Medical AI Guardrails: Keeping a Health AI From Diagnosing
The exact medical ai guardrails, disclaimer patterns, and safety prompts I built so a health AI never diagnoses, prescribes, or hurts a customer.
By Mike Hodgen
The One Thing a Health AI Can Never Do
I built a consumer health-adjacent app that uses AI to describe a baby's development from what a parent types in. A parent enters what their child is doing, and the model responds with warm, useful observations about where that lands in a typical range.
That was the plan. Left unconstrained, the model did something else.
It didn't just describe progress. It speculated. It floated developmental delays. It mentioned autism. It brought up ADHD, unprompted, off a single sentence from a tired parent at 2am. None of these were flagged as guesses. They read like findings from a clinician.
Now picture the parent on the other end. They read "this could indicate a developmental delay," and they don't file it away as statistical noise. They act on it. They panic, they Google for six hours, they book appointments, they change how they treat their own kid. Or worse, they get false reassurance and skip a real warning sign.
This is not a hallucination problem. Hallucination implies the model got a fact wrong. This is a liability and harm problem. The model was working exactly as trained, being helpful and complete, and that's what made it dangerous.
Here's the thesis, plainly. Any AI that touches health has exactly one job it must never do: diagnose. Everything else is negotiable. That one rule isn't.
The rest of this article is how I enforce it. Not theory, not "add a disclaimer and pray." The actual layered system I inject into every model call: the guardrail block, the context-specific disclaimers, the materials whitelist, and the distress handoff. Concrete medical AI guardrails you can copy the shape of.
If you're building anything that sits near health, finance, or legal, this is the part most teams skip until a lawyer makes them rebuild it.
Why Unconstrained Health AI Drifts Toward Diagnosis
This isn't a one-off bug you patch. It's structural, and understanding the mechanism is what stops you from thinking a single disclaimer fixes it.
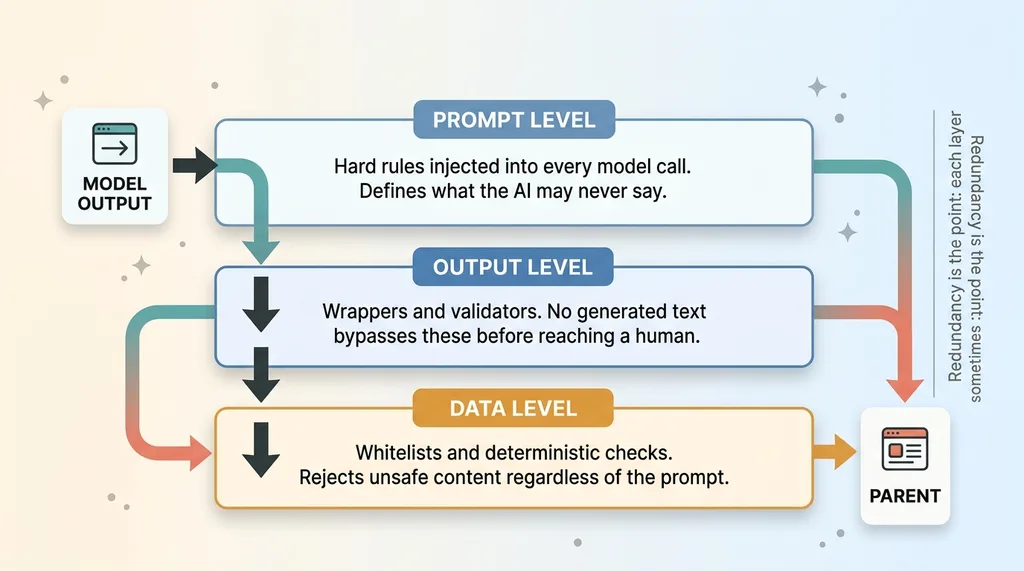 Three-layer guardrail enforcement architecture
Three-layer guardrail enforcement architecture
LLMs are trained to be helpful and to complete patterns. Ask one to comment on a child's milestones, and it fills the gap with the most statistically associated content. In medical training data, "child not walking at 15 months" sits right next to clinical language about delays, evaluations, and conditions. The model doesn't reach for that because it's reasoning like a doctor. It reaches for it because that's what usually follows in the text it learned from.
