AI Video Coaching Review: How I Built a Multi-Pass Critic
How I built an AI video coaching review that watches the tape twice. The agentic multi-pass design, the Gemini Files API fix, and why infra beat the prompt.
By Mike Hodgen
How a Real Coach Actually Watches Tape
Watch a good martial-arts instructor review a student's video and you'll notice something. They don't watch it once and bark a grade. They watch the whole clip first to get the shape of it, then they pick the three or four moments that actually matter, then they scrub back and re-watch those moments slowly, sometimes frame by frame.
That two-tier attention is the entire job. The first watch is about context. The second is about detail. Skip either one and the feedback is useless.
I was building a coaching feature for a martial-arts academy product. Students upload a technique video, the system gives them coaching feedback. Simple on the surface. The trap was obvious the moment I sketched it: if you hand a video to a single AI prompt and say "grade this," you get a confident-sounding paragraph that no real instructor would respect. "Good energy, work on your base." Vague. Useless. The kind of thing that makes a student feel coached without actually coaching them.
So this AI video coaching review came down to one thesis: meaningful video analysis is multi-pass and agentic. You copy the human behavior. Watch the whole thing once to triage, then re-watch the moments that matter at higher detail, then synthesize.
But here's the part that almost killed the project, and it had nothing to do with the prompt or the model. The feature looked finished and never actually worked. Before I could make the AI smart, I had to make sure it could see the video at all. That's where the real story starts.
The Feature Was Silently Broken Before the AI Ran
This is the part buyers need to hear, because it's the reason "we tried AI video and it didn't work" is so common.
The review feature was wired up. It had a button. It returned text. It looked done. It had never once actually analyzed a video.
The HLS streaming URL the model couldn't ingest
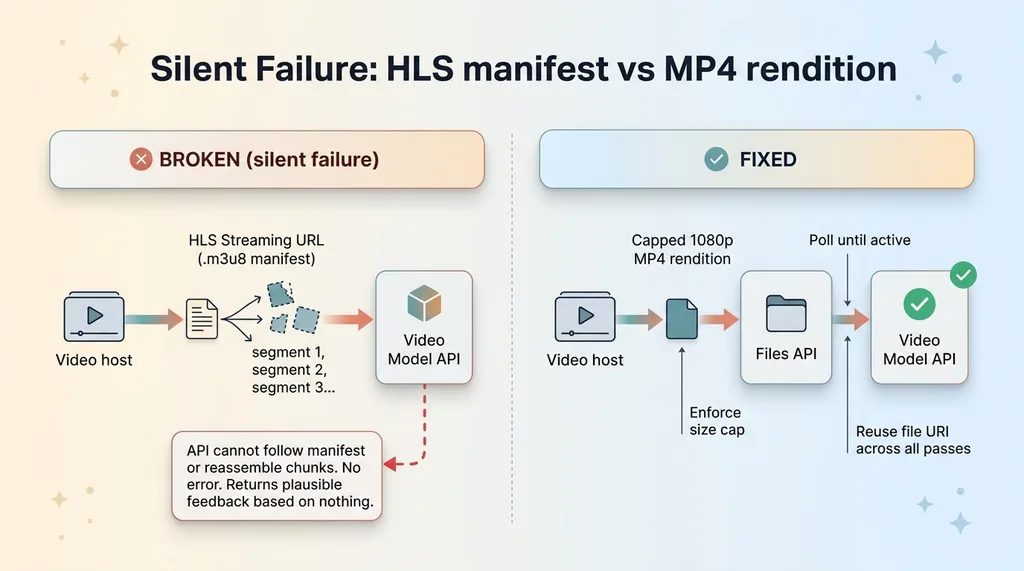
The pipeline was handing the model an HLS streaming URL. That's a manifest file, a little text document that points at dozens of chunked video segments meant for a browser player to stitch together on the fly. Great for streaming to a phone. Completely unreadable to a video model's API.
