Build an AI Searchable Knowledge Base for Legal Cases
I turned 1,600+ scattered emails and PDFs into an AI searchable knowledge base I can query in plain English. Here's how to stop re-reading threads.
By Mike Hodgen
The Real Problem: Every Question Means Re-Reading a Thread
A few years back I watched a complex legal dispute eat people alive, not because the legal arguments were hard, but because nobody could find anything. The matter spanned multiple cases. It generated thousands of emails plus PDFs scattered across two or three Gmail accounts and a graveyard of folders nobody could navigate.
Every time someone asked a simple question, the whole thing ground to a halt. "What did we agree about the March shipment?" "When did the other side first raise the warranty issue?" "How much are they actually claiming on the second invoice?"
The answer always lived inside a thread. The problem was you had to remember the thread existed first. Then you had to find it. Then you had to re-read it, in full, to reconstruct the context you'd already had two months ago and forgotten.
This is where an AI searchable knowledge base earns its keep, and where most people never think to build one. The cost of not having one is brutal and invisible. I watched the same questions get re-litigated internally three and four times. Decisions got made on stale information because the person making them couldn't find the email that changed everything. Hours disappeared into inbox archaeology.
If you've ever run a long vendor fight, a contract dispute, an acquisition, or any document-heavy matter, you know this exact feeling. The information you need exists. You paid for it. It's just trapped in a format where every answer requires a human to re-read something.
That's not a search problem. That's a structure problem. And it's fixable.
Why Email Search Isn't a Knowledge Base
 Email Search vs Knowledge Base
Email Search vs Knowledge Base
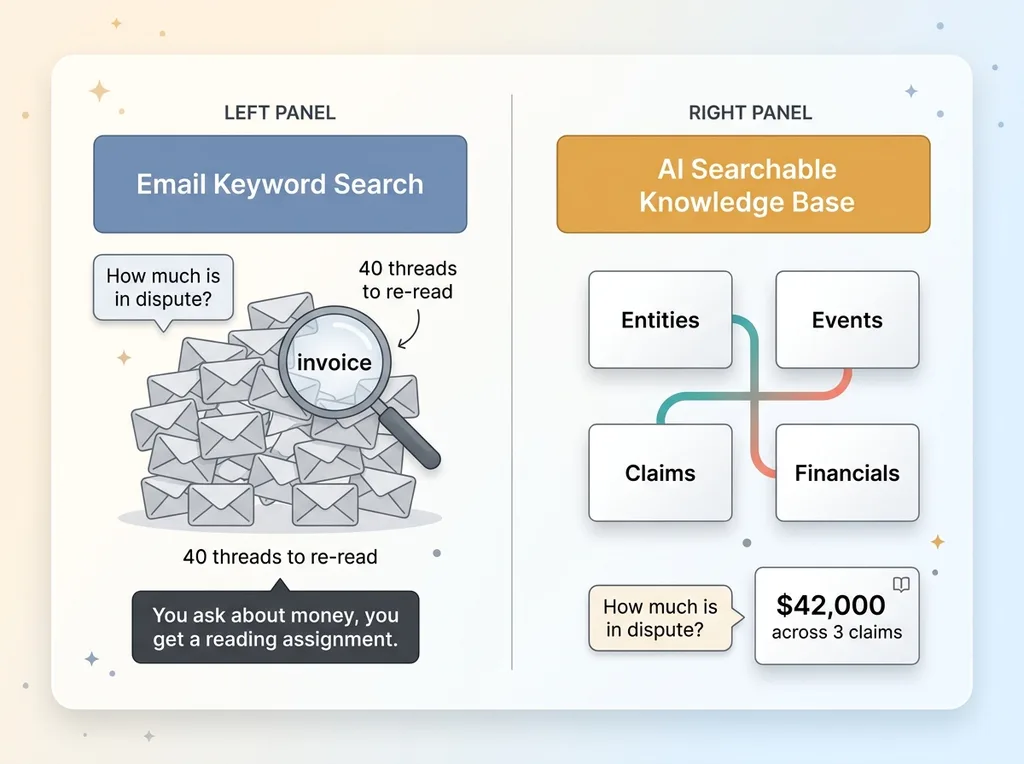
Search finds messages, not answers
Gmail search is good at one thing: finding emails that contain a word. That's it. Type "invoice" and you get 40 threads back. Useful if you already know which thread you want. Useless if your actual question is "how much is in dispute, and who's claiming it."
