Plaid Integration Architecture: One Layer, Many Products
How I built Plaid integration architecture as shared infrastructure across five products instead of bolting a separate bank-data integration onto each one.
By Mike Hodgen
Five products, five bank-data problems, one bad default
I have five separate projects on my plate right now, and every single one needs to talk to a bank. None of them need it for the same reason.
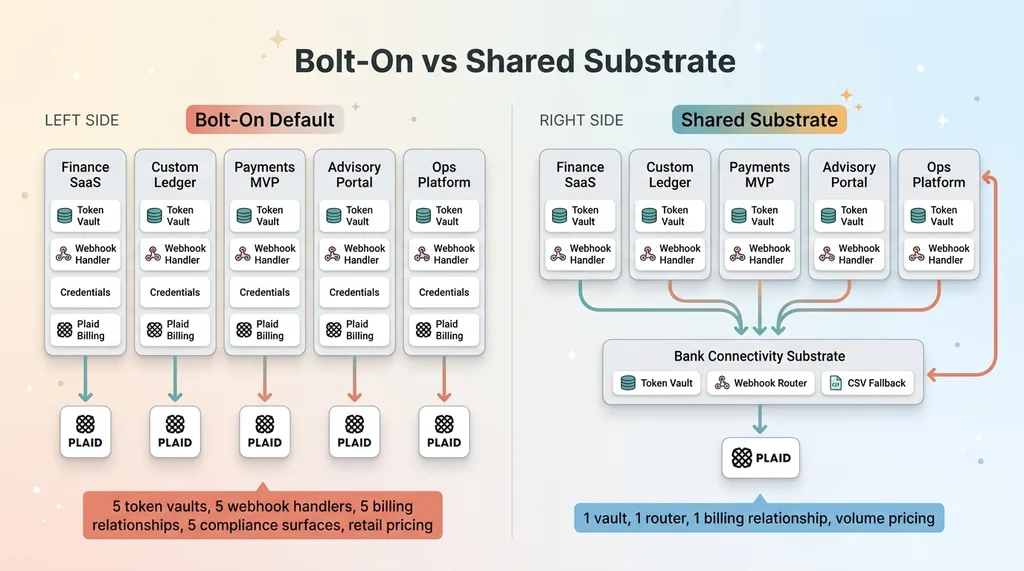 Bolt-on vs Shared Substrate comparison
Bolt-on vs Shared Substrate comparison
An e-commerce finance SaaS needs transaction data to categorize spend. A custom ledger I built for a brand I run needs account balances and reconciliation feeds. A payments MVP needs ACH to move money. A financial advisory firm I work with needs account aggregation for a client portal. And a window-treatment ops platform wants to offer working capital to its contractors, which means KYC and underwriting.
Different jobs. Same underlying need: a reliable pipe into bank data.
The lazy default every engineering team reaches for is to implement Plaid inside each app. It feels right. The product needs bank data, so you wire Plaid into that product. Ship it. Move on.
Do that five times and look at what you've built: five token vaults, five webhook handlers, five sets of credentials to rotate, five separate billing relationships with Plaid, and zero volume pricing because no single product hits enough volume to matter. You've also created five separate compliance surfaces, which is five times the audit work and five times the places a credential can leak.
I want to be straight with you up front. This is a plan in progress, not five shipped products running on a unified backbone. Some of this is live, some of it is on the whiteboard. But the plaid integration architecture question underneath it is one I had to answer before writing a line of code, and it's the same question any company building more than one data-driven product eventually faces.
Should you rebuild the same integration in every product? Or should bank connectivity be infrastructure that every product draws from?
That's what this whole piece works out.
Bank connectivity is infrastructure, not a feature
The primitive vs. the logic
Plaid is a primitive. Connecting to a bank, fetching a list of transactions, initiating an ACH transfer, running an identity check. These are commodity capabilities. Plaid sells them, Teller sells them, MX sells them. You rent the pipe.
The differentiation is never in the connection. It's in what you do with the data once it arrives.
How you reconcile a ledger against a brand's actual deposits. How you score a contractor for a loan. How you flag a cash crunch three weeks before it hits. That logic is your product. The bank connection is plumbing that gets you the raw material.
This is the pay for primitives, build the logic principle, and it applies cleanly here. You pay once for the bank data API primitive. You build the business logic many times, because that's where the value lives.
Why five integrations is five times the liability
Now flip it. When you implement the same primitive five times, you multiply the surface area for bugs, security holes, and compliance exposure without adding a dollar of differentiated value.
