Master Data Record Deduplication Without Breaking Anything
One employee appeared as three names across three systems. Here's how I did master data record deduplication additively, without breaking a single live query.
By Mike Hodgen
The Day Nothing About One Person Would Join
A window-treatment company called me because their COO had asked a simple question: how much did one sales rep sell last quarter, and what did we pay her in commission?
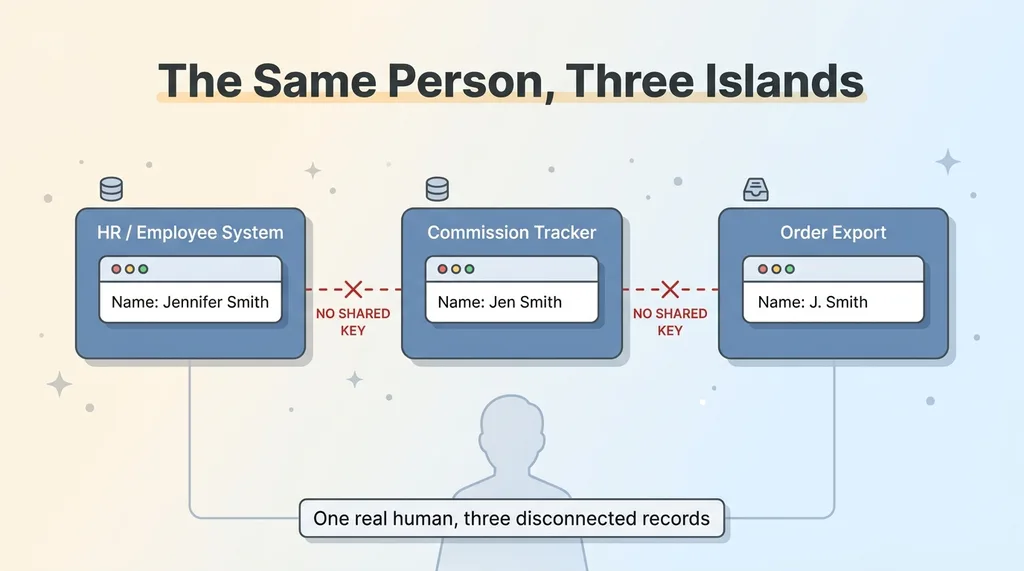 One person fragmented across three systems with no joining key
One person fragmented across three systems with no joining key
Three reports came back. Three different numbers.
The problem wasn't math. It was that one human being existed as three separate people in their systems. The employee table had her as "Jennifer Smith." The commission system listed "Jen Smith." The order export, which fed half their reporting, called her "J. Smith."
No key joined them. Not a person ID, not an employee number, nothing. Each system had its own row for her, and those rows had no idea the others existed.
So when someone tried to answer "what did this person sell and what were they paid," they were doing it by hand. Eyeballing names. Guessing which "Smith" was which. And every report that touched both selling and payment data was a manual reconciliation that took the better part of a day and still produced numbers nobody fully trusted.
This is what master data record deduplication actually looks like in a small company. It isn't an abstract data-quality score on a dashboard. It's commissions floating in one island, assignments in another, and no single place to manage any actual person.
The COO's real question, the one underneath the reporting question, was the one I hear most: our records are a mess, can this be cleaned up without a risky big-bang migration that breaks payroll?
Yes. And I'll show you exactly how, because the answer is more about discipline than cleverness.
Why Duplicate Records Happen (And Why They Quietly Cost You)
Three systems, three naming conventions
This was not a typo problem. It was structural.
Each system was adopted at a different time, by different people, for a different reason. The HR system came first. The commission tracker came later, built by whoever ran sales at the time. The order export was bolted on when they needed reporting. Nobody ever agreed on a shared person ID.
The root cause was free-text name fields. When the only thing identifying a person is a name someone typed, you get "Jen Smith" in one place and "Jennifer Smith" in another and "J. Smith" in a third. All correct. All referring to the same woman. None of them joinable.
