I Built an AI Compliance Review Tool That Audits Ads in 60s
How I built an AI compliance review tool that audits radio ads for a regulated financial firm in 60 seconds, with FINRA rule classification and citations.
By Mike Hodgen
The problem: a weekly radio show stuck in compliance for days
A financial advisory firm I worked with runs a weekly radio show. Every segment, before it could air or get repurposed into a clip, had to clear human compliance review. That's non-negotiable for a FINRA and SEC-regulated firm. The problem wasn't that they reviewed. The problem was how long it took and how blunt the process was.
Segments sat in review for days. By the time compliance cleared a piece, the market commentary in it was stale. The hosts were frustrated because their best, most timely takes got mangled or delayed. The compliance team was buried under a queue they could never get ahead of.
Here's what I found when I looked closely. The reviewers defaulted to the strictest possible standard on everything. A live, off-the-cuff on-air conversation got treated exactly like a polished, scripted retail advertisement. Two completely different things under the rules, judged by the same harshest checklist.
That's not rigor. That's a reflex. When a human reviewer is personally accountable and unsure, they reach for the safe default: apply the toughest rule and you can never be accused of being too lax. Totally understandable. Also totally wrong, because it slows everything down and demands disclosures and rewrites the actual rules never required.
The insight that shaped the entire build: the bottleneck wasn't speed, and it wasn't a lack of diligence. It was misclassification. A senior compliance officer would have looked at a live radio chat and immediately known it falls under a different, narrower rule set than a scripted ad. The junior reflex collapses that distinction and applies the maximum to everything.
So I didn't build a tool to make review faster by cutting corners. I built an ai compliance review tool that does the one thing the humans were skipping under pressure: correctly classify the content first, then apply only the rules that actually govern it.
Why 'apply the strictest rule to everything' fails
The FINRA 2210(a) distinction most teams collapse
FINRA Rule 2210(a) splits communications into categories, and they are not treated the same. A scripted retail communication, think a written ad distributed to the public, carries the heaviest disclosure and review burden. A public appearance, like a host talking live and unscripted on the radio, is governed by a different, narrower subset of obligations.
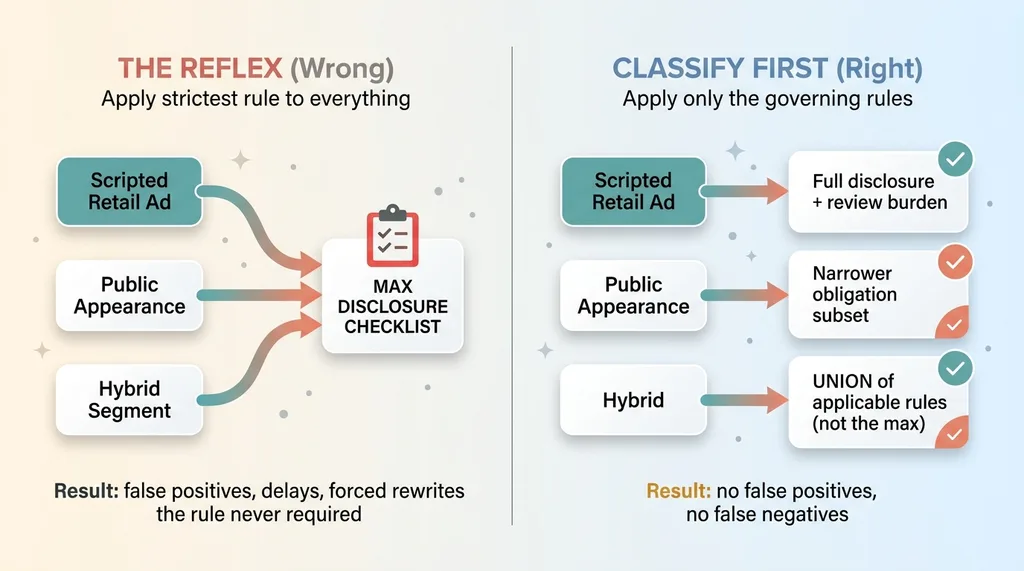 FINRA 2210(a) classification: collapsing all content into the strictest rule vs correct classification
FINRA 2210(a) classification: collapsing all content into the strictest rule vs correct classification
Then there's the hybrid case: a segment that starts with a scripted promo read, then drifts into live extemporaneous discussion. That one needs the union of the applicable rules, not the maximum of both.