Plaid ships a breaking change to a webhook payload. With one integration, you patch one place. With five, you patch five, and you'd better hope all five teams noticed the changelog.
A token-handling bug in one app is a contained problem. The same bug copy-pasted across five apps is five separate incidents waiting to happen, on five different timelines, discovered by five different people who may not talk to each other.
Five integrations isn't five times the work. It's five times the liability. And none of that duplicated effort makes any of your products better.
The substrate: one account, per-project sub-tenants
Portfolio-level account
Here's the shape of the fix. One Plaid account at the portfolio level. The parent. All five products connect through it.
The practical wins are immediate. One billing relationship means volume pricing kicks in across all five products combined, instead of five accounts each sitting at low volume paying retail rates. One set of credentials to rotate when it's time to rotate. One place to manage Plaid product access, so when I want to turn on Identity for the underwriting use case, I flip it on in one console.
Sub-tenant isolation per project
But one account does not mean one undifferentiated blob of data. Each of the five products is a sub-tenant with its own scoped namespace inside the shared substrate.
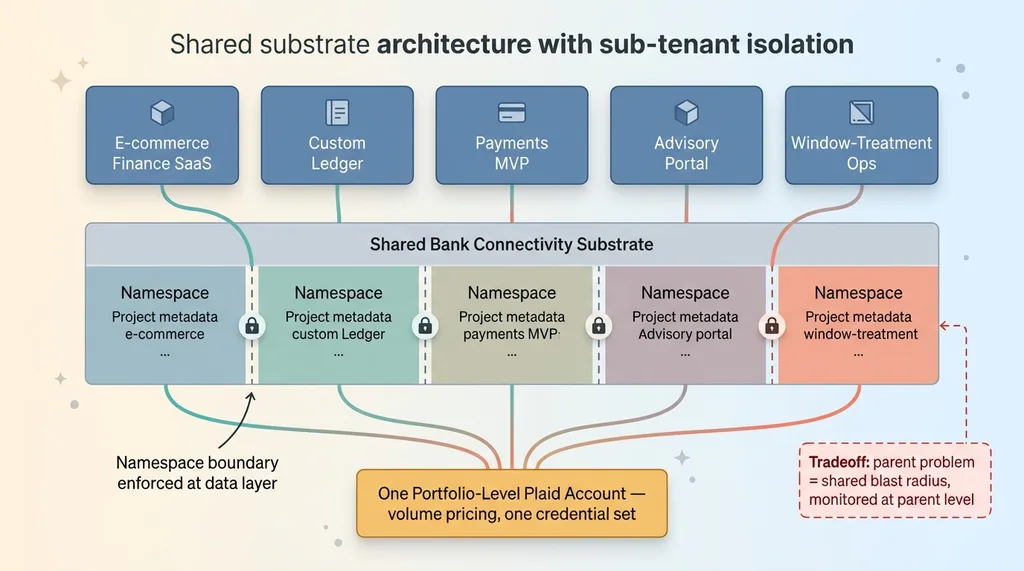 Shared substrate architecture with sub-tenant isolation
Shared substrate architecture with sub-tenant isolation
This is shared infrastructure multi-product done right. The substrate is shared. The data is not.
The sub-tenant for the advisory firm must never see items belonging to the payments MVP. Ever. Every item gets tagged with project metadata the moment it's created, and every query is scoped to its project. Data does not leak across tenants, because the namespace boundary is enforced at the data layer, not left to application code to remember.
This mirrors the same client-data-isolation principle I apply everywhere I handle data for more than one party. Shared infrastructure, isolated data.
Now the honest tradeoff. Coupling five products to one Plaid account means a problem at the parent affects everyone. If the account gets rate-limited or suspended, all five products feel it. That blast radius is real, and you manage it deliberately: monitoring at the parent level, alerting before you hit limits, and a clear plan for what happens if the parent has a bad day. You don't pretend the tradeoff doesn't exist. You price it in.
One encrypted token vault for every product
Field-level encryption at rest
The token vault is the heart of this whole thing, and it's where I spend the most care.