The hidden cost: nothing can be joined
Without a canonical key, every cross-system report is a guess.
Commissions get misattributed because the system can't confidently match a sale to a payout. Assignment routing sends the wrong installer because the name didn't match cleanly. Somebody spends a full day reconciling spreadsheets, and the output is still soft.
The deeper cost is trust. Once a blended report has burned you twice with wrong numbers, you stop believing any of them.
The discipline that fixes this is called entity resolution: deciding when two records refer to the same real-world thing. Most small companies do entity resolution in someone's head. They just know "J. Smith" is Jennifer. That works until that person leaves, or the data grows, or an auditor asks you to prove it. It doesn't scale and it doesn't survive scrutiny.
Why I Didn't Do a Big-Bang Migration
The instinct, when you see a mess like this, is to rip it out. Rebuild the schema clean, define proper IDs, migrate everything at once, flip the switch over a weekend.
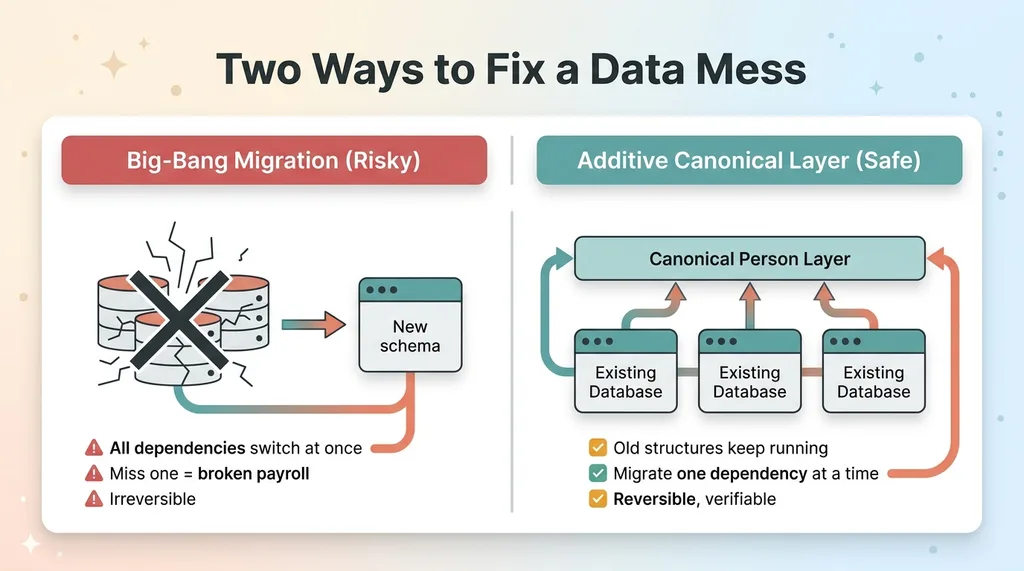 Big-bang migration vs additive canonical layer
Big-bang migration vs additive canonical layer
That is the single riskiest path available.
Every live query depends on the current shape of the data. Every report, every scheduler filter, every nightly export, every commission calculation. Some of those dependencies are documented. Most are not. They live in a query someone wrote three years ago that quietly runs payroll.
Miss one, and you don't find out at deploy time. You find out when paychecks are wrong or the install crew shows up at the wrong house.
So I set one rule and never broke it: every step had to be additive. Nothing live could break.
Instead of demolishing and rebuilding, you add a canonical layer alongside the existing mess. The old structures keep running exactly as they did. Then you migrate dependencies onto the canonical layer one at a time, on your schedule, with the ability to verify each one before moving to the next.
This is the direct answer to "can it be cleaned up without a risky migration." Yes, additively. You build toward a single source of truth by layering it on, not by detonating what already works.
The whole job becomes a series of small, reversible moves instead of one irreversible gamble.
