AI Compliance False Positives: Regex First, Model Second
How I cut AI compliance false positives to zero with a deterministic regex pre-scan that feeds suspects to an LLM for in-context judgment.
By Mike Hodgen
The First Compliance Scan Embarrassed Itself
A financial advisory firm came to me with a problem that sounds simple until you try to solve it. Their website copy has to satisfy a strict broker-dealer rulebook. Wrong claim, wrong title next to a name, missing disclosure, and you are not looking at a typo. You are looking at a regulatory liability.
So I built a scanner. The first version was the obvious version: feed the page to an LLM, ask it to flag violations against the rulebook. Clean, fast, impressive in a demo.
It embarrassed itself on the first run.
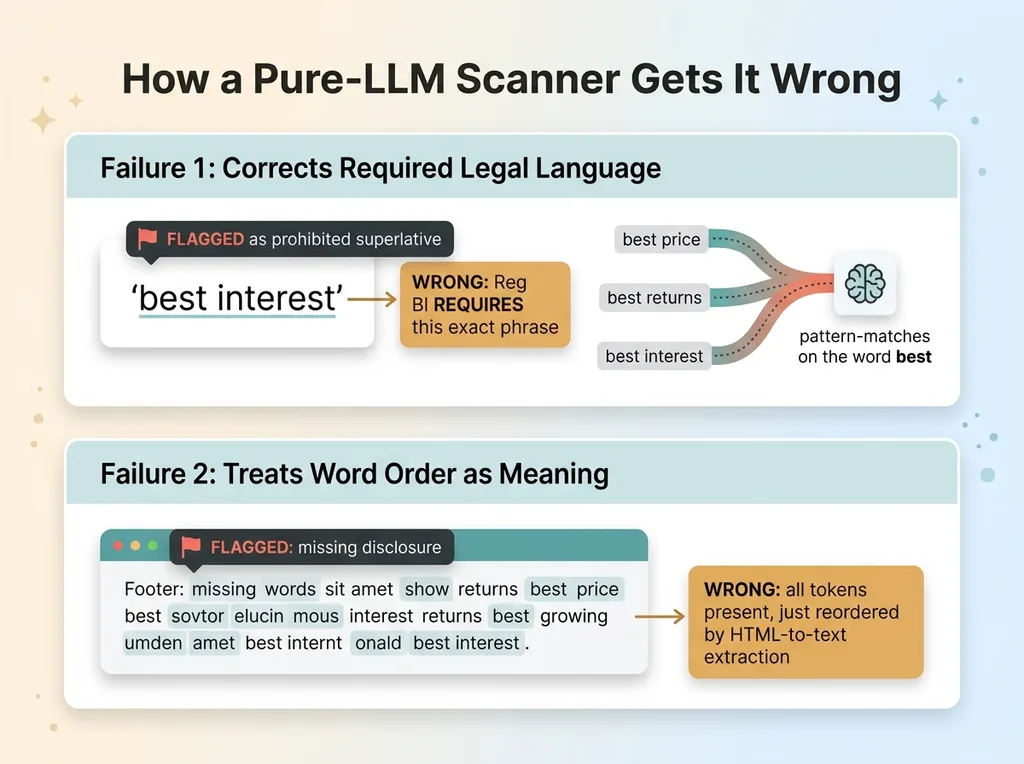
It flagged "best interest" as a prohibited marketing superlative. Except "best interest" is not a superlative. It is a required Reg BI phrase. The model saw "best" and pattern-matched it to "best price" and "best returns" and waved the flag.
Then it called the page footer "garbled" and reported a missing disclosure. The disclosure was not missing. The HTML-to-text extraction had reordered the words during parsing, and the model judged the text by reading order. Everything was there, just out of sequence.
Two findings on the first run. Both wrong.
The owner's reaction was the right one: if it gets the obvious stuff wrong, why would I trust it on the subtle stuff? That is the doubt this whole article answers, and it is the doubt every CEO should have about AI compliance false positives.
Here is the thesis up front. A pure-LLM scanner is unreliable in both directions. It hallucinates violations that are not there, and it skates past the subtle ones that are. You do not fix that with a better prompt. You fix it with a different architecture: deterministic code first, model second.
Let me show you why the pure-LLM approach fails, then how the fix actually works.
