Inventory Sync Between Systems: How I Made Two Disagree No More
How I keep a warehouse system and storefront in inventory lockstep using an outbox pattern, hourly reconcile, and an AI drift-investigator. No silent failures.
By Mike Hodgen
The Day a Bulk Script Over-Corrected 581 SKUs
I run a DTC fashion brand in San Diego. Everything is handmade, which means inventory is messy by nature. We have a warehouse system that tracks physical bins and a storefront that tells customers what's available to buy. For months, I assumed those two numbers agreed. They didn't.
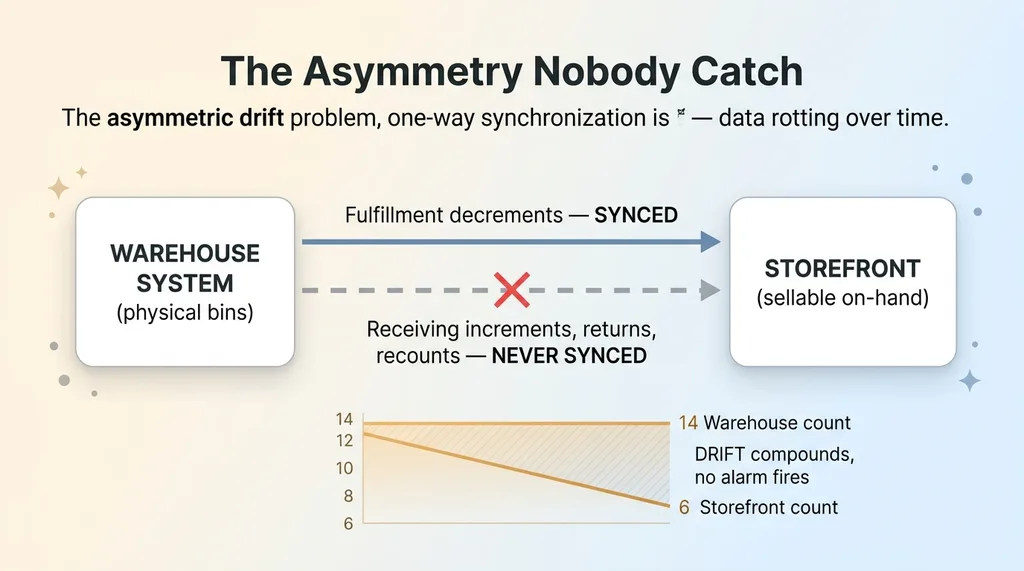
Here's what was happening. When orders shipped, the fulfillment events synced cleanly. The storefront decremented. Perfect. But when we received new product or restocked a bin, those increments never made it to the storefront. The sync only knew how to subtract, never add.
So the storefront on-hand drifted down. Slowly. Quietly. A SKU that physically had 14 units showed 6. Another showed zero when we had a full bin in the back. Phantom stockouts everywhere, hiding sellable product from customers who wanted to buy it.
I noticed the pattern and did what most operators do. I wrote a bulk correction script to close the gap in one pass.
It over-corrected 581 SKUs.
The script read the warehouse counts and pushed them to the storefront, but it didn't account for in-flight orders or pending fulfillments. In one run it swung the brand from phantom stockouts straight into overselling risk. Now the storefront was advertising inventory we'd already promised to other customers. I had traded one silent failure for a louder, more expensive one.
That's the lesson I want to start with, because it cost me real money before it taught me anything. Inventory sync between systems doesn't fail loudly. It fails quietly and asymmetrically. One direction works. The other rots. And the "fix" you reach for in a panic can be worse than the drift.
This is exactly where DTC operations bleed money without anyone seeing the wound. Let me show you the architecture I built to make it stop.
Why Two Inventory Systems Always Drift Apart
 The asymmetric drift problem (one-way sync rotting over time)
The asymmetric drift problem (one-way sync rotting over time)
The asymmetry nobody catches
The warehouse system I built tracks physical bins, real units sitting on real shelves. The storefront tracks sellable on-hand, the number a customer sees. These are two different sources of truth, and the question of which one is correct is its own rabbit hole I've written about in who is right about your stock, the shelf or the storefront.
