I Built an 8-Agent AI Trading Bot. Here's What I Learned.
I built a multi-agent AI trading bot with 8 specialized agents — Grok sentiment, Bayesian learning, prediction markets, and stat-arb — running 24/7 on paper. The bugs I found would have lost real money.
By Mike Hodgen
I run a fashion brand. We make festival apparel by hand in San Diego. So when I tell you I built an 8-agent AI trading system that watches crypto markets 24/7, the reasonable question is: why?
The answer has nothing to do with getting rich off crypto. It has everything to do with pressure-testing the multi-agent AI systems I build for a living.
I wanted the hardest possible environment to validate my architecture patterns. Trading gives you that. When your autonomous system makes a bad decision in an e-commerce pipeline, you find out in a quarterly report. When an AI trading bot makes a bad decision, you find out in seconds — measured in dollars. That kind of immediate, brutal feedback is exactly what I needed.
Here's the setup: Alpaca paper trading account, $100k in simulated capital, trading BTC/ETH/SOL around the clock. Eight specialized AI agents coordinating through an async signal bus — five core agents handling the trading pipeline, plus three intelligence agents pulling sentiment from X, regime signals from prediction markets, and statistical arbitrage from cross-asset correlations. The system learns which of its own signals actually predict price moves using Bayesian probability. Built it. Running 24/7 since.
I need to be clear upfront: this is a paper trading system. Simulated money. This is not financial advice, not a crypto pitch, not a get-rich-quick story. It's an architecture story — about what happens when you design autonomous AI systems that need to make high-stakes decisions without a human in the loop.
And the bugs I found? They're the real reason I'm writing this.
The Architecture: 8 Agents Modeled After a Quant Hedge Fund
The design principle is simple: model the system after how a real quant fund organizes its people. Each agent has one job, clear boundaries, and a specific mandate. This is the same philosophy behind why I use multiple specialized AI models instead of one — generalists underperform specialists in every domain I've tested.
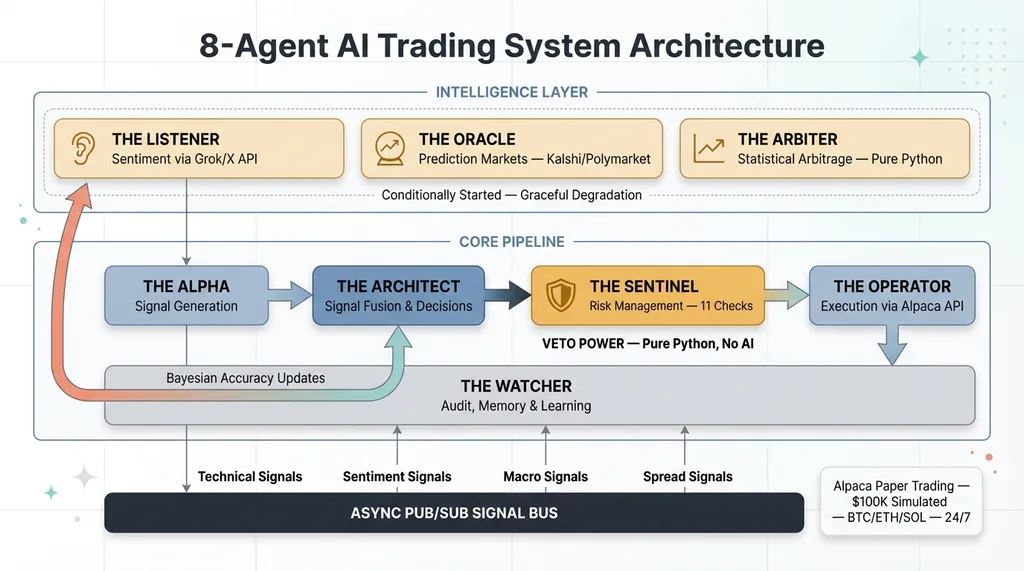 8-Agent Trading System Architecture
8-Agent Trading System Architecture
The Core Pipeline (5 Agents)
The Alpha — signal generation. Runs technical analysis across multiple timeframes (1-minute, 5-minute, 15-minute) and detects market regime — trending, ranging, or volatile with separate confidence scoring. It doesn't make trade decisions. It generates conviction-weighted signals: "BTC is showing a bullish crossover on the 5-minute with 73% conviction in a trending/high-volatility regime, confirmed across all three timeframes." Raw material for the decision-maker.
