AI Route Optimization Scheduling: Where Math Beats AI
How I built AI route optimization scheduling for a field install team: an LLM handles judgment, deterministic 2-opt handles the math. Here's the split.
By Mike Hodgen
How a Field Team Actually Plans Routes (Badly)
Picture a window-treatment install company on a Monday morning. One person sits in front of a wall calendar, coffee going cold, trying to figure out which of four installers takes which of thirty jobs that week, and in what order they drive to them.
That's it. That's the system. AI route optimization scheduling is the last thing on this person's mind, because right now the "engine" is a calendar and a memory.
The read-only calendar problem
The calendar shows appointments. It does not show drive time between them. It doesn't know that two of those jobs are forty minutes apart in opposite directions. It can't tell you which installer is already at capacity, or which one actually knows how to handle motorized shades versus basic roller blinds.
All of that lives in the dispatcher's head. Which works fine until the dispatcher is sick, or quits, or just has a bad day. The whole operation runs on one person's mental map.
What 'eyeballing it' costs
Here's what eyeballing it produces in practice. A job assigned to an installer who's never done that product type, so it takes twice as long. Two installers crossing the same town twice in one day because nobody saw the overlap. A due date missed because it was buried three screens down in the calendar and never surfaced.
None of this is a motivation problem. The dispatcher is working hard. The problem is that a single human cannot hold geography, capacity, skill matching, and due dates in their head all at once. Nobody can. Four variables across thirty jobs and four people is a combinatorial mess.
This is how most field service businesses actually run. Not because they're lazy, but because the planning problem is genuinely too big for one brain.
The Mistake Most People Make: Asking AI to Do the Routing
When people finally decide to fix this, the instinct is to throw the whole thing at a frontier model. "Here are thirty jobs, here are four installers, plan my week." Paste it into ChatGPT and pray.
That fails. And it fails in ways that are dangerous because they look plausible.
Why an LLM can't reliably order stops
LLMs are bad at the math part of routing. Ask a model to compute drive time across a matrix of thirty stops and it will hallucinate distances. It'll tell you two addresses are twelve minutes apart when they're forty. It has no actual map. It's pattern-matching on what driving distances usually look like.
Worse, it's non-deterministic. Run the same prompt twice and you get two different routes. You cannot run a field operation on a tool that gives a different answer every time you ask the same question.
Routing is a solved math problem, not a judgment call
Here's the thing people miss. Ordering stops to minimize driving is the traveling salesman problem. It has been studied for decades. There are proven algorithms that get you near-optimal answers fast and the same way every time.
Asking an LLM to guess at stop order is using the wrong tool for a job that math already solved. When the answer can be computed exactly, you compute it. You don't ask a probabilistic model to estimate what a function can calculate precisely.
I've written before about where I draw the line on letting a model compute. Routing is the cleanest example I know. The model should never touch the distance math.
Splitting the Problem: Judgment vs. Math
The fix is to stop treating this as one problem. It's two. And they need two different tools.