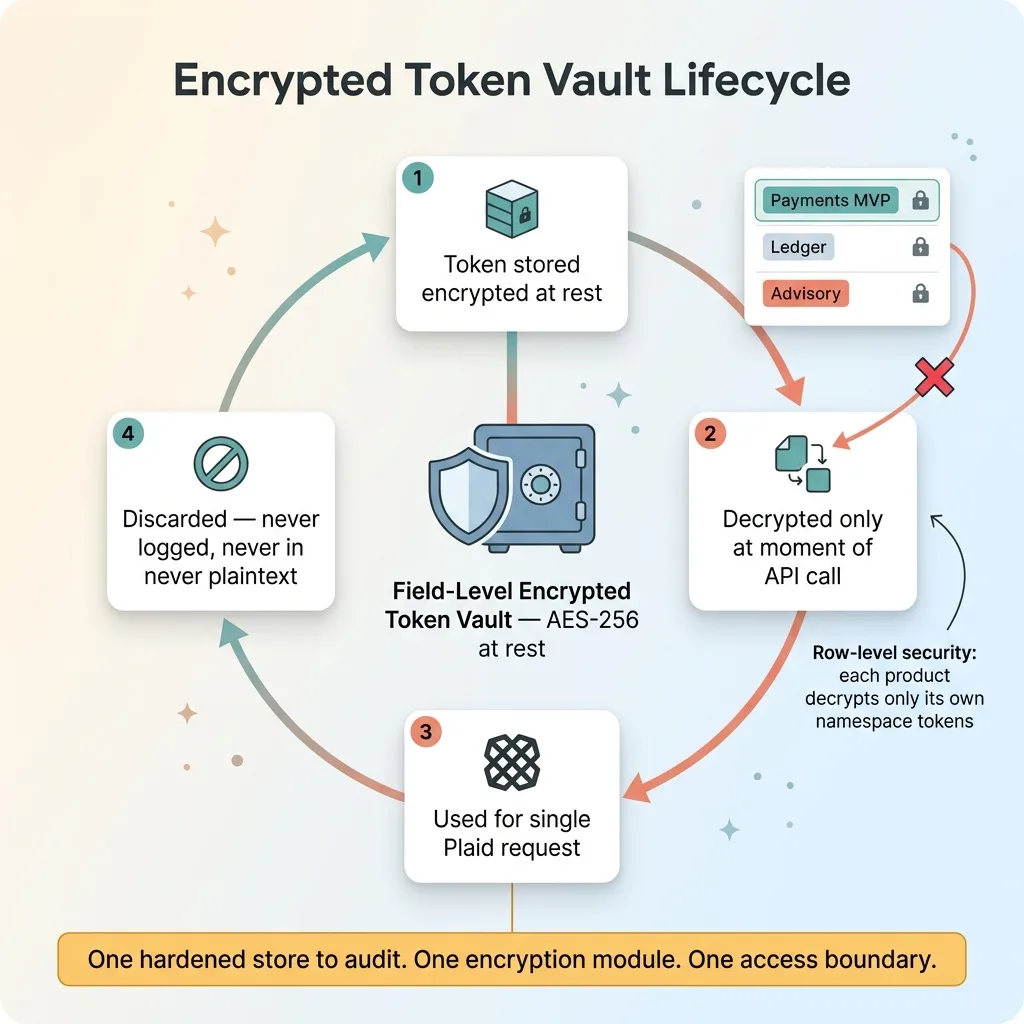 Encrypted token vault lifecycle and access scoping
Encrypted token vault lifecycle and access scoping
A Plaid access token is not a low-stakes credential. It is a key to a business's bank account and its books. If one leaks, the damage isn't a marketing inconvenience. It's somebody's financial data exposed.
So there's a single field-level-encrypted token vault that all five products read from. Tokens are encrypted at rest with AES-256. They're decrypted only at the exact moment of an API call, used, and discarded. They are never logged. They are never committed to a repo. They never sit in plaintext anywhere they could be scraped.
This is the encrypt those tokens at rest discipline applied to the highest-stakes data in the system.
Why tokens never live in app code
Centralizing the vault is safer than running five separate ones, and the reason is simple. One hardened store to audit. One encryption module to get exactly right. One access-control boundary to defend.
Contrast that with the bolt-on pattern, where each app stores tokens however the developer happened to wire it that day. One app uses environment variables. One stuffs them in a database column in plaintext because it was a Friday. One logs them by accident in a debug statement nobody removed. Five integrations means five chances to get the most dangerous part wrong.
Inside the shared vault, row-level security and access scoping keep the payments MVP from ever reading the ledger's tokens. Each product can only decrypt the tokens tagged to its own namespace. The fintech token vault is the one component I'd rather over-engineer than under-engineer, because everything else is recoverable and this isn't.
One webhook router that fans out by item metadata
Plaid talks back to you constantly. Transaction updates, item errors, re-auth requirements, new account detections. These all arrive as webhooks.