A dispute isn't a pile of emails. It's a web of facts. Who said what. When they said it. What got agreed. What's owed. Which claim ties to which event. Email keyword search can't model any of that, because it treats every message as an undifferentiated blob of text.
You ask a question about money and get back a reading assignment. The search engine doesn't know what an invoice is. It just knows the letters appeared somewhere.
Context lives in your head, not the inbox
The reason a dispute feels manageable for the first month is that the context lives in your head. You remember the sequence. You remember the deal points. You remember who flaked on what.
Then time passes. People rotate off. The matter gets handed to someone new. And suddenly all that context that was never written down anywhere structured is just gone. The inbox didn't capture it. The inbox only captured the messages.
So the unit of organization has to change. You can't organize a complex matter around "messages." You have to organize it around facts: entities, events, claims, financials. A full text search over an email database is a starting point, but it's not the destination. The destination is a structure where the question maps to an answer, not to a stack of things to re-read.
What I Built: A Queryable Brain Over the Whole Matter
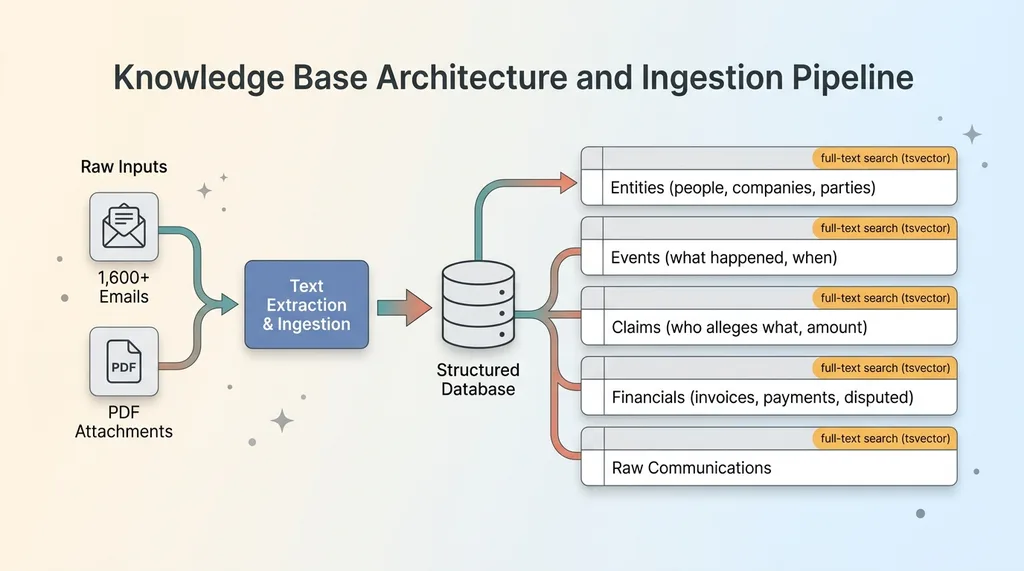
I took 1,600+ raw emails plus the document attachments and ingested all of it into a real database. Not a folder system. Not a tagging scheme. A structured set of tables designed around the facts of the matter.
Structured tables for entities, events, claims, and financials
The schema broke the chaos into things you'd actually query. One table for entities (the people, companies, and parties involved). One for events (what happened, and when). One for claims (who's alleging what, and the amount). One for financials (invoices, amounts disputed, payments). Plus a table holding the raw communications themselves, so nothing got thrown away.
This is the same pattern I use when I build a knowledge base with AI search for a professional services firm. The domain changes, the structure doesn't. You model the facts that matter, then you make them queryable.