The mistake nearly every overloaded review team makes is collapsing these into one. They grab the retail-ad checklist and run it against everything, because that's the safest-feeling option when you're not certain.
The cost of over-compliance
Over-compliance feels free. It isn't.
When you demand the full scripted-ad disclosure stack on a live conversation, you force rewrites the rule never required. You make the host read legalese that doesn't fit the format. You delay timely content until it's worthless. And you erode trust with an audience that can tell when something's been sanded down by lawyers.
I wrote more about this tension in shipping AI content in a regulated industry. The honest takeaway: over-compliance is a process failure, just like under-compliance. One exposes you to regulators. The other quietly bleeds speed, money, and audience trust. A good system has to avoid both, and you can't do that without correct classification.
How the AI compliance review tool actually works
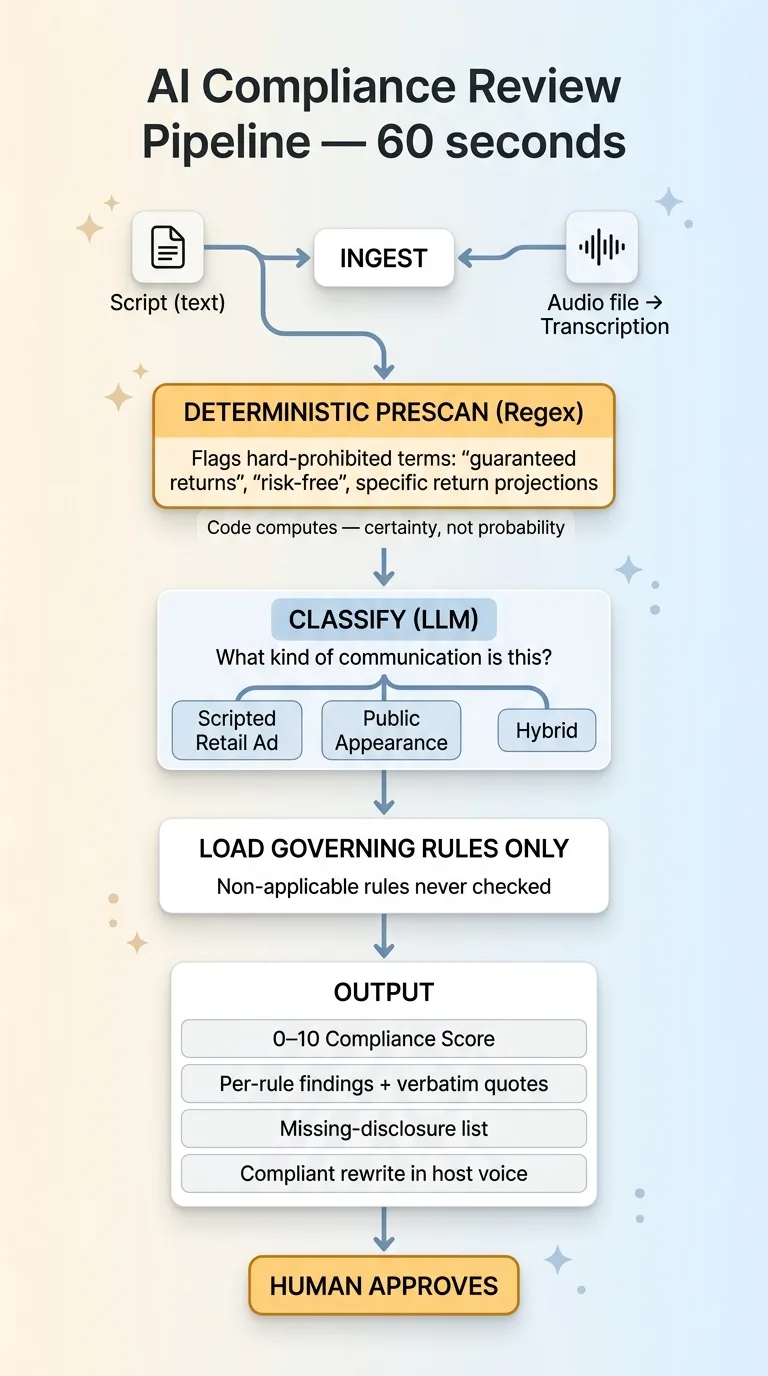 End-to-end compliance review pipeline (ingest, classify, score, rewrite)
End-to-end compliance review pipeline (ingest, classify, score, rewrite)
Ingest: script or audio file
The tool takes either input. If the firm has a script, it ingests the text directly. If all that exists is the recording, an audio model transcribes it first. That ai audio transcription compliance step matters, because most live segments were never scripted in the first place. The whole point was reviewing what was actually said on air, not an idealized version of it.
