AI Citation Hallucination Prevention: The Firewall
AI writers invent sources that don't say what they claim. Here's the citation hallucination prevention firewall I built so no unsupported stat reaches a reader.
By Mike Hodgen
The Failure Mode Nobody Talks About
Bad prose you'll catch. A fake citation you won't.
I built a content pipeline for a longevity and telehealth brand, and one of the early drafts almost shipped a lie.
The AI drafter attached a clean, plausible-looking URL to a statistic about a biomarker. Real domain. Real-sounding article title. A number that felt directionally correct. The kind of thing you'd nod at and move on. Except when I clicked through, the source title didn't say what the article claimed it said. The stat and its citation had nothing to do with each other.
That's the moment ai citation hallucination prevention stopped being a theoretical concern for me and became a hard requirement.
Here's the thing everyone gets wrong. They worry about AI writing clunky sentences. Bad prose is annoying, but you'll catch it. You read a paragraph that sounds like a robot, you fix it, you move on. The dangerous failure is the opposite. It's a confident, well-formatted number with a citation that doesn't back it up.
A human skims the draft. Sees a statistic. Sees a link next to it. Trusts it. That's how it gets through.
The cruel part is that the citation makes the number more believable, not less. A bare statistic invites scrutiny. A statistic with a source attached gets a pass. The link does the work of earning trust, and if the link is wrong, you've just published something false that looks more credible than if you'd left it unsourced.
In health content, that's not a typo. That's a credibility killer and a potential liability. The same is true for legal and financial content. Anywhere a number carries weight, a fabricated citation is the worst possible failure, because it's the one your reviewer is least likely to catch.
Why AI Models Fabricate Sources
Plausible is not the same as true
You don't need a PhD to understand why this happens. LLMs predict plausible text. That's the whole job. They generate the next most likely token based on everything that came before.
A citation is just more text to predict. The model doesn't go fetch a real document, read it, and quote it. It generates a string that looks like a citation, because citations have a recognizable shape. A domain, a title, a number. The model knows what those look like. It does not know whether they agree with each other.
So you get a URL that looks right, a title that sounds right, and a stat that's believable. Three plausible pieces. The problem is that plausible and true are different things, and the model optimizes for the first one.
The URL that almost matches
The most common pattern I saw wasn't a made-up domain. Made-up domains are easy to catch. You click, you get a 404 or a parked page, you know instantly something's wrong.
 Why the 'Almost-Matching' URL Is the Dangerous Failure
Why the 'Almost-Matching' URL Is the Dangerous Failure
The dangerous version is a real-ish domain, a real-ish article title, and a number the source never actually states. Everything resolves. Everything loads. The page exists. The article is real. But the specific claim the AI attached to it isn't in there.
That's worse, because nothing trips the obvious alarms. The link works. The site is reputable. Only a careful read of the actual source reveals the mismatch, and nobody does a careful read of every citation in a draft.
This is the exact reason CEOs tell me they can't trust AI-written content. They're not wrong to be skeptical. They've just been told the solution is "review it more carefully," which doesn't scale and doesn't work.
Stop Treating Statistics Like Prose
Every datum carries a source index
The fix isn't better prompting. It's architecture.
In a naive pipeline, a statistic is just a sentence in a paragraph. The number "42% reduction" is the same kind of object as the words around it. It's text. And text is exactly what LLMs are happy to fabricate.
In my pipeline, figures and charts aren't text. They're typed data objects. A number isn't a string sitting in a paragraph. It's a structured object with fields, and one of those fields is a citation index pointing to a specific source entry.
The data and its source are bound together at the structural level. Not glued together as text that happens to sit near each other. Bound, as a property of the object itself.
Figures as typed data objects
This matters because it changes what the system can reason about. When a number is just prose, the pipeline can't ask "does this have a source?" There's no clean way to check. The number and any nearby citation are both just words.
 Statistic as Prose vs Statistic as Typed Data Object
Statistic as Prose vs Statistic as Typed Data Object
When the number is a typed object with a required citation field, the question becomes trivial. Does this figure have a backing source entry? Yes or no. It's a property, not a guess.
This is the same broader pattern I use everywhere AI assertions need guardrails. In my DTC brand, I lock the AI to a known set of facts so it can only describe products that actually exist in the catalog. Same idea here. Constrain what the AI is structurally allowed to assert, instead of hoping it behaves.
This works for any high-stakes content. Legal, financial, medical. Anywhere a number needs provenance, you stop treating statistics like prose and start treating them like data that carries its source wherever it goes.
The Compliance Gate That Rejects Mismatched Citations
Title must match URL
Binding numbers to sources is layer one. It guarantees every figure has a citation. It doesn't guarantee the citation is correct. That's a separate problem, and it needs its own layer.
