The IDOR Vulnerability Fix Hiding in My Consumer App
An IDOR vulnerability fix that closed eight insecure routes at once. How body-param auth lets users read other people's data, and the one helper that stopped it.
By Mike Hodgen
The Bug: Change a Number, Read Another Family's Data
A few months back I was reviewing a consumer subscription app I'd built. Logged in as myself, everything worked. The dashboard loaded my data. My account, my records, my history. Clean.
 IDOR vulnerability: broken vs secure request flow
IDOR vulnerability: broken vs secure request flow
Then I opened the network tab and changed one number.
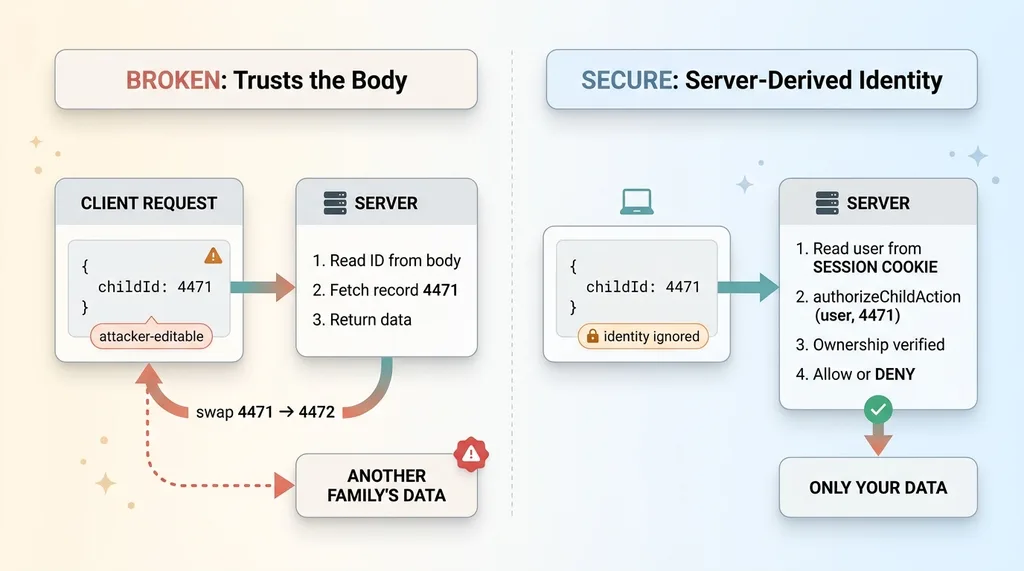
The app accepted a child ID in the request body, looked it up, and handed back the record. It never checked whether the logged-in user actually owned that child. I swapped my ID for a different one, and another family's data came back. Not my account. Theirs.
That is an IDOR vulnerability. Insecure direct object reference. The name is uglier than the concept. It means the app trusts an identifier the client sends instead of deriving that identifier from the authenticated session. The user says "give me record 4471," and the server says "sure," without ever asking "wait, is 4471 yours?"
The route looked roughly like this in shape: accept a resource ID from the body, fetch the record by that ID, return it. No ownership check anywhere in the middle. For an honest user, the ID in the body is always their own, so the app behaves perfectly. Read works. Write works. Updates save. Nothing looks wrong.
That's the trap. The app works flawlessly for every honest user. You test it logged in as yourself, and you only ever send your own IDs. The bug is invisible during normal use. It's invisible during QA. It's invisible in the demo. The only person who finds it is someone who deliberately edits the request, and by the time they do, it isn't a bug report. It's a data breach.
This is the fix hiding in a consumer app I shipped myself. Not a client's mess. Mine. And once I saw the shape of it, I knew it wasn't going to be alone.
