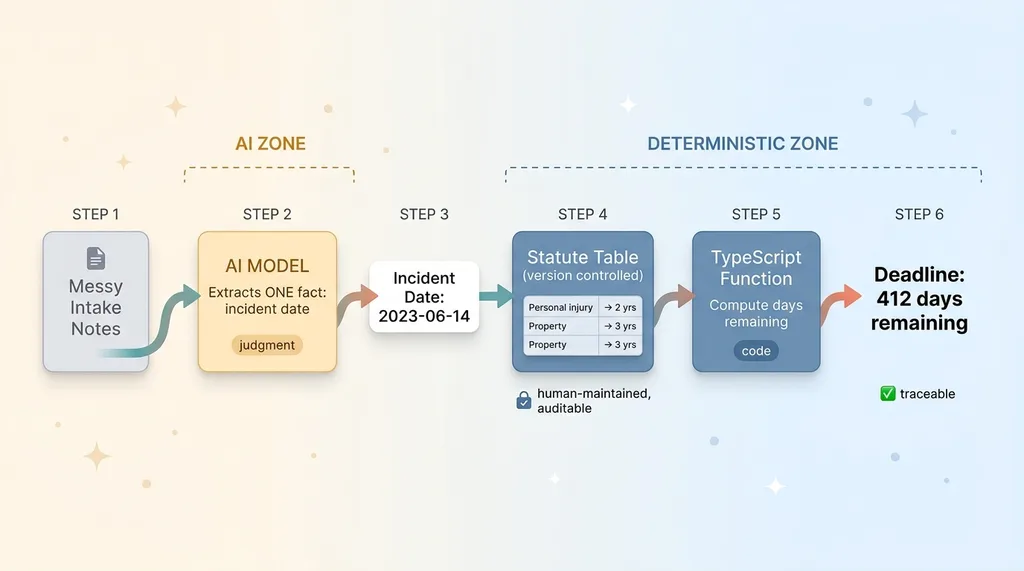 Deadline computation pipeline (extract date, lookup statute, compute days)
Deadline computation pipeline (extract date, lookup statute, compute days)
The wrong way, the way I started, was to ask the model what the statute-of-limitations deadline is. Or worse, let it emit a "days remaining" value directly. That puts the model in charge of two things it should never own: the legal rule and the arithmetic.
The right way uses the model for exactly one thing. It reads the intake and extracts a single fact: the date the incident happened.
That's it. That's all the model does.
That date then feeds a hardcoded statute table, maintained by a human and kept in version control. The table maps case types to their limitation periods. A TypeScript function takes the incident date, looks up the applicable statute, and computes the days remaining. Pure arithmetic over a known rule.
The model never touches the math. It doesn't know the statute. It can't, because it never sees the table.
Why does this matter so much here? Because a hallucinated deadline in a legal context isn't a software defect. It's malpractice exposure. The firm carries that risk, the client lives with the consequence, and the vendor who shipped the system carries the blame.
Splitting the job removes the risk entirely. The captured date is a fact, and extracting facts from messy text is precisely what the model is reliable at. The deadline is arithmetic over a legal rule, and that has to live in code.
There's a second benefit that matters more than people expect. The statute table is auditable. A paralegal can open it and read the rules in plain terms. A partner can verify that the system encodes the law correctly without understanding a single thing about AI. The rule isn't hidden inside a black box. It's a table anyone can check. That's how you get llm hallucination prevention that a non-engineer can actually trust.
Machine-Verifying Every Citation the Model Produces
Same firm, different failure mode. Models fabricate legal citations constantly.