Before any draft moves forward, it passes through a compliance gate. The gate checks every citation against one question: does the title attached to this source actually correspond to what the URL points to?
If a citation's title doesn't match its source, the draft gets rejected. Not flagged. Not softened. Rejected, full stop, before it goes anywhere near a human reviewer or a render step.
This is part of the firewall I built between my AI writer and my AI editor. If you want the full architecture of how that writer/editor split works, I wrote it up here: the firewall I built between my AI writer and my AI editor.
The real failure it caught in testing
This gate earned its place during testing. The drafter had paired a statistic with a source whose title didn't match the claim. Exactly the failure mode I described at the top. A plausible number, a real source, but the two didn't actually agree.
The gate caught it. Then it rejected the entire draft.
Not "removed the bad citation and kept going." Rejected the whole thing and sent it back to be regenerated. That feels harsh. It's supposed to. Rejecting the draft is the safe default, because the alternative is trusting the system to surgically fix the one thing it just got wrong, which is exactly the thing you can't trust it to do.
When you're shipping AI content in a regulated industry, the harsh default is the correct default. A rejected draft costs you a few minutes of regeneration. A published mismatch costs you a lot more.
cleanFigures(): The Render-Time Backstop
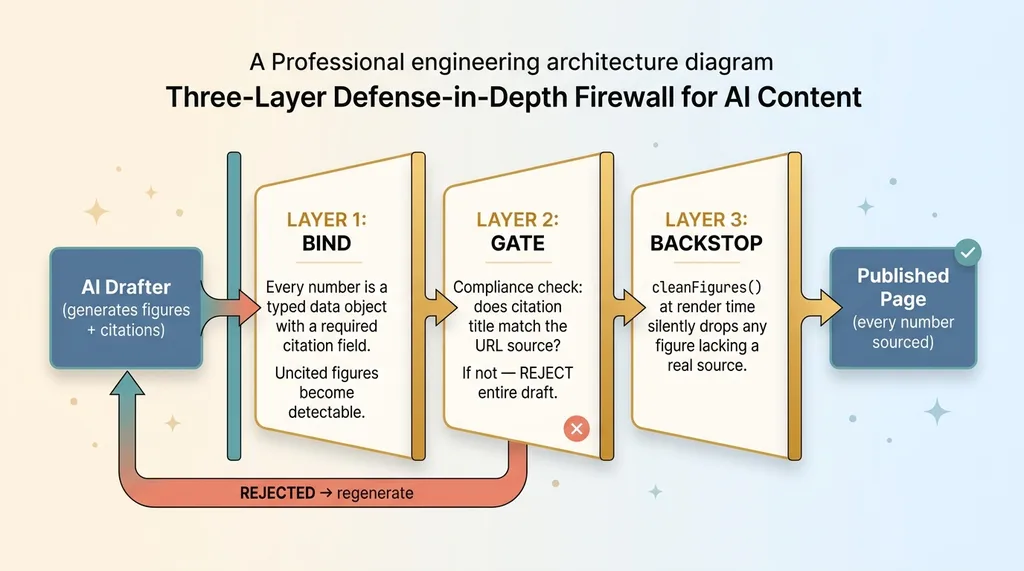 The Three-Layer Defense-in-Depth Firewall
The Three-Layer Defense-in-Depth Firewall
If a number has no real source, it never renders
Two layers down, you'd think we're safe. We're not, and a system that assumes it's safe is the one that eventually ships a lie.
So there's a third layer. A cleanFigures() step that runs at render time, right before the page is built.
Its job is simple and unforgiving. It walks through every figure and chart in the final content and silently drops any one that lacks a real backing citation. No source, no render. The number simply does not appear on the page.
This means an uncited number physically cannot reach a reader. Even if a hallucinated figure somehow survived drafting. Even if it slipped past the compliance gate. It still hits this final wall, and the wall removes it before anyone sees it.
A silent drop beats a published lie
The design principle is one sentence. A number never appears without its source.
Everything else follows from that. If a figure can't prove it has a source, it's gone. It's better to show fewer charts than to show one unsupported statistic. A page with three solid, sourced numbers beats a page with five numbers where one is fabricated, because that one fabricated number poisons trust in all five.
This is defense in depth. Three independent layers, each catching what the previous might miss.
- Layer one binds every number to a source structurally, so an uncited figure is detectable at all.
- Layer two rejects any draft where a citation title doesn't match its source.
- Layer three drops any surviving uncited figure at render time, no exceptions.
No single layer is perfect. That's the point. You don't build trust by hoping one check is flawless. You build it by stacking checks so that a failure has to slip past all three, and the odds of that drop fast with every layer you add.
This pattern generalizes to any content pipeline. Bind, gate, backstop. Three chances to catch what one would miss.
What a Verified Content Pipeline Actually Costs You
Fewer figures, more trust
I'm not going to tell you this is free. It isn't.
