Prevent AI Hallucination Citations: A Grounding Fix
My AI invented a Fed rate cut on a regulated broadcast. Here's the three-source verification pipeline I built to prevent AI hallucination citations for good.
By Mike Hodgen
The Day the AI Cut Rates and Nobody Asked the Fed
A model I was running drafted a line, confidently, about an emergency Fed rate cut happening "this week."
It never happened. The model invented it.
This was for a regulated financial firm that does a weekly live radio show. The model's job was to draft talking points for the host, the kind of thing that sounds like market commentary. Most of what it wrote was fine. Then it slipped in a specific, timely, completely fabricated claim about central bank action.
Here is why that matters and why I lost sleep over it. On a FINRA-regulated broadcast, a false statement of fact on air isn't an embarrassing typo. It's genuine legal exposure. A compliance officer doesn't care that the AI "meant well." A false statement about monetary policy, delivered live to an audience that might act on it, is the kind of thing that draws regulatory attention and lawsuits.
And here's the part most people miss: the model wasn't broken. It was doing exactly what generative models do. It produced plausible text. That's the entire job. A language model predicts what words come next, and "the Fed cut rates this week" is a perfectly plausible sequence of words. The model has no internal mechanism that says "wait, did that actually occur?"
The danger isn't that AI lies. The danger is plausibility without provenance. The output reads exactly as confident whether the claim is true or fabricated. There's no tonal tell. A human reading the draft cold has no way to know which sentences are real.
So the buyer's question, the one I had to answer for this firm, is brutal and fair: how do you stop AI from confidently making things up when a false statement creates real liability?
You can't fix it with a better prompt. I learned that the hard way. You fix it with architecture.
Why a Single Trend Source Is a Liability, Not a Shortcut
The original pipeline had one design flaw, and it was the kind of flaw that looks like a convenience.
 Hallucination risk clustering: evergreen vs current-events claims
Hallucination risk clustering: evergreen vs current-events claims
 Old single-source laundering pipeline vs new verified architecture
Old single-source laundering pipeline vs new verified architecture
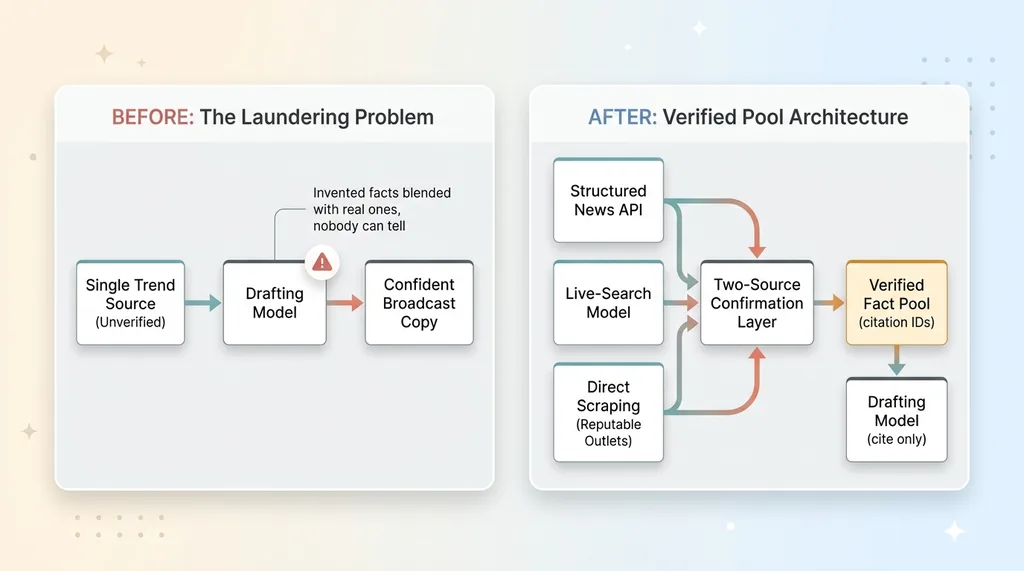
It fed the drafting model a single trend source and asked it to summarize "what's happening this week." One input. Unverified. The model took that input, blended it with whatever it already "knew," and produced authoritative-sounding copy.