The Architect — signal fusion. This is where judgment lives. Takes signals from all four sources — technical, sentiment, prediction markets, and spread analysis — and makes the actual trade/no-trade call. Requires confluence from at least two signal sources before entering any position. During risk-off macro regimes, the bar goes up to three of four sources agreeing. During a crisis? All longs are vetoed automatically.
The Sentinel — risk management. Eleven independent safety checks with absolute veto power over any trade. Position limits, correlation exposure, drawdown circuits, market hours enforcement for equities, forward risk modeling — and it doesn't use a single line of AI. More on this in a moment, because the design choice here is the most important one in the entire system.
The Operator — execution. Talks to the Alpaca API, places bracket orders, manages trailing stops. Pure execution, zero decision-making.
The Watcher — audit, memory, and learning feedback. Logs every signal, every decision, every veto. Tracks performance, scores signal quality with 15-minute delayed evaluation, and feeds Bayesian accuracy updates back to the sentiment agent. The data layer that lets me diagnose what's working and what isn't — per agent, per signal type, per symbol.
The Intelligence Layer (3 Agents)
These agents are conditionally started — if the API keys aren't configured, the system runs without them. Graceful degradation, not hard dependencies.
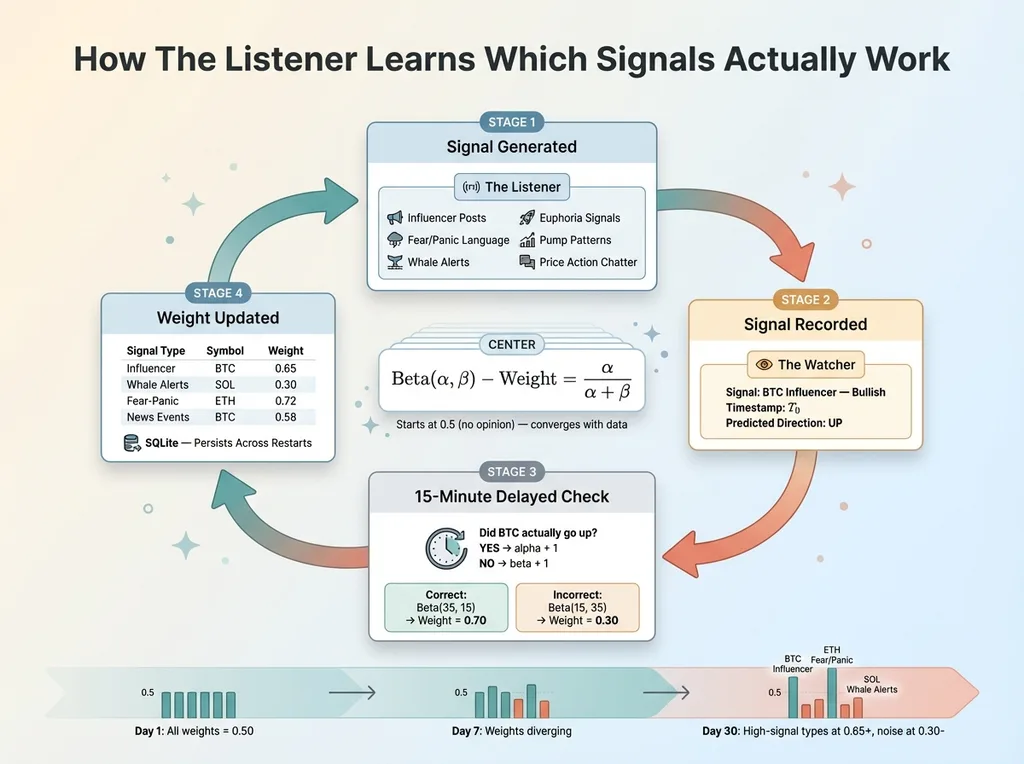 Bayesian Learning Feedback Loop
Bayesian Learning Feedback Loop
The Listener — Grok-powered sentiment intelligence. Polls X every five minutes using the xAI API with seven targeted query templates per symbol — not just "$BTC" but specific searches for price action chatter, influencer posts, fear/panic language, euphoria signals, regulatory news, whale alerts, and coordinated pump patterns. Grok analyzes the raw social data and extracts a sentiment score, confidence level, and key themes.