Step One: Pick a Canonical Person Record and Link by ID
The employee table becomes the source of truth
The first decision is the most important: which system holds the real person?
I picked the employee table. It already had the most complete data, and crucially, it had a stable ID that didn't change when someone's name got typed differently. That's the test for choosing a canonical record. You want the system with the most authoritative, slowest-changing data, not the one that's most convenient to query.
Commission reps point to it, not the other way around
Once the employee table was canonical, I linked the commission reps to it by that stable ID. A real foreign key. From that point forward, the connection between a commission rep and a person was a key, not a name match.
Here's the part that keeps it safe: this is additive.
The commission system kept its own row for Jennifer. I didn't delete it or move it. I added a reference field that pointed that row at the canonical person ID. Existing joins by name still worked exactly as before. New joins by ID became possible alongside them.
Nothing that was running stopped running. The old name-matching reports kept producing the same output. But now there was a clean path to ask "give me everything tied to this person ID" and actually get a complete answer.
The order export, being downstream, didn't get its own copy of the truth. It resolved through the canonical record. Downstream systems should hold references, not facts. The moment three systems each believe they own the truth about a person, you're back where you started.
This is the foundation of unifying people into a single canonical record, and everything after it depends on getting this one choice right.
Step Two: Reconcile the Name Mess Without Deleting History
Keep stale names as resolvable aliases
Now the names. The obvious move is to "fix" them all to one spelling and move on.
That breaks history.
Those three names were not wrong. They were historical. Old commission records referenced "Jen Smith." Past order exports said "J. Smith." Prior reports were built against specific spellings. If you overwrite or delete them, you orphan every record that pointed at them.
So instead of deleting, I built an alias table. Every historical spelling mapped to the one true person ID. "Jen Smith," "Jennifer Smith," and "J. Smith" all became aliases of the same canonical person.
Why deleting the old names would break things
Now a lookup by any of those spellings resolves to the same person.
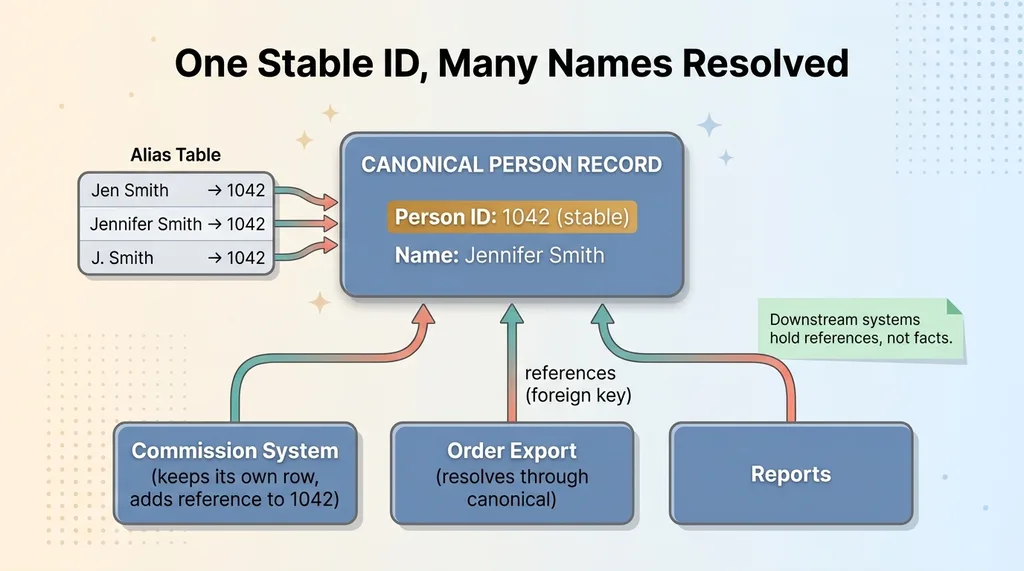 Canonical person record with references and alias resolution
Canonical person record with references and alias resolution
This is alias reconciliation, and it's a core entity resolution pattern. You unify the present without erasing the past. The audit trail stays intact. If someone needs to know what a 2022 report actually said, the original spelling is still there, now correctly pointed at the right human.
