Compliant AI Content Automation: The Hard Gate
How I built compliant AI content automation for a regulated firm, with a hard compliance gate, auto-regeneration, and an append-only audit trail.
By Mike Hodgen
Why a Final Compliance Review Doesn't Work
A financial advisory firm came to me with a deceptively simple ask: one-click weekly content across multiple platforms, written for multiple advisors who are genuine experts but not marketers. They wanted the experts to push a button and get a week of posts ready to go.
Here's the catch that makes this hard. The firm is FINRA-regulated. Every single piece of content is a potential legal liability. One post with a performance guarantee, one "risk-free" phrasing, one cherry-picked return, one missing disclosure, and you're not looking at a typo. You're looking at a regulatory problem with real teeth.
So the question becomes: how do you build compliant AI content automation when a single bad post can trigger an examination?
The cost of one bad post
Most people underestimate this. A bad social post in an unregulated business is embarrassing. A bad post from a registered advisor is evidence. It sits there, timestamped, screenshot-able, and it implicates the advisor, the firm, and the compliance officer who let it through.
That changes the whole calculation. You can't treat content like a numbers game where 95% good is fine. In this world, 95% good means 5% liability.
Where most content tools put the check
The standard approach puts compliance review at the very end. Generate a stack of posts, queue them up, hand them to a human, let the human catch anything bad before it ships.
This fails for two reasons.
First, it kills the one-click promise. If a human has to review everything, you haven't automated content, you've just moved the bottleneck to the most expensive person in the room.
Second, and worse, humans approving a stack of pre-written posts get fatigued. By post number twelve, they're rubber-stamping. The error they were supposed to catch slips through because their brain checked out at post seven.
The check can't be a polite suggestion at the end. It has to be a structural gate in the middle. My core thesis on this project: nothing reaches a human until it's already clean. (If you want the broader picture, I wrote about shipping AI content in a regulated industry.)
Making the Compliance Check a Hard Gate, Not a Final Review
The architecture decision that makes everything else work: the compliance check sits in the middle of the pipeline, between generation and human review. Not at the end.
Every generated piece is scored against the firm's specific rule set before it can advance. A failing piece never moves forward. It never lands in a human's queue. It never gets seen by anyone until it passes.
In-loop vs end-of-line
Compare the two flows.
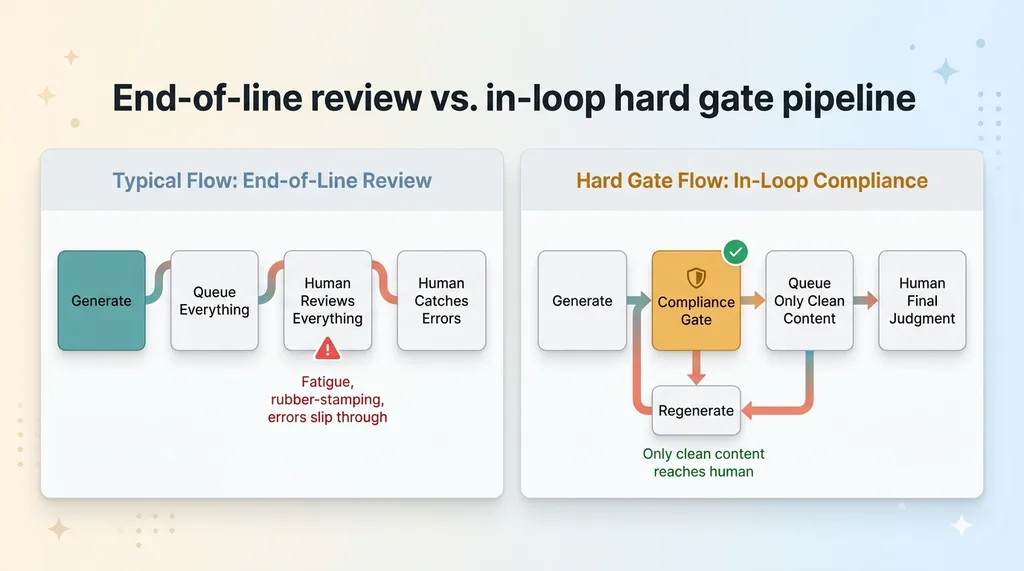 End-of-line review vs. in-loop hard gate pipeline comparison
End-of-line review vs. in-loop hard gate pipeline comparison
The typical flow: generate, queue everything, human reviews everything, human catches errors. The human's job is error-catching, which is exactly the job humans are worst at when they're tired.