But here's the part I'm most proud of: The Listener learns which of its own signals actually predict price moves.
Each sentiment reading gets tagged with a sub-signal type (influencer signal, fear/panic, news event, etc.). The Watcher records what the signal predicted, then checks 15 minutes later whether the price actually moved in that direction. Those outcomes feed back into a Bayesian Beta-distribution tracker — one per signal type per symbol — that adjusts the weight of each signal over time.
The math is clean: Beta(alpha, beta) where alpha counts correct predictions and beta counts incorrect ones. Weight = alpha / (alpha + beta). Starts at 0.5 (uniform prior, no opinion). After 50 signals, if "influencer posts about BTC" predicted direction correctly 65% of the time, its weight rises to 0.65. If "whale alerts for SOL" was wrong 70% of the time, its weight drops to 0.30 and gets progressively ignored.
The distributions persist to SQLite, so the learning survives restarts. The system gets smarter every day it runs.
The Oracle — prediction market regime detection. Polls Kalshi and Polymarket every five minutes, tracking probability movements across economics, crypto, politics, and regulatory markets. The key insight: the absolute probability of a market doesn't matter much. What matters is dp/dt — the rate of change. A prediction market moving from 30% to 45% in an hour is a signal. Sitting at 45% for a week is noise.
The Oracle detects three things:
- Regime shifts — when aggregated prediction market sentiment tips from neutral to risk-on, risk-off, or crisis
- Crisis events — two or more markets spiking more than 10 percentage points simultaneously
- Platform divergences — when Kalshi and Polymarket disagree on the same event by more than 15 points, which historically signals an information asymmetry worth watching
It uses Grok's web search for macro news context, then classifies the current regime with both an LLM assessment and a deterministic fallback. The regime feeds directly into The Architect's confluence gate.
The Arbiter — pure Python statistical arbitrage. No AI, no LLM, no API calls. Monitors the correlation between every pair of watched assets (BTC/ETH, BTC/SOL, ETH/SOL), computes a rolling spread z-score using log price ratios, and emits a mean-reversion signal when the z-score exceeds 2.0 standard deviations.
When BTC and ETH historically move together with 0.85 correlation but suddenly diverge — one rallies while the other doesn't follow — the Arbiter flags it. The spread tends to revert. It's one of the oldest edges in quantitative finance, and it requires zero machine learning to detect.
How the Agents Communicate
The backbone is an async pub/sub signal bus with typed channels. The Alpha publishes technical signals. The Listener publishes sentiment signals. The Oracle publishes macro signals. The Arbiter publishes spread signals. The Architect subscribes to all four and publishes trade decisions. The Sentinel subscribes to trade decisions and publishes approvals or vetoes. The Operator subscribes to approved trades only.
This matters more than it sounds. In a synchronous system, each step waits for the previous one to complete. With async pub/sub, signals flow naturally. The system processes multiple signal sources simultaneously without bottlenecks. A sentiment signal from The Listener can arrive and get fused with a technical signal from The Alpha in the same decision cycle.
It's the same pattern I used when I built a full CRM in a single session — separate concerns, let components communicate through clean interfaces, and you get a system that's both fast and debuggable.
Multi-Source Confluence: Why More Signals Beat Better Signals
Here's an insight from actually running this system: the number of independent signal sources that agree matters more than the quality of any single signal.
