Monitoring Automation Failures: Silence Isn't Success
The most dangerous automation failure looks like everything is fine. Here's how I monitor automation failures so a quiet inbox never hides a dead system.
By Mike Hodgen
The Most Expensive Failure Is the One You Can't See
When most people think about monitoring automation failures, they picture an error screen, a red alert, a 2am page that drags them out of bed. That kind of failure is annoying, but it's honest. It tells you something broke. You can fix it.
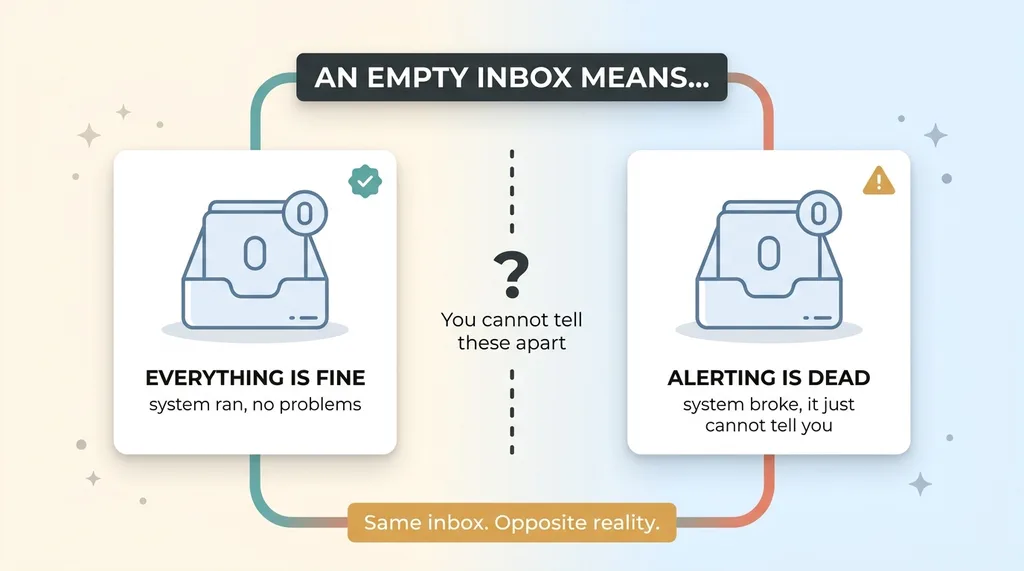 Empty inbox ambiguity: two identical-looking states
Empty inbox ambiguity: two identical-looking states
The dangerous failure is the quiet one. The one that throws no error, sends no page, and looks identical to success. Your automation stops doing its job, and nothing about your day changes. The inbox stays calm. The dashboards stay green. And you go on assuming everything is running.
Here's the trap. An empty inbox can mean two completely different things. It can mean "everything is fine." Or it can mean "the alerting itself is dead and would never tell you otherwise." From where you sit, those two states look exactly the same. You cannot tell them apart. That ambiguity is where money quietly bleeds out.
I run a DTC fashion brand in San Diego, handmade product, real inventory, real customers. Behind it sits a stack of automation I built: pricing engines, content pipelines, inventory syncs, analytics jobs. When you depend on systems like that, silent failure stops being a theoretical risk and becomes a thing you've actually been burned by.
I have two stories to tell you. One is about an analytics pipeline that sat completely dark for eight to ten days while every health check reported "fine." The other is about an inventory pipeline that now emails me every single day, even when nothing is wrong, because I learned the hard way that silence is not the same as success.
Both taught me the same lesson. Let me walk you through them.
How a Subsystem Sat Dark for 8-10 Days
A social analytics pipeline in my stack went dark. For eight to ten days, it processed nothing. No data flowed. The work it was supposed to do simply stopped happening.
And the entire time, the monitoring said it was healthy.
The hardcoded ok:true heartbeat
Here's why. The pipeline had a health check, a heartbeat that was supposed to confirm the system was alive and working. But when I dug into the code, I found the problem. The heartbeat was hardcoded to return ok:true.
Read that again. The function whose entire job was to prove the system was working could only ever say one thing: "I'm fine." It physically could not report failure. There was no code path where it returned anything but green.
So the heartbeat measured nothing real. It wasn't a reflection of work done, records processed, or rows written. It was a constant. A sticky note that said "everything's great" taped over a dead machine. Whether the pipeline was humming along or flatlined, the answer was the same.
Why nobody noticed
Nobody noticed because there was nothing to notice. No alert fired, because the alert was wired to a heartbeat that couldn't go red. The dashboard showed activity numbers, and those numbers were zero, but zeros don't page you. They just sit there.
