Building an AI Audio Compliance Pipeline
How I built an AI audio compliance pipeline that transcribes radio content and audits it against the rulebook, handling MIME quirks and serverless timeouts.
By Mike Hodgen
The Problem: Your Rulebook Is Written for Text, Your Content Is Audio
A regulated financial firm I worked with runs content on the radio. Every word spoken on air is subject to compliance rules. Disclosures, risk language, prohibited claims, the works. But here's the catch that nobody planned for: the entire rulebook was written for text.
You cannot audit audio you cannot read. That sentence is the whole problem in one line. An ai audio compliance pipeline exists to solve exactly this gap, because compliance covers the spoken word, but every rules engine you'd ever want to run needs a text representation to evaluate.
The doubt I hear from buyers in regulated spaces is direct: can AI actually handle our audio? Our podcasts, our broadcast spots, our recorded calls? Or is this only good for marketing copy and web pages?
The honest answer is yes, AI can handle your audio. But only if you respect what makes audio different from text. Treat a radio spot like a blog post and you'll fail in ways that have nothing to do with how smart your model is.
Consider the math. A 4-minute radio spot is several hundred spoken words. Every one of those words is on the record. Every required disclosure has to be said out loud, in a tight window, with no footer to hide in. If your review process only checks the written script and not what actually aired, you're auditing a document that may not match the broadcast.
So the job splits into two distinct problems. First, turn the audio into faithful text. Then run judgment against that text. The firms that get this wrong usually fail at the first step, and they fail in boring, unglamorous ways.
Why Naive Audio Handling Fails in Unglamorous Ways
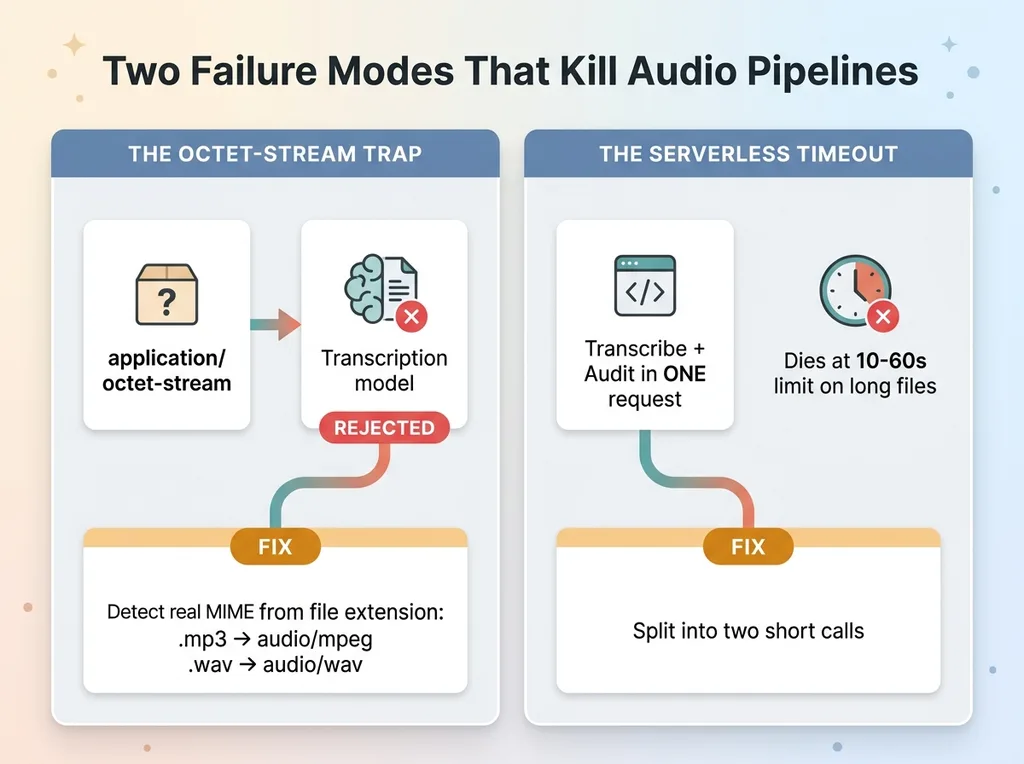
Before any compliance logic runs, two specific failure modes will bite you. Neither is exciting. Both kill projects.