Full-text search on every table
Every table got a full-text-search tsvector column. That means any field on any record is searchable, not just a single notes box. You can search across claims and events and entities at once, or scope it down to exactly one table when you know what you're after.
This is the layer that turns a full text search email database from a flat pile into something you can actually interrogate by topic, by party, by dollar amount.
Ingesting 1,600+ emails and the PDF attachments
Here's the part most quick builds skip. I didn't just index email subject lines and bodies. I downloaded the PDF attachments and ran text extraction on them, so the contents inside the documents became searchable too.
 Knowledge Base Architecture and Ingestion Pipeline
Knowledge Base Architecture and Ingestion Pipeline
That matters more than it sounds. Half the important facts in any dispute live inside attachments, not in the email body. A contract clause. A revised invoice. A signed amendment. If your search only sees filenames, you've indexed the cover and ignored the book.
By the end, the entire matter (every email, every document, every claim and amount) lived in one place that could answer questions instead of just storing text.
Asking Questions in Plain English Instead of Scanning Inboxes
This is the payoff. Everything above is plumbing. Here's what it buys you.
One query command
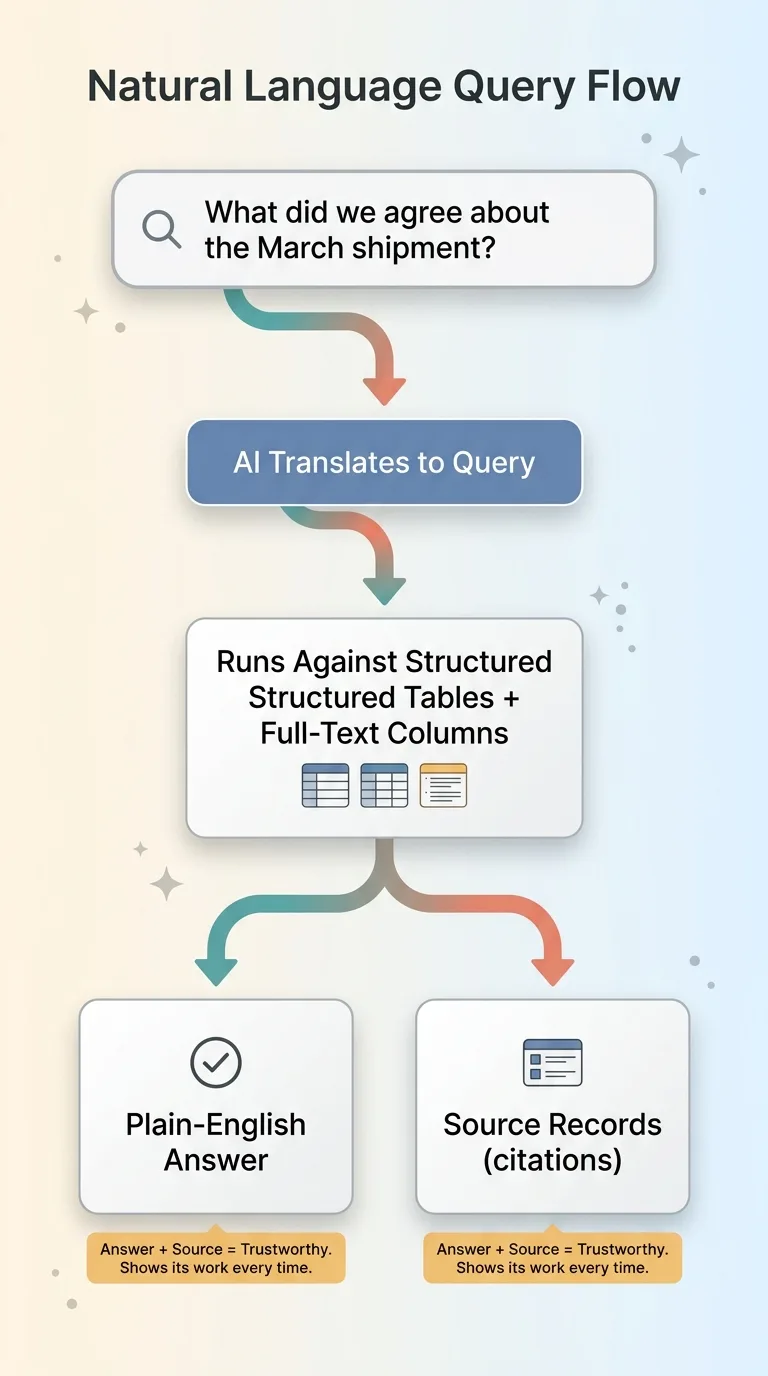
I exposed a single query command over the whole database. One entry point. I don't have to remember which table holds what or how the columns are named. I just ask.