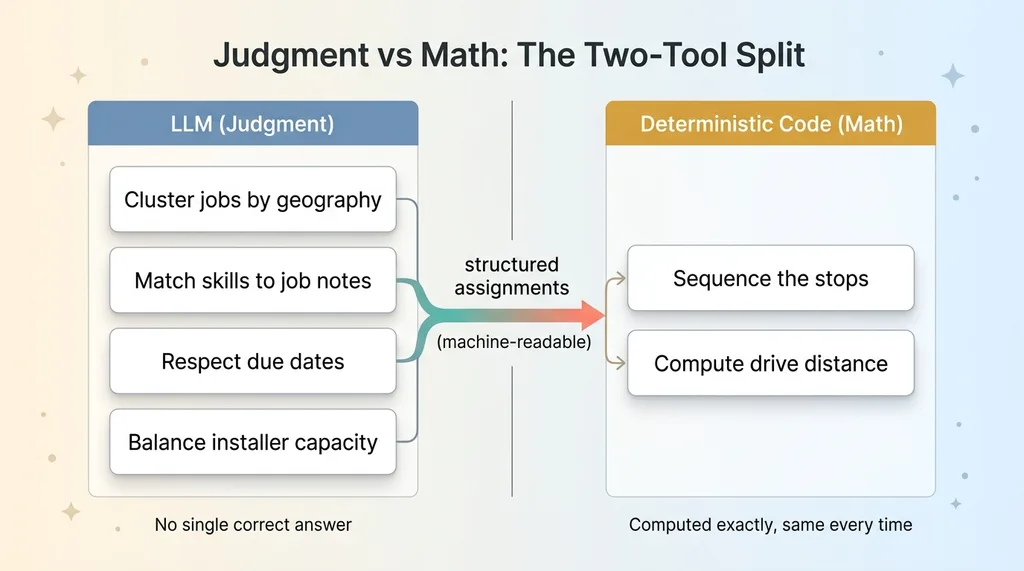 Judgment vs Math: The Two-Tool Split
Judgment vs Math: The Two-Tool Split
What the language model decides
The LLM handles the fuzzy stuff, the parts where there's no single correct answer and you need judgment.
Clustering jobs by geography so the day's work is in the same area. Reading the job notes and matching them to the right installer's skills. Respecting due dates. Balancing the load so one person isn't slammed while another has two jobs. These are judgment calls with tradeoffs, exactly what language models are good at.
Critically, the model outputs structured assignments, not prose. It returns who installs what, on which day, in a machine-readable format. Not a paragraph explaining its reasoning. Structured output means the next step in the pipeline can actually use the answer.
What deterministic code decides
Once the model has assigned jobs to installers and days, deterministic code takes over. Given one installer's list of stops for Tuesday, the code computes the order that minimizes driving. Every time. Same input, same output.
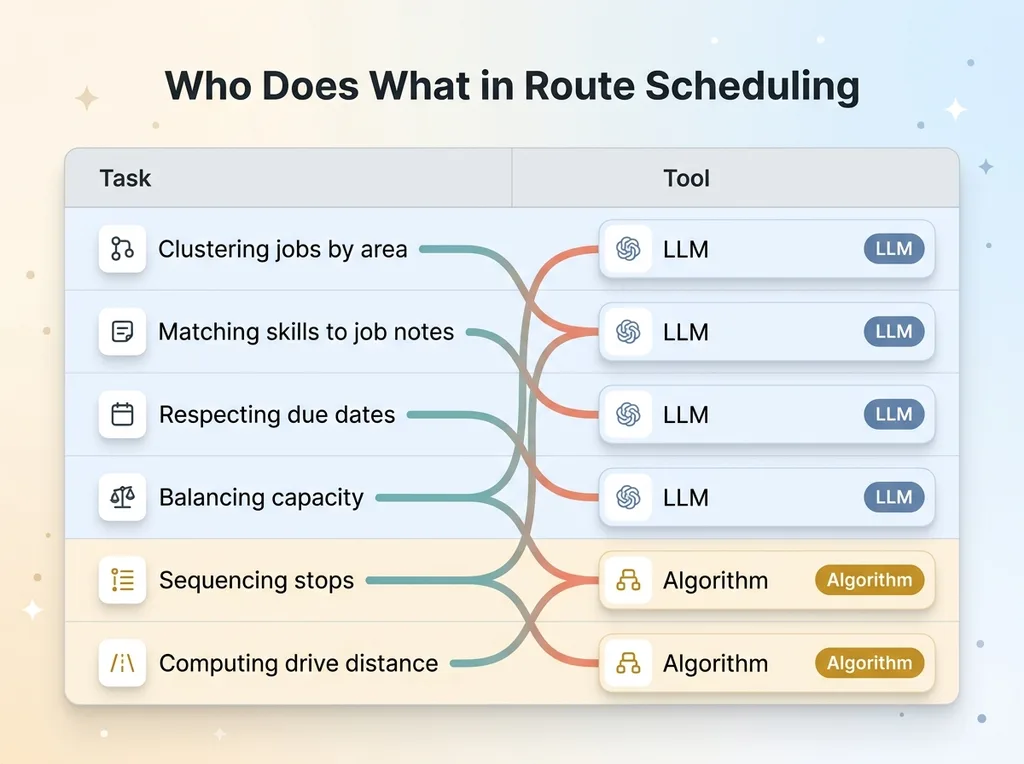 Task-to-Tool Assignment Matrix
Task-to-Tool Assignment Matrix
| Task | Tool | |------|------| | Clustering jobs by area | LLM | | Matching skills to job notes | LLM | | Respecting due dates | LLM | | Balancing capacity | LLM | | Sequencing stops | Algorithm | | Computing drive distance | Algorithm |
This is the architecture I keep coming back to: let the model judge and the code compute. The model decides who and what. The code decides the order and the distance. Clean line, no overlap.