That's the laundering problem. A single unverified input goes in, and polished, confident broadcast copy comes out. Nobody downstream can tell the difference between a fact that was sourced and a fact the model invented to fill a gap.
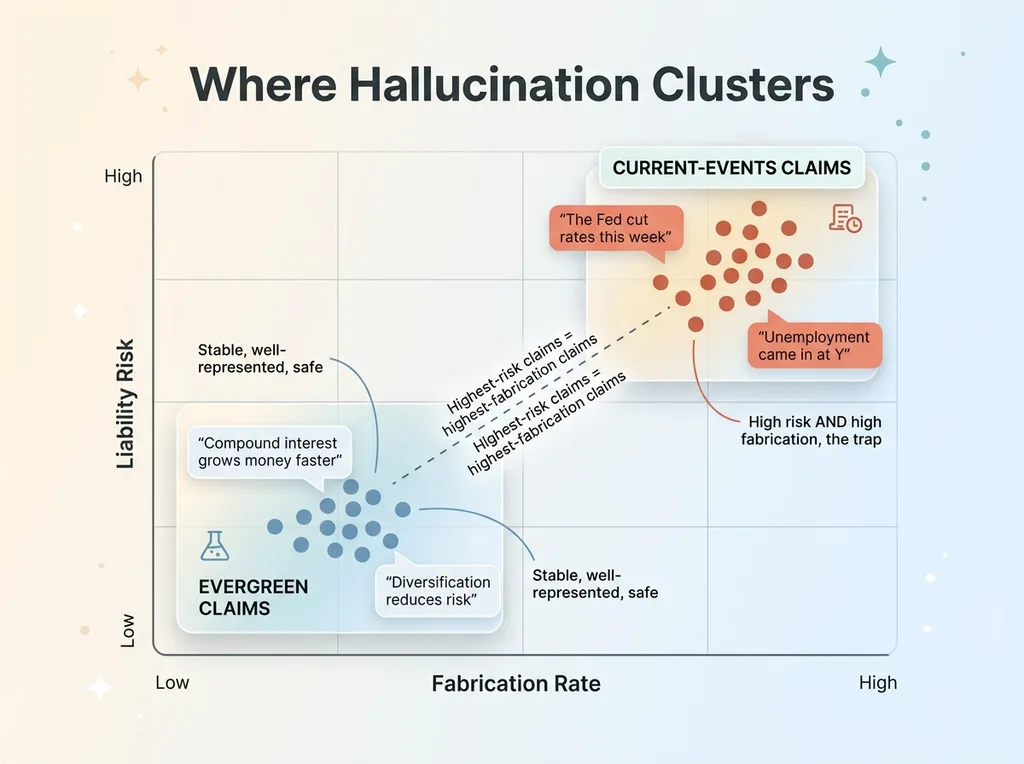
Here's something I've learned watching these systems fail: hallucination isn't random. It clusters. And it clusters around exactly the claims that matter most.
Evergreen explanations are low-risk. "Compound interest grows your money faster the earlier you start" is something the model will get right essentially every time, because it's a stable, well-represented concept. There's no "this week" to get wrong.
Current-events claims are where models fabricate. "The Fed did X this week." "Unemployment came in at Y." "The market reacted to Z." These are timely, specific, factual statements, and they're precisely where the model invents details, because it's pattern-matching to what a typical week sounds like rather than reporting what actually happened.
So the highest-risk claims and the highest-fabrication-rate claims are the same claims. That's the trap regulated firms fall into.
The fix is not a smarter model. A bigger model still hallucinates current events. The fix is architectural: you have to constrain the model to a pool of facts it cannot invent. You have to lock the AI to a verified source of truth and refuse to let it free-associate about reality.
Once you accept that, the engineering problem becomes clear. Build the pool. Make the model cite it. Verify the citations with code. Fail safe when anything doesn't check out.
That's what I built next.
Building a Three-Source News Verifier
I tore out the single source. In its place I built a multi-source news verification layer that pulls from three independent channels.
The three channels are deliberately different in kind: a structured news API, a live-search-capable model, and direct scraping of reputable outlets. The reason for three, and the reason they're independent, is the same reason journalism has always worked this way. A single source can be wrong, stale, or fabricated. Independent corroboration is what separates reporting from rumor.