Classify before you judge
Before any large language model evaluates anything, a deterministic regex prescan runs against the transcript. It checks for hard-prohibited terms, the words and phrases that are flat-out banned regardless of context. No guarantees, no projections of specific returns, no "risk-free." If those show up, they get flagged with certainty, not probability.
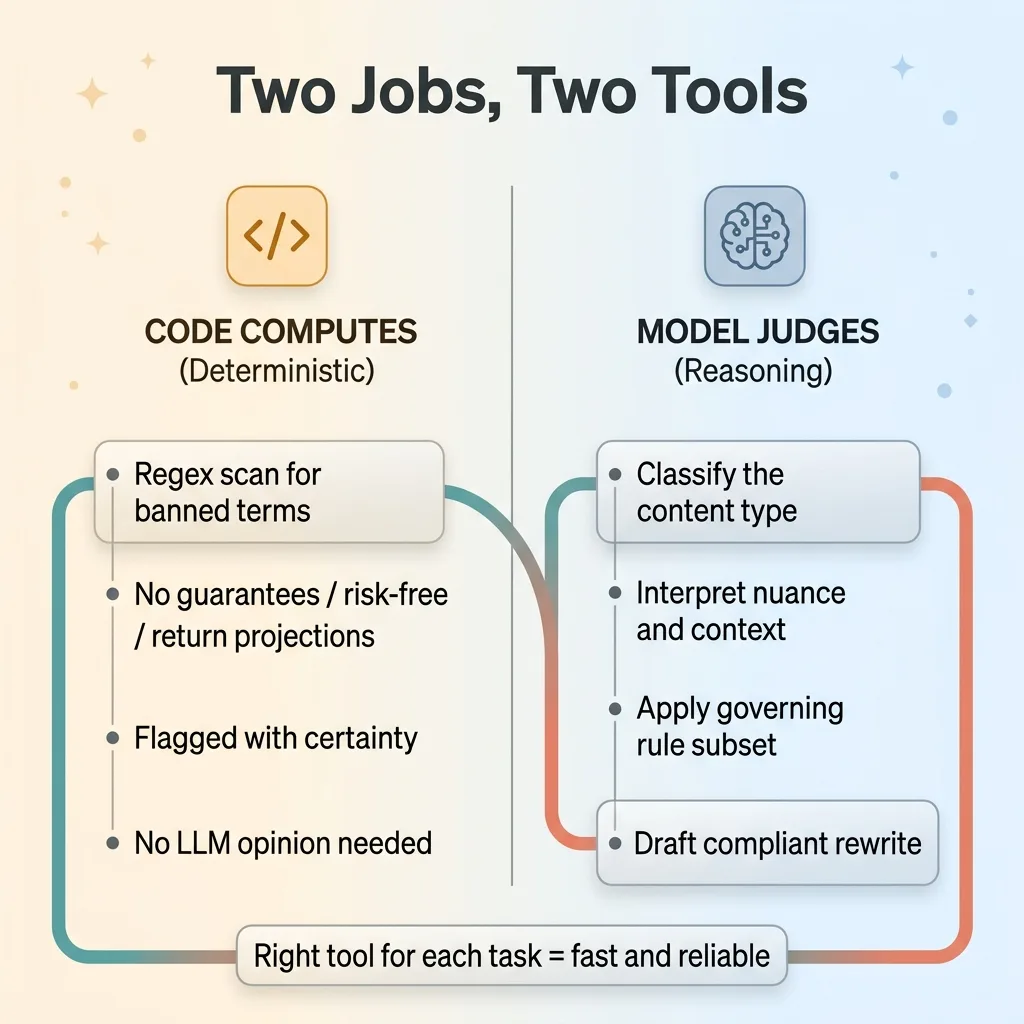 Model judges, code computes, division of labor
Model judges, code computes, division of labor
This is the split I always design for: let the model judge and let the code compute. A regex finding a banned word is deterministic. It doesn't need an LLM's opinion. Save the model's judgment for the parts that actually require reasoning.
Only after the prescan does a frontier model step in, and its first job is not to hunt violations. Its first job is to classify the content under 2210(a). Scripted retail ad, public appearance, or hybrid. Once it decides, it loads only the governing rule subset for that category. The rules that don't apply never get checked.
Score, cite, and rewrite
The output is built to be acted on, not just read. Every run produces four things:
- A 0-10 compliance score, so a reviewer knows at a glance whether this is clean or a problem.
- Per-rule findings with the exact rule citation and a verbatim quote from the transcript as evidence. No vague "this might be an issue." It says which rule, and shows the words that triggered it.
- A missing-disclosure list, the specific disclosures the governing rules require that aren't present.
- A compliant rewrite in the host's own voice, fixing the findings without flattening the personality that makes the show worth listening to.
The whole thing runs in about 60 seconds. The old process took days. That's not a speed trick. It's what happens when you stop making a human do mechanical pattern-matching and reserve them for the calls that need judgment.