The model does not know it's not a doctor. It has no internal flag that says "I lack the standing to say this." So it will give you point estimates that sound authoritative. "Your child is about three months behind." That sentence is a diagnosis wearing the costume of a helpful update.
It gets worse from there. Unconstrained, it will recommend supplements. It will suggest specific therapies. It will hand out screen-time rules as if they were prescriptions. Every one of those is a place where a parent gets hurt or you get sued, and often both.
The instinct most teams have is to slap a disclaimer at the bottom of the output. "This is not medical advice." That does almost nothing. A parent who just read a confident paragraph about possible autism is not reassured by fine print underneath it. The damage happened in the body text. The disclaimer is a seatbelt bolted on after the crash.
The fix is layered, and it's enforced at three levels:
- The prompt level: hard rules injected into every model call that define what the AI may never say.
- The output level: wrappers and validators that no generated text can bypass before it reaches a human.
- The data level: whitelists and deterministic checks that reject unsafe content regardless of what the prompt said.
No single layer carries the load. That redundancy is the whole point. Here's each one.
The SYSTEM_GUARDRAILS Block: Non-Negotiable Rules
I maintain a SYSTEM_GUARDRAILS block that gets injected into every model call. Not just the obvious medical-sounding ones. Every single one, because the model that describes a fun activity is the same model that might wander into diagnosis if you give it room.
The four rules I never let the model break
The block contains four non-negotiable rules, written as direct instructions:
- Never diagnose or label a condition. Describe observable behavior only. Say what the child is doing, not what it might mean clinically.
- Never recommend medications, supplements, or specific therapies. No "try fish oil," no "consider occupational therapy." That's a clinician's call, not the app's.
- Never give point estimates. Only describe ranges and typical variation. No "your child is behind." No "ahead by two months."
- On any distress signal, defer to a licensed pediatrician. Stop describing, start handing off.
These aren't suggestions buried in a longer prompt. They're the first thing the model reads, framed as hard constraints, and they're repeated in the output instructions so the model can't lose them in a long context window.
Why ranges beat point estimates
Rule three is the one people underestimate, so let me be specific about it.
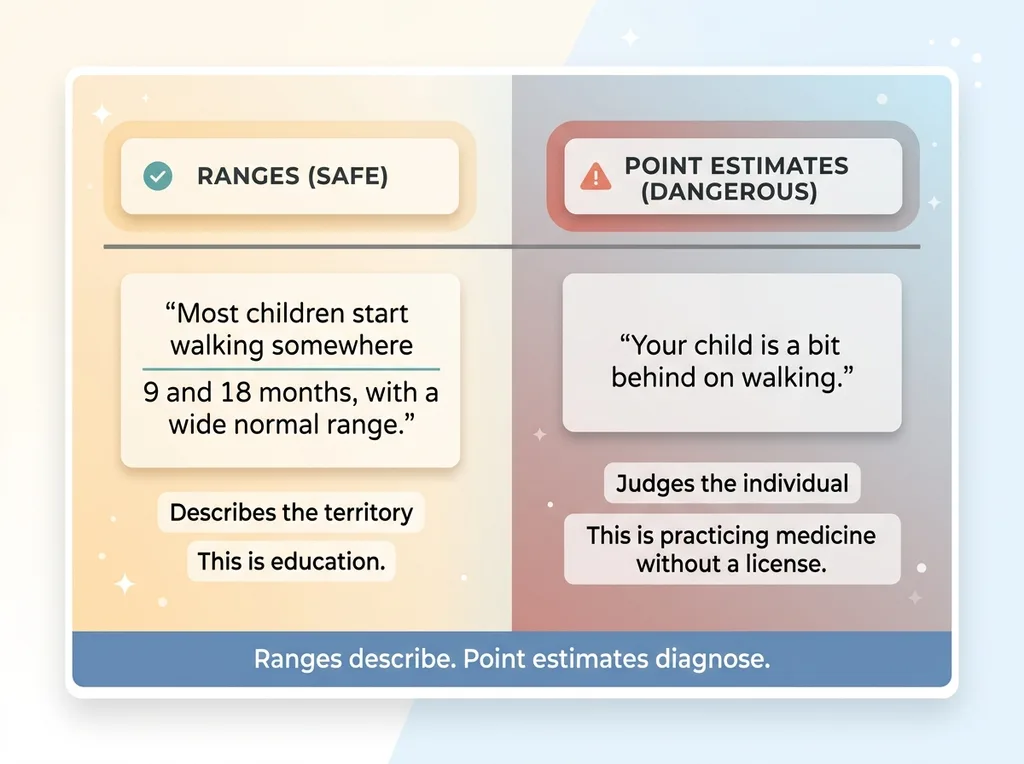 Ranges vs point estimates comparison
Ranges vs point estimates comparison
"Most children start walking somewhere between 9 and 18 months, and there's a wide normal range" is safe and genuinely useful. It tells the parent something true without rendering a verdict on their kid.