The API can't follow a manifest. It can't reassemble chunks. It just got a pointer to nothing it could use. And there was no loud error. No stack trace. The model returned plausible-sounding feedback based on essentially nothing, and everyone downstream assumed it worked.
Silent failure is the most expensive kind. A crash gets fixed. A confident wrong answer ships.
The rendition + Files API fix
The fix was unglamorous infrastructure, which is usually where the real work lives.
 Silent Failure: HLS manifest vs MP4 rendition
Silent Failure: HLS manifest vs MP4 rendition
On upload, I request a capped-1080p MP4 rendition from the video host. When the renditions-ready webhook fires, the system downloads that MP4, then uploads it to the model's Files API (this is the Gemini Files API video path for native ingestion). Then I poll until the file reports active, enforce a size cap so nobody can choke the pipeline with a two-hour upload, and make the file self-cleaning so storage doesn't balloon over time.
One more detail that matters for cost: I reuse the resulting file URI across every later pass. Upload once, reference it four or five times. No re-uploading the same video for each analysis stage.
The lesson I keep relearning on client work: the difference between a working AI feature and a silent failure is usually the delivery layer, not the cleverness of the prompt. Most people debug the prompt for a week when the model was never getting a file it could read.
Pass One: The Overview That Picks the Key Moments
With the model actually receiving a real video, the agentic flow could start. Stage one is the overview pass, and it mirrors the coach's first watch.
The model watches the full clip once at normal frame sampling and does exactly two jobs. First, it breaks the clip into phases: setup, entry, the technique itself, the finish. Second, it picks up to four key moments worth a closer look, each tagged with a timestamp.
That's it. The overview pass is not trying to grade anything. It's triage. It's the instructor scanning the whole clip to figure out where to spend attention.
This is where the model's native video understanding earns its keep. It isn't watching screenshots. It actually processes the clip as video, which is the whole reason this approach works at all. I wrote more about that native capability in an AI video review system using Gemini if you want the deeper version.
The four-moment cap is deliberate. It does two things. It keeps cost and latency bounded, because the expensive work happens later and I don't want it running on the whole timeline. And it forces the model to prioritize.
A coach who tries to comment on every half-second of a clip gives you noise. A coach who picks the four moments that determine whether the technique worked gives you something you can act on. The cap forces that same discipline on the model. Triage first, detail later. Cheap pass first, expensive passes only where they're warranted.
Pass Two: Parallel Zoom Passes That Re-Watch the Moments
Stage two is the literal "watch the tape twice" part.
 Narrow context vs wide context produces better answers
Narrow context vs wide context produces better answers
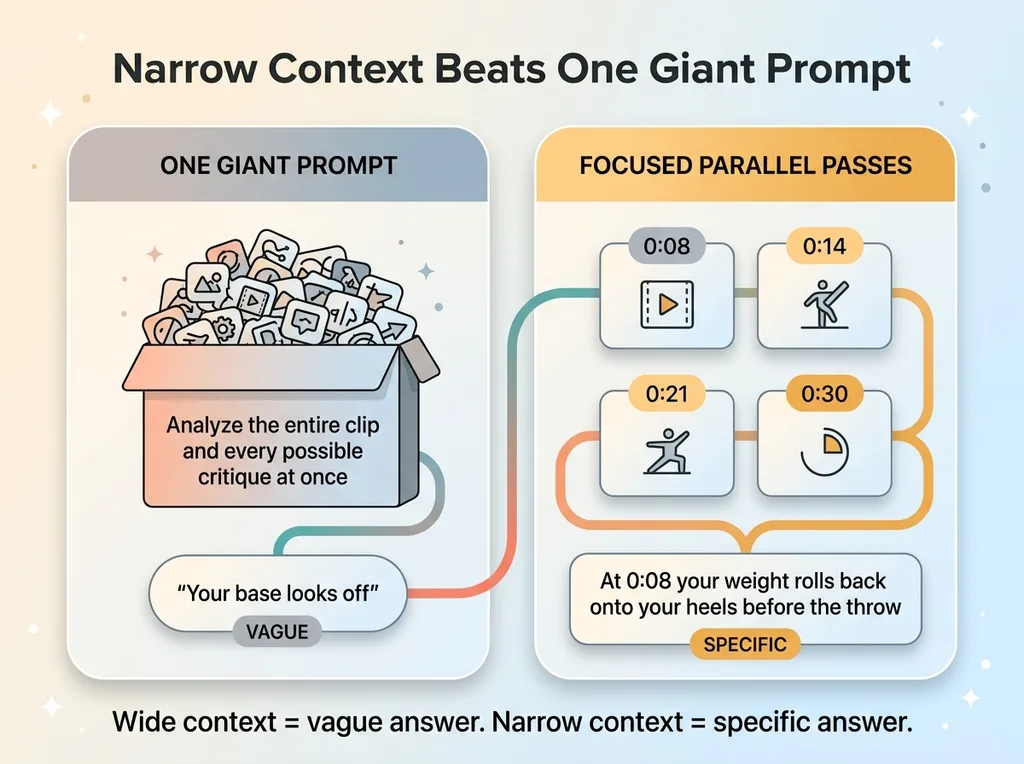