 Two Unglamorous Failure Modes (octet-stream and serverless timeout)
Two Unglamorous Failure Modes (octet-stream and serverless timeout)
The octet-stream trap
When a browser or a command-line tool uploads an audio file, it often labels the file with a generic content type: application/octet-stream. That's the digital equivalent of a box marked "stuff." The transcription model takes one look, can't tell whether it's an MP3 or a WAV, and rejects it.
You uploaded a perfectly valid audio file and got an error that looks like the model is broken. It isn't. The upload header lied, or said nothing useful at all.
The fix is to stop trusting the upload header. I detect the real MIME type from the filename extension and coerce it before the file ever reaches the transcription step. An .mp3 gets stamped audio/mpeg, a .wav gets audio/wav, and the model accepts it without complaint.
This is audio mime type handling, and it's the single most common reason a working pipeline appears to fail in testing. Nobody warns you about it because it's not in any tutorial. It's in the gap between the tutorial and production.
The serverless timeout
The second failure shows up once the files get longer. You build a single serverless function that transcribes the audio and audits the transcript in one request. It works fine on a 30-second clip. Then someone uploads a 6-minute interview and the function dies mid-execution.
Serverless platforms cap how long a single request can run, often around 10 to 60 seconds depending on your tier. Transcription plus audit on a long file blows straight past that limit. The request times out, the user sees a generic error, and the content never gets reviewed.
These are not glamorous problems. They're plumbing. But plumbing is exactly what separates a demo that works on stage from a system that runs every day. Get the MIME coercion and the timeout decomposition right, and the rest of the pipeline becomes almost boring. Which is the goal.
The Two-Stage Pipeline: Transcribe, Then Audit
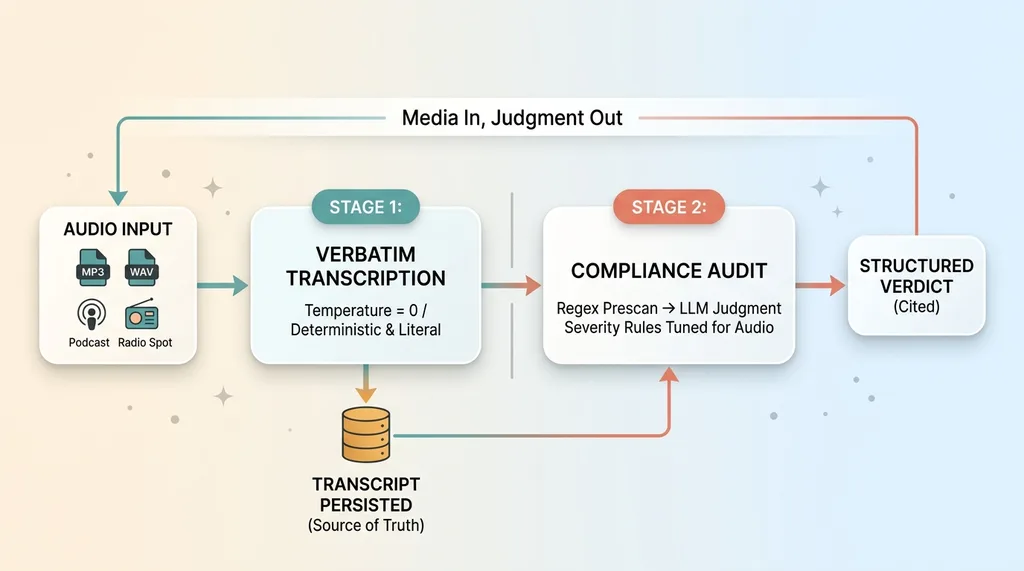
The architecture that works is deliberately simple. Two stages, each doing one job. Don't let one model try to listen and judge at the same time.