If I'd used three sources that all pulled from the same upstream feed, I'd have one source wearing three hats. Independence is the whole point. When three genuinely separate channels report the same event, the odds that all three are simultaneously wrong drop dramatically.
Tiering outlets by trust
Not all sources deserve equal weight, so every outlet gets scored.
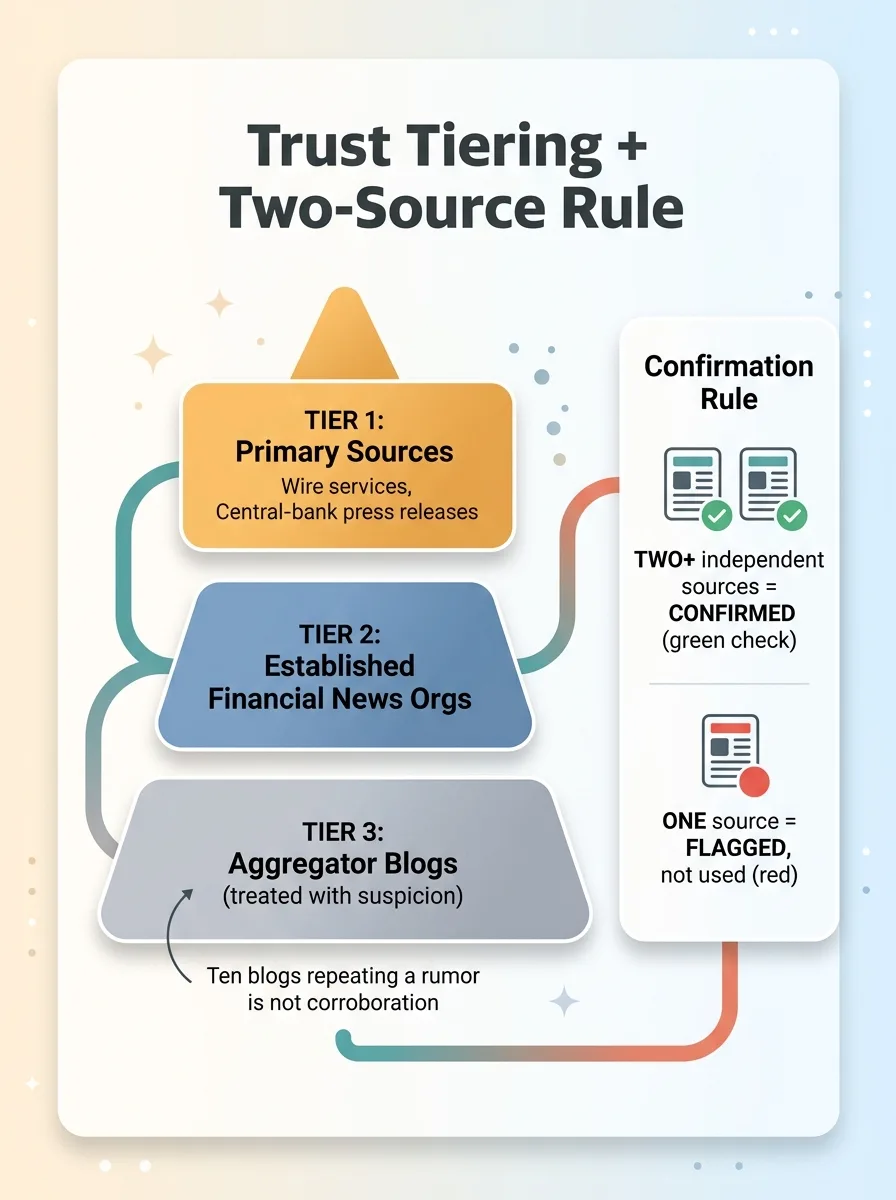
A wire service or a central-bank press release sits at the top tier. That's primary-source material, the closest thing to the event itself. An established financial news organization sits below that. An aggregator blog that reposts other people's reporting sits near the bottom.
When the system evaluates a headline, the tier matters. A claim corroborated by two top-tier sources is rock solid. A claim that only shows up on low-tier aggregators gets treated with suspicion, even if multiple aggregators carry it, because they're often just echoing the same unverified origin.