Why It Wasn't One Bug, It Was a Cluster
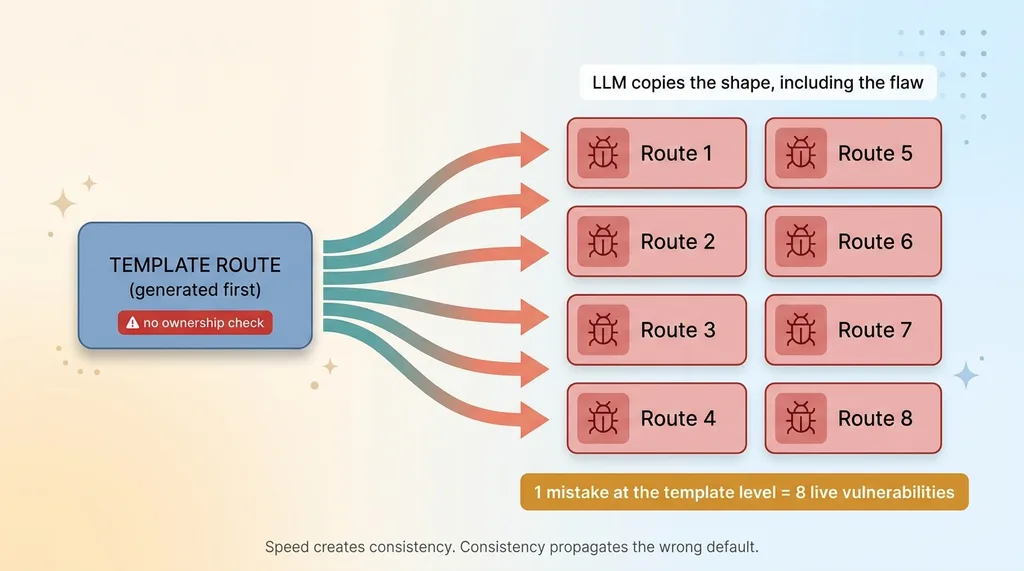
It wasn't one route. It was eight.
 One template flaw propagating into eight vulnerable routes
One template flaw propagating into eight vulnerable routes
The same broken pattern, copied across the entire API surface. Accept an ID from the body, fetch by ID, return or update. Eight times. Every one of them trusted the client to be honest about which record it was asking for.
Here's why AI-generated code produces clusters like this. When you build fast and an LLM scaffolds your API, it copies the shape of the first route into the next one. And the one after that. The model isn't reasoning about authorization on each route. It's pattern-matching on the structure you already have. So if route one trusts the body param, routes two through eight inherit the exact same flaw, because they were generated from the same template in your own codebase.
One mistake at the template level becomes eight live vulnerabilities. This is the same dynamic I wrote about when I ran a security audit across 58 codebases in one day. The flaws were rarely one-offs. They came in families, because the thing that generated the code generated it consistently, including the bad parts.
This is also the buyer-doubt point made concrete. If you've shipped an AI-built app, the holes you can't see are the ones you copied without noticing. You didn't write the vulnerability eight times on purpose. You wrote it once, the tooling propagated it, and now it lives in eight places you'd have to actually inspect to find.
I didn't find these because an alert fired. No alert fires for IDOR. The app is healthy. The logs are clean. I found them because I went looking, route by route, asking one question of each: where does this ID come from, and does anything check ownership before it's used. The answer, eight times in a row, was the body, and no.
This pattern shows up constantly in apps built the way I describe in vibe-coding security. Speed creates consistency, and consistency propagates the wrong default.
The Root Cause: Trusting the Request Body for Auth
The underlying mistake is simple to state and easy to commit. The app made authorization decisions based on values the client controls.
Body params are attacker-controlled
Anything in the request body is editable by whoever sends the request. The user ID, the resource ID, the account number, all of it. A browser dev tool, a proxy, or ten seconds in a terminal lets anyone change those values to anything they want. The client is not a trusted source. The client can be hostile.
So the rule is absolute: an authorization decision cannot depend on a value the user can edit. If the question "is this user allowed to touch this record" is answered using data the user supplied, you haven't built authorization. You've built a suggestion box.
Server-derived identity is the only safe source
Compare the two patterns.
The broken pattern derives both "who" and "what they can touch" from the body. The request says "I am user 12, give me child 4471," and the server believes both halves. Nothing is verified against the session.
The correct pattern derives the authenticated user from the server session, never from the body. The server already knows who you are because you presented a valid session cookie. From there, it verifies ownership: does this authenticated user own the resource they're trying to reach. If not, refuse.
This app runs on Supabase, so the fix lives in the server-side auth layer. The session cookie maps to a verified user on the server. Server-side auth in Supabase means you read identity from createServerSupabase and the session, not from whatever JSON the client decided to send. The client gets to say what it wants to do. The server decides who is asking.