For each key moment the overview picked, I run a separate high-frame-rate pass that focuses only on that time window. If the overview flagged 0:08, 0:14, 0:21, and 0:30, that's four independent zoom passes, each looking at a few seconds of video at much denser frame sampling.
Higher frame rate is the point. At normal sampling, the model sees the gist. At high sampling on a narrow window, it sees hand placement, weight transfer, the exact timing of a hip rotation. The details a single skim would smear over. This is the difference between "your base looks off" and "at 0:08 your weight rolls back onto your heels before the throw."
Because the moments are independent, the passes run in parallel. Four zoom passes firing at once instead of one after another keeps total latency close to a single pass. And every one of them reuses the same Files API URI from the fix above, so I'm not uploading the video four more times.
Here's the architectural argument, and it's the one that matters for any video AI you're considering. Splitting into focused passes beats one giant prompt. Each pass has a narrow job and a narrow context window. A narrow job produces specific output. A giant "analyze everything" prompt produces mush, because the model is trying to hold the whole clip and every possible critique in its head at once.
Narrow context, specific answer. Wide context, vague answer. That holds across nearly every AI system I build.
I used the same focused-attention pattern to score hundreds of videos with AI that actually watches them for a different production use case. Same principle, different domain. The model that genuinely watches beats the model that pretends to.
Pass Three: Synthesis Into a Score and Time-Coded Feedback
Stage three pulls everything together. The synthesis pass takes the phase structure from the overview and the detailed findings from each zoom pass and produces one output: a 0-to-1 score plus feedback anchored to timestamps.
The time-coding is what makes the whole thing usable. "At 0:08 your weight is back on your heels, which kills your entry" is coachable. A student can rewatch that exact moment and feel what the AI saw. "Work on your base" is a fortune cookie. Time-coded AI feedback is the entire difference between a tool an instructor respects and a toy they ignore.
Synthesis is its own pass for a structural reason. If I asked the zoom passes to also produce the final grade, each one would only see its own three-second slice. None of them would have the full picture. The technique might look bad at 0:08 but get rescued at 0:21, and only a pass that sees all of it can weigh that. The synthesis pass sees the overview, every zoom finding, and the phase breakdown, then scores against the whole.
This is also the natural place to add a self-checking step, where the model reviews its own draft feedback for consistency before it finalizes. I've written about giving an AI a critic that fixes its own mistakes, and the same loop fits here cleanly.
Honest note, because I'd rather you trust me than oversell: AI scoring is directional, not gospel. It's a strong, consistent first read. It is not a black belt with twenty years on the mat. Which is exactly why the next section exists.
The Security Fix: Students Can't Grade Themselves
Here's the unglamorous detail that would've sunk this product in a different way.
