Retrofit a Multi-Tenant Database Without Downtime
How I retrofitted a multi-tenant database onto a live single-tenant app with no rewrite, no outage, and an additive tenancy spine. Real approach, anonymized.
By Mike Hodgen
The problem: you built it for one, now you want to sell it to many
I built a tool for a window-treatment company. One customer, one schema, one set of orders flowing through it every day. It worked. Real traffic, real orders, real money moving through the system on a Tuesday afternoon while I was on a call.
Then the obvious thought showed up, the one that shows up for everyone who builds something good for a single client. Other companies in the exact same business would pay for this. Same workflows, same headaches, same gap in the market. I had a product. I just had a product with one tenant baked into every table.
So here is the question every founder asks at this point, and it is the right one to ask: how risky is it to make this multi-tenant? You have a thing that makes money. You do not want to break it.
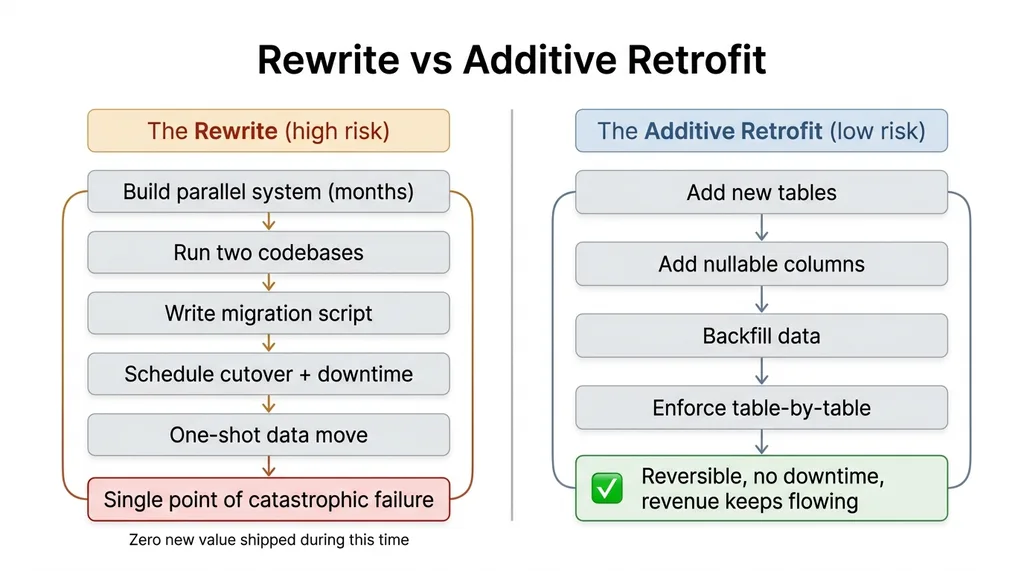
The honest answer most engineers give is "rewrite it." That answer is wrong, and it is expensive. It comes from a good instinct (the schema really does assume one owner everywhere) but it leads you straight into months of parallel-system work and a cutover where you hold your breath.
Here is my thesis, and I have shipped it: you can retrofit a multi-tenant database additively. No rewrite. No downtime. You do it by sequencing the scary part deliberately instead of doing it as a big bang.
The scary part has a name. It is retrofitting row-level security onto tables that are already serving live traffic. That is where the outage risk actually lives. Everything else is bookkeeping.
The trick is to isolate that risk into a controlled window and leave the rest of the work boring on purpose. Let me walk through exactly how I did it, in the order I did it.
Why the rewrite instinct is wrong (and expensive)
Engineers reach for the rewrite because a single-tenant schema feels like it needs surgery everywhere. Every table assumes one owner. Making it multi-tenant feels like touching all of them at once, so why not start clean.
 Rewrite vs Additive Retrofit comparison
Rewrite vs Additive Retrofit comparison
I understand the pull. A blank schema is satisfying. But look at what the rewrite actually costs you.
You build a parallel system for months. You run two codebases. You write a migration script to move live data from the old shape to the new shape. Then you schedule a cutover, take the app down, run the script, and pray nothing in production had an edge case your script did not. During all of that, you ship zero new value to the customer who is paying you right now.
For a tool that is already making money for one customer, that is the wrong trade. The right move is to keep the thing running exactly as it is and bolt tenancy on around it.
The principle is simple and it has saved me every time. Additive changes are reversible and low-risk. Destructive migrations on live data are where outages come from. A new nullable column hurts nobody. A rewritten schema with a one-shot data move is a single point of catastrophic failure.