Most integrations sync one event type beautifully and ignore the rest. Fulfillment decrements? Handled. Receiving increments, customer returns, manual recounts? Often completely invisible to the sync.
That's the asymmetry. The integration was built by someone who tested the happy path (an order ships, stock goes down) and never wired up the reverse. It looks like it works because the most common event flows correctly.
Why one-way syncs rot over time
The damage compounds. Every receiving event that doesn't reach the storefront widens the gap by a few units. Over weeks, a SKU drifts from accurate to badly wrong.
And no alarm ever fires. Each individual sync "succeeded." The fulfillment events all went through. The system reports green while the actual numbers march further apart every day.
This is the part buyers need to internalize: drift is the default state, not the exception. Two systems left alone will always disagree eventually. The only question is whether you measure it or discover it during a quarterly count when you're already 600 units off.
Integrations that report success while doing nothing useful are the most dangerous kind. They give you confidence you haven't earned. The companion architecture I built to kill this is in two systems of record without silent failures, but let me walk through the core pieces here.
The Outbox Pattern: Every Inventory Write Gets a Receipt
The fix for the asymmetry is structural. Stop relying on the sync to "know" about each event type. Instead, make every inventory write generate its own receipt.
 The Outbox Pattern with idempotency keys and worker drain
The Outbox Pattern with idempotency keys and worker drain
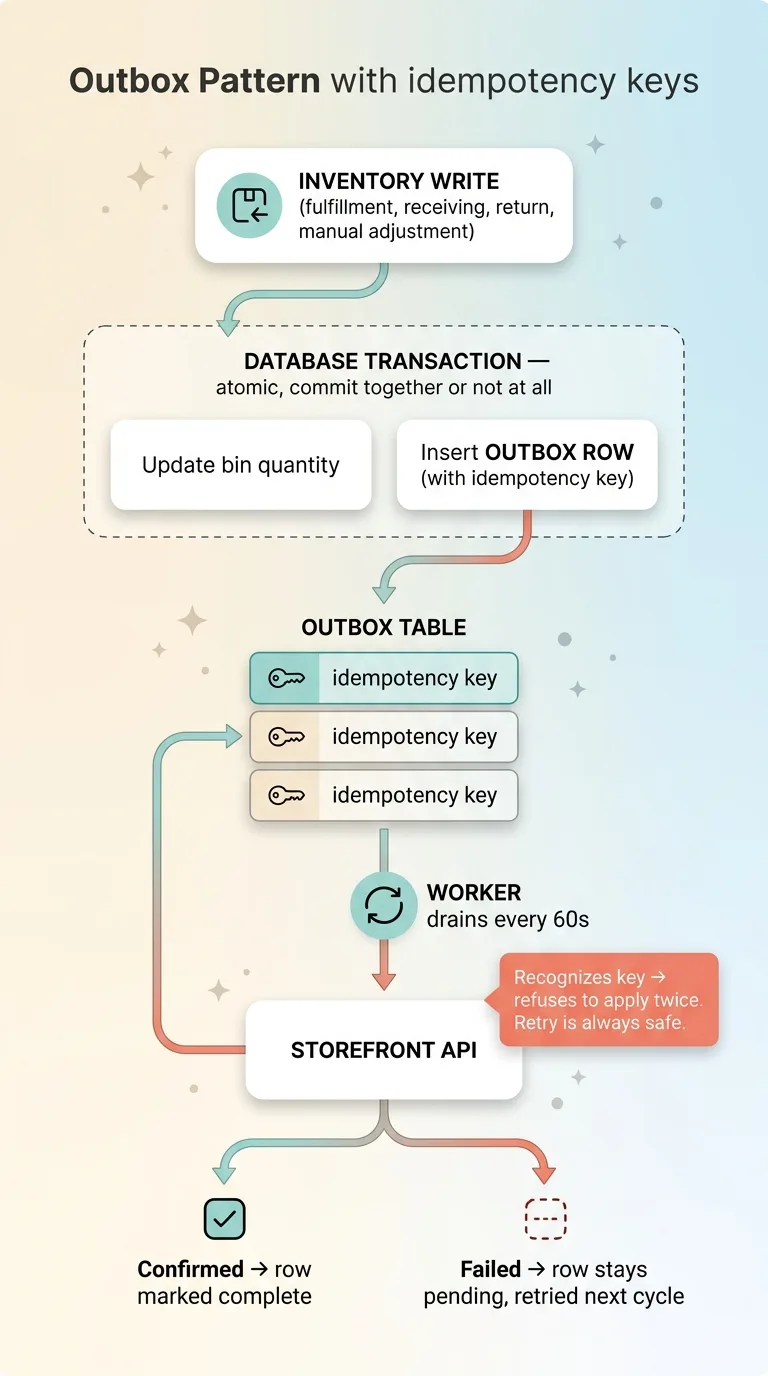
Here's the outbox pattern in plain terms. Every single inventory write (a fulfillment, a receiving, a return, a manual adjustment) writes a row into an outbox table inside the same database transaction as the inventory change itself.