 AI proposes, human disposes security model
AI proposes, human disposes security model
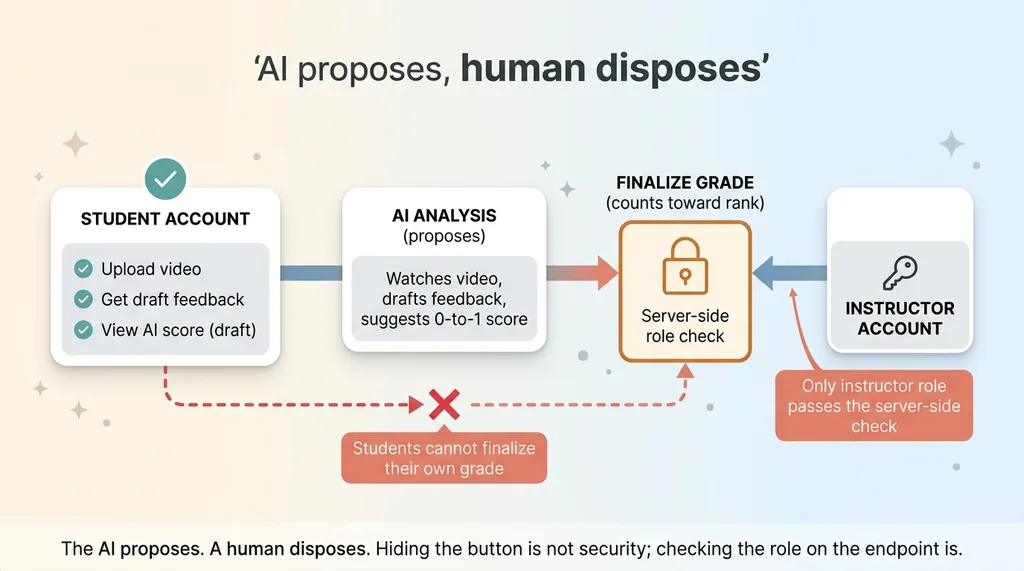
The AI score influences rank progression. In a ranking system, that score isn't just feedback, it can move a student up. Which means the grading endpoint is a consequential action, not a cosmetic one.
The first version had a problem hiding in plain sight. If a student could call the finalize-and-grade endpoint themselves, they could promote their own rank. Upload a video, trigger the grade, get the score that counts. The model becomes the judge and the student holds the gavel.
The fix is simple and it lives on the server, not in the UI. Students can upload and get draft feedback all day. But finalizing the grade that actually counts toward rank is gated to instructor accounts, enforced server-side. Hiding the button isn't security. Checking the role on the endpoint is.
This ties to a principle I apply on every system I build, AI or not: the AI proposes, a human disposes. Anything that moves money or moves rank stops for a human. The model can do the analysis, draft the feedback, suggest the score. A person with authority pushes the button that makes it real.
That's the answer to the quiet fear every buyer has about "AI analyzes video." It doesn't mean handing the model the keys. It means the model does the watching and a human owns the decision.
Why Multi-Pass Beats One Prompt, and What It Means for You
If you've tried AI video review and walked away unimpressed, here's what probably happened. Someone did it in one pass with one prompt, and there's a decent chance the delivery layer was quietly broken and nobody noticed, just like mine was.