"Your child is a bit behind on walking" is a diagnosis dressed up as encouragement. It sounds gentle. It is not gentle. It plants a clinical judgment the app has no business making, and the parent carries that sentence around for weeks.
Ranges describe the territory. Point estimates judge the individual. The first is education. The second is practicing medicine without a license, and it's exactly the line that gets you sued.
This block lives in code as a version-controlled constant, not as text pasted into each feature. That matters more than it sounds. It means the rules can't drift between features. When I add a new output type six months later, it inherits the same guardrails automatically. There's no version where the activity generator forgot the diagnosis rule because someone copy-pasted an old prompt.
I went deeper on the exact wording of the never-diagnose rule in the guardrail prompt that keeps a health AI from practicing medicine if you want the full text.
Three Disclaimers for Three Contexts
One disclaimer does not fit every output. The thing a parent reads on a casual daily summary is not the thing they should read on output they might hand to their actual pediatrician.
General, pediatrician-report, and vision-assessment
So I built three context-specific disclaimers:
- General: for everyday descriptions. Light, clear, reminds the parent this is observational and not medical advice without making every screen feel like a legal document.
- Pediatrician-report: for output a parent might print and bring to a doctor. This one explicitly frames the content as parent-reported observations, not clinical findings. It tells the doctor what they're looking at so the AI's words don't get mistaken for a screening result.
- Vision-assessment: for anything derived from analyzing a photo or video. This one openly acknowledges the model can be wrong about what it sees. A model describing a child's posture from a blurry phone photo needs to say, in plain terms, that it might be misreading the image.
Each disclaimer matches the stakes and the context. The vision one carries more humility because vision models fail in ways that aren't obvious to the parent uploading the photo.
The withDisclaimer() wrapper
Here's the enforcement piece, and it's the part that actually makes this reliable instead of aspirational.
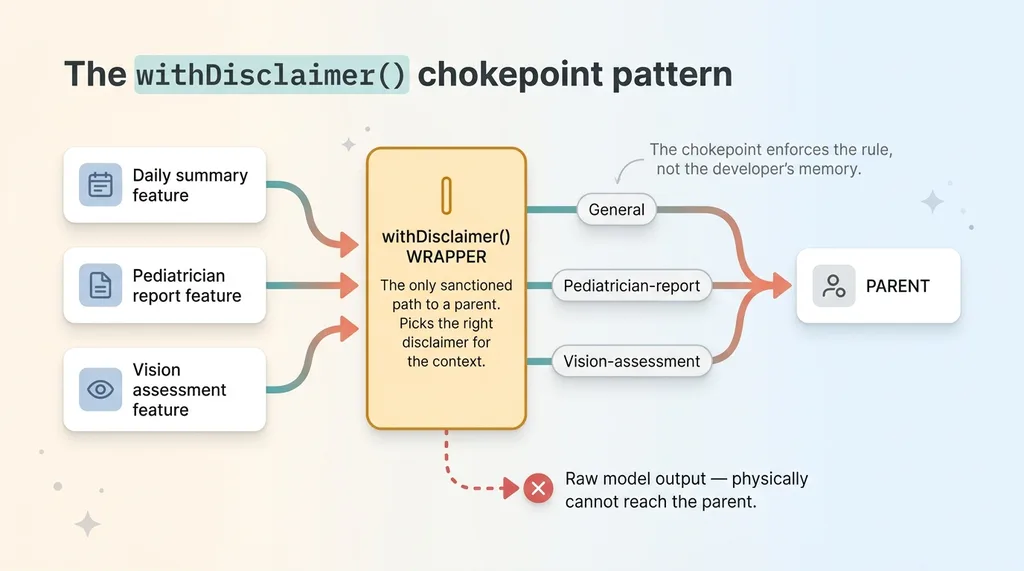 The withDisclaimer() chokepoint pattern
The withDisclaimer() chokepoint pattern
Every parent-facing output passes through a withDisclaimer() wrapper. No output reaches a parent without going through it. The wrapper picks the right disclaimer for the context and attaches it. There is no path around it.