That last part matters. The change to the bin and the outbox row commit together or not at all. There's no scenario where you adjust stock but forget to queue the sync, because they're atomic. The write physically cannot happen without leaving a receipt.
Idempotent rows so retries never double-count
Each outbox row carries an idempotency key. This is the detail that saved me from my own 581-SKU disaster.
When the worker pushes an adjustment to the storefront, it includes that key. If the push times out and the worker retries, the storefront recognizes the key and refuses to apply the same adjustment twice. Idempotent inventory adjustments mean a retry is always safe. You can replay the entire outbox and end up at the correct number, never double-counted.
Fire-and-forget API calls don't give you this. You call the storefront API, the network hiccups, the call times out, and you have no idea whether it landed. So you retry blind and maybe decrement twice. Or you don't retry and lose the update entirely. Both are silent corruption.
Drained every minute, never fire-and-forget
A worker drains the outbox every 60 seconds. It reads pending rows, pushes each change to the storefront, and marks the row complete only after the storefront confirms. If a push fails, the row stays pending and gets retried next cycle.
This is the opposite of fire-and-forget. Nothing vanishes on a timeout. Every adjustment sits in the queue until it's confirmed delivered.
And because every write type queues a row (not just the ones the original integration knew about), the asymmetry is gone. Receiving increments now reach the storefront the same way fulfillment decrements do. The outbox doesn't care what kind of event it is. It just delivers receipts.
This is the outbox pattern for inventory doing exactly what it's supposed to: turning unreliable network calls into a durable, replayable, exactly-once stream.
Hourly Reconcile: Sum the Bins, Compare to the Storefront
The outbox keeps things in sync going forward. But it can't fix what it never saw, and it can't catch a bug in its own delivery logic. You need a safety net underneath.
Every hour, a reconcile job runs. It sums the physical bin quantities for each SKU in the warehouse system and compares that total to the storefront on-hand for the same SKU.
If the two numbers match, great. If they don't, the job logs the delta with a timestamp, the warehouse value, the storefront value, and a computed severity. It does not fix anything. The reconcile records first, acts never. That separation is deliberate, and it's the discipline I lacked when I wrote the bulk script.
What gets logged when numbers disagree
Each drift row is a permanent record. Timestamp, SKU, warehouse total, storefront total, the delta, and the severity tier. Over time this becomes a forensic log. When something goes wrong, I can see exactly when a SKU started drifting and how fast.
That history is also what lets the AI investigator (next section) make good decisions instead of guessing.
Severity tiers: minor, major, critical
Not every delta deserves the same response, so the job computes a tier:
- Minor: off by 1 to 2 units. Usually a timing artifact, an order mid-flight, an outbox row that'll drain in the next cycle. These often self-heal.
- Major: a delta large enough that it's probably not just timing. Worth investigating but not an emergency.
- Critical: a large delta that signals a real bug, a missed event stream, or something like theft or a miscount. These get attention immediately.
Measuring drift continuously is the whole point. The difference between catching a problem in one hour versus finding it in a quarterly physical count is the difference between a five-minute fix and a 581-SKU mess. Reconcile inventory drift on a schedule, and the problem never gets a quarter to compound.
The AI Drift-Investigator That Knows When Not to Touch It
Logging drift is useful. But major and critical rows still need a decision: is this safe to auto-correct, or does a human need to look?