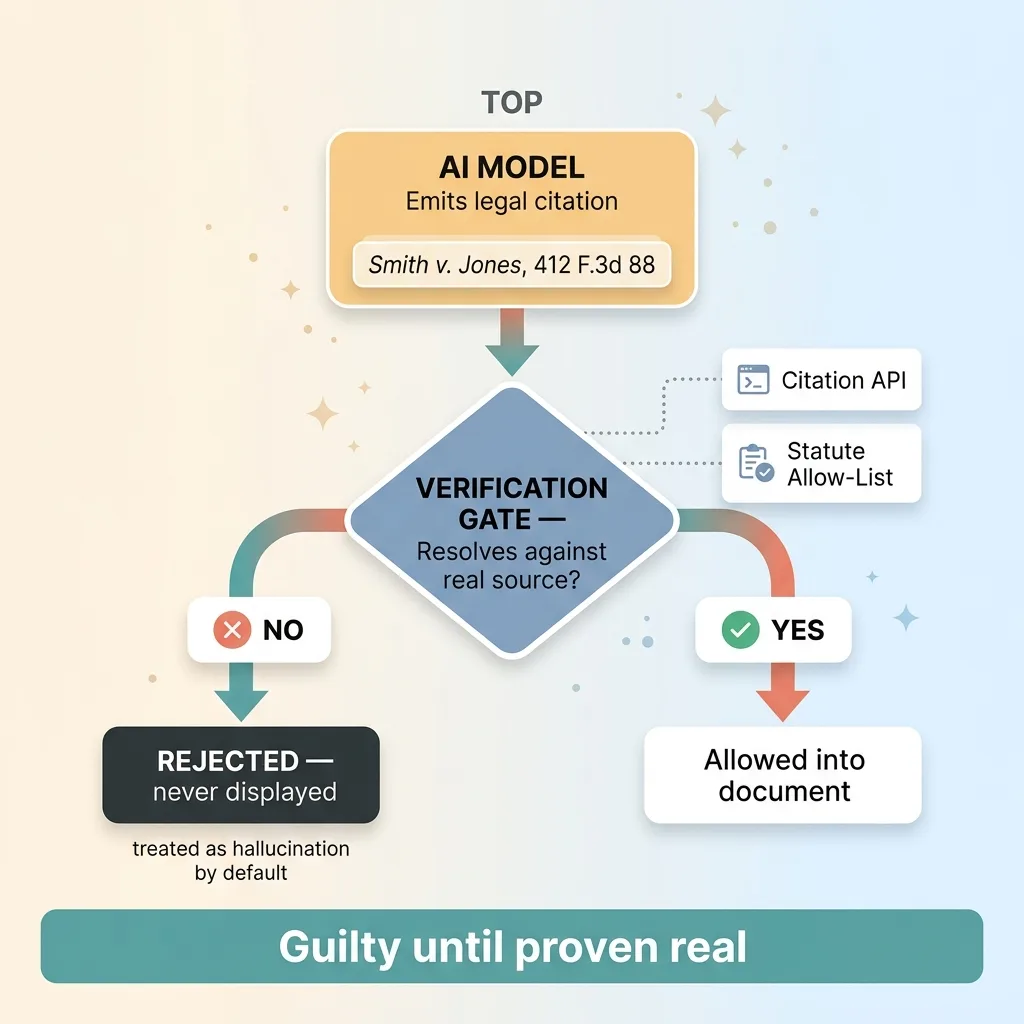 Citation verification gate (guilty until proven real)
Citation verification gate (guilty until proven real)
And they're good at it. A model will produce a case name with the right cadence, a reporter volume that looks legitimate, a statute reference formatted to perfection. Every surface signal says "real." The case doesn't exist. Lawyers have been sanctioned for filing briefs full of these. It's a known, documented disaster.
You cannot solve this by asking the model to be honest. Honesty isn't a setting. The model doesn't know it's lying, because it doesn't know anything. It produces plausible text.
So I built a gate. Every citation the model emits gets machine-verified before it's allowed anywhere near a document or a client. The case name gets checked against a real citation API. Statute references get checked against a maintained allow-list. If a citation doesn't resolve, it isn't flagged with a warning. It's rejected. It never gets displayed.
A citation that can't be verified is treated as a hallucination by default. Guilty until proven real.
This is the same principle I use to keep AI from inventing products in my DTC brand, which I wrote up as lock the AI to a real catalog so it can't invent facts. Different domain, identical move. You don't ask the model to stay inside the lines. You build a wall that makes coloring outside them impossible to ship.
This is what auditable ai systems look like in practice. Every claim the model makes is checkable against an external source of truth, automatically, before a human ever sees it. The model can be as creative as it wants in the draft. Nothing unverified survives the gate.
A Wage-and-Hour Engine Where AI Is Nowhere Near the Math
Here's a case where I kept the model as far from the numbers as possible: a California labor-compliance tool for a labor compliance SaaS client.
California wage-and-hour law is brutal arithmetic. Daily overtime thresholds, meal-period premiums, rest-break penalties, penalty stacking that compounds in specific statutory ways. Every violation maps to an exact dollar consequence defined by law. There is one correct answer for any given timesheet, and the law decides what it is.
Normalize the input, then run hardcoded rules
The model's only job is normalization. Timesheets arrive in a dozen messy formats: exports from different payroll systems, spreadsheets, scanned PDFs, handwritten notes someone typed up. Reading varied, inconsistent formats and turning them into a clean structured record is exactly what models are good at.