I'll be honest about how this happens. When you're moving fast, trusting the body feels natural because in your own testing the body always contains your own ID. The happy path and the secure path look identical when you're the only user. I shipped this myself, knowing better, because speed hid the gap. That's not a competence problem. It's a visibility problem, and it's exactly why this slips past people who are otherwise careful.
The One-Function Fix: authorizeChildAction()
The fix wasn't eight fixes. It was one function and a discipline.
 The one-function fix: centralized authorization gate
The one-function fix: centralized authorization gate
Verify ownership before any read or write
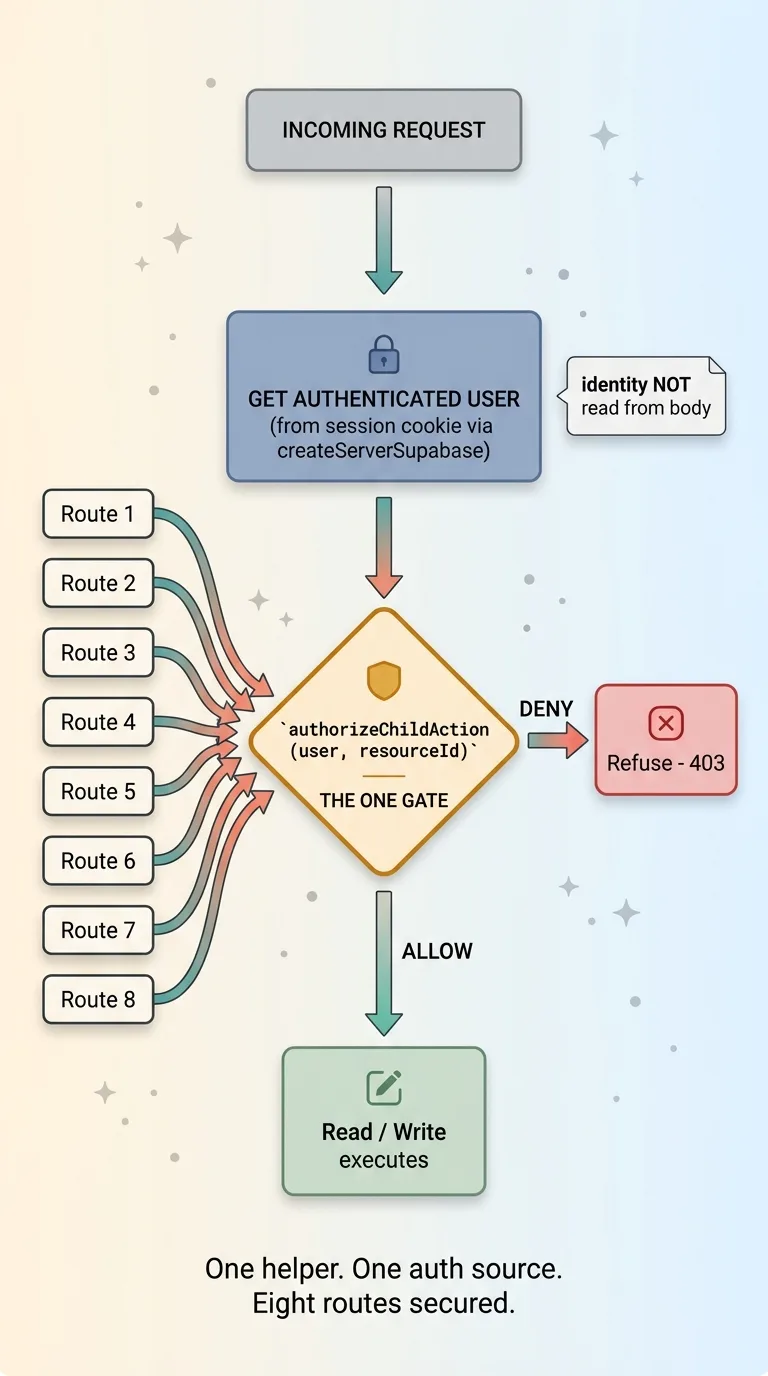
I wrote a single authorize-this-action helper. Call it authorizeChildAction. It takes the authenticated user and the target resource ID, confirms on the server that the user actually owns that resource, and refuses everything else before a single read or write happens.