When you split it this way, both halves get more reliable. The model isn't asked to do arithmetic it's bad at. The code isn't asked to make judgment calls it can't make.
The Routing Math: Nearest-Neighbor Plus 2-opt
So how does the code actually order the stops? Three steps, and none of them are mysterious once you see them.
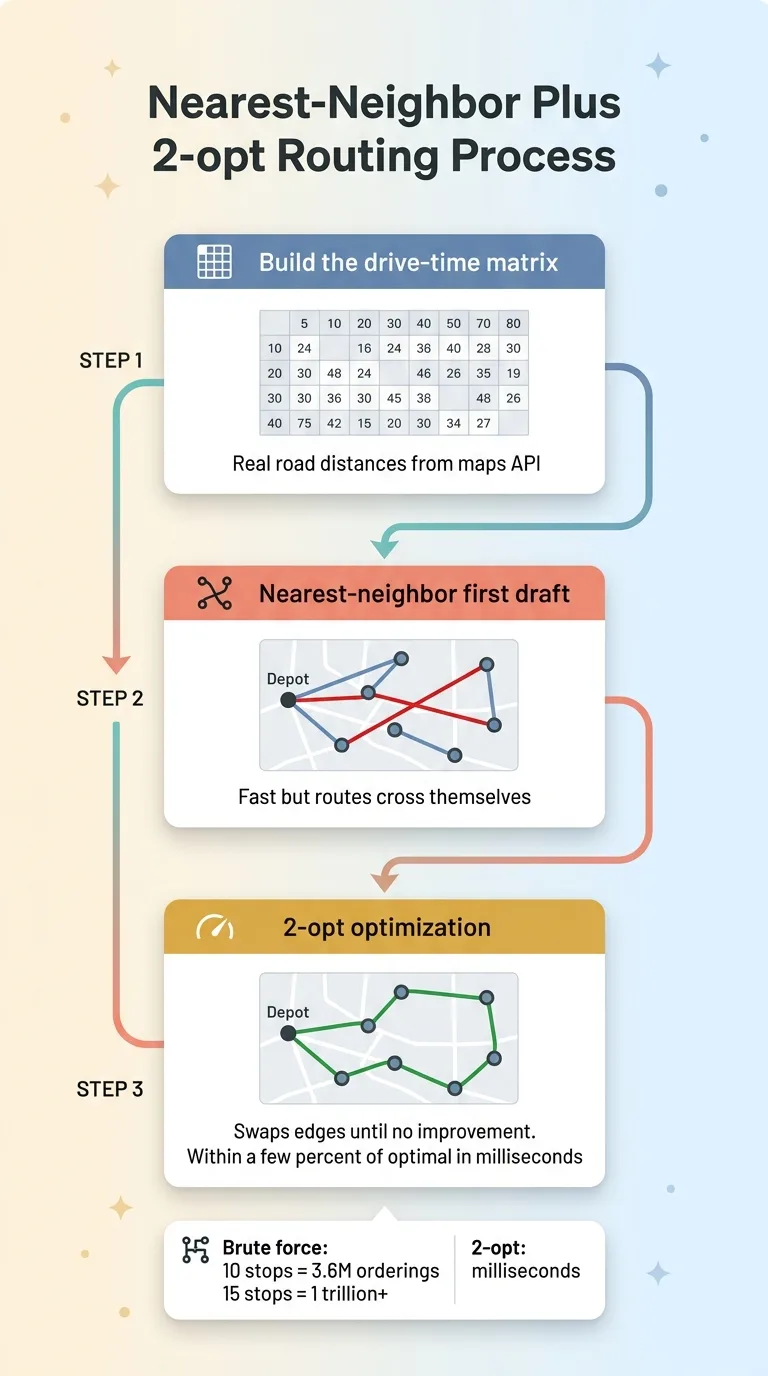 Nearest-Neighbor Plus 2-opt Routing Process
Nearest-Neighbor Plus 2-opt Routing Process
Building the drive-time matrix
Step one: build a matrix of drive times between every pair of stops. If an installer has eight jobs, that's the drive time from each one to every other one. You get these numbers from a maps API, real road distances, not crow-flies guesses.