Natural language over structured data
I ask the database questions in plain English. "What did we agree about the March shipment?" "List every claim over $10k." "What happened between these two dates?" "Which invoices are disputed and by whom?"
 Natural Language Query Flow
Natural Language Query Flow
The AI translates the question into a query against the structured tables and the full-text columns, runs it, and returns an answer with the underlying facts attached. Not 40 threads to re-read. The actual answer, plus the records it came from so I can verify it.
That last part matters. Natural language database query is only trustworthy when it shows its work. I want the answer and the source rows, every time. This is the same approach I took when I built a searchable brain for a legal case, where the whole point was surfacing the right records fast without trusting the model blindly.
Let me be honest about what this is and isn't. It surfaces the right records fast. It does not replace legal judgment. The system tells you what the facts say. A human still decides what those facts mean and what to do about them.
That's the right division of labor. The machine does the recall. The recall was never the hard part of being smart, it was just the slow part. Offload that, and the human gets to spend their time on the thing only a human can do: deciding.
The difference in practice is enormous. A question that used to take 20 minutes of inbox archaeology takes 15 seconds and comes back with citations. Multiply that across every question asked over the life of a matter and you understand why this is worth building.
Locking Down Sensitive Legal Data
Now the objection any serious person raises immediately: you just aggregated everything privileged and confidential into one database. Isn't that a liability?