 AI Drift-Investigator decision logic (dual thresholds and escalation)
AI Drift-Investigator decision logic (dual thresholds and escalation)
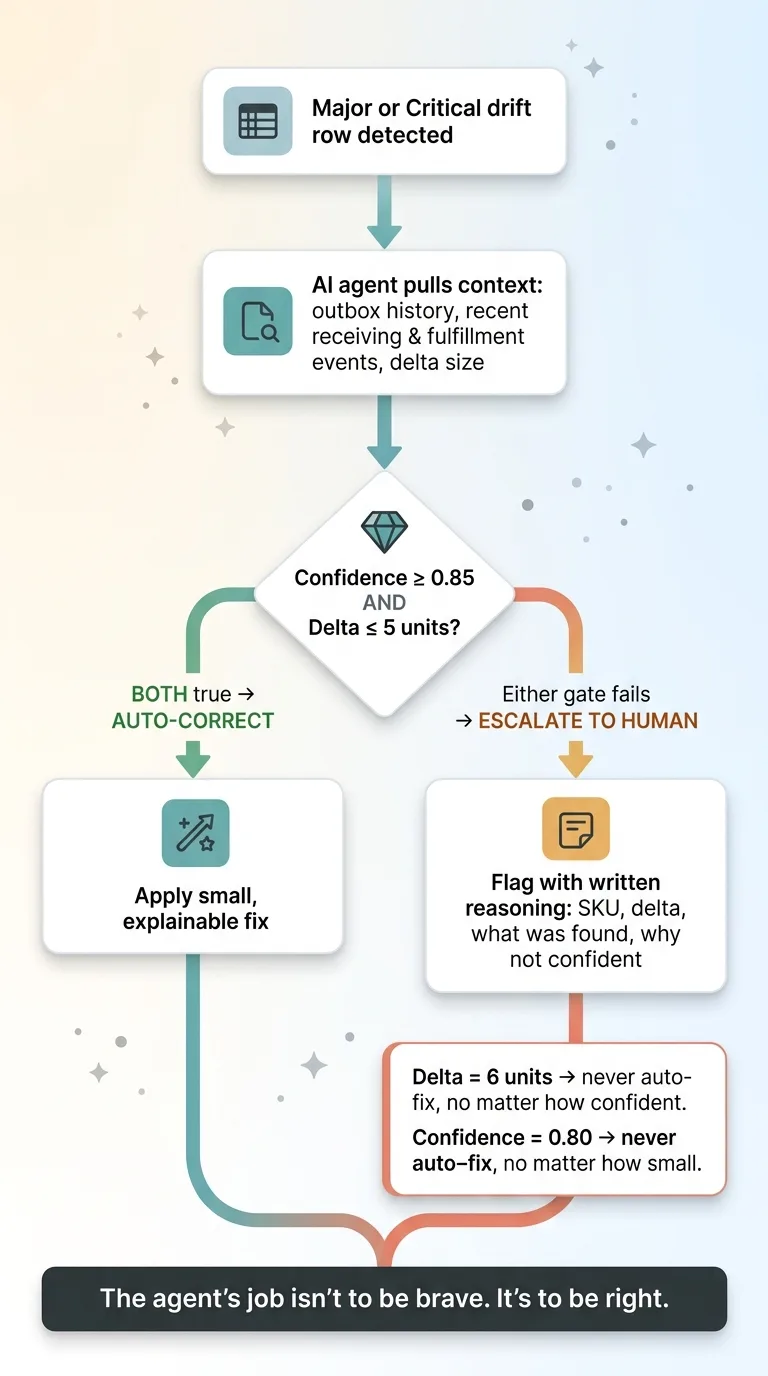
I built an AI agent to triage exactly that. When a major or critical drift row appears, the agent pulls context: recent outbox history for the SKU, recent receiving and fulfillment events, and the size of the delta. It's trying to answer one question. Do I understand why these numbers disagree?
Confidence and delta thresholds before any auto-fix
Here's the rule that exists because of my own disaster. The agent only auto-corrects when both conditions are true:
- Confidence is at least 0.85
- The absolute delta is 5 units or fewer
If the delta is 6 units, it does not auto-fix, no matter how confident it is. If confidence is 0.80, it does not auto-fix, no matter how small the delta. Both gates have to pass.