My flow: generate, gate, regenerate failures, queue only what passed, human reviews pre-cleared content. The human's job shifts from catching errors to making a final judgment call on content that's already legally sound.
That's a different job entirely. Catching a missing disclosure in a stack of forty posts is grinding, error-prone work. Approving content that's already passed the rules is a quick, high-leverage decision.
What the gate actually blocks
The rule set encodes the firm's actual compliance requirements, not generic guidelines. For this client it included:
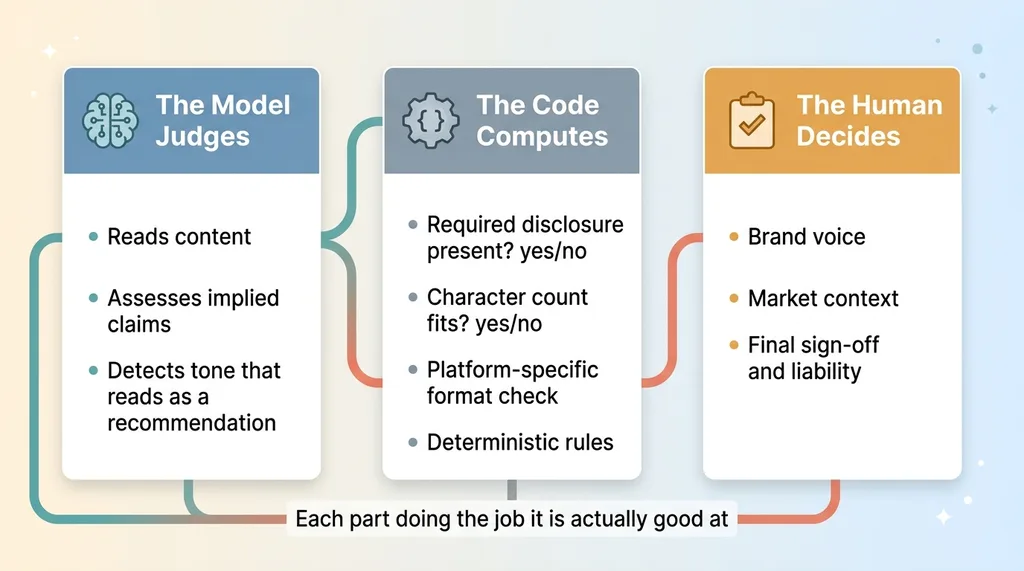 Model judges, code computes, human decides division of labor
Model judges, code computes, human decides division of labor
- Prohibited claims, performance guarantees, "risk-free", anything implying assured returns, cherry-picked historical numbers without context.
- Required disclosures per platform, different platforms need different disclosure language, and some need it in a specific format.
- Tone limits, no language that could read as a recommendation to a general audience.
- Firm-specific bans, phrasings their compliance officer had flagged in the past.
The principle underneath this is one I apply everywhere: let the model judge, let the code compute. The model reads the content and assesses whether a claim is being implied. The code enforces the hard rules, the required disclosure either exists or it doesn't, the character count either fits or it doesn't. You don't ask an LLM to be deterministic about things that should be deterministic.
How Auto-Regeneration Against the Specific Rule Works
This is the part most people get wrong, and it's the part that makes the whole system practical instead of just a fancier rejection stamp.
When a piece fails the gate, it doesn't just get thrown out. The system identifies the specific rule it violated. Not "this failed." Something precise: "implied guaranteed return on line 2" or "missing required disclosure for this platform."
Feeding the exact failure back into the model
Then it regenerates the piece with that exact feedback injected into the prompt. Not a vague "try again." A targeted instruction: rewrite this, remove the prohibited claim on line 2, keep everything else intact, here's the disclosure that needs to be present.
The difference between vague self-correction and grounded regeneration is enormous. If you tell a model "this had a compliance problem, fix it," you get a coin flip. It might fix the real issue, it might rewrite something that was fine, it might introduce a new problem.
If you tell it "you implied a guaranteed return in this exact sentence, rephrase that sentence to remove the implication, leave the rest alone," it fixes the actual thing. The regeneration has to be grounded in the specific named rule or it doesn't reliably work.
I learned this the hard way on my own content pipeline before I ever applied it to a regulated client. Vague feedback produces vague fixes.
Capping the retry loop
The retry loop has a cap. Three attempts. After that, the system stops trying.