 Two-Stage Transcribe-Then-Audit Pipeline
Two-Stage Transcribe-Then-Audit Pipeline
Stage one: verbatim transcription at zero temperature
The first model transcribes the audio verbatim at zero temperature. Both of those choices matter.
Verbatim matters because compliance cares about exactly what was said, not a cleaned-up paraphrase. If the host mumbled a disclosure or skipped a word, I need that in the transcript. A model that "helpfully" tidies the language is destroying the evidence I'm trying to audit.
Zero temperature kills creative drift. At higher temperatures, transcription models start guessing and smoothing. At zero, the output is as deterministic and literal as the model can manage. For transcribe audio for compliance work, deterministic and literal is the entire point.
Stage two: audit the transcript against the rulebook
Once I have a faithful transcript, the second model audits it against the rulebook, the same way a text audit would run on any written document. This is where the compliance logic lives, and it's the same engine I describe in my piece on building an AI that audits radio ads in 60 seconds.
The auditor doesn't start with the model, though. It starts deterministically. I run a regex first, a model second approach, where a fast pattern prescan catches the obvious violations and feeds clean context to the model for the judgment calls. Cheaper, faster, and more reliable than throwing the whole transcript at an LLM and hoping.
The design principle underneath all of this: separate the media-to-text problem from the text-to-judgment problem. Each stage does one job and does it well. That separation is what makes the system maintainable, and it's a "media in, structured judgment out" pattern that generalizes to video, recorded calls, webinar replays, any spoken content at all.
Splitting the Work Into Two Calls So Nothing Times Out
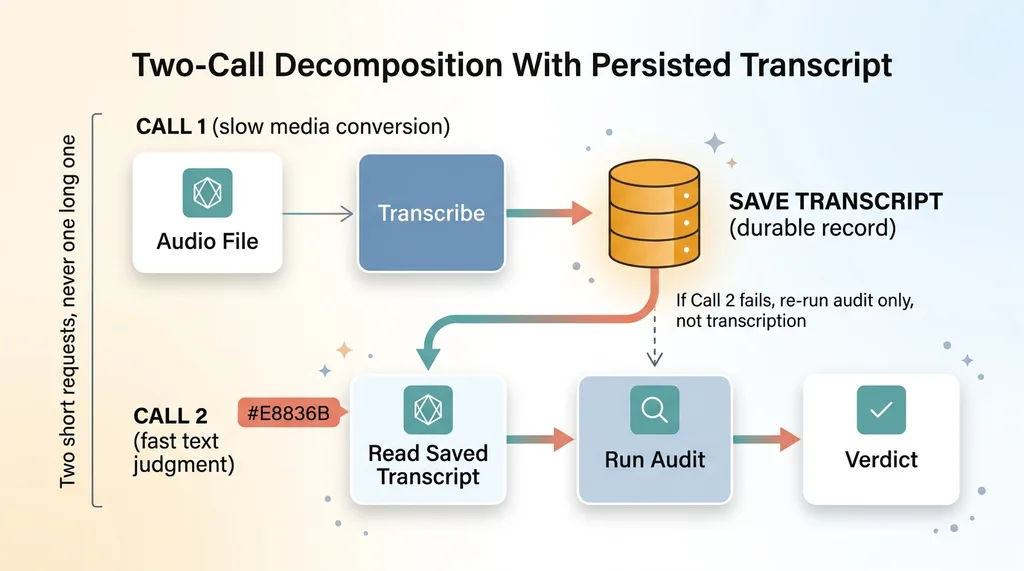
Remember the serverless timeout from earlier? Here's the correct fix, and I want to be clear it's not a hack. It's the right decomposition.
 Two-Call Decomposition With Persisted Transcript
Two-Call Decomposition With Persisted Transcript
Instead of one request that transcribes and audits, I split the work into two separate client calls. Neither call carries the full weight, so neither blows the execution limit.