There is a business case underneath all of this too. The whole reason you are doing the migration is that you want to build it for one client, ship it to a hundred. The faster you can prove the multi-tenant model on a customer you already have, the faster you can sell to the second one. A rewrite delays that proof by months. An additive approach lets you validate the model while the original customer keeps using the app, none the wiser.
You do not need to bet the business to find out if the SaaS idea works.
The additive tenancy spine: tenant on every row
The core of the whole approach is what I call the tenancy spine. It is the structure that says "this row belongs to this customer," and the entire point is that you add it without changing anything that already exists.
New tables, not changed tables
Start by creating the organizational structure as brand-new tables. In this domain I had three levels: a top-level organization, an operational arm under it, and the individual users. New tables for each. They reference each other. They do not touch a single existing table when you create them.
This is the part people skip. They want to start altering the live tables right away. Do not. New tables breaking nothing is the entire safety property you are building on.
Then, and only then, you add a tenant reference column to your existing tables. One column. Nullable. No default that does anything, no foreign key constraint enforced yet, no NOT NULL. It just sits there empty.
Your existing rows now have a place to record which tenant they belong to. They do not yet, and nothing checks.
Why additive means zero downtime
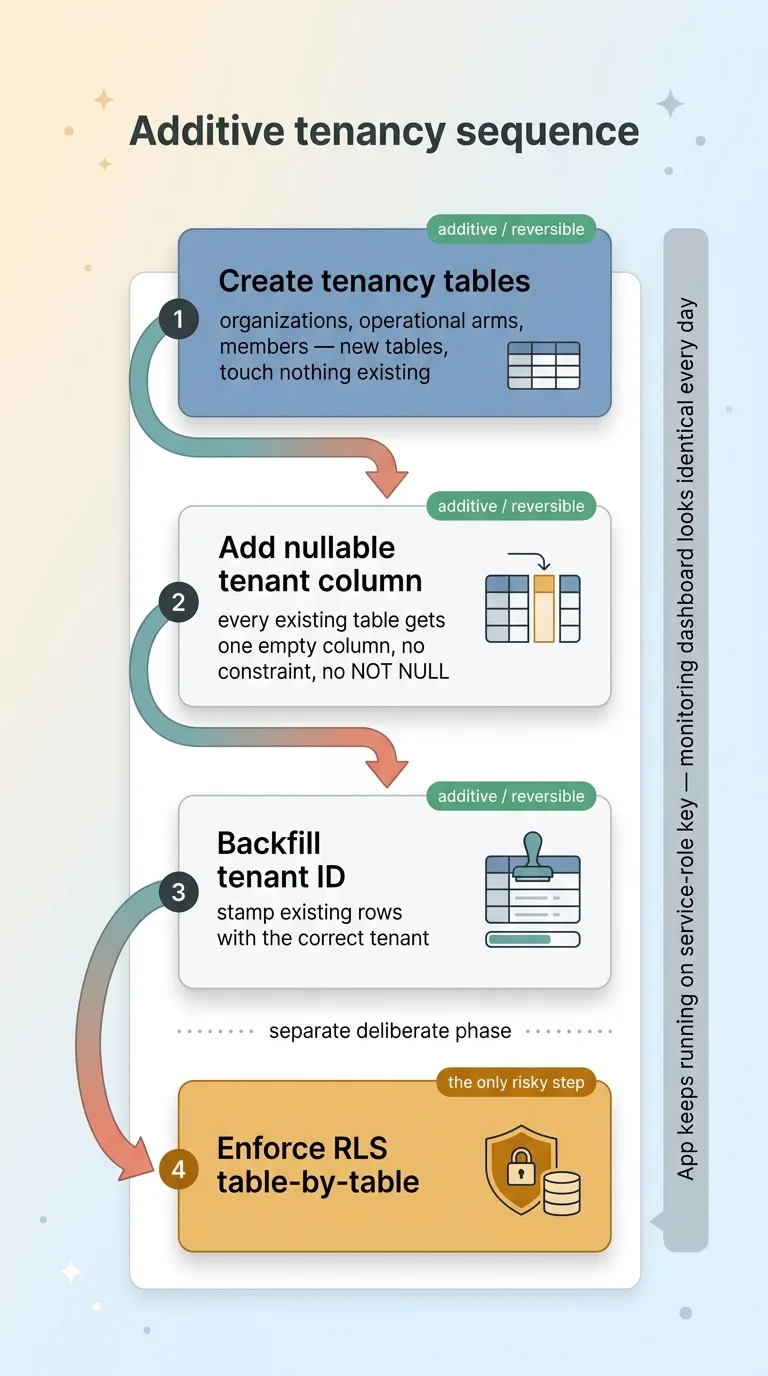
Here is the sequence I actually ran:
 The four-step additive tenancy sequence
The four-step additive tenancy sequence
- Create the tenancy tables (organizations, operational arms, members).