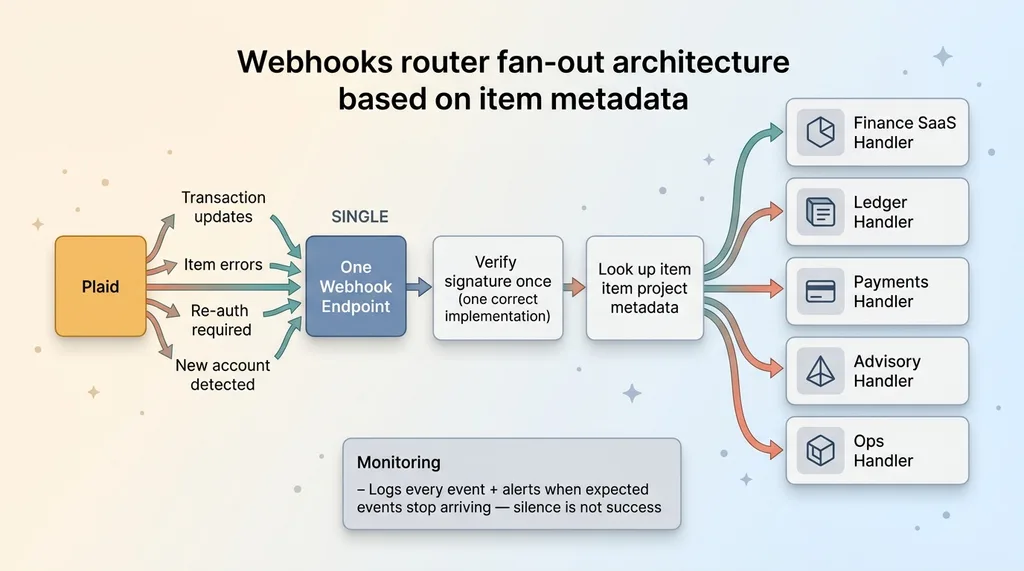 Webhook router fan-out by item metadata
Webhook router fan-out by item metadata
The bolt-on pattern gives you five webhook endpoints, five separate signature-verification implementations, and five places where a silent failure can hide for weeks before anyone notices the transaction data went stale.
The substrate has one webhook endpoint. It verifies the signature once, against one correct implementation. It looks up the item's project metadata, figures out which product the event belongs to, and fans the event out to that product's handler.
One place to verify. One place to monitor. One place to add support for a new event type when Plaid ships one.
And the router has to be honest. A webhook router that silently drops events is worse than no router, because it gives you false confidence that data is flowing when it isn't. So it logs every received event and alerts when expected events stop arriving. Silence is not success. If the transaction webhooks for a given item go quiet, I want to know that day, not at month-end reconciliation.
The frontend gets the same treatment. Instead of five copy-pasted Plaid Link integrations that slowly drift apart, there's one reusable React hook that any product imports to launch Plaid Link. One drop-in component, one place to update when the Link flow changes, no drift.
The CSV fallback nobody plans for (but everyone needs)
Here's the part most teams skip, and it's the part that decides whether your product works for everyone or just most people.
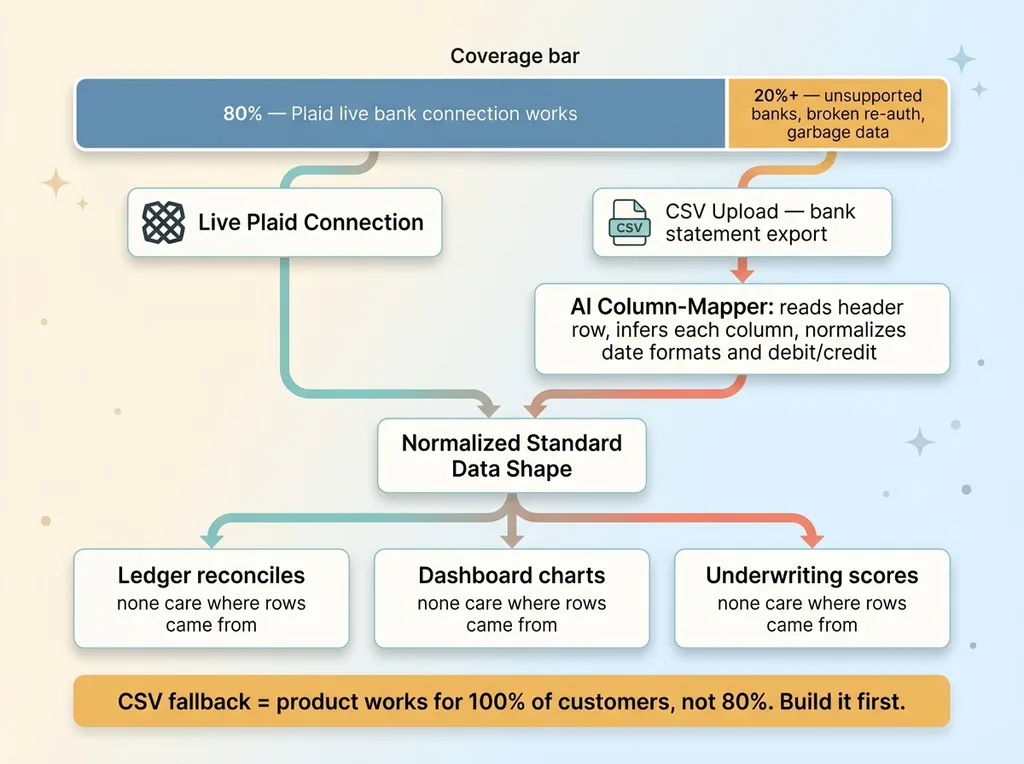 CSV fallback covering the customers Plaid misses
CSV fallback covering the customers Plaid misses
Plaid's bank coverage has real gaps. Some banks aren't supported at all. Some connections break and refuse to re-auth no matter what the customer does. Some business accounts simply don't aggregate cleanly, returning partial or garbage data. If your entire product assumes a live bank connection, every one of those customers is dead in the water the moment they sign up.
That's not a small slice. Depending on your customer base, it can be twenty percent or more.
So every product in the substrate has a mandatory CSV fallback. Any customer can upload a bank statement export or a transaction CSV, and the same downstream logic runs as if the data had come straight from Plaid. The ledger reconciles it. The dashboard charts it. The underwriting engine scores it. None of them care where the rows originated, because the data shape is normalized before it reaches them.
This is where an AI column-mapper earns its keep. Every bank's CSV export looks different. Different column names, different date formats, different ways of representing a debit versus a credit. Hand-coding a parser for each one is a losing game. An AI mapper reads the header row, infers what each column means, and normalizes it into the standard shape. New bank, new format, no new code.
I'll say it plainly. The CSV fallback is not a nice-to-have. It's the difference between a product that works for 100% of your customers and one that works for the 80% Plaid happens to cover cleanly. Build it first, not last.