The first call transcribes the audio and returns. That transcript gets persisted immediately. Only then does a second call run the audit against the saved transcript. Two short requests instead of one long one. This is the same decomposition I use elsewhere when splitting work so neither call blows the time limit keeps a system responsive.
Persisting every transcript is the part that earns its keep operationally. If the second call fails for any reason, the transcript is already saved. Nothing is lost. You re-run the audit, not the whole expensive transcription. And you accumulate an auditable record of exactly what was said on every piece of content, which is itself a compliance asset.
The raw transcript becomes the source of truth. The audit verdict can be regenerated, re-reviewed, or escalated to a human, but the underlying text it judged is fixed and stored. That's exactly what you want when a regulator asks you to prove what aired and what you checked.
People reach for the single-function approach because it feels simpler. One request, one response, done. But "simpler" that times out on real files isn't simpler, it's broken. The two-call split matches the actual shape of the problem: a slow media conversion followed by a fast text judgment, with a durable record in between. When the architecture mirrors the work, the system stops fighting you.
Why a Missing Disclosure on Air Is Critical, Not Minor
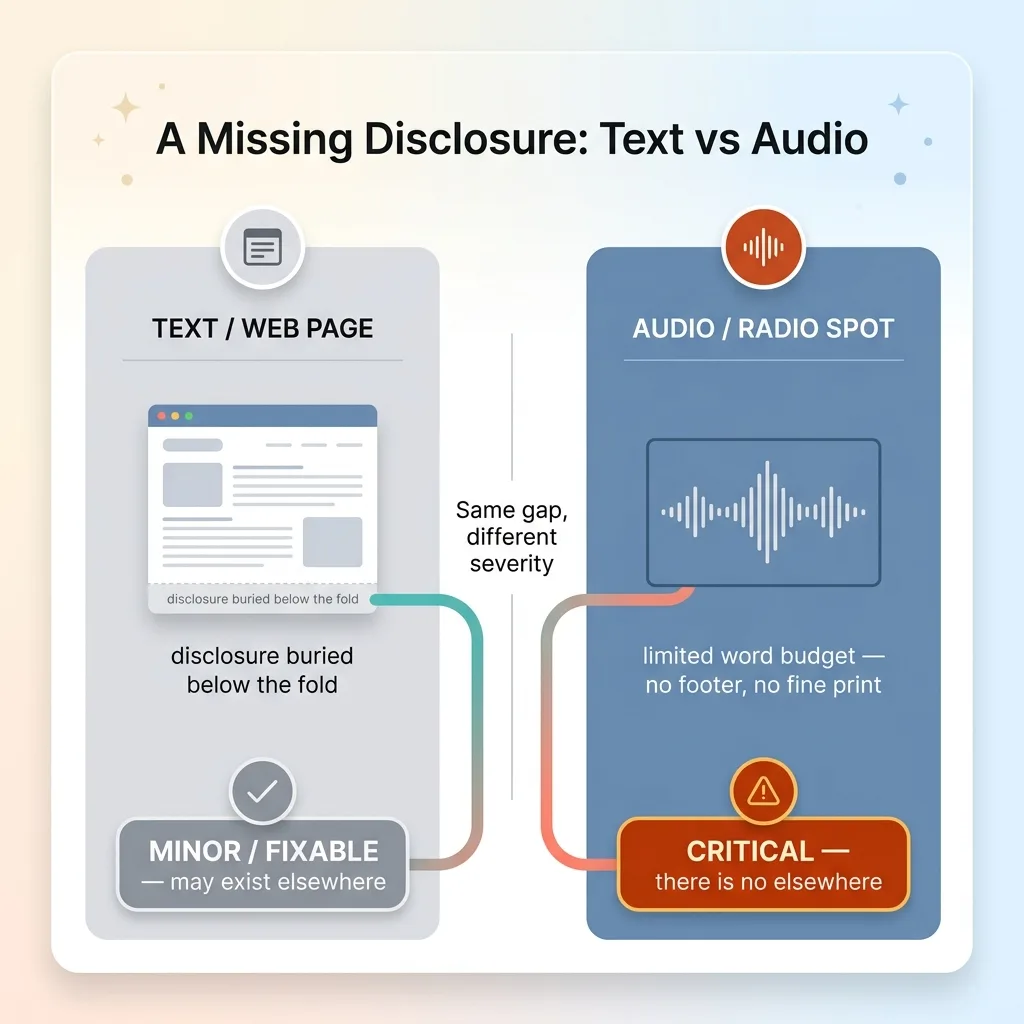
Here's the domain insight that makes audio genuinely harder than text, and it has nothing to do with transcription quality.