- Add a nullable tenant column to every existing table.
- Backfill that column with the correct tenant ID.
- Later, in a separate deliberate phase, enforce.
Notice what is missing. There is no step where existing behavior changes. The app keeps running on the service-role key exactly as it did before, querying the same tables, returning the same results. The permissive policies that were already in place stay untouched.
Every single step on that list is additive. New columns that default to null. New tables. New helper functions. Nothing that already runs gets modified, so nothing that already runs can break.
This is the heart of additive database migration. You are not transforming the system. You are growing new structure alongside it and leaving the old structure to keep doing its job. The day you create the tenancy spine, your monitoring dashboard should look identical to the day before. That is the point.
Seeding the original customer as tenant zero
Once the spine exists and the backfill column is in place, you seed your first tenant. And your first tenant is the customer you already have.
 Tenant zero, reframing the existing customer
Tenant zero, reframing the existing customer
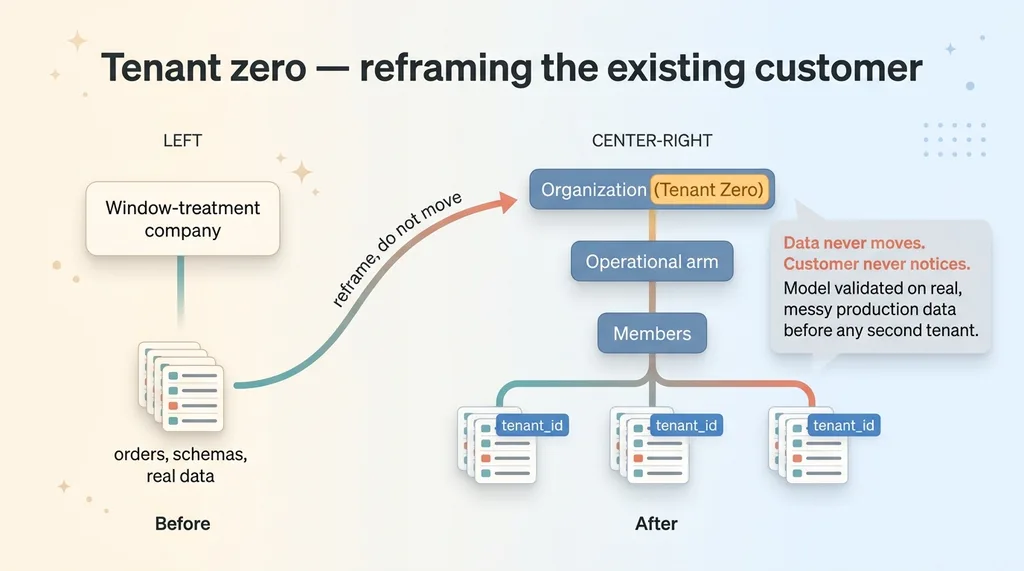
The original window-treatment company becomes the first row in the new organizations table. Its operational arm gets backfilled as the first operational unit. Then every existing row in every existing table gets stamped with that tenant's ID during the backfill.
I call this tenant zero. It is the customer you have understood for months, with data you already trust, running through a model you have not yet proven.
This pattern does two things, and both of them matter more than they sound.
First, it proves the multi-tenant model against real production data before any outsider touches the system. You are not testing tenancy with fake seed data and a clean schema. You are testing it with the messy, real, edge-case-riddled data your actual customer generated by using the product. If the model survives that, it will survive a second tenant.
Second, the original customer's experience never changes. They were tenant-of-one before. Now they are tenant-zero-of-one. From their seat, nothing happened. No downtime, no migration window, no "we are upgrading our systems" email.
This is what de-risks the entire project. Most single tenant to multi tenant migration disasters happen because the team validates the new model on a fresh schema and discovers the hard cases only when real data hits it in production. By reframing your existing customer as tenant one, you flip that order. You validate on real data first, strangers second.