Why a Pure-LLM Scanner Produces False Positives
 Pure-LLM scanner failure modes (the two false positives)
Pure-LLM scanner failure modes (the two false positives)
It "corrects" required legal language
The model pattern-matches on surface features. "Best interest" looks like a marketing superlative because the word "best" carries that signal in most training data. The model has seen ten thousand "best price" claims flagged as puffery, so it flags "best interest" too.
It does not know that Reg BI requires that exact phrase. It does not know the difference between a banned superlative and a mandated regulatory term, because nothing in the request told it. You handed a judgment engine a detection job, and it got creative in exactly the place you needed it boring.
This is the dangerous failure mode. The model is not just missing things. It is actively flagging correct, required language as violations. It is "correcting" the law.
It treats word order as meaning
The garbled footer was the second failure, and it is sneakier. HTML-to-text extraction reorders words. Nav elements, hidden spans, and CSS-positioned blocks all get flattened into a token stream that does not match reading order.
The required disclosure was fully present. Every token was there. But the model judged presence by sequence, decided the words were scrambled, and reported a missing disclosure that was sitting right in front of it.
Here is the broader point that took me a few systems to fully internalize. An LLM is a judgment engine, not a detection engine. Ask it to detect known, fixed patterns and it will improvise where you need determinism.
And the cost is not abstract. Every false positive erodes trust. A compliance scanner that flags correct language two times on its first run is a scanner the owner stops using by the second week. AI compliance false positives are not a quality metric. They are an adoption killer. A tool nobody trusts gets turned off, and then you are back to a junior associate reading every page by hand.
The Fix: A Deterministic Pre-Scan That Surfaces Suspects
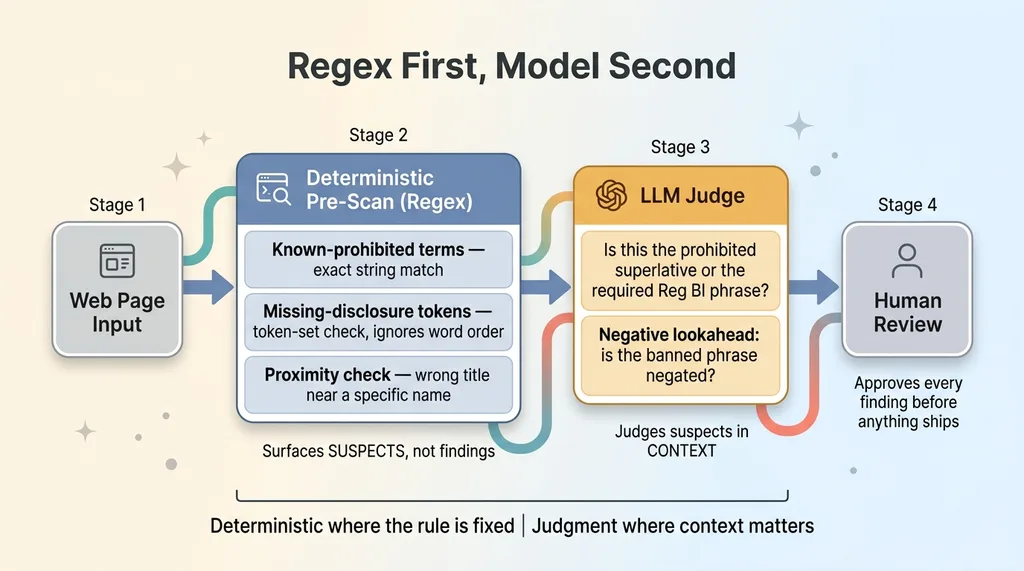
The fix is a regex plus LLM pattern. A deterministic pre-scan runs first and does the cataloging the model is bad at. It does three jobs.
 Regex-first, model-second architecture pipeline
Regex-first, model-second architecture pipeline
Known-prohibited terms
The rulebook has a finite list of banned terms and phrases. Specific superlatives, guarantee language, prohibited titles. Regex catches those with exact matches and zero interpretation. No "maybe this counts as a superlative." Either the literal string is on the page or it is not.
This is the part the model kept getting wrong, and it is the part that has a fixed answer. Fixed answer, deterministic code. No judgment required.
Missing-disclosure tokens
The pre-scan checks whether each required disclosure is present by token, not by word order. It looks for the set of tokens that make up the disclosure anywhere in the extracted text.