Classification first is the whole trick
If I had to point to the single design decision that makes this work, it's this: the AI does not start by scanning for violations. It starts by deciding what it's looking at.
This mirrors how an experienced compliance officer actually thinks. Hand a senior reviewer a transcript and they don't immediately run a checklist. They first ask, "What kind of communication is this?" Because the answer determines which rulebook even applies. A junior reviewer skips that question and applies the harshest checklist to everything, which is exactly the failure mode I found in the radio show queue.
Classifying first prevents errors in both directions.
It stops false positives, flagging a live appearance for missing disclosures that only scripted ads require. That's what was bloating the firm's review time and frustrating hosts.
It also stops false negatives, missing a rule that genuinely does apply because you assumed the wrong category. If you treat a scripted ad like casual talk, you under-review it. Classification protects against that too.
The hybrid case is where this really pays off. When a segment mixes a scripted promotional read with live discussion, the tool doesn't pick one category or default to the strictest. It applies the union of the applicable rules. The scripted portion gets the scripted obligations. The live portion gets the public-appearance obligations. Nothing extra, nothing missed.
That nuance is impossible if you blanket-apply one standard. It's the difference between a tool that thinks like a senior officer and a checklist that thinks like an anxious intern.
Can AI do this without creating legal exposure?
This is the first question every compliance lead asks me, and it should be. The answer is yes, but only because of how the system is bounded.