One function. One place to reason about whether someone is allowed to do something. The logic that used to be missing from eight routes now lives in one helper that every route calls first, before it touches the database.
The signature is dull on purpose. Authenticated user in, resource in, allowed-or-denied out. The dullness is the point. Authorization shouldn't be clever or per-route or improvised. It should be one boring gate that everything passes through.
Move every route to server-side auth
Then I moved all eight routes to server-side Supabase auth. Identity now comes from the session cookie via the server client, not from the request body. The route no longer accepts "I am user 12." It reads who you are from your verified session and ignores any identity claim in the body entirely.
So the flow on every route became: get the authenticated user from the session, call authorizeChildAction with that user and the requested resource, and only if it passes does any data operation run.
The result: one helper, one auth source, eight routes secured. That's the one-function fix in the title. Not a heroic rewrite. A single centralized check and a switch from client-supplied identity to server-derived identity.
The architectural lesson is the part worth keeping. When the authorization check lives inside each route, it gets forgotten in some of them, every time, because humans and LLMs both copy the structure and skip the safety. When the check lives in one helper that every route is required to call, forgetting it becomes a visible, obvious omission instead of a silent one. You centralize the thing that's dangerous to forget. As I argued in IDOR is the vulnerability AI developers never think about, the default has to be deny, and the deny has to live somewhere you can't skip.
The Two Bugs Next Door: Cron Joins and Stripe Checkout
Security holes travel in neighborhoods. While I was fixing the IDOR cluster, I found two adjacent problems, the kind you only see once you're already in the code looking hard.
Crons joined on the wrong column
The background jobs, the crons that run on a schedule with no user watching, were joining tables on the wrong column. In practice that meant automated processing could pull records across account boundaries. No malicious user required. The job itself was quietly mixing data that belonged to different accounts because the join condition was loose.
This is the worst kind of bug because there's no request to inspect and no user to blame. It runs at 3am, processes everyone's data, and the only symptom is wrong results that look plausible. I tightened the joins so every automated operation stays scoped to the correct account, the same way a user-facing request would be.
Deriving the Stripe user from the session, not the client
The checkout flow derived the user ID from the client instead of the session. Same root cause as the IDOR cluster, different blast radius. Here it meant a user could potentially attach a subscription, and the billing that comes with it, to the wrong account.
Two fixes. First, derive the Stripe customer from the authenticated session, never from anything the client sends. Second, add webhook idempotency with a stripe_events table, so a replayed or duplicated webhook can't double-process and create a mess of duplicate charges or state.
Payment code and background-job code are where the worst holes hide, because they're the least watched and the most consequential. Nobody's eyeballing the cron. Nobody re-tests checkout after it works once. That's exactly why I check them first when I go looking.
Why This Is the Most Common Hole in Vibe-Coded Apps
If I had to name the single most common flaw in apps built fast with AI, it's this one. IDOR, in a cluster, almost every time.
The reason is structural. LLMs generate happy-path code. You ask for a route that fetches a record by ID, and you get a route that fetches a record by ID. It works. It's exactly what you asked for. What you didn't ask for, and what the model rarely adds on its own, is the ownership check, because the prompt was about the feature, not the threat.
So the code passes every test you run, because you run every test logged in as yourself, sending your own IDs. It demos perfectly. It ships. And it stays broken until someone curious or malicious sends a different ID, at which point it's a breach, not a bug report.
The same five holes show up in nearly every AI-built app I look at, and the same five security holes show up in every AI-built app walks through the full set. But IDOR is the headliner. It's the one I expect to find before I open the editor.
Which brings me back to the doubt every founder should be sitting with. What's in the app I already shipped that I can't see. The honest answer, most of the time, is this exact thing, repeated across however many routes your tooling generated from the same template.
How to Find Out If Your Shipped App Has This
You can check this yourself, today, and you should.