Where the money is: underwriting on data nobody else has
Now the payoff. The reason the whole architecture is worth the trouble.
The window-treatment ops platform wants to offer capital to its contractors. To underwrite a loan, it pulls Plaid bank data: cash flow, balances, deposit patterns, the financial pulse of the business.
But it doesn't stop there. It already holds proprietary operational data on every one of those contractors. The job pipeline. Completed installs. Payment history. Supplier terms. It knows which contractors have steady work booked three months out and which ones are running thin.
A bank underwriting that same contractor sees one thing: the bank account. This platform sees the bank account plus the actual operating signal of the business.
That combination is a moat no standalone lender can copy, because they don't have the operational data and they never will. This is underwriting on operational data nobody else has, and it's the highest-LTV use case in the whole portfolio.
Here's the strategic point. The shared substrate is what makes this affordable to build. The bank-data primitive was already solved once, for all five products. The token vault exists. The webhook router exists. The CSV fallback exists. So the only thing that actually needed building was the differentiated logic: the underwriting model itself. That's where the engineering time goes, because that's the only part that's a moat.
When to build the substrate and when to skip it
Let me be honest about the decision, because the substrate is not always the right call.
If you have one product that needs bank data, do not build a shared substrate. Integrate Plaid directly into that product and move on. The substrate is overhead you don't need, and you'd be solving a portfolio problem you don't have.
The substrate pays off when you have, or genuinely will have, multiple products drawing from the same primitive. When combined volume makes volume pricing matter. When you'd rather defend one security boundary than five.
This is a build vs. buy decision at its core. You buy the primitive. You build the substrate and the logic on top. The line between those two is the line between commodity and moat.
And again, this is a plan in progress, not a finished platform. That's exactly how I think these things through before committing engineering time. I'd rather draw the architecture, find the tradeoffs, and decide deliberately than rebuild the same integration five times by reflex.
Because that's what most teams do. They default to rebuilding the same connection in every app, and nobody stops to ask whether it should be infrastructure instead. Asking that question early, before five duplicate integrations exist, is the kind of call that saves a year of cleanup.
Thinking about AI for your business?
If this resonated, let's have a conversation. I do free 30-minute discovery calls where we look at your operations and identify where AI could actually move the needle.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call