 Audio vs Text Severity Logic for Missing Disclosures
Audio vs Text Severity Logic for Missing Disclosures
Spoken audio has no on-screen disclosures. No fine print. No footer. No small grey text at the bottom of the page.
A web page can technically satisfy a disclosure requirement by burying it in 8-point type below the fold. Ugly, but it's there, and a text auditor will find it. A radio spot has no such surface. If the required disclosure isn't spoken out loud, in the spot's tight word budget, it does not exist anywhere.
That changes the severity logic completely. In a text audit, a missing disclosure might land as a minor or fixable issue, because maybe it's elsewhere on the page. In an audio audit, a missing critical disclosure is critical, full stop, because there is no other surface where it could legally live.
I encoded this directly into the audit prompt and the severity rules. When the auditor evaluates a transcript and finds a required disclosure absent, it doesn't hedge. There's no "perhaps it appears elsewhere" fallback, because in audio there is no elsewhere. The medium itself raises the stakes, and the system knows it.
This is the difference between an AI that processes words and an AI that understands the medium those words live in. A generic text auditor pointed at a transcript would under-flag every missing disclosure, treating the most dangerous gap in a broadcast as a footnote.
So when a buyer asks whether AI can handle their broadcast content, this is what I mean by yes. Not yes because it can read a transcript. Yes because the system was built to respect how audio actually works, including the parts that make it riskier than text.
A Reference Pattern for Any 'Media In, Judgment Out' Workflow
Step back and the shape of this pipeline applies far beyond radio.
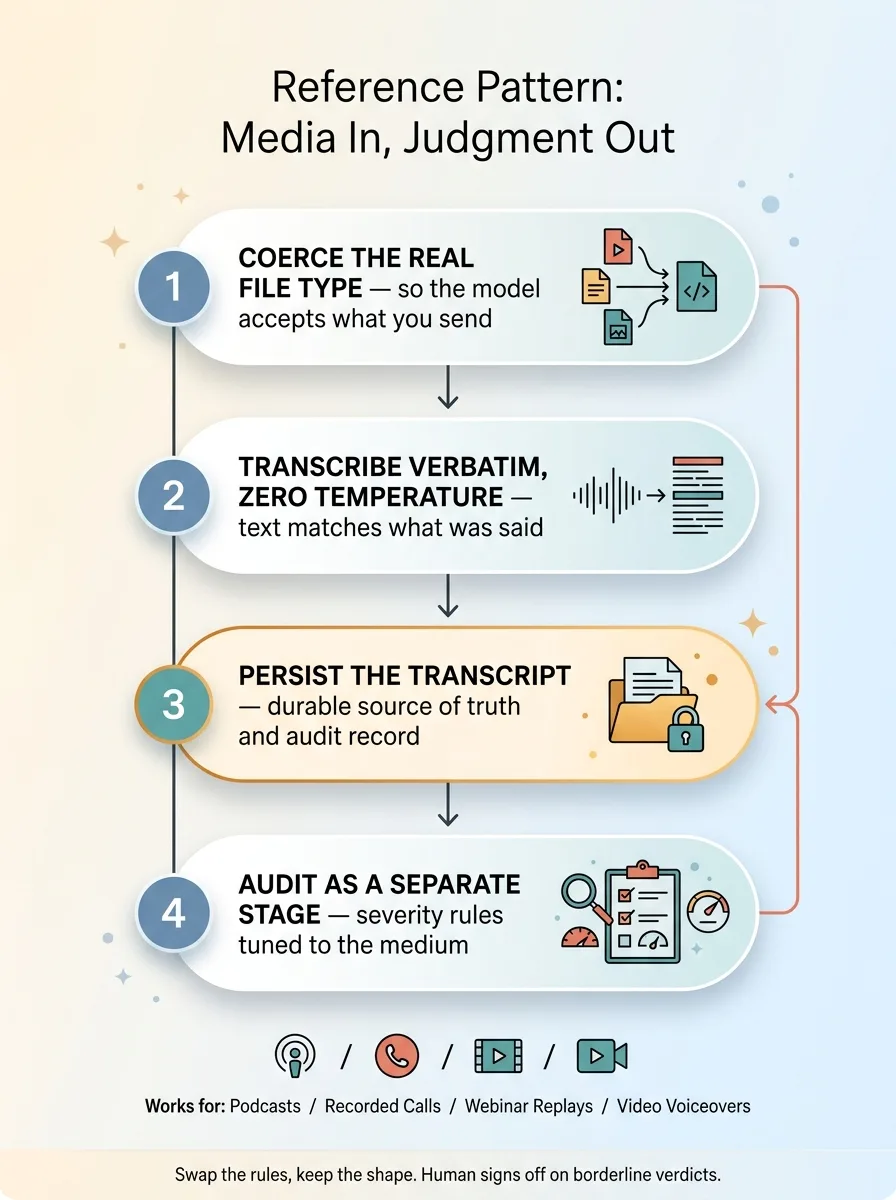 Reference Architecture for Any Media-In Judgment-Out Workflow
Reference Architecture for Any Media-In Judgment-Out Workflow
Podcasts. Recorded sales calls. Webinar replays. Video voiceovers. Anywhere the regulated content is spoken or recorded rather than written, the same pattern holds:
- Coerce the real file type so the transcription model accepts what you send it.
- Transcribe verbatim and deterministically at zero temperature, so the text matches what was actually said.