This is what kills the garbled-footer class of false positive at the detection layer. A reordered footer still contains all its tokens, so the token check passes even when the reading order is scrambled.
A proximity check the model can't fake
This is the one that earns its keep. A wrong professional title sitting next to a specific person's name is a violation, even when the correct title appears correctly somewhere else on the page.
 The proximity check (wrong title next to a name)
The proximity check (wrong title next to a name)
Pure presence-checking misses this completely. If "Investment Adviser Representative" appears correctly in the team bio, a naive scan sees the correct title present and moves on. Meanwhile the homepage calls the same person a "Financial Advisor" right next to their name, and that is the violation.
The proximity check ties the suspect term to the entity it modifies. Wrong title within N tokens of this specific name. That binds the finding to context that simple presence-checking throws away.
Now the critical design decision. The pre-scan does not emit findings. It surfaces suspects. Each hit comes through as "pattern matched here, evaluate in context" and gets handed to the model. Deterministic where the rule is fixed, judgment where context matters. This is the same division I wrote about in let the model judge, let the code compute, and it is the backbone of every reliable system I build.
Why the Model Still Makes the Final Call
Regex surfaces suspects. It cannot judge them. That is why the model is still in the pipeline, just in a different seat.
When the pre-scan flags "best interest," it does not declare a violation. It hands the model a pattern hit and asks the real question: is this the prohibited superlative, or the required Reg BI phrase? That is a context call, and context is exactly what the model is good at.
Token presence over word order
For the footer, the model receives the disclosure tokens the pre-scan found and judges presence independent of sequence. All tokens accounted for, disclosure present, no finding. The scrambled reading order is no longer the deciding factor because the deterministic layer already confirmed the tokens exist.
Negative lookahead so a disclosure can't trip its own rule
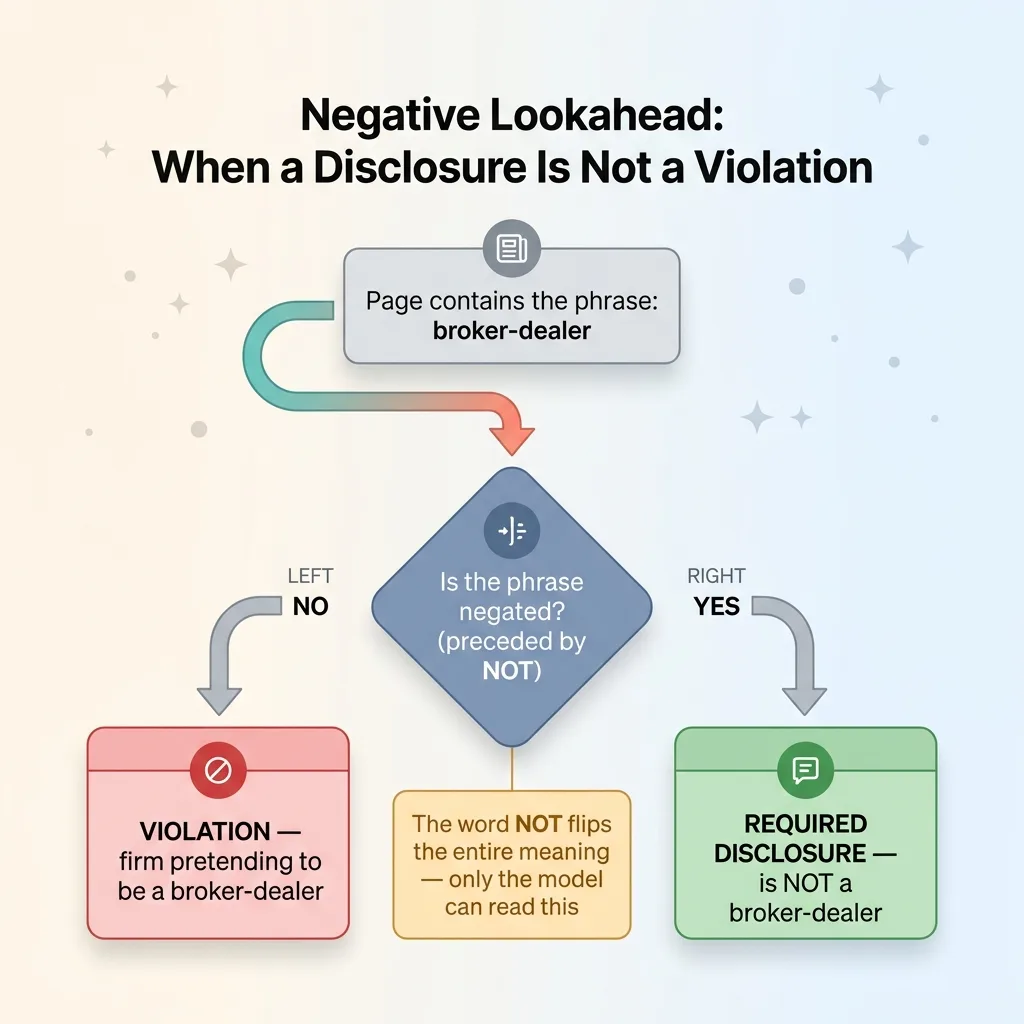
This is the sharpest example in the whole system. One rule says the firm must not pretend to be a broker-dealer. A naive scan trips on the required disclosure "is NOT a broker-dealer," because that text contains the exact banned phrase "broker-dealer."