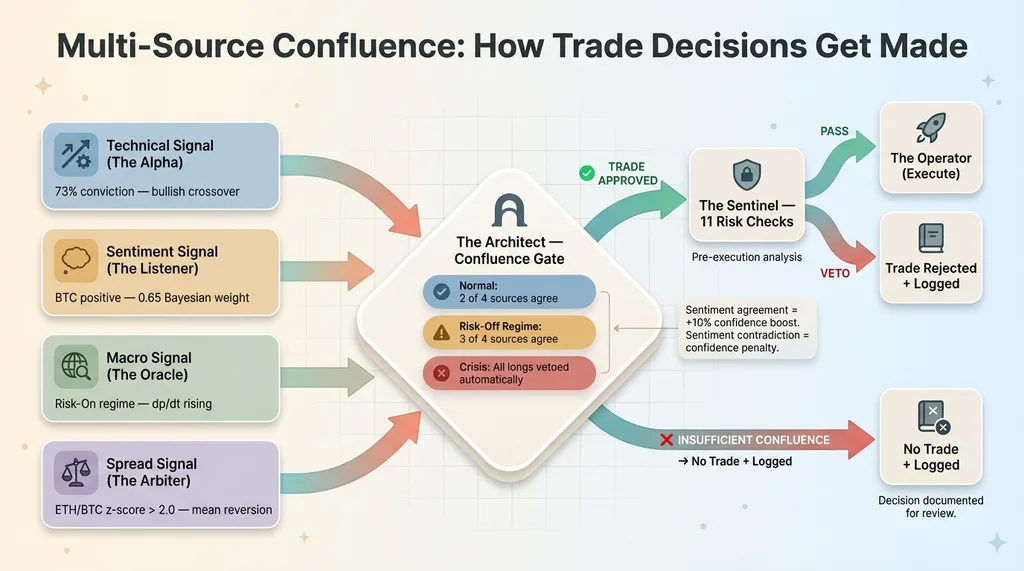 Async Signal Flow and Confluence Gate
Async Signal Flow and Confluence Gate
The Architect's confluence gate requires at least 2 of 4 sources (technical, sentiment, macro, spread) to agree on direction before entering a trade. During risk-off regimes from The Oracle, that threshold jumps to 3 of 4. During a crisis classification, all long entries are automatically vetoed regardless of how many sources agree.
When sentiment aligns with the technical signal, the Architect boosts confidence by 10%. When they contradict, confidence gets penalized. This isn't just weighting — it's information theory. Independent confirming signals multiplicatively reduce the probability of a false positive.
The Bayesian learning loop makes this even more powerful over time. As The Listener learns which sentiment sub-signals are actually predictive for each symbol, the garbage signals get down-weighted and the confluence calculation gets cleaner. The system doesn't just fuse signals — it learns which signals deserve to be fused.
Why Deterministic Safety Beats AI for Risk
Here's the design decision I feel strongest about: The Sentinel is pure Python. No LLM. No AI. No machine learning. Every risk check is deterministic — hard-coded rules that execute identically every single time.
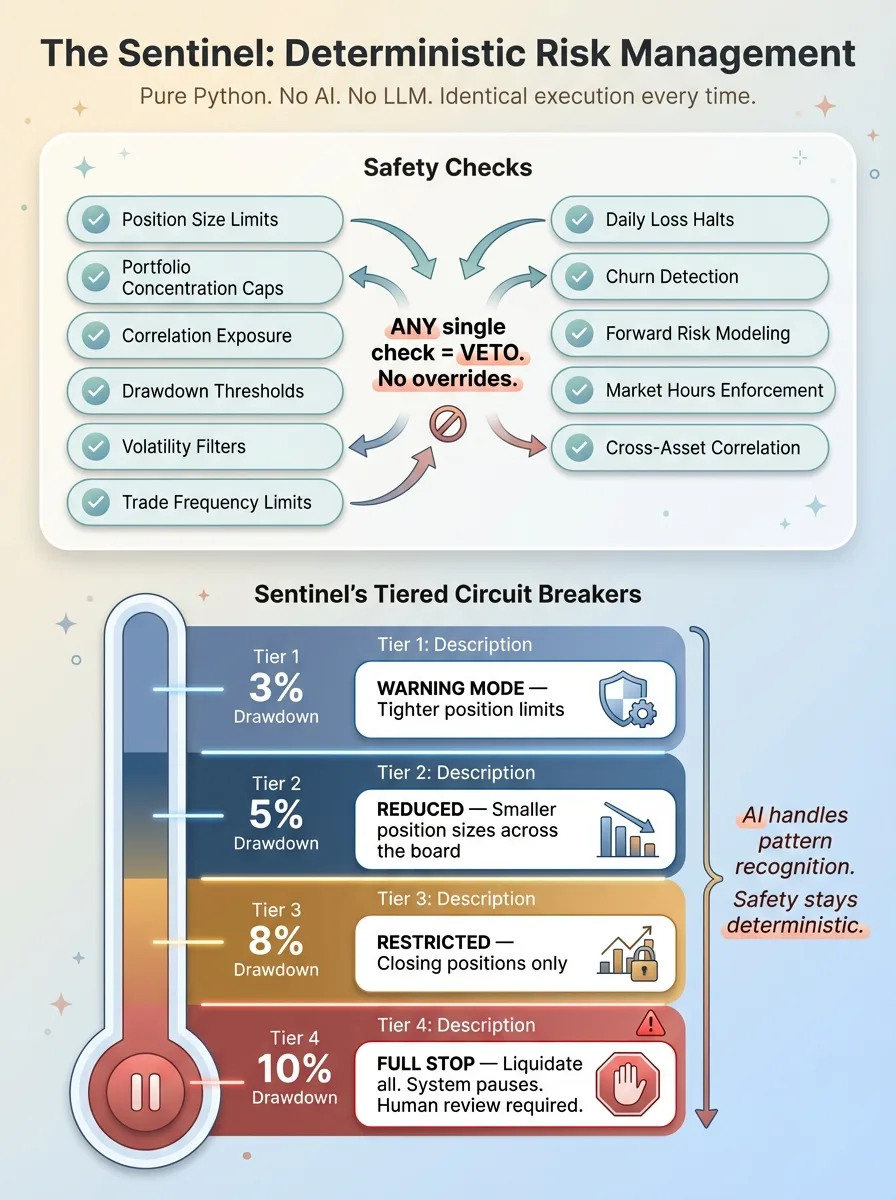 Deterministic Safety: Sentinel's Tiered Circuit Breakers
Deterministic Safety: Sentinel's Tiered Circuit Breakers
Why? Because you never, ever want a language model getting creative about whether to cut a losing position.