Trust tiering is what stops the system from confusing volume with veracity. Ten blogs repeating a rumor is not corroboration. Two independent primary sources is.
The two-source confirmation rule
Here's the rule that does the heavy lifting. A headline is only marked "confirmed" when two or more independent sources report the same event.
 Source trust tiering and two-source confirmation rule
Source trust tiering and two-source confirmation rule
One source reporting something? Flagged, not used. It might be true. It might be early. It might be wrong. The system doesn't gamble on it.
This is the heart of the ai fact grounding pipeline. The output of this layer isn't "here's what's happening this week" as a blob of text. It's a structured pool of confirmed headlines, each one corroborated, each one carrying its sources and a citation ID. The drafting model doesn't get to summarize the news anymore. It gets a vetted list of facts it's allowed to reference, and nothing else.
Forcing Every Claim to Declare Itself: Evergreen vs. Factual
Building the verified pool is half the fix. The other half is forcing the draft to use it.
After the model writes the rundown, every single claim has to declare what kind of claim it is. There are exactly two types.
Evergreen claims are general financial education. "Diversification reduces risk." "Tax-advantaged accounts compound faster." These are timeless, low-risk, and need no citation. The host can say them any week of the year and they're just as true.
Factual claims are timely statements about what's happening now. "Mortgage rates moved this week." "The latest jobs report showed X." Every factual claim must carry a citation ID that points into the verified pool.
The model does the first-pass classification. It labels each claim as it writes. And here's the critical design principle: classification alone is not trust.
You do not let the AI grade its own homework on whether a fact is real. The model labeling a claim "factual" doesn't make it true. The model attaching a citation ID doesn't make the citation valid. Those are just claims about claims.
What the typing does is something subtler and more valuable. It forces every sentence to declare its risk profile. An evergreen claim is announcing "I don't depend on current events, judge me on general accuracy." A factual claim is announcing "I'm asserting something about the world this week, and here's the receipt I'm pointing to."