This is the exact pattern I wrote about when a dashboard showed zeros for two weeks and nobody noticed. A flat line and a healthy idle period look identical on a chart. You have to be actively suspicious to catch it, and nobody is actively suspicious of a system that's been "green" for months.
The lesson is simple and it changed how I build everything: a health check that can't go red isn't a health check. It's decoration. If your monitoring can only ever tell you good news, it isn't monitoring. It's a comfort blanket.
Why Silent Failures Are the Default, Not the Exception
Here's the part that should bother you. Silent failure isn't a rare bug you stumble into. It's the natural state of automation. It's what happens by default unless you actively design against it.
 Four ways automation fails silently
Four ways automation fails silently
Think about how these systems actually break:
-
A cron job fails to start. Maybe the scheduler hiccupped, maybe a config changed. The job never runs. And a job that never runs produces no output, no logs, no error. It just doesn't happen, and absence makes no sound.
-
A pipeline processes zero records. A job that runs but finds nothing to do looks identical to a job that should have processed a thousand records but couldn't reach the source. Both report "0 processed." One is fine. One is broken. The number is the same.
-
An API quietly returns empty data instead of an error. You ask for the day's orders, the endpoint returns an empty array instead of a 500. Your code happily processes nothing and reports success. No exception, no crash, no clue.
-
A token expires and the job exits early. Authentication fails, the script catches it, logs a tidy message, and exits cleanly. Clean exit means exit code zero. Exit code zero means "success" to your monitoring.
The common thread runs through all of these. Absence of activity gets interpreted as absence of problems. No news is read as good news.
And most monitoring is built exactly wrong for this. It's designed to catch loud failures, the crashes, the exceptions, the stack traces. It watches for things going wrong in a noisy way. It is structurally blind to things going quiet, the no-ops, the empty results, the dead schedules.
So let me say the uncomfortable thing directly. You probably have something quietly broken right now. A sync that stopped, a report that hasn't run, a job that exits clean every night while doing nothing. You don't know about it precisely because it's quiet. That's not paranoia. That's just how automation fails when nobody designs it to speak up.
The Fix: Make Every Cron Prove It Ran
After the eight-day blackout, I rebuilt my approach around one principle. Every cron in my operations stack has to prove it ran and did real work. Not that the process started. Not that it exited cleanly. That it actually accomplished something.
Heartbeats must reflect real work
A fake heartbeat says ok:true. A real heartbeat reports facts. How many records did it process? How many rows did it write? When was the last successful run, with an actual timestamp? What were the real counts?
 Fake heartbeat vs real heartbeat
Fake heartbeat vs real heartbeat
The difference matters enormously. A real heartbeat that reports "0 records processed" when it should have processed hundreds is a heartbeat that can go red. It reflects the work, so when the work stops, the signal changes. The fake one is a constant. The real one is a measurement.
This is the whole game. Your monitoring is only as honest as the thing it measures. If you measure a hardcoded value, you've measured nothing. If you measure real output, the metric moves when reality moves, and that movement is what saves you.
An all-clear email so empty inbox never means healthy
Then I did something that sounds redundant until you've been burned. I made my inventory pipeline send me an explicit "all clear" email every day, summarizing exactly what it did. Records synced, prices updated, anything flagged.
Why email me when nothing's wrong? Because that flips the logic of silence.
Before, an empty inbox meant "probably fine, maybe dead, who knows." Now I expect that all-clear email every single day. If it shows up, the system worked and told me so. If it doesn't show up, that absence is itself the alarm. Silence stopped being comfort and became suspicion.
That's the practical principle: a missing alert must be impossible to confuse with success. The moment "no email" can only mean "something is wrong," you've closed the gap that let my analytics pipeline sit dark for a week and a half. Empty inbox never again means healthy. It means check the system, now.