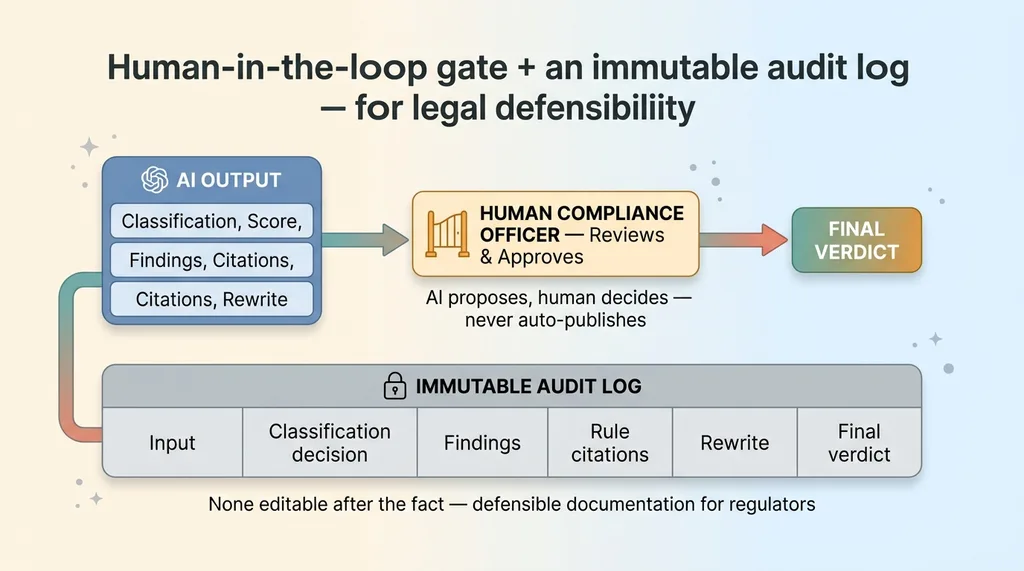
The AI proposes, a human approves
The tool never auto-approves. It never publishes. It produces a recommendation, and a human compliance officer signs off on it. That's not a nice-to-have I bolted on. It's the core design principle behind every AI system I ship stops for a human.
What changes is the officer's job. Instead of reading a raw transcript cold and reaching for the safe default, they review a classified, scored, cited document. They're faster because the mechanical work is done, and they're better-armed because they can see exactly which rule applies and the verbatim evidence behind every finding. The accountable human is still the one who says yes. They just say it in minutes with better information.
The immutable audit log
Every run writes to an immutable log. Input, classification decision, findings, rule citations, the rewrite, and the final verdict. All of it captured, none of it editable after the fact.
 Human-in-the-loop gate plus immutable audit log for legal defensibility
Human-in-the-loop gate plus immutable audit log for legal defensibility
This is what actually reduces legal exposure. Not the speed, not the AI's cleverness. Defensible documentation. When a regulator asks why a piece of content was approved, the firm can produce a complete record of how that decision was made, what rules were considered, and what evidence supported it. That capability ties into the broader idea of a searchable brain for legal rules: your obligations become queryable, and every decision against them becomes traceable.
I'll be honest about the limit here, because it's the whole reason the design holds together. The AI can be wrong. It can misclassify an edge case or miss a nuance. That is precisely why the human gate and the audit log exist. The system is built around the assumption that the model is fallible, so a person stays accountable and every decision stays documented.
What it doesn't do, and where it still needs a human
I'd rather tell you the limits up front than have you discover them in production.