 The Multi-Pass Agentic Pipeline (full flow)
The Multi-Pass Agentic Pipeline (full flow)
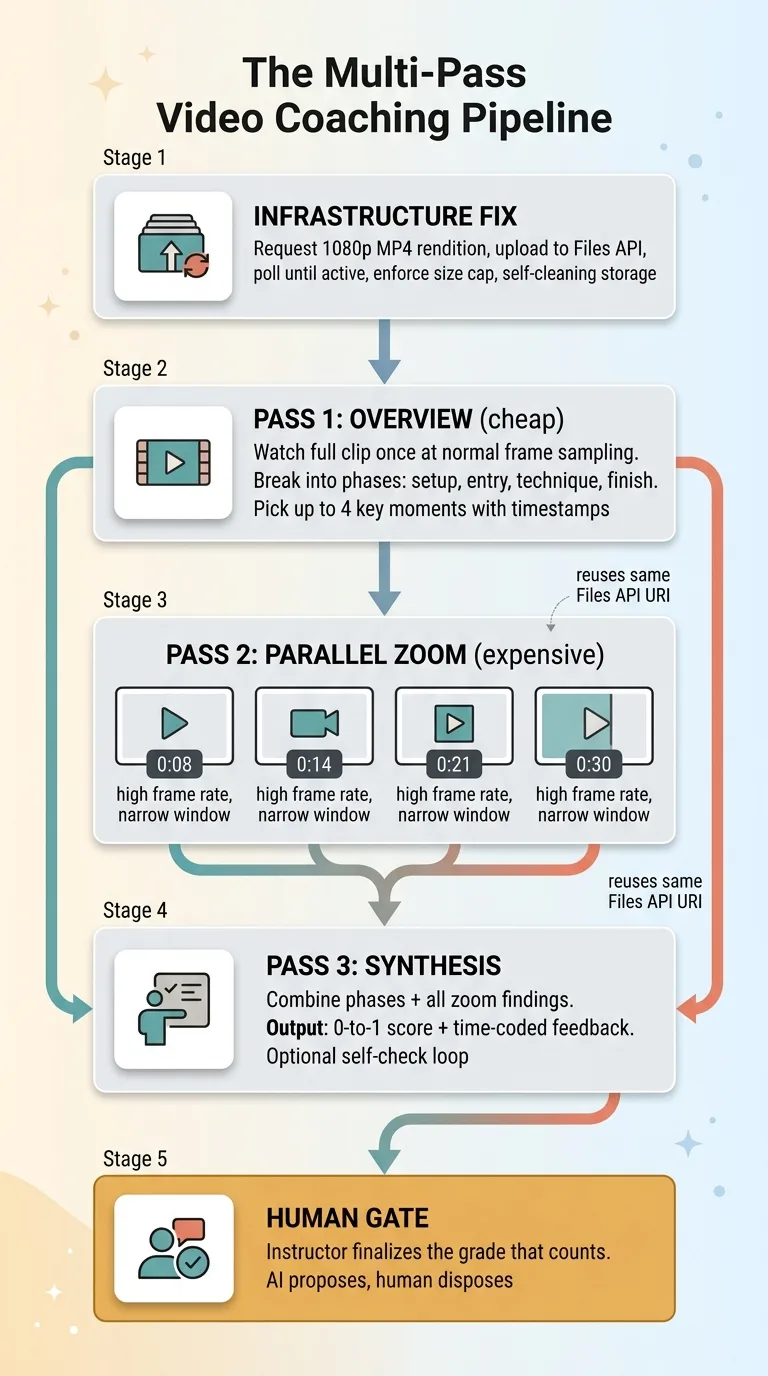
The pattern that actually works is the one I just walked through:
- Fix the infrastructure first so the model gets a file it can actually read. A rendition, the Files API, a poll-until-active check. Boring and decisive.
- Triage with a cheap overview pass that picks the few moments that matter.
- Re-watch those moments in parallel at high frame rate, each pass with a narrow job.
- Synthesize into time-coded output so the feedback points at a moment, not a vibe.
- Gate the consequential action behind a human so the model proposes and a person disposes.
None of this is specific to a martial-arts academy. Swap the domain and the pattern holds. Sales call review where the AI flags the three moments a rep lost the deal. Manufacturing QA footage where it isolates the frames a defect appears. Training compliance, sports coaching, anywhere a human currently watches video and writes notes by hand.
The thing I want you to take away: the design matters more than the model. The same model produced garbage on a broken HLS link and genuinely useful coaching once the architecture was right. The model didn't change. The system around it did.
If your team reviews video by hand and you suspect AI could handle the first pass, the question isn't which model. It's how you stage the passes, fix the delivery layer, and gate the decision. That's the kind of thing I build. Tell me what you're trying to ship.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call