The Sentinel runs 11 independent checks on every proposed trade: position size limits, portfolio concentration caps, correlation exposure, drawdown thresholds, volatility filters, trade frequency limits, daily loss halts, churn detection, forward risk modeling, market hours enforcement for stocks, and cross-asset correlation analysis. Any single check can veto a trade. No overrides.
The circuit breakers are tiered:
- 3% portfolio drawdown: warning mode, tighter position limits
- 5% drawdown: reduced position sizes across the board
- 8% drawdown: restricted to closing positions only
- 10% drawdown: full liquidation, system pauses, human review required
This same principle applies to every autonomous system I build. AI handles pattern recognition, creative synthesis, signal detection — the fuzzy work it's genuinely good at. But the parts that protect you from catastrophic failure? Those stay deterministic. I've written about this pattern in the context of AI systems that reject their own bad work. The Sentinel is the trading version of that same architecture.
5 Bugs That Would Have Lost Real Money
This is the section that matters most. Building the system took a few sessions. Finding the bugs that would have been invisible in a demo but devastating with real money — that's the actual work.
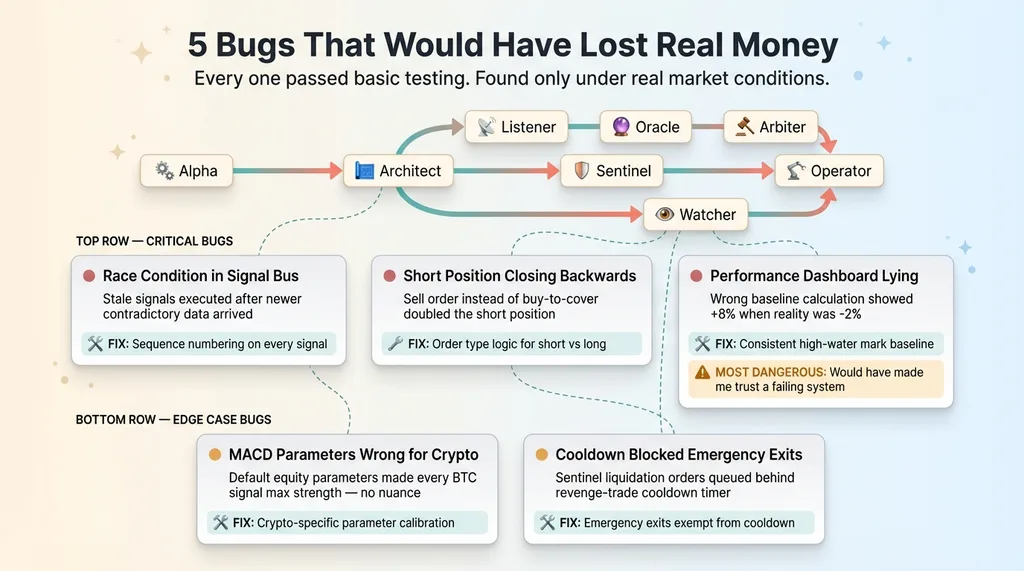 5 Critical Bugs and Where They Lived
5 Critical Bugs and Where They Lived
The 3 Critical Bugs
Bug 1: Race condition in the signal bus. Under fast market conditions, The Architect would receive a signal from The Alpha, make a trade decision, and send it to The Operator for execution. But between the decision and the execution, a newer contradictory signal would arrive. The Operator would execute the stale trade — sometimes in the exact wrong direction.