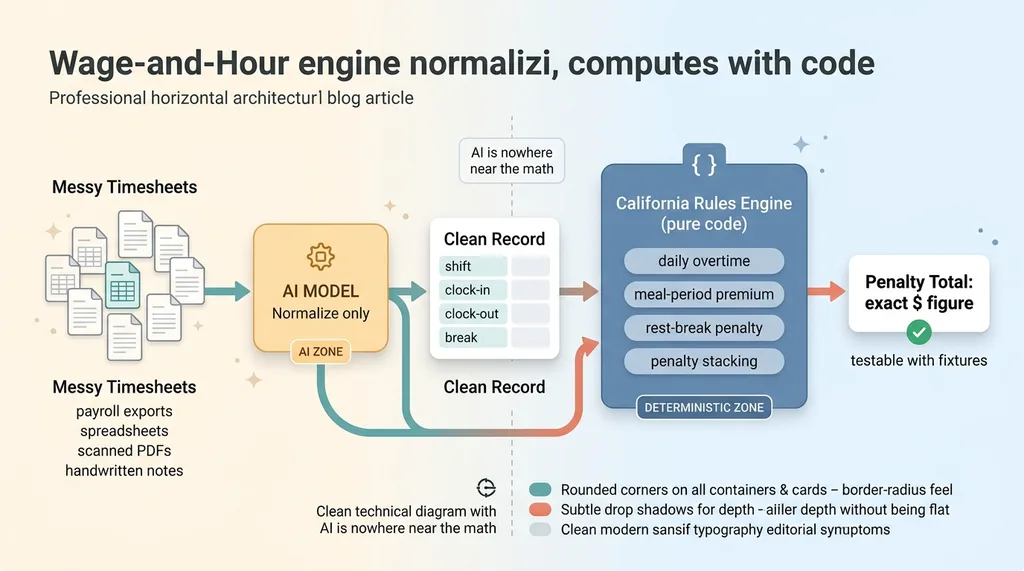 Wage-and-hour engine: normalize with AI, compute with code
Wage-and-hour engine: normalize with AI, compute with code
So the model reads the mess and outputs clean structured data: shifts, clock times, break records. That's where its involvement ends.
Then a deterministic California rules engine runs over that normalized data. It computes every violation and every penalty in plain code, following the statute step by step. The AI is nowhere near the arithmetic.
Why penalties can't be a model's guess
A fabricated penalty number in a compliance product is two disasters at once. It's a liability for the customer, who may act on a wrong figure in a legal proceeding. And it's a credibility death for the vendor, because the entire value of a compliance tool is that the numbers are correct.
You don't get to be approximately right about a penalty calculation. You're right or you're worthless.
This is the same discipline I applied when I built a trading system and deliberately kept AI out of the money-moving math entirely, which I wrote about in I made risk management deterministic and kept AI out of it entirely. When real money or legal liability rides on a number, the model doesn't get a vote.
The other payoff is testability. Because the rules engine is pure code, I can write fixtures with known-correct answers and prove the engine produces them. Feed it a timesheet, assert the exact penalty total. You cannot write a passing test against a model's guess. You can write one against arithmetic you own.
Rolling Up Scores So the Arithmetic Stays Auditable
The intake scorer for that law firm is where the two sides of the line sit side by side, and it makes the principle obvious.
 Auditable score rollup: code-traced vs. model black box
Auditable score rollup: code-traced vs. model black box
The model judges individual factors. Is this a strong case? How severe is the injury? How clear is liability? Those are genuine judgment calls. A senior partner reading the same file might score them differently, and that's fine, because they're opinions informed by experience. The model is standing in for that judgment, and it's reasonable at it.
But the rollup, where individual factor scores get multiplied by weights and summed into a final score, happens in TypeScript. Every time.
Here's why that matters. A partner looks at a case and asks, "why did this score a 72?"
If the math lives in code, I can show the exact arithmetic. This factor scored a 4, weighted at 0.3, contributing 1.2 to the total, and here are the other eleven, and here's the sum. The number is defensible line by line.
If the model did the math, the only honest answer is "the model said so." That's unauditable. It's also unfixable, because if the number's wrong, there's no specific step to correct. You're back to praying the next model version does better.
This is the broader rule, and it's the test I use to decide which side of the line any task belongs on: anywhere a human will need to explain or defend a number, that number must come from code you can trace.
Auditability isn't a nice-to-have feature you add later. It's the question that tells you where the model stops and the code starts.
Why This Answers the Skeptical CEO, Not Just the Engineer
If you're a CEO who's said "AI is too unreliable for high-stakes numbers," you're right about the risk and wrong about the conclusion.
You're right that a model confidently emitting a wrong penalty total or a wrong deadline is a real, serious danger. I've watched it happen. Your instinct to distrust that is correct, and it's exactly the instinct I wrote about in the skeptical CEO is usually right about AI hype.
But the answer was never to avoid AI. The answer is to architect it so it only does the work it's reliable at. Reading. Judging. Extracting. And never the work where being confidently wrong is catastrophic.
Deterministic AI architecture is the thing that turns "AI is too risky for this" into "AI is safe here, because the math is mine." The model reads the intake. My code computes the deadline. The model normalizes the timesheet. My code calculates the penalty. The model judges the factors. My code does the rollup. At no point is a number that matters left to a guess.
That's the difference between knowing when not to use ai and refusing to use it at all. The skill isn't picking a side. It's drawing the line in the right place.
Most vendors who burned you did the opposite. They let the model compute, shipped well-formed wrong answers, and called it innovation. The output demoed beautifully. Then a number was wrong in a way nobody caught until it cost something.
When I build a system, that line between judgment and arithmetic is the first thing I draw. Before the prompts, before the model selection, before any of it. Because if you get that line wrong, nothing downstream can save you.
Thinking about AI for your business?
If this resonated, let's have a conversation. I do free 30-minute discovery calls where we look at your operations and figure out where AI could actually move the needle, and just as importantly, where it can't be trusted near the math.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call