This system drops figures. Some numbers that the AI generated never make it to the page because they couldn't prove their source. Some drafts get rejected entirely and have to be regenerated, which costs time. The pipeline produces slightly less than a naive setup, and it's slower than one that just publishes everything the AI writes.
That's the deal. The tradeoff is fewer published numbers in exchange for every published number being real.
The tradeoff is honest
For low-stakes blog filler, maybe you don't need all three layers. If a number being slightly off costs you nothing, the overhead isn't worth it. I'd rather tell you that than pretend every business needs the full firewall.
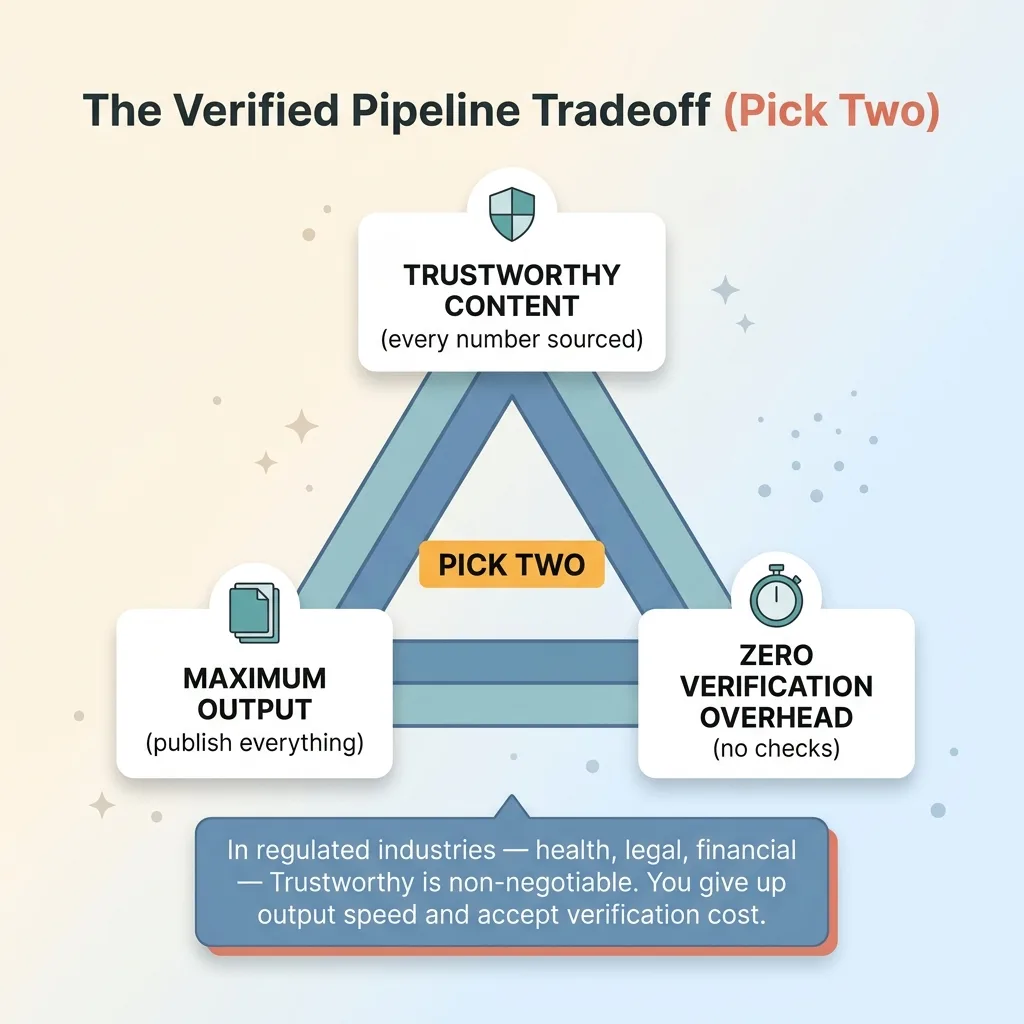 The Verified Pipeline Tradeoff (Pick Two)
The Verified Pipeline Tradeoff (Pick Two)
But for health, legal, or financial content, where a wrong stat is a genuine liability, this isn't optional. It's the structural cost of being able to say "you can trust this." There's no version where you get trustworthy AI content and maximum output and zero verification overhead. Pick two, and if you're in a regulated space, two of them are non-negotiable.
This is what "trusting AI content" actually requires under the hood. Not a better prompt. Not a smarter model. Structure that makes the bad outcome impossible rather than unlikely.
And to be clear about what AI did and didn't replace here. AI replaced the typing. It writes the draft, generates the figures, drafts the citations. It did not replace the judgment about what's safe to publish. That judgment is encoded in the layers, and the final call still belongs to a human.