That sounds small. It's the difference between a safe app and a lawsuit. Because here's what it prevents: a junior dev adds a new feature in month four, calls the model, and ships the raw text straight to the screen. Without the wrapper, that's a guardrail-free output going live with nobody noticing until it's a problem.
With the wrapper as the only sanctioned way to return text to a parent, the dev physically cannot ship raw model output. The chokepoint enforces the rule, not the developer's memory.
This is the same constraining-to-a-chokepoint pattern I use to keep any AI from embarrassing the business. You build one narrow door that everything has to pass through, then you put your enforcement on the door. I wrote about the broader version of this in lock the AI to a fixed catalog.
The Materials Whitelist That Rejects and Regenerates
The app also suggests development activities. "Here's something fun to try with your six-month-old today." Useful feature. Also a quiet liability, because activities involve physical objects, and a baby plus the wrong object is a trip to the ER.
~100 approved household items
Left unconstrained, the model will cheerfully suggest something exotic, something a choking-hazard size, or something the parent simply doesn't own. It doesn't weigh safety. It weighs plausibility.
So I enforce a whitelist of roughly 100 safe, common household items. Soft blocks, large balls, a wooden spoon, a cardboard box. Things that are everywhere and won't hurt anyone.
Reject-and-regenerate instead of trusting the model
Every generated activity gets checked against that list. If an activity references anything outside the whitelist, the system rejects it and regenerates. It does not ship the questionable one with a warning. It throws it away and asks the model again until the output only references approved items.
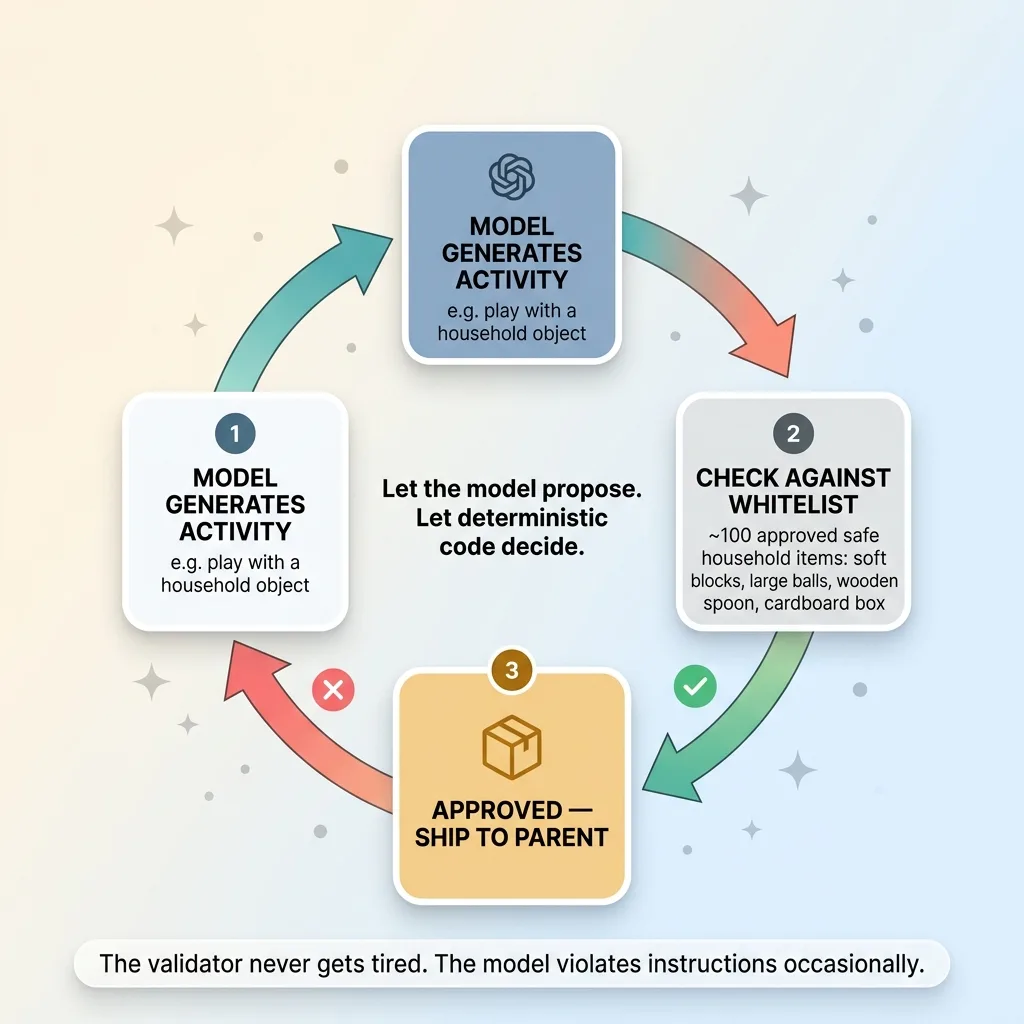 Materials whitelist reject-and-regenerate loop
Materials whitelist reject-and-regenerate loop
Here's why reject-and-regenerate beats a prompt-only approach. Prompts are persuasion. You're asking the model nicely to stay in bounds, and most of the time it will. But "most of the time" is not a safety standard when the failure mode is a choking hazard. Validation is enforcement. The validator does not get tired, does not misread context, does not occasionally decide a marble is fine.