 Row-Level Security vs UI-Only Hiding
Row-Level Security vs UI-Only Hiding
Yes. If you do it wrong.
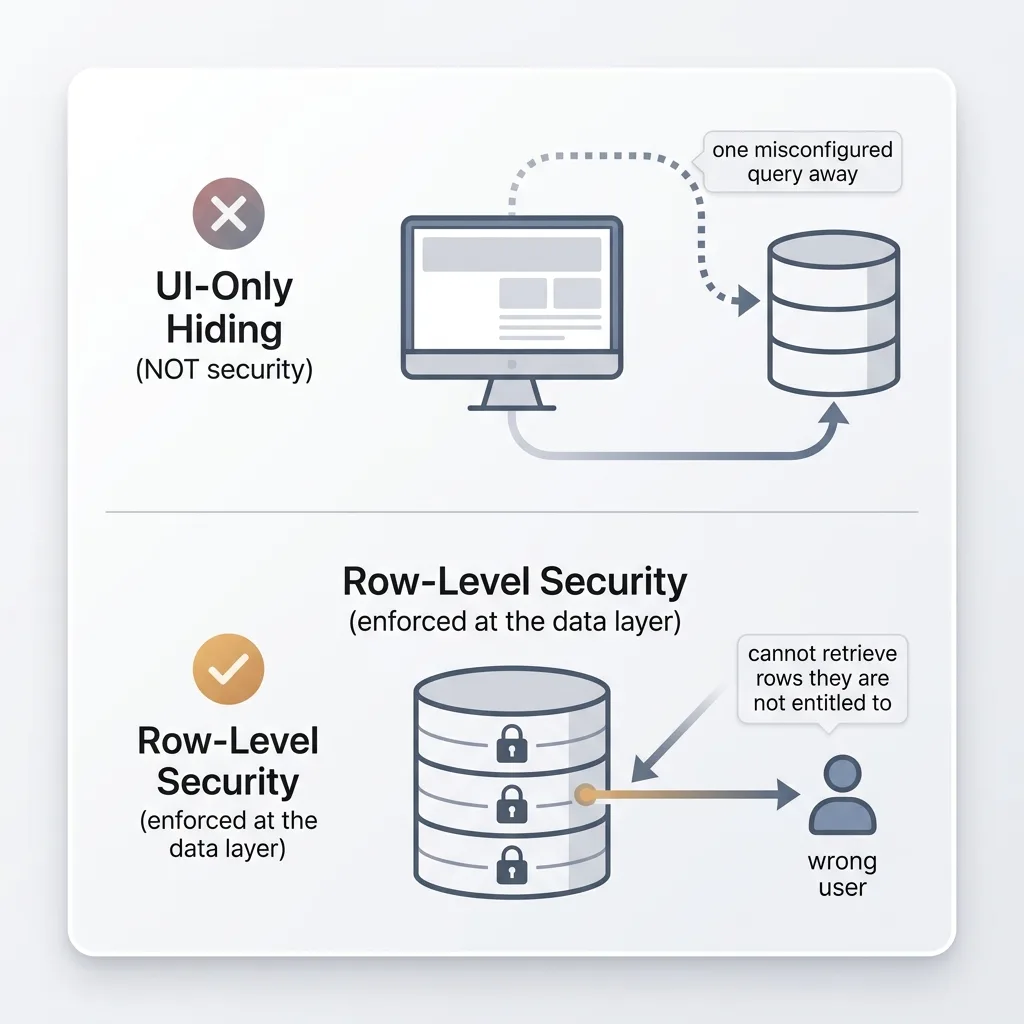
A knowledge base that pulls everything into one place is also a single point of exposure. The same property that makes it useful (everything's together, everything's queryable) makes it dangerous if you don't lock it down. So I enabled row-level security on the privileged tables.
That means access control happens at the database layer, not just hidden behind a UI. This distinction matters more than most people realize. Hiding sensitive data behind a screen the user isn't supposed to click is not security. The data is still right there, one misconfigured query away. Row-level security enforces access on the data itself, so the wrong person literally cannot retrieve rows they aren't entitled to, no matter how they connect.
For legal and financial data this isn't a nice-to-have. It's the entry fee. Privileged material, settlement figures, party communications, all of it has to be access-controlled at the layer that actually controls access. I walk through exactly how I do this at scale in my row-level security on the privileged tables playbook.
I'll be blunt: most fast builds skip this entirely. Someone wires up a slick natural-language search over confidential documents in a weekend and ships it with the security of a public spreadsheet. Encryption and access control are table stakes for this kind of system, not an upgrade you bolt on later. If a vendor builds you a legal knowledge base and can't tell you how the privileged data is locked down at the database layer, that's your answer about whether to trust them with it.
When This Pattern Is Worth It (And When It Isn't)
I don't think every matter needs this. Let me draw the line honestly.