The concrete payoff was immediate. A blended report that used to miss Jennifer's commission entirely, because the name on the sale didn't match the name on the payout, now resolved both through the alias table and joined cleanly. The number was finally right, and it was right for a reason you could explain.
That's the difference between a clean dataset and a trustworthy one. A clean dataset looks tidy. A trustworthy one can show its work.
Step Three: Let One Person Hold Multiple Roles Safely
A multi-role array, with the primary role preserved
The next structural crack: one person could be both a sales rep and an installer. But the schema assumed one role per person, period.
That's why the same human was being maintained in two different role-specific tables, with all the duplication that implies.
The fix was to add a multi-role array so a person could carry several roles at once. Sales rep and installer, in one record.
Why the scheduler's existing filter never noticed
Here's the trap. The scheduler filtered on a single primary-role field. If I'd replaced that field with the array, the scheduler would have broken instantly, and installs would have stopped routing.
So I didn't replace it. I kept the primary-role field exactly as it was and added the array alongside it.
The scheduler's existing filter kept working, completely unchanged. It read the primary role like it always had. Meanwhile, new logic could read the array when it needed the full picture of what someone did.
This is the additive pattern in miniature: extend, don't replace.
And it ties straight back to entity resolution. Once you have a unified person record that can hold multiple roles, you stop maintaining the same human in two separate tables. One person, one record, multiple roles. The duplication that caused half the original mess simply goes away, without any running system noticing the floor moved under it.
Step Four: Date the Tier Changes Instead of Rewriting Them
Effective-dated commission history
The last unifying move was the subtlest, and the one that quietly corrupts the most money.
Commission tiers changed over time. A rep might be at one tier last year and a higher tier now. But the schema only stored the current tier. So when anyone recalculated a past payout, it used today's tier, not the tier that was actually in effect back then.
A tier bump silently rewrote history. Last year's commission would recompute to a number that was never true.
A tier change should never alter a past payout
The fix is effective dating. Each tier carries a start date. Any historical payout gets computed against the tier that was in effect on that date, not whatever the tier happens to be now.
 Effective-dated commission tiers vs single current-tier overwrite
Effective-dated commission tiers vs single current-tier overwrite
Additive, same as everything else. I added a dated history table and backfilled the current tier as the latest record. Existing reads that just wanted "current tier" kept working without a change. New logic could ask "what was this person's tier on this date" and get the right answer.
Effective dating is how you keep the past correct while letting the present change. It's not a commission concept. It's a data discipline that applies anywhere history matters.
One caution worth stating plainly: after a change like this, you'll recalculate everything and compare to the old numbers. If they match perfectly, it's tempting to call it done. But a migration that hits zero variance can still be broken. Matching the old numbers can mean you reproduced the old bug. Validation has to be smarter than "the totals agree."
Proving Nothing Broke, and What This Buys You
Because every step was additive, the proof was almost boring, which is exactly what you want.