This matrix is the foundation. Everything else operates on it.
Why 2-opt and not brute force
Step two: nearest-neighbor gives you a fast first draft. Start at the depot, go to the closest stop, then the closest unvisited stop from there, and so on. Quick, but not optimal. It tends to leave you with routes that cross over themselves.
Step three is where vehicle routing 2-opt comes in. 2-opt repeatedly takes two edges in the route, swaps them, and checks if the total distance dropped. If it did, keep the swap. Repeat until no swap improves things. This systematically removes the crossings and tightens the loop.
Why not just brute-force every possible order? Because the number of permutations explodes. Ten stops is 3.6 million orderings. Fifteen stops is over a trillion. You'd never finish. 2-opt gets you within a few percent of optimal in milliseconds.
The straight-line fallback
Here's the resilience detail that matters in production. What happens if the maps API key is missing, or the service is down?
The system falls back to straight-line (haversine) distance. It calculates the geographic distance between coordinates directly, no API needed. The system degrades gracefully instead of crashing.
Honest note: straight-line distance is approximate. It doesn't know about highways or one-way streets. But a day routed by straight-line distance still beats a day ordered randomly by a long shot. Graceful degradation beats a hard failure every single time.
Geocode Once, Cache Forever
Here's the unglamorous part that determines whether this thing is cheap or expensive to run.
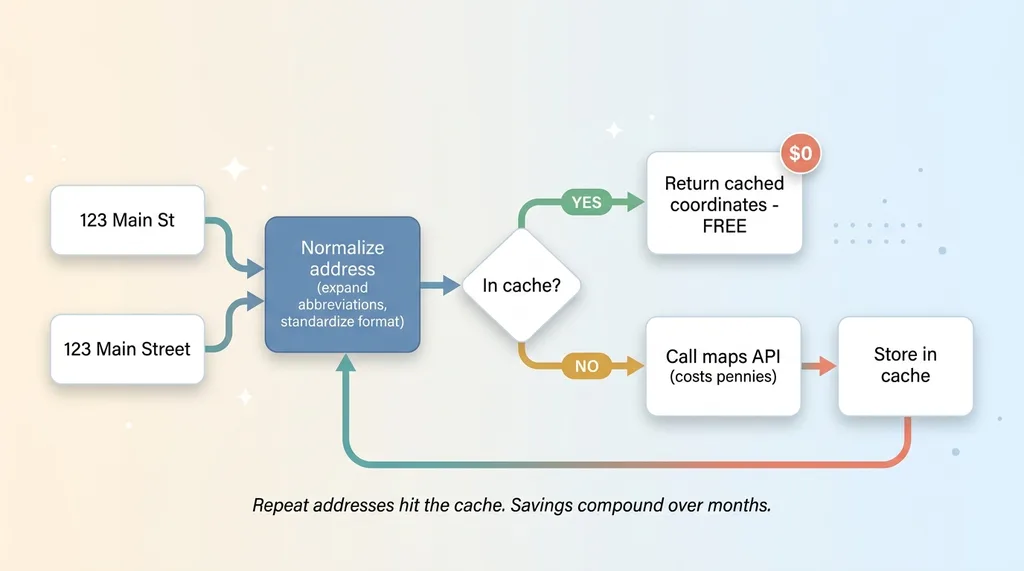 Geocode Once, Cache Forever with Normalization
Geocode Once, Cache Forever with Normalization
Why repeated lookups quietly cost money
Every address has to be turned into coordinates (latitude and longitude) before you can compute anything. That's geocoding, and most maps APIs charge per lookup. Pennies each, but it adds up fast when you're processing thirty jobs a week, every week.