 Negative-lookahead disclosure logic
Negative-lookahead disclosure logic
The model applies negative-lookahead logic. If the phrase is negated, it is the required disclosure, not a violation. The presence of "NOT" before the phrase flips the entire meaning, and the model is the only component that can read that.
Only after passing this judgment does the model write a finding. That is the division. Deterministic code raises its hand and says "look here." The model decides whether to act. This is also why I lock the model to the firm's approved language so it cannot invent or "fix" required phrases, which I broke down in constraining what the AI is allowed to claim.
Two Prompt Fixes That Drove False Positives to Zero
I want to be honest about the iteration, because the architecture got us close but not all the way on the first production run.
Two false positives survived. Both were the classes I described above leaking through because the model's prompt did not yet encode how to handle them.
The first fix was explicit: judge token presence independent of word order. I told the model directly that a reordered disclosure is still a present disclosure, and to evaluate the token set rather than the reading sequence. That killed the garbled-footer class.
The second fix encoded the negative-lookahead reasoning. I gave the model the rule that a negated banned phrase is the required disclosure, with the "is NOT a broker-dealer" case as the worked example. That killed the negated-disclosure class.
After those two fixes, false positives hit zero on the production corpus.
Now the honest limitation. Zero on this corpus, with this rulebook. New rules need new patterns, and a page with a structure I have not seen could surface something new. I am not selling you a scanner that is perfect forever, because that scanner does not exist.
What I am selling is debuggability. When a false positive shows up, I know exactly which layer to fix. Did the regex surface the wrong suspect, or did the model judge it wrong? One is a pattern fix, the other is a prompt fix. Either way I know where to put my hands.
A pure-LLM black box gives you nowhere to put the fix. You tweak the prompt, rerun, and hope. With this architecture, every failure has an address.
Why This Pattern Generalizes Beyond Compliance
This is not a compliance trick. The regex-first, model-second pattern applies anywhere you mix fixed rules with contextual judgment.
Content moderation: deterministic code catches the known slur list, the model judges the edge cases where context decides whether something is an attack or a quote. Contract review: regex finds the clause types, the model reads whether the terms are acceptable. Data validation, brand-voice checks, same shape every time.
The general principle for reliable AI content scanning is simple. Use deterministic code for anything with a fixed answer. Use the model only for the judgment calls a regex genuinely cannot make. That keeps the model's hallucination surface small and your false positives debuggable.
Most people do the opposite. They reach for the LLM first because it is the impressive part. It demos beautifully, it feels like the future, and it is the thing the board wants to hear about. So the LLM does everything, including the boring detection work it is worst at.
The reliable systems invert that. The model goes last, as the judge, after cheap deterministic code has done all the cataloging. The deterministic prescan LLM handoff is not the flashy part of the build. It is the part that makes the thing trustworthy enough to leave running.
This is how I build across regulated work generally. The fixed rules belong in code. The judgment belongs to the model. The line between them is where the reliability lives.
What It Takes to Trust an AI Scanner
Back to the owner's question, because it is the right one. How do you trust an AI scanner that flags things that are actually correct?