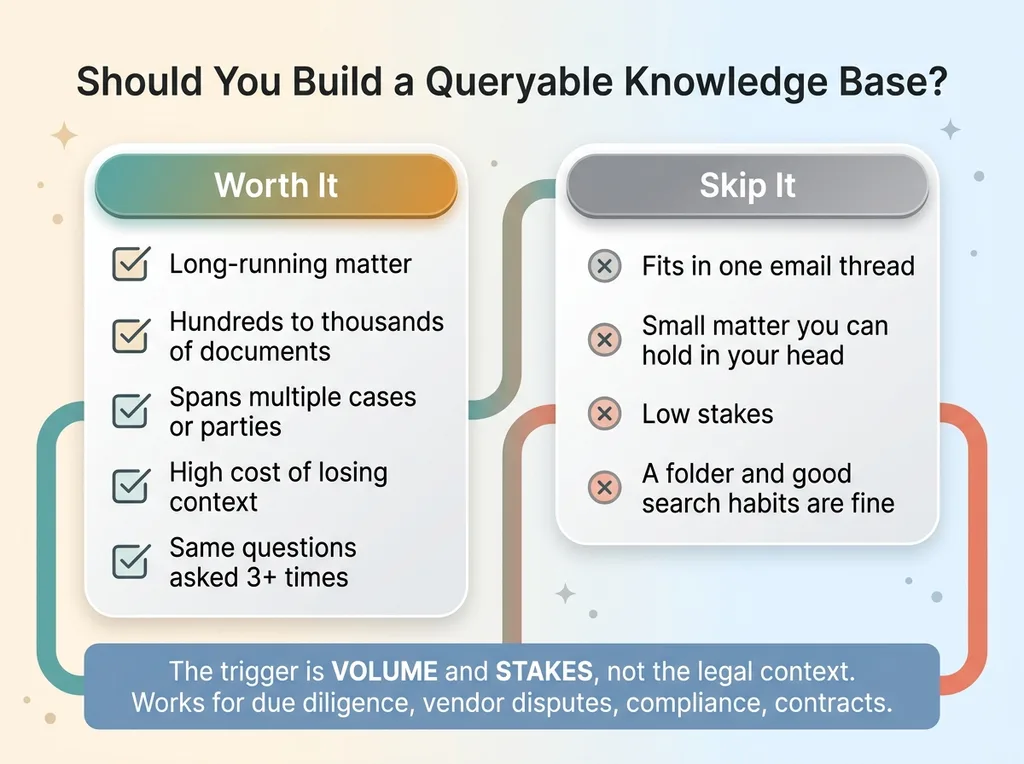 When to Build This Pattern (Decision Guide)
When to Build This Pattern (Decision Guide)
Worth it: long-running, document-heavy, high-stakes
Build this when the matter is long-running, generates hundreds or thousands of documents, spans multiple cases or parties, and the cost of losing context is real. By "real" I mean: missed facts that change outcomes, the same questions answered three times by three people, decisions made on stale information because nobody could find the current version.
When those conditions are true, the system pays for itself fast. Every question answered in seconds instead of half an hour. Every fact retrievable instead of remembered. Every decision made on what's actually true, not what someone half-recalls.
Skip it: a one-off thread or a small matter
If your whole dispute fits in one email thread, don't build a database. Just read the thread. The structure overhead isn't worth it for a matter you can hold in your head. There's a real crossover point, and below it, a folder and good search habits are genuinely fine.
Here's the part that matters for you, though: none of this is actually about legal work. The same approach works for any business sitting on a sprawling document corpus. Due diligence in an acquisition. A multi-year vendor dispute. A compliance matter with years of correspondence. A stack of contracts nobody can answer questions about.
The trigger isn't the legal context. The trigger is volume and stakes. When you have enough documents that re-reading is expensive, and the cost of missing a fact is high, this pattern earns its keep. The domain is almost irrelevant.
Your Business Already Has a Corpus Like This
Here's what I've learned building these. Almost every business is sitting on exactly this problem somewhere, and most don't recognize it as a problem they can fix.
A dispute that's been running for two years. A client relationship with a decade of email behind it. A regulatory matter with thousands of pages of correspondence. A pile of contracts where answering any real question means somebody re-reads three documents.
The context exists. You already paid for it. It's just trapped in threads and PDFs, in a format where every answer requires a human to go find it and read it again. That's not a knowledge problem. You have the knowledge. It's an access problem.
And the fix isn't better search habits or a cleaner folder structure. You can't organize your way out of this with discipline. The fix is a queryable brain over the corpus: structure the facts, make every field searchable, lock down what's sensitive, and put a plain-English question box on top of it.
If you've got a pile of documents and facts you keep re-reading, a matter where the same questions come up over and over, this is exactly the kind of system I build. The hard part isn't the AI. It's modeling your specific corpus so the answers are actually right. That's worth a conversation. Let's talk through what your own knowledge base would look like and whether the volume and stakes justify building one.
Thinking about AI for your business?
If this resonated, let's have a conversation. I do free 30-minute discovery calls where we look at your operations and find where AI could actually move the needle, not where it sounds impressive in a deck.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call