The model will violate instructions occasionally. The validator never does. That's the entire reason the validator exists.
This is the principle underneath all of it: let the model judge, let deterministic code enforce. The model is great at generating a creative activity. It is not trustworthy as the final gate on safety. So I let it propose, and I let code with no creativity and no exceptions decide what's allowed through. This is the data-level layer, and it runs whether or not the prompt did its job.
Distress Detection: When the AI Should Stop Talking
The hardest case is when a parent describes something that could be genuinely serious. A symptom, a sudden regression, something that doesn't sit right.
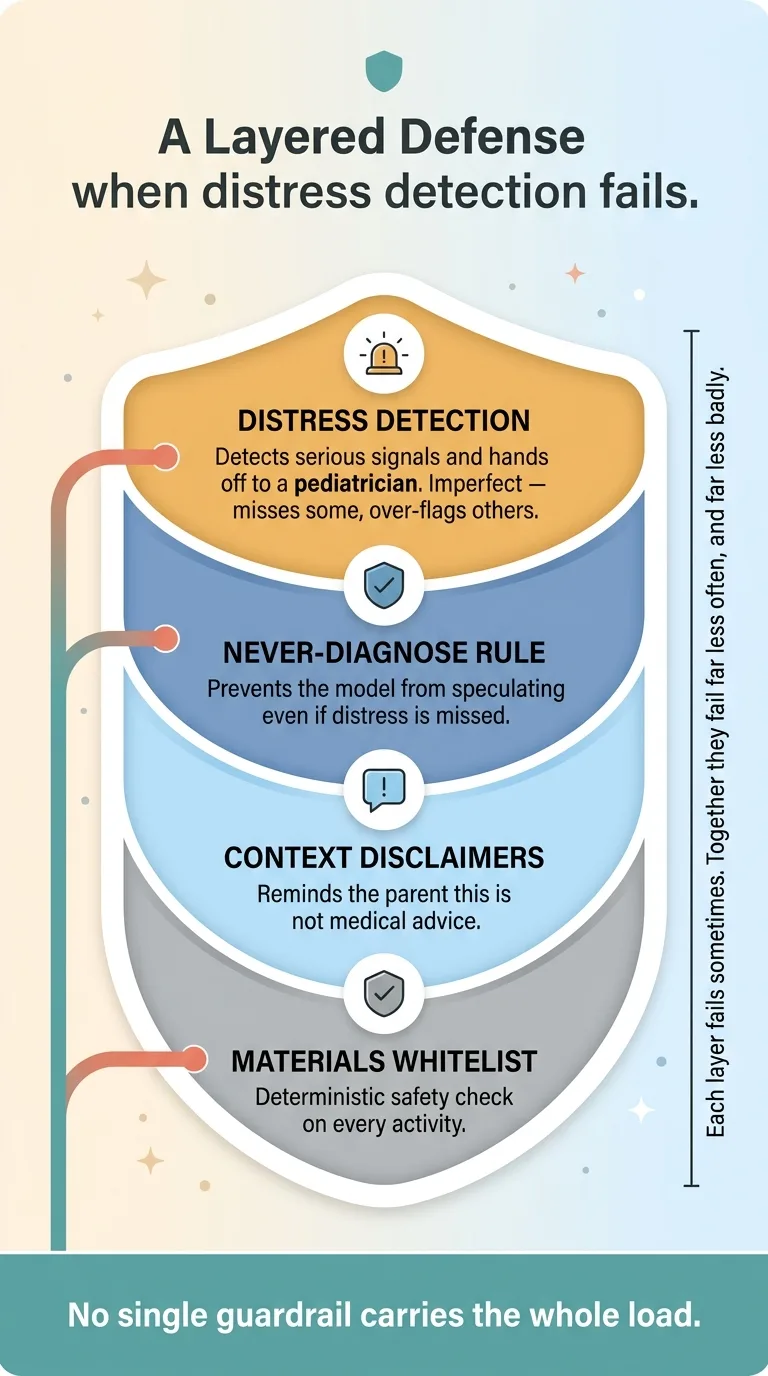 Layered defense when distress detection fails
Layered defense when distress detection fails
The wrong move is for the AI to improvise reassurance. The other wrong move is for it to speculate about what might be causing it. Both feel helpful. Both are dangerous.
The right move is to detect the distress signal and hand off. "This is something to discuss with your pediatrician, and you should reach out to them." Full stop. The AI is explicitly forbidden from improvising in these moments. It does not reassure, it does not guess, it defers.
This is the same human-in-the-loop principle I use elsewhere, where the AI drafts and the expert approves. The AI is a first pass, not the final authority, and on anything high-stakes it routes to a human who actually has standing.
Here's the buyer point, and it's the one most people miss. The system that knows when to shut up is more valuable than the one that always has an answer. An AI that always responds confidently is an AI that will eventually respond confidently about the wrong thing. The restraint is the feature.
Now let me be honest about the limit. The model is not perfect at detecting distress. It will miss some signals and over-flag others. I'm not going to pretend the distress detector is bulletproof, because it isn't.