 Three-part self-audit checklist for shipped apps
Three-part self-audit checklist for shipped apps
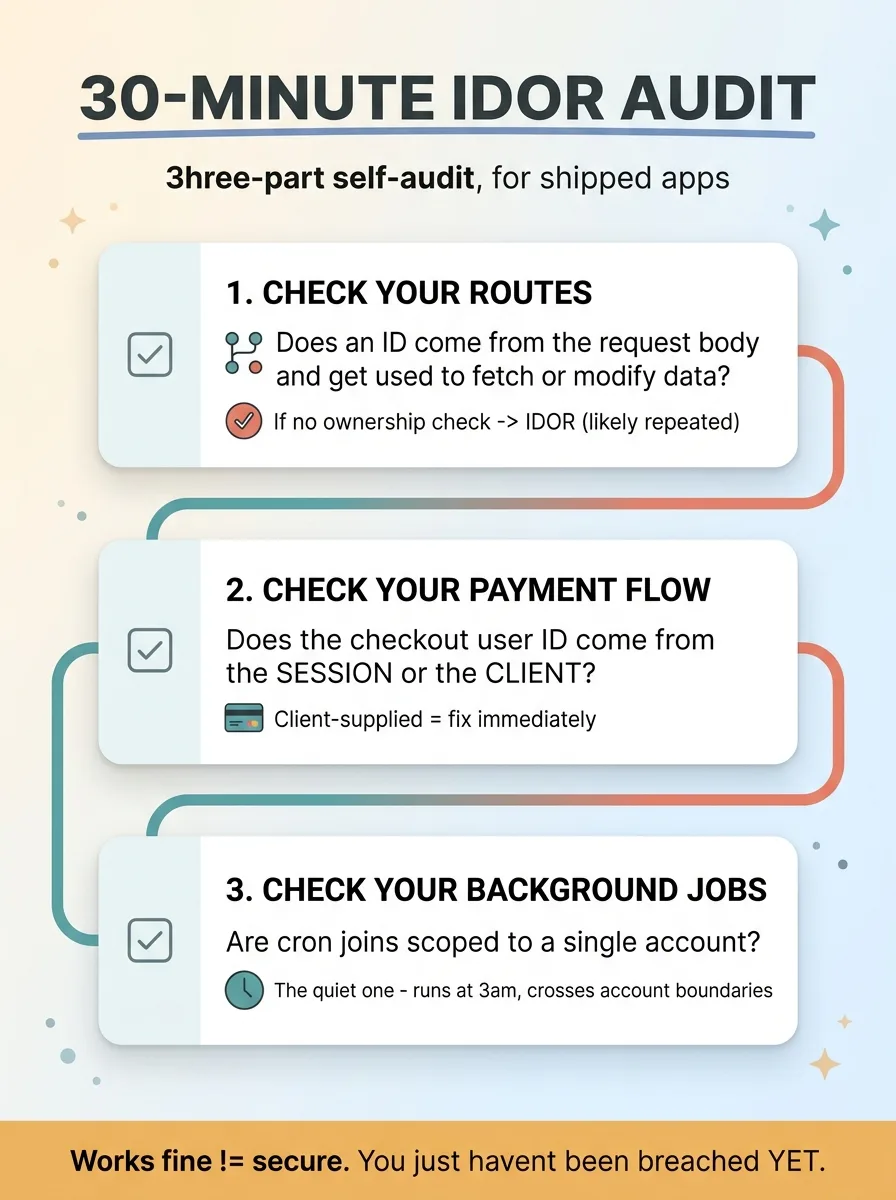
Search your routes for any place where an ID comes from the request body and is then used to fetch or modify data. For each one, ask: does anything verify that the logged-in user owns that record before the operation runs. If the answer is no, you have an IDOR vulnerability, and you almost certainly have it more than once.
Then check your payment flow. Does the user ID in checkout come from the session or from the client. If it comes from the client, fix it before you read another sentence.
Then check your background jobs. Are the joins scoped to a single account, or can a cron cross account boundaries. This is the quiet one, so look carefully.
For someone who knows the pattern, this is roughly a 30-minute audit per app. The reason most teams have never run it isn't laziness. It's that nothing ever forced them to. The app works. The customers are happy. No alert has fired. You don't run the audit because you've never been breached, and "yet" is doing a lot of work in that sentence.
I run this exact audit across client codebases. And I build the fix, not just hand over a PDF that lists problems. The IDOR cluster, the helper, the server-side auth switch, the cron joins, the Stripe session derivation, all of it gets shipped, not just diagnosed. If you've built fast with AI and you want to know what's actually live in your code, have me audit what you already shipped.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call