The fix was sequence numbering on every signal. The Operator now checks that the signal ID it's executing matches the latest signal ID from The Architect. Stale signals get rejected. Simple once you find it. Hard to find when the market is moving slowly in testing.
Bug 2: Short position closing was backwards. When The Operator tried to close a short position, it was sending a sell order instead of a buy-to-cover. This didn't close the short — it doubled it. In a rally, this would have been catastrophic. Your system thinks it's reducing risk while it's actually doubling down in the wrong direction.
This one makes you feel stupid when you find it. The code looked right at a glance. It passed basic testing because the test cases were all long positions. The first time the system went short on ETH and tried to close, I saw the position size jump from -2 to -4 instead of going to zero.
Bug 3: The Watcher was lying about performance. The performance dashboard was calculating returns against the wrong baseline — using the initial portfolio value instead of the rolling high-water mark for some metrics and vice versa for others. The result: phantom profits. The dashboard showed +8% when reality was -2%.
This is arguably the most dangerous bug of the three. The other two would have lost money in obvious ways. This one would have made me believe the system was working while it quietly bled. I'd have kept it running, maybe even moved to real money, based on fabricated results.
The 2 Edge Cases That Would Have Bled Slowly
Edge Bug 1: MACD signals on BTC were permanently maxed out. The default MACD parameters (12, 26, 9) were designed for equities. BTC's volatility range is an entirely different beast. Every signal from The Alpha was either "strong buy" or "strong sell" — never a moderate read. The Alpha was effectively screaming at The Architect all day with no nuance, which meant the conviction weighting was meaningless.
The fix was crypto-specific parameter calibration. Wider windows, adjusted thresholds. The kind of thing that seems obvious in hindsight but doesn't show up until you actually look at the signal distribution instead of just the trade output.
Edge Bug 2: Cooldown timer blocked emergency exits. After a losing trade, The Operator enters a cooldown period to prevent revenge trading — a good idea in principle. But the implementation didn't exempt Sentinel-triggered emergency liquidations. If The Sentinel needed to dump everything during a crash but The Operator was in cooldown from the previous loss, the liquidation order would queue behind the timer instead of firing immediately.
In a flash crash, minutes matter. A queued emergency exit is worse than no emergency exit at all because you think you have protection that isn't actually functioning.
The lesson across all five: every one of these bugs passed basic testing. They only appeared under specific market conditions, timing edge cases, or when I looked at the actual data distributions instead of spot-checking outputs. This is why paper trading exists. It's why I run any autonomous system — trading or business — in simulation with real data before it touches anything that matters.
What I'm Measuring (And Why Most Trading Bots Skip This)
Most people build a bot and stare at P&L. That tells you almost nothing about whether the system is working or just riding a lucky streak.
Here's my measurement framework:
- Win rate: target >45%. You don't need to win most trades. You need your winners to be bigger than your losers. A 40% win rate with a 3:1 reward-to-risk ratio is extremely profitable.
- Profit factor: target >1.3. Gross profits divided by gross losses. Below 1.0, you're losing money. At 1.3, you're generating $1.30 for every $1.00 lost.
- Sharpe ratio: target >1.0. Risk-adjusted returns. A high return with wild swings is worse than a moderate return with consistency.