You are doing the migration by reframing what you already have, not by rebuilding it. The data does not move. The customer does not move. You just give the thing they already own a name in a new table.
Keeping RLS helpers off the public API surface
Now the security layer. Row level security RLS is how the database itself refuses to hand one tenant another tenant's rows. But RLS policies need a trusted way to answer one question on every query: which tenant is this request acting as?
That answer comes from helper functions. And where you put those functions matters enormously.
Security-definer functions
I write the tenant-resolution helpers as security-definer functions. That means they run with the privileges of the function owner, not the caller, so they can read the tenancy tables a regular client should never see directly. Then I keep them off the public API surface entirely, so a client cannot call them, probe them, or pass them arguments to fish for another tenant's context.
The function is trusted, hidden, and called only by the policies themselves. A client never touches it.
Why this matters for isolation
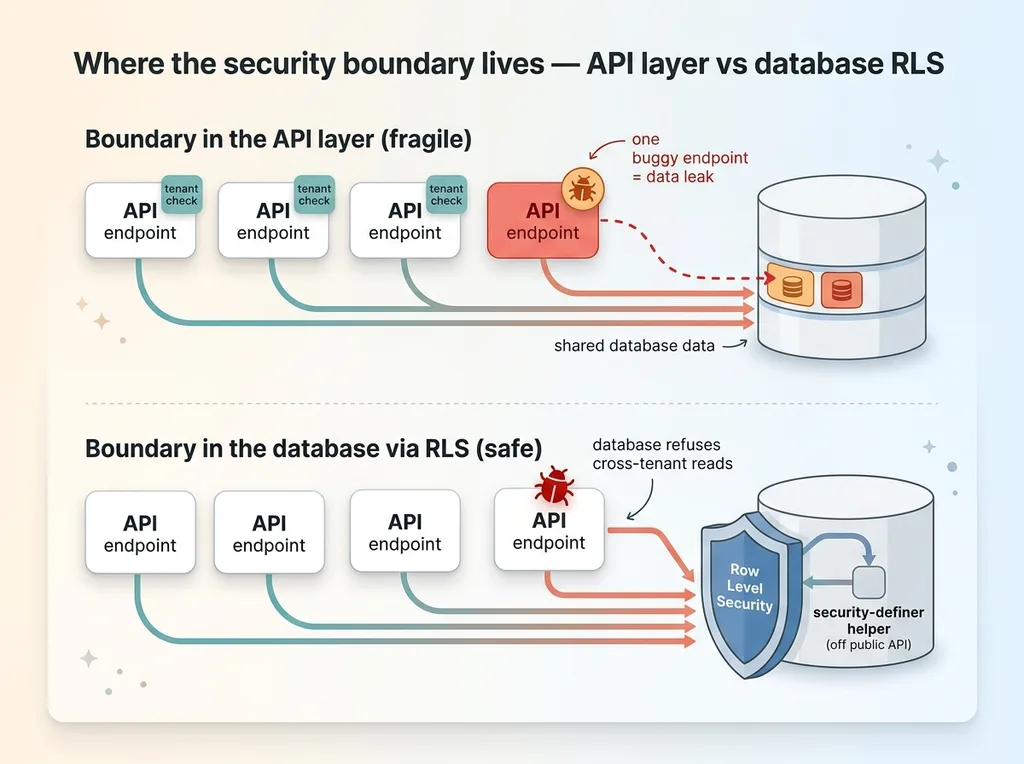
The principle here is that the security boundary lives in the database, not in the application layer. This is the thing I see teams get wrong constantly. They put the tenant check in the API, which means a single bug in a single endpoint can leak one customer's data to another.
 Where the security boundary lives, API layer vs database RLS
Where the security boundary lives, API layer vs database RLS
When the boundary lives in the database through RLS, a bug in your API cannot cross tenants. The database refuses. That is the entire argument for treating data isolation as a default, not a feature. You do not bolt isolation onto each endpoint. The floor of the system enforces it for free.
There is a real tradeoff, and I will be honest about it. Security-definer functions are powerful, which means they have to be written carefully. No dynamic SQL. A locked search_path so nobody can shim a malicious function in front of yours. If you are sloppy here, the thing meant to protect tenants becomes the hole. Treat these functions as the most security-sensitive code in the system, because they are.
Deferring RLS enforcement as a deliberate phase, not a big bang
Here is the sequencing insight that makes the whole thing safe.