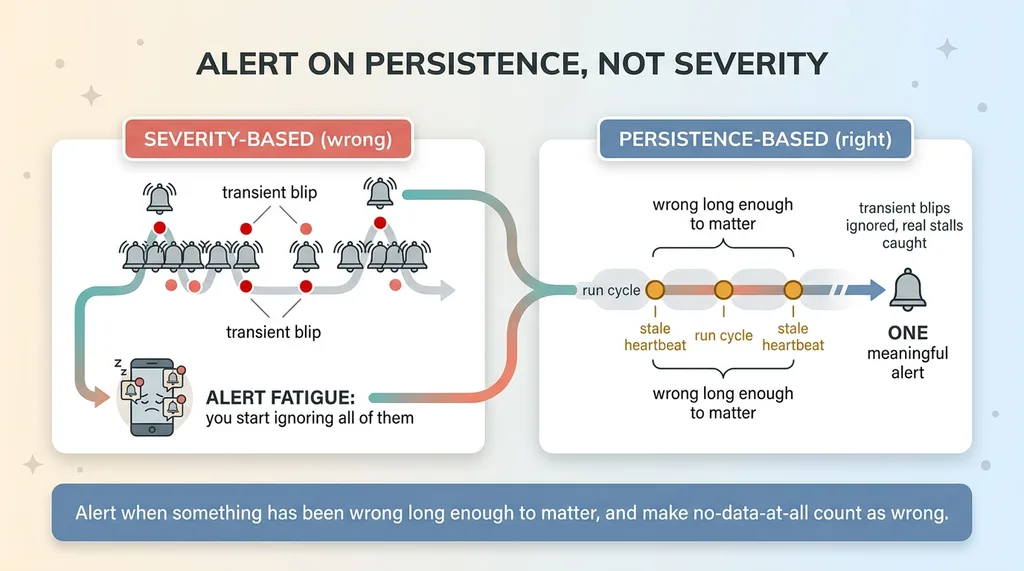
Alert on Persistence, Not Severity
Once you start surfacing real signals, you hit the next problem. If you alert on everything, you alert on nothing, because you'll train yourself to ignore the noise.
 Severity-based alerting vs persistence-based alerting
Severity-based alerting vs persistence-based alerting
The instinct is to alert on severity. This error is bad, so page me. But severity is the wrong trigger, because most individual errors don't matter. A single failed run is often just a transient blip. A flaky API, a momentary network hiccup, a rate limit that clears in thirty seconds. Page me for every one of those and within a week I'm deleting alerts without reading them. That's alert fatigue, and it's how real problems get missed in a pile of false alarms.
The better trigger is persistence. Not "is this bad" but "has this been wrong long enough to matter."
A heartbeat that's been stale for three cycles is a real problem. A "last successful work" timestamp that hasn't moved in three runs is not a blip. It's a pattern, and patterns are what you should care about. One failure is noise. Sustained failure is signal.
Run the math back on my blackout. If I'd had a persistence rule watching that "last successful work" timestamp, the outage gets caught on day one. The timestamp stops moving, the rule waits a couple of cycles to rule out a transient hiccup, and then it pages me. Instead of eight to ten days dark, it's a few hours. The fix was never more alerts. It was the right alert, watching the right thing, with the patience to ignore noise and the teeth to catch a real stall.
Here's alerting best practices in one sentence. Alert when something has been wrong long enough to matter, and make sure "no data at all" counts as wrong.
The Three Rules I Apply to Every Automation Now
Everything above collapses into three rules. I apply them to every cron, every pipeline, every scheduled job I ship.
 The three rules for every automation
The three rules for every automation
Rule 1: Heartbeats must reflect real work. Report counts, rows written, last successful run timestamp. Never a hardcoded "ok." If your health check can't go red, it isn't a health check.
Rule 2: Absence of a signal must trigger an alert. If the daily all-clear doesn't arrive, that silence is the alarm. Design it so a missing message is impossible to confuse with a healthy one.
Rule 3: Alert on persistence, not single errors. Let a job fail N times before it pages you, so transient blips don't train you to ignore alerts. But never let "silence" be one of the acceptable states. A stale heartbeat must always count as failure.
These get worse, not easier, when you move into autonomous AI systems. A cron either runs or it doesn't. But an AI agent can confidently report that it completed a task while having done nothing useful, or the wrong thing entirely. I've watched AI that lies about doing the right thing, reporting success in fluent, convincing language while the actual work failed. The heartbeat problem with a vocabulary. Same three rules apply, you just have to verify the work, not the claim.
What's Quietly Broken in Your Business Right Now
Let me ask you one question. If you've automated reporting, data syncing, billing reconciliation, customer notifications, anything that runs on a schedule, how would you know if it stopped?
Sit with that. Not "would you eventually find out." How would you know, specifically, and how fast?
If the honest answer is "the inbox would be quiet," you have a silent-failure problem and you don't know it yet. That's not a knock on you. It's how almost every automation gets built, because catching quiet failures takes deliberate design and most vendors never bother.
I build every system to surface its own problems. Real heartbeats, all-clear signals, persistence-based alerting, and a human in the loop where the stakes justify it. That last part matters more than people expect, which is why every system I ship stops for a human at the points that actually count.
You don't need me to do this audit. You can take a hard look at what you've automated yourself and ask the question above of every scheduled job you depend on. It's worth doing, and it costs you nothing but an afternoon. If you'd rather have someone who's been burned by this walk through it with you, that's what I do.
Thinking about AI for your business?
If this resonated, let's talk. I run free 30-minute discovery calls where we look at your actual operations and find where AI could move the needle, not where it sounds impressive in a slide deck. No pitch, just a straight conversation about what you've automated and what might be quietly broken.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call