The fix is simple: geocode every address exactly once, then cache the result. You never pay for the same lookup twice.
Field businesses see the same addresses constantly. Repeat customers. Neighbors who saw your van and called. The same office buildings and apartment complexes over and over. The cache hit rate climbs over time, and the savings compound. After a few months, most of your lookups are free because you've already seen the address.
Address normalization before caching
One detail that separates a cache that works from one that quietly leaks money: normalize the address string before you cache it.
"123 Main St" and "123 Main Street" are the same place. If you cache them separately, you've just paid twice for one address and created a duplicate. Normalize the string first, expand abbreviations, standardize the format, then check the cache. Now both spellings hit the same cached coordinate.
This is boring plumbing. It's also exactly the kind of data hygiene that makes AI systems affordable to run at scale. The flashy part is the routing. The part that keeps your bill low is normalizing "St" to "Street" before you call the API.
A Human Still Approves Every Route
The scheduler produces a complete plan. Assignments, ordered routes, drive times. And then it stops and waits.
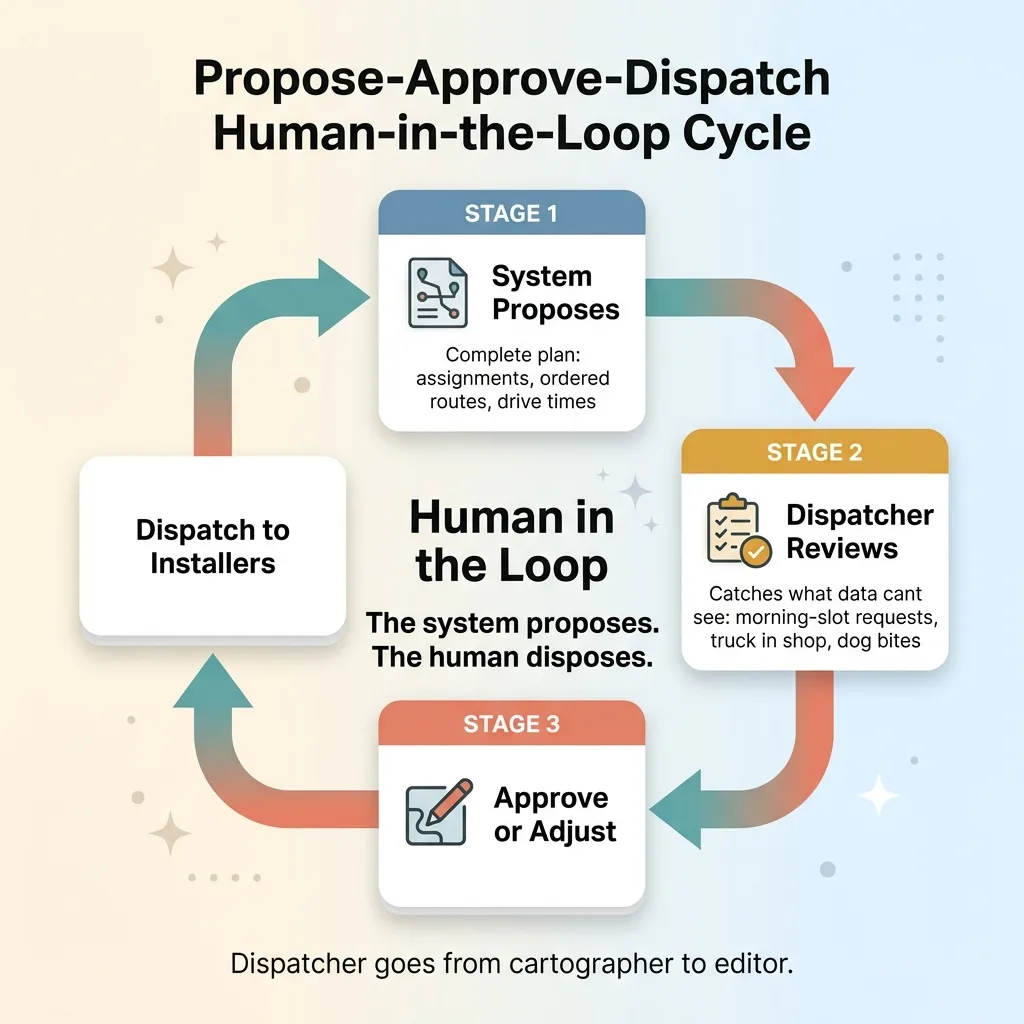 Propose-Approve-Dispatch Human-in-the-Loop Cycle
Propose-Approve-Dispatch Human-in-the-Loop Cycle
Nothing auto-dispatches
Nothing dispatches automatically. The system proposes, a human disposes. The dispatcher opens the proposed plan, sees the drive times laid out for the first time ever, and approves or adjusts before anything goes to the installers.
This is deliberate. I build every system this way, and I've written about why every AI action stops for a human.
Why the dispatcher stays in the loop
The model doesn't know everything. It doesn't know that one customer specifically asked for a morning slot because they work afternoons. It doesn't know that an installer's truck is in the shop today and he's borrowing a smaller van that can't fit the big window units. It doesn't know the homeowner's dog bites and the installer wants backup.
The human catches what the data can't see. That context lives outside the system, in phone calls and texts and tribal knowledge.