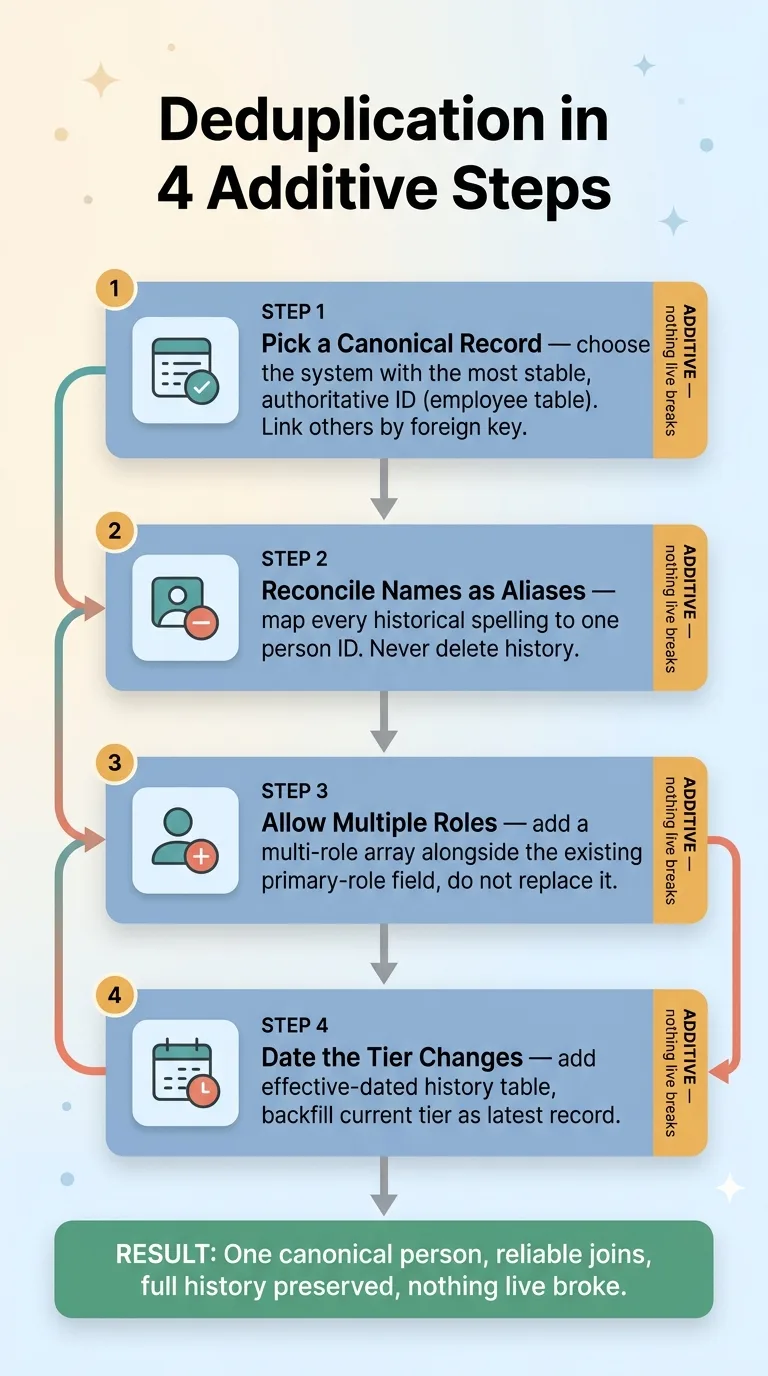 The four additive steps of safe deduplication
The four additive steps of safe deduplication
Every live query, report, and export ran unchanged before and after the work. Identical output. The name-matching reports still matched names. The scheduler still filtered on primary role. The current-tier reads still returned the current tier.
What changed was what became newly possible. ID-based joins now worked. Alias lookups resolved. The multi-role array was there for any new logic that wanted it. The dated tier history was ready for accurate recalculation.
No big-bang. No weekend downtime. No broken payroll. No install crew at the wrong house.
The payoff for the COO was the thing he asked for in the first meeting: one canonical person record, reliable joins between commissions and assignments, full history preserved, and the ability to answer "how much did this person sell and what were they paid" in a single query that returns one number you can defend.
Most companies live with this kind of mess for years. Not because they don't see it, but because the cleanup feels too risky to start. They assume fixing it means a rewrite, and a rewrite means betting payroll on a migration.
It doesn't have to be a rewrite. It can be additive layers added on top of what you already run, verified one at a time, with nothing live ever at risk.
If your records are a tangle of duplicates and mismatched names, the first thing to do is look at the actual shape of the data before anyone touches it. That's where I start. Have me look at your data mess and I'll tell you what's actually going on before we change a single field.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call