How to Tell If Your AI Content Is Safe to Publish
Three questions to ask your pipeline
If you're running any kind of AI content operation right now, here's a quick self-assessment. Three questions. Answer them honestly.
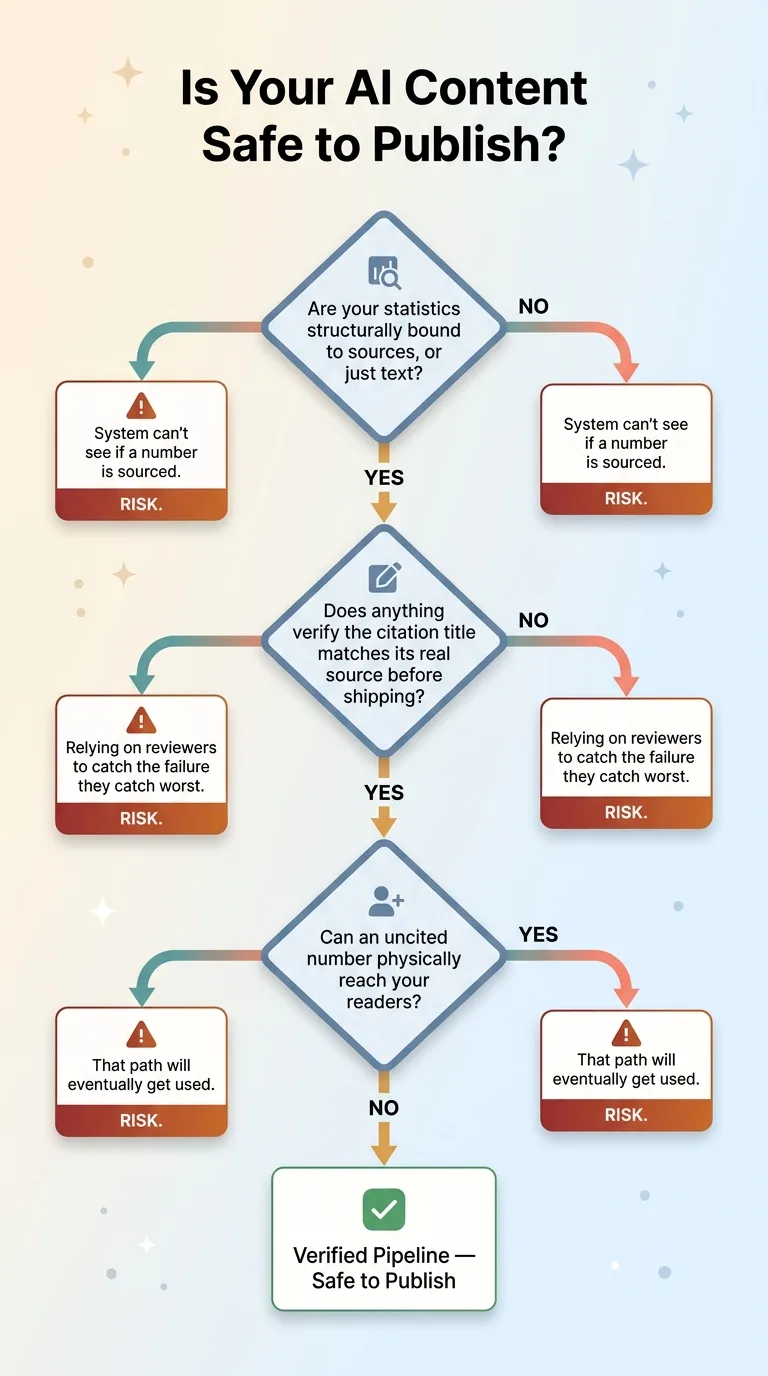 Three Self-Assessment Questions Decision Flow
Three Self-Assessment Questions Decision Flow
One. Are your statistics structurally bound to sources, or are they just text? If a number in your pipeline is the same kind of object as the words around it, your system has no way to know whether it's sourced. It can't protect you from something it can't see.
Two. Does anything verify that a citation's title matches its actual source before it ships? Not "did a human glance at it." An actual check. If the answer is no, you're relying on reviewers to catch the one failure they're statistically worst at catching.
Three. Can an uncited number physically reach your readers? If there's any path where a figure without a verified source ends up on a published page, that path will eventually get used.
If any of those answers made you uncomfortable, you likely have a hallucination risk live on your site right now. Not theoretical. Live.
Every AI system I ship is built this way, and every AI system I ship stops for a human before anything reaches a real audience. The firewall is how I make AI content shippable in industries where a wrong number is a lawsuit, not a typo. It's the kind of thing I build into a content pipeline before it touches your readers, not after something goes wrong. If you want to see what that looks like for your operation, let's talk about what a verified content pipeline looks like for you.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team. Just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call