- Persist the transcript as the durable source of truth and auditable record.
- Audit as a separate stage with severity rules tuned to the medium, so a missing disclosure on air gets treated as the critical gap it is.
That's the reference architecture for serverless audio processing in a compliance setting. It's not tied to any one rulebook or industry. Swap the rules, keep the shape.
I'll be honest about the limits, because anyone who isn't is selling you something. Transcription isn't perfect on heavy accents, fast crosstalk, or poor audio quality. When two people talk over each other, the model guesses, and sometimes it guesses wrong. So a human still signs off on borderline verdicts. The pipeline does the heavy lifting at scale and flags what it's unsure about. It doesn't replace the compliance officer, it makes one compliance officer as effective as five.
The buyer answer stands. Yes, AI handles your audio and broadcast content, not just your text. The pattern is proven, the failure modes are known and solved, and the human stays in the loop exactly where they should be.
If Your Content Isn't Text, Your Compliance Process Probably Isn't Covering It
Here's the uncomfortable part. Most compliance review processes silently skip audio and video, because those formats are hard to read. The review gets done on the written script, or it doesn't get done at all.
Which means the riskiest content, the stuff that goes out over the air or onto a podcast feed, often goes unchecked. Not because anyone decided to skip it. Because it was hard, and hard things quietly fall off the list.
I build pipelines that turn whatever format your content lives in into a structured, cited verdict you can actually defend. Audio in, judgment out, with the transcript saved as evidence. The same approach works for video and recorded calls.
If your firm has radio spots, podcasts, webinar replays, or recorded calls sitting outside your review process, that's a real gap, and it's the kind that's worth closing before someone else points it out for you.
The fastest way to start is to tell me what your content actually looks like. Not what you wish it looked like. The messy reality of formats, volume, and where the rules apply. That's the conversation that leads somewhere.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call