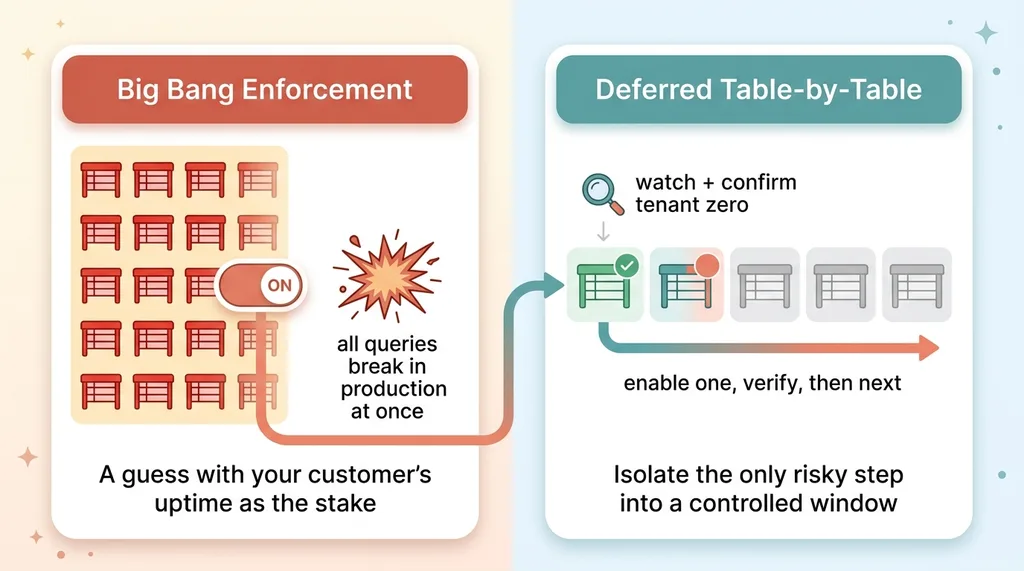 Big-bang RLS enforcement vs deferred table-by-table enforcement
Big-bang RLS enforcement vs deferred table-by-table enforcement
The scary part is not creating the policies. It is flipping enforcement on, so the database starts actively refusing cross-tenant reads. That is the moment a query written years ago, one that assumed a single owner, suddenly returns nothing and breaks a page.
So I leave that part for last, on purpose, as its own deliberate phase.
Until enforcement is flipped, the app runs on the service-role key, which bypasses RLS entirely. The policies exist. The helpers exist. The backfill is done. But nothing is enforced, so there is no behavior change and no risk while the entire spine is being built. You assemble the whole machine cold before you turn it on.
When you do enforce, you do it table by table. Backfill already complete. Tenant zero already proving the policies return the right rows. You enable RLS on one table, watch it, confirm tenant zero still sees exactly its own data, then move to the next.
Contrast that with the big bang. In the big-bang version you flip RLS on every table at once, on live traffic, and find out in production which of your hundred queries assumed a single owner. That is not a migration. That is a guess with your customer's uptime as the stake.
I lean on a consistent process for this part, the same one in the RLS playbook I use across 50+ tables, because the table-by-table discipline is what keeps it boring.
Now the honest part. Enforcement is still real work. This is the phase where you catch every query that quietly assumed one owner, and there will be more of them than you expect. But you have isolated that work into a controlled window with a known scope, instead of bundling it with schema changes, data moves, and a cutover all at once. You debug one category of problem at a time, with everything else already stable underneath you.
How risky is making it multi-tenant, really
The rewrite is the risk. The multi-tenancy is not.
Done additively, the whole thing happens with the live app untouched. Spine first as new tables and nullable columns. Tenant zero seeded from the customer you already have. RLS helpers hidden behind security-definer functions. Enforcement deferred to a deliberate, table-by-table phase. At no point does revenue stop. At no point does the original customer notice anything.
You prove the model on a real tenant, with real data, before you ever sell to a second one. That is the opposite of betting the business.
The hard part of this work is not the SQL. The SQL is straightforward once the order is right. The hard part is judgment about sequencing, knowing which step has to come before which, and which scary step you can safely defer until everything else is already proven. That judgment is what keeps a live product live.
This is exactly the kind of decision I make when I take a working tool and turn it into something you can sell to many customers. I have written before about the honest way to turn an internal tool into a paid product, and the database is usually where the real fear lives.
If you have built something that works for one customer and you want to sell it to a hundred without a rewrite that puts your existing revenue at risk, that is a conversation worth having.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call