This separation is enormous for shrinking the blast radius. In a typical rundown, most of the content is evergreen, the stable educational stuff. Only a handful of sentences are factual, timely claims. By typing them, I've isolated the dangerous lines from the safe ones. Now I only have to rigorously verify the small set of sentences that can actually hurt the firm.
A factual claim with no citation ID isn't a borderline case. It's not a valid claim, full stop. It either points to a verified headline or it doesn't ship.
The Runtime Verifier That Walks Every Citation
Now the enforcement layer. This is code, not a model.
 Runtime citation verifier, the deterministic check
Runtime citation verifier, the deterministic check
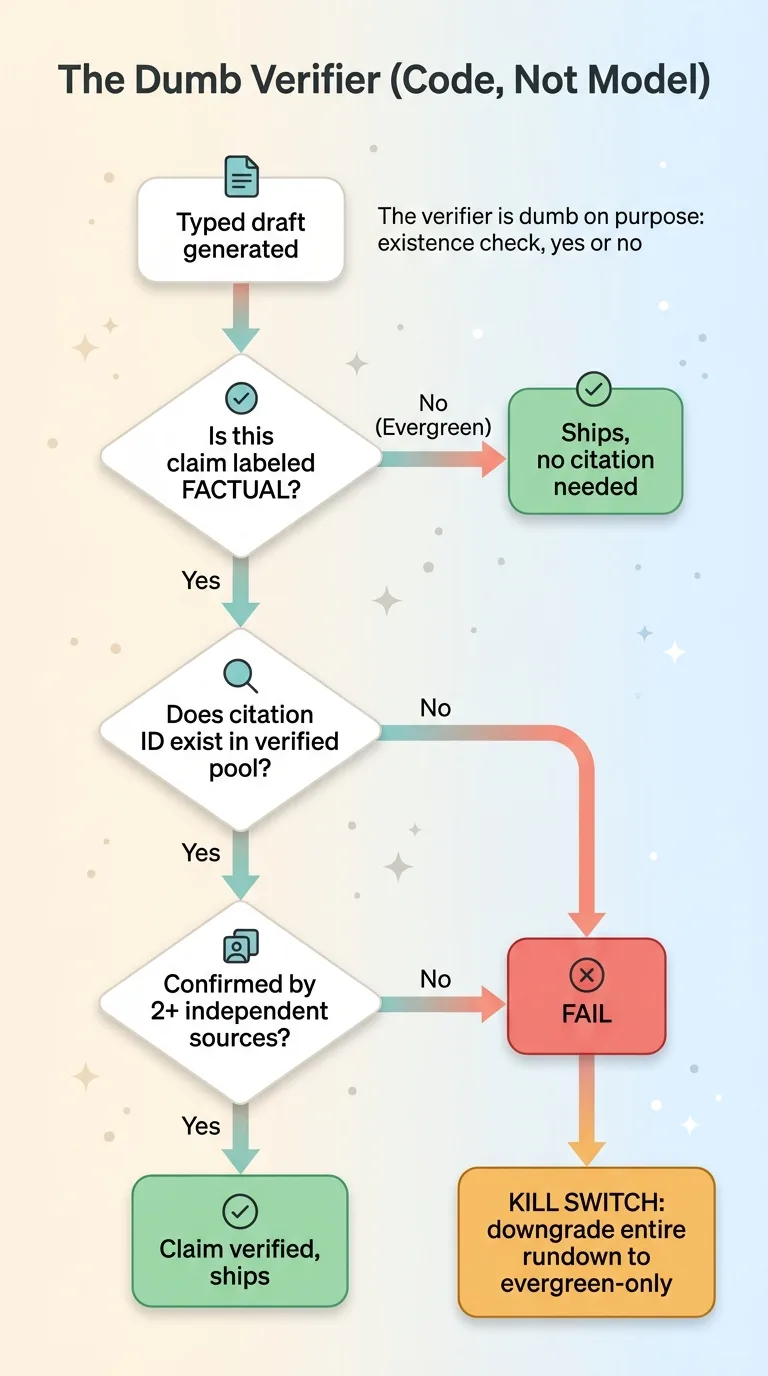
After the typed draft is generated, a verifier walks every claim in the rundown. For each claim labeled "factual," it does two checks. First: does the cited ID actually exist in the verified news pool? Second: was that headline confirmed by two or more independent sources?
The model can claim a citation. The code checks whether the citation is real. That's the entire distinction, and it's the most important architectural decision in the whole system. This is the line where the model stops judging and code starts computing. I've written before about why you let the model judge but let code do the verifying, and this is that principle at its sharpest.
The verifier is dumb on purpose. I want to be clear about that, because people assume more intelligence is always better. Here it's the opposite.
The verifier does not reason about whether a claim sounds plausible. It does not evaluate the quality of the writing. It does not have opinions. It performs one operation: does this citation ID resolve to a real, two-source-confirmed headline in the pool, yes or no?
That dumbness is exactly why it's trustworthy. A smart verifier could be talked into things, could rationalize a borderline claim, could hallucinate its own judgment. A dumb existence check can't. There's no plausibility for a fabricated citation to exploit.
This is how you prevent ai hallucination citations at the mechanical level. When the model invents a fact, it has to invent a citation ID to go with it (because every factual claim requires one). That fabricated ID has nothing to point to. It's not in the pool. The check fails instantly, deterministically, every time.
The model can be as creative as it wants. It cannot create a citation that resolves to a source that doesn't exist. The pool is the ground truth, and the code is the bouncer at the door checking IDs against the list.
The Kill Switch: Downgrade to Evergreen-Only
So what happens when a factual claim fails verification?