- Signal accuracy: target >50%. Did each agent's signals predict direction correctly, independent of whether we acted on them? This isolates signal quality from execution quality — and the Bayesian tracker gives me this per signal type, per symbol, automatically.
- Max drawdown: hard ceiling at 10%. The kill switch. Non-negotiable.
The Watcher tracks all of this continuously and scores each agent's contribution independently. If The Alpha is generating great signals but The Architect is fusing them poorly, the data shows it. If The Sentinel is vetoing too many winning trades, I can see the cost of false negatives. If The Listener's sentiment signals for SOL are noise but its BTC signals are gold, the Bayesian weights reflect that within days.
This agent-level attribution is something I apply to every multi-agent system I build. You need to know which component is underperforming, not just whether the whole system output looks acceptable.
The Proof: Modularity Actually Works
When I first wrote about this system, the three intelligence agents — The Listener, The Oracle, and The Arbiter — were planned but not built. The Phase 2/3 roadmap existed. The signal bus channels were defined. The Pydantic models were written. But the agents weren't wired up.
Adding all three took a single session. Zero changes to the existing five agents' core logic.
The Architect already had a _cache_signal() method that stored signals by source key. It was caching technical signals from The Alpha. When The Listener started publishing sentiment signals and The Oracle started publishing macro signals, The Architect cached them exactly the same way. The confluence gate already had slots for "sentiment" and "macro" — they just started getting filled.
The Sentinel didn't need to change at all. It doesn't care where a trade decision came from. It runs its 11 checks regardless.
The Operator didn't change. The Watcher needed a small addition — the Bayesian update callback — but its core signal-tracking and performance-measurement logic was untouched.
This is what good agent architecture buys you: extensibility without rewrites. The pub/sub bus, the typed signal models, the clear agent boundaries — these aren't academic design patterns. They're what let you go from 5 agents to 8 without breaking anything that was already working. I've seen the same pattern pay off in business automation: the cost of adding capability to a well-architected system is a fraction of adding it to a monolith.
What a Trading Bot Teaches You About Any AI System
Here's where this becomes relevant whether or not you care about trading.
Agent boundaries matter. When each agent has one clear job, bugs are findable and fixable. The short-closing bug was in The Operator. The phantom profit bug was in The Watcher. I could isolate, fix, and redeploy each one without touching the rest of the system. When agents blur responsibilities, failures cascade invisibly and you're debugging the whole system instead of one component.
Keep safety deterministic. Whether it's risk management in trading or data validation in a business pipeline, the parts that protect you from catastrophic failure should never be probabilistic. A language model should never decide whether to enforce a business rule. It can recommend, it can flag, but the enforcement layer needs to be code that runs the same way every time.
Let the system learn what works. The Bayesian feedback loop between The Watcher and The Listener is the pattern I'm most excited about. Instead of hand-tuning signal weights, the system discovers which signals are predictive and adjusts automatically. This same approach applies to any multi-agent business system: track which agent outputs actually drive good outcomes, and let the weights evolve.
Paper trade everything. In business terms: simulate, test with real data, run in shadow mode before going live. All five bugs I found passed basic testing. They would have been invisible in a demo. They would have cost real money in production.
Measure each agent, not just the output. If your AI content system produces a bad article, is it the research agent, the writing agent, or the editing agent? Without per-agent metrics, you're guessing. With them, you're diagnosing.
Design for evolution. The pub/sub architecture means I can add new agents without rewriting existing ones. I proved this by going from 5 to 8 agents in a single session. Same principle applies to business systems — build modular, or rebuild constantly.
These are the exact architecture principles I apply when building AI systems for businesses. The trading bot is a 24/7 stress test of the same patterns that drove +38% revenue per employee and 3,000+ hours saved annually at my DTC fashion brand. The domain is different. The architecture is the same. The rigor is the same.
If you're building multi-agent AI systems or thinking about autonomous AI for your operations, this is the kind of architecture work I do.
Thinking About AI for Your Business?
If any of this resonated — the architecture patterns, the agent design, the Bayesian learning, the obsession with testing before deploying — I'd enjoy the conversation. I do free 30-minute discovery calls where we look at your actual operations and figure out where AI can move the needle. Not a sales pitch. Just an honest look at what's possible.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call