This is deliberately conservative. The 581-SKU catastrophe happened because a script corrected blindly across hundreds of SKUs in one pass. The AI is built to be the opposite of that script. It would rather escalate a hundred small issues to me than apply one wrong correction at scale.
When it escalates to a human instead
Anything larger or murkier gets flagged for a human. Not auto-fixed. Flagged.
And when it escalates, it doesn't just dump a row in my lap. The agent writes its reasoning: here's the SKU, here's the delta, here's what I found in the recent events, here's why I'm not confident enough to touch it. Maybe it noticed a receiving event that never produced an outbox row. Maybe two adjustments collided. Maybe it genuinely can't explain the gap.
So I start the investigation with context instead of from zero. That's the difference between automation that saves time and automation that just moves the work around.
This is the human-in-the-loop philosophy I apply to every system I build. The AI handles the volume of small, explainable corrections. The judgment calls (the big deltas, the ambiguous cases, the ones that might be theft) stay with a person. The agent's job isn't to be brave. It's to be right, and to know the difference.
That's where the real value sits. Not in automating everything, but in knowing precisely what not to automate.
Why I Email Myself "All Clear" Every Single Day
Every morning I get an email with the reconcile summary. Even when nothing is wrong. Especially when nothing is wrong.
 The four-layer architecture making silent failure impossible
The four-layer architecture making silent failure impossible
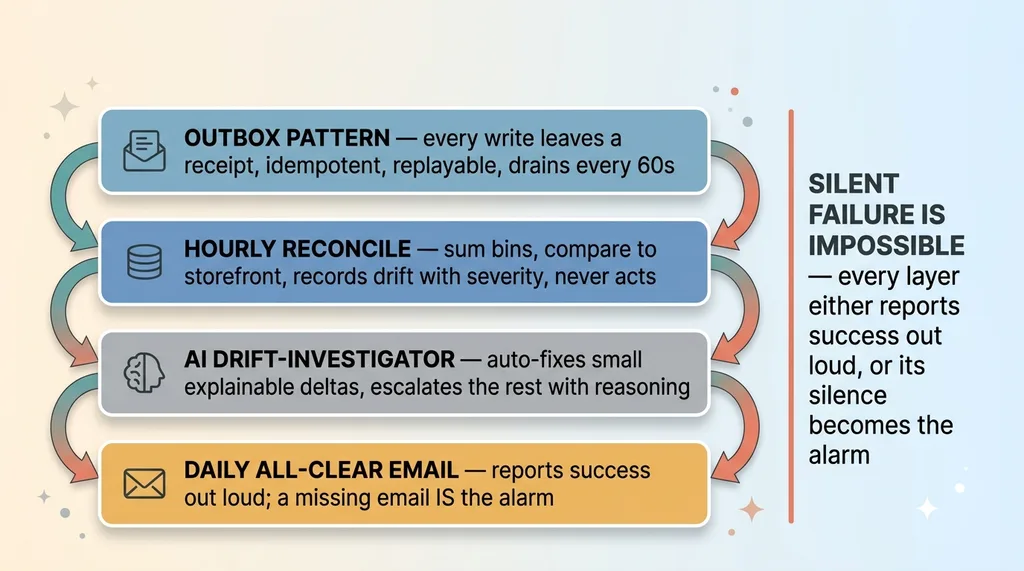
The digest lists the counts: SKUs checked, drift rows opened, rows auto-fixed by the agent, rows escalated to me. On a clean day it's an explicit all-clear. Everything checked, nothing wrong, here are the numbers proving it.
People ask why I'd want an email that says "nothing happened." Because silence is ambiguous.
Think about it. If the only signal is an alert, then a reconcile job that crashed and stopped running looks identical to a reconcile job that ran perfectly and found no problems. Both produce zero alerts. You can't tell a healthy system from a dead one.
The all-clear email proves the system is alive. If the digest doesn't show up one morning, that absence is the alarm. A missing all-clear tells me the reconcile job itself broke, which is exactly the kind of quiet failure that started this whole mess.
I wrote about this principle in detail in silence is not success. The short version: a system that only talks when something breaks gives you no way to trust it when it's quiet.