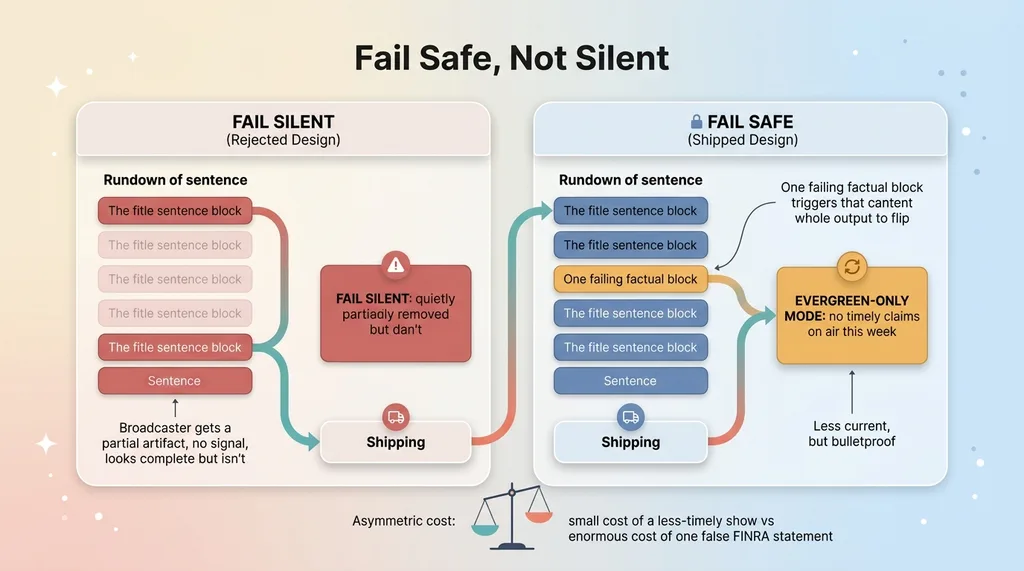 Fail-safe kill switch vs fail-silent trimming
Fail-safe kill switch vs fail-silent trimming
The whole rundown gets downgraded. Not the failing line. The whole thing. The output flips to "evergreen-only: do not make timely claims on air."
This is the design philosophy that matters most: the system fails safe, not silent.
I deliberately did not build it to trim out the bad lines and ship the good parts. That sounds reasonable until you think about the failure mode. If the system quietly removes three sentences and ships the rest, the broadcaster has no idea which lines were pulled or why. They're working with a partially-verified artifact and no signal about its trustworthiness. That's worse than useless, it's dangerous, because it looks complete.
Instead, the moment any factual claim fails, the entire output flips to a mode where the host delivers only timeless educational content that week. No timely claims at all. The show is less current, but it's bulletproof.
That's conservative on purpose. In a regulated context, the math is lopsided. The cost of a less-timely show is small. The cost of one false statement of fact on a FINRA-regulated broadcast is potentially enormous. When the downside is that asymmetric, you fail toward safety every time.
This ties directly into how I think about every system I ship stopping for a human. A human reviewer still signs off before anything airs. But there's a difference between a human reviewing raw model output (where they'd have to fact-check every sentence themselves) and a human reviewing a constrained, verified, citation-backed artifact. In the first case the human is the entire defense. In the second, they're the final check on a system that's already done the hard verification.
The human reviews a smaller, safer surface. That's the whole point of building everything underneath it.
What This Costs You to Skip, and What It's Worth to Get Right
Step back and the real lesson isn't about a radio show.
This was never a content problem. It was a liability architecture problem. And most teams deploying AI in regulated spaces (financial, legal, medical, advisory) don't discover the gap until something false has already gone out the door. By then it's not a design conversation, it's a damage-control conversation.
The pattern generalizes well beyond broadcasting. Any time AI produces statements of fact that carry legal or financial weight, you need the same three things: provenance (every fact traces to a real source), deterministic verification (code checks the trace, not a model), and a fail-safe default (when in doubt, the system refuses rather than guesses). This is the spine of shipping AI content in a regulated industry.
Let me be honest about what this doesn't do. It does not make the AI smarter. The model still hallucinates exactly as much as before. I just built a cage that catches the hallucinations before they reach an audience. It also adds latency and engineering cost. Multi-source verification takes time. The verifier is more code to maintain.
But for a regulated broadcaster, the alternative is hoping the model behaves. That's not a strategy. That's a bet, and it's a bet where you lose big the one time it goes wrong.
Here's the question I'd put to you if you're putting AI in front of customers or the public in a regulated industry. It's not whether the model will eventually make something up. It will. That's what these models do. The question is whether your system catches it before it ships.
Most of the systems I see don't. They're one plausible-sounding fabrication away from a problem nobody planned for.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits, including where your current output could be creating exposure you haven't audited yet.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call