Frame this correctly: it's a feature, not a limitation. The dispatcher's job changes from guessing to reviewing. Instead of building the whole plan from scratch in their head, they're checking a solid draft and making small adjustments. That's faster, less stressful, and far less error-prone. They go from cartographer to editor.
Where AI Belongs in Your Scheduling, and Where It Doesn't
If you take one thing from this, take the rule.
The general rule for build decisions
Use AI for the parts that require judgment and have no single right answer. Use deterministic code for the parts that can be calculated and must be correct.
Most field service dispatch AI gets this exactly backwards. They ask the model to do the routing math (which it's bad at) and they hard-code the judgment calls into rigid rules (which can't handle real-world nuance). Both halves end up worse. The LLM plus deterministic algorithm split fixes both at once.
What this looks like in your business
This isn't only about window treatments. If you run an install team, a service fleet, a delivery operation, or anything where a human plans routes by hand, the same split applies. Assignments and clustering go to the model. Sequencing and distance go to the algorithm. A human approves the result.
Whatever install scheduling software you eventually run, that division of labor is what makes it trustworthy.
Here's what I'll tell you honestly, though. The hardest part of building this was not the 2-opt algorithm. That's textbook. The hard part was sitting with the dispatcher and understanding exactly how they thought, what they checked, what they knew that wasn't written down anywhere. That's the real work, and it's why generic scheduling tools so often fail. They never learned how your dispatcher actually thinks.
So if you've got someone planning routes by hand, tell me what your dispatcher does by hand. That conversation is where every good system starts.
Thinking about AI for your business?
If this resonated, let's talk. I do free 30-minute discovery calls where we look at how your operations actually run and find the places where AI could genuinely move the needle, not where it just sounds impressive in a pitch deck.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call