This is the direct answer to the buyer fear I opened with. Integrations that fail silently are the problem. So I built the entire architecture so that silent failure is impossible. Every layer either reports success out loud or its silence becomes the alarm.
What Inventory Accuracy Across Two Systems Is Actually Worth
Let me put numbers on it, because this is where the boring plumbing earns its keep.
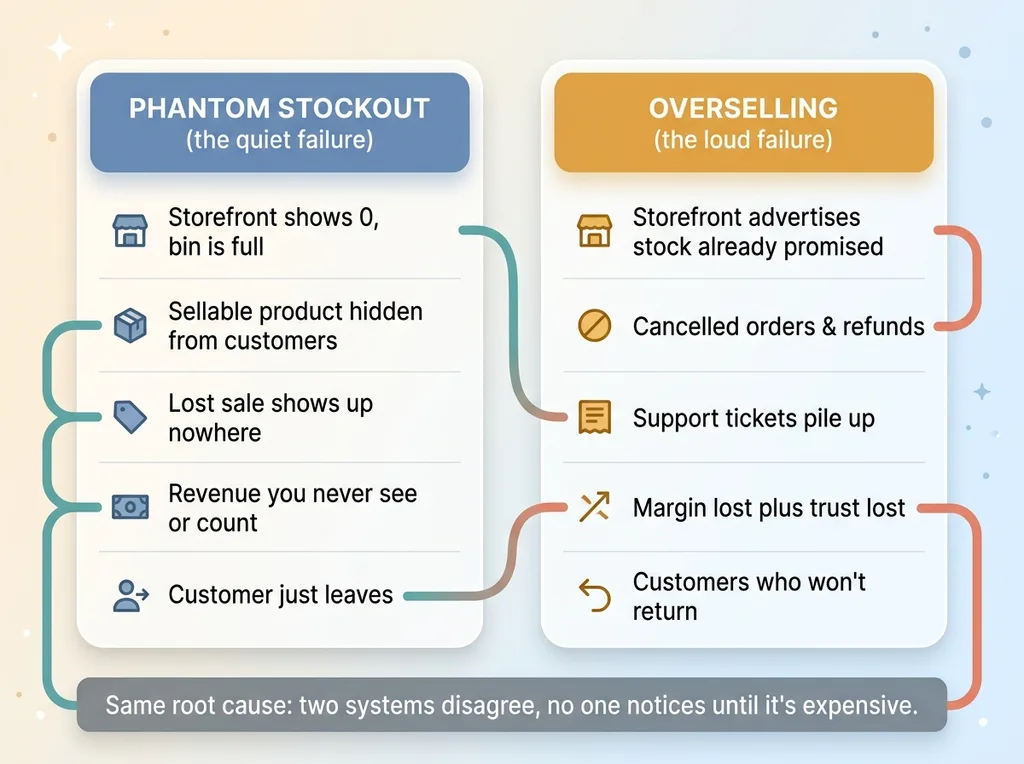 Phantom stockouts vs overselling, the two failure modes
Phantom stockouts vs overselling, the two failure modes
Phantom stockouts mean you're sitting on sellable product the storefront refuses to sell. That's revenue you never see and never count, because the lost sale doesn't show up anywhere. The customer just leaves. Multiply that across hundreds of drifting SKUs and you're quietly leaving real money on the shelf.
Overselling is the opposite failure and it's louder. Cancelled orders, refunds, support tickets, and customers who won't come back. Every oversold unit costs you the margin plus the trust.
Both failures come from the same root cause. Two systems that disagree, and no one notices until it's expensive.
The fix is not exciting. It's an outbox table with idempotency keys, a worker that drains it every minute, an hourly reconcile that records drift before touching it, and a conservative AI that only auto-corrects the small, explainable cases. Boring plumbing plus careful judgment on the edges.
Here's my honest note. This did not eliminate drift entirely. Two systems will always disagree at the margins. What it did was make drift visible and bounded. I always know how far off I am, the gap is small, and I catch it in an hour instead of a quarter. That's the realistic goal, not perfection.
This is the kind of silent operational leak I find and seal in DTC operations. Most teams don't know it's there until they go looking. If you want a second set of eyes, let's look at where your operations are leaking.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call