 Three layers of trust in the scanner
Three layers of trust in the scanner
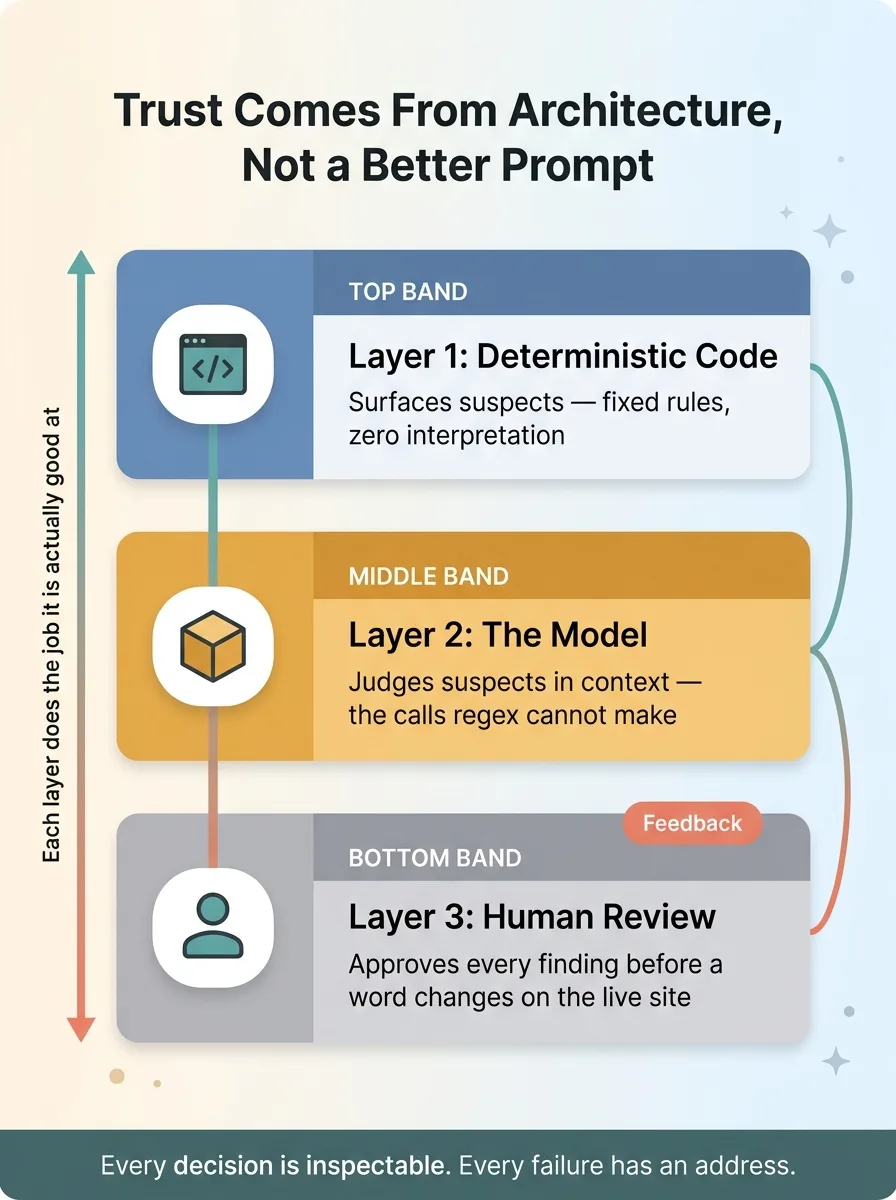
You do not trust the LLM to detect. That was the mistake in version one.
You trust deterministic code to surface suspects. You trust the model to judge those suspects in context. And you trust a human to approve every finding before a single word changes on the live site. Three layers, each doing the job it is actually good at.
Trust comes from architecture, not from a better prompt. A better prompt makes a black box slightly less wrong. An architecture makes every decision inspectable, and gives you a place to fix the next failure when it shows up.
And the human stays in the loop. Every finding stops for review before anything ships, which I wrote about in every finding still stops for a human. For regulated work, that is not optional. A single wrong claim is a real liability, and no scanner gets to publish unsupervised.
This is the kind of system I build for firms where the cost of a wrong claim is measured in regulatory exposure, not embarrassment. If a compliance scanner you can actually trust would save your team from reviewing every page by hand, that is a conversation worth having.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call