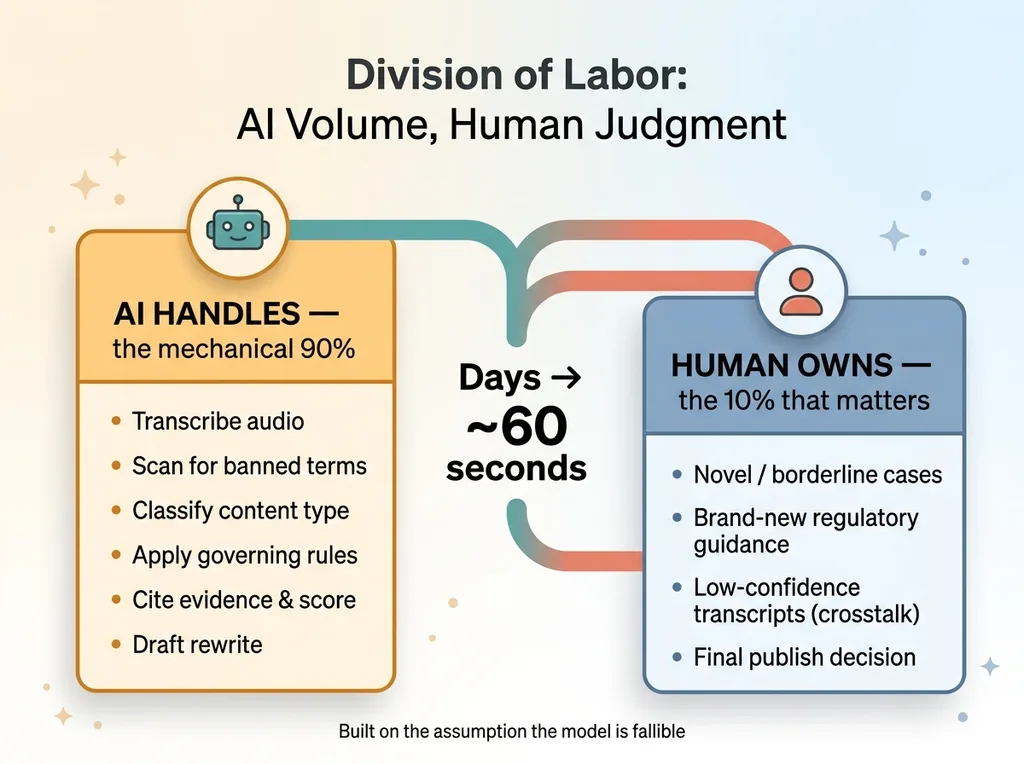 The 90/10 division of labor: what AI handles vs what stays human
The 90/10 division of labor: what AI handles vs what stays human
It doesn't replace the compliance officer's judgment on novel or borderline cases. When something genuinely new shows up, a fact pattern the rules don't cleanly address, that's a human call. The tool will flag uncertainty, but it won't pretend to resolve it.
It doesn't interpret brand-new regulatory guidance it hasn't been given. If a rule changed last week and nobody fed the change into the system, it doesn't magically know. The rulebook is only as current as what you load into it.
The transcription isn't perfect. Heavy crosstalk, multiple hosts talking over each other, a poor recording, all of those degrade accuracy. So on low-confidence runs, the tool surfaces that, and a human spot-checks the transcript before trusting the analysis built on it.
And the rewrite is a draft, not a final. It's a strong starting point in the host's voice, but a person still owns the publish decision.
Here's why I frame all of this as a feature, not an apology. The tool collapses review from days to about a minute by doing the mechanical 90% reliably. That leaves the 10% that requires real judgment to the person who's actually accountable for it. That's the right division of labor. AI does the volume, the human owns the calls that matter.
What this pattern unlocks for any regulated marketing team
Strip away the radio show specifics and you're left with an architecture that applies anywhere regulated marketing gets reviewed.
Classify the content type first. Apply only the rules that govern that type. Run deterministic checks for the hard-prohibited stuff, and reserve the model's judgment for the rest. Cite the exact rule and quote the exact evidence behind every finding. Log everything immutably. Gate the final decision on a human.
That same structure works for healthcare claims, supplement copy, legal advertising, insurance marketing, any field where what you say is bound by rules and reviewed before it ships. The FINRA categories swap out for whatever framework governs your industry. The skeleton stays the same.
The real win isn't speed for its own sake. It's taking a feared, slow, judgment-heavy bottleneck, the thing everyone dreads and over-applies out of caution, and turning it into a fast, documented, defensible process. Your reviewers stop defaulting to the strictest standard because they're guessing. They start making confident calls because the classification and evidence are in front of them.
If your team is drowning in compliance review, or quietly applying the harshest rule to everything because it's the only safe move you've got, that's exactly the kind of system I build. Not a demo. A working tool that fits your actual rules and your actual workflow.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call