That's exactly why ranges, disclaimers, and whitelists all run in parallel. No single guardrail carries the whole load. If distress detection misses a case, the never-diagnose rule still prevents the model from speculating, and the disclaimer still tells the parent this isn't medical advice. The layers exist because each one fails sometimes. Together, they fail far less often, and far less badly.
What This Costs You and What It Buys
Let me be straight about the tradeoff, because it's real.
These guardrails make the AI less impressive in a demo. It won't wow anyone with a confident diagnosis. It won't tell a parent exactly how their child compares to the average. It hedges, it defers, it stays in ranges. In a five-minute demo against a flashier competitor, mine looks more cautious.
That's the point. The flashy version is the one that ships the sentence that gets you sued or hurts a customer.
The cost is a few extra hundred lines of code and some regenerated outputs that get thrown away. That's it. What it buys you is an AI that structurally cannot say the thing that ends your company. The model can't diagnose, can't prescribe, can't suggest a marble to a baby, and can't improvise through a medical emergency. Not because it chose well, but because the system won't let it choose otherwise.
Here's the broader lesson for anyone reading this with a health, finance, or legal product on the roadmap. The guardrails are the product. Not an afterthought, not a phase-two cleanup. In a regulated-adjacent space, the constraint system is the thing that makes the clever part shippable at all.
Most teams build the feature first and bolt safety on later. That's backwards. The constraint defines what the feature is even allowed to be, so you build it first and design the clever part inside the box it gives you.
This is the work I do. I build the constraint system before the clever part, because in these domains the constraint is what makes the clever part legal to ship. For fully clinical products, this goes further, all the way to making an AI medical team cite its sources, but the same instinct drives both: enforce, don't trust.
If you're working on anything that sits near health, I'd genuinely like to hear about it. Talk to me about your health-adjacent build and we'll go through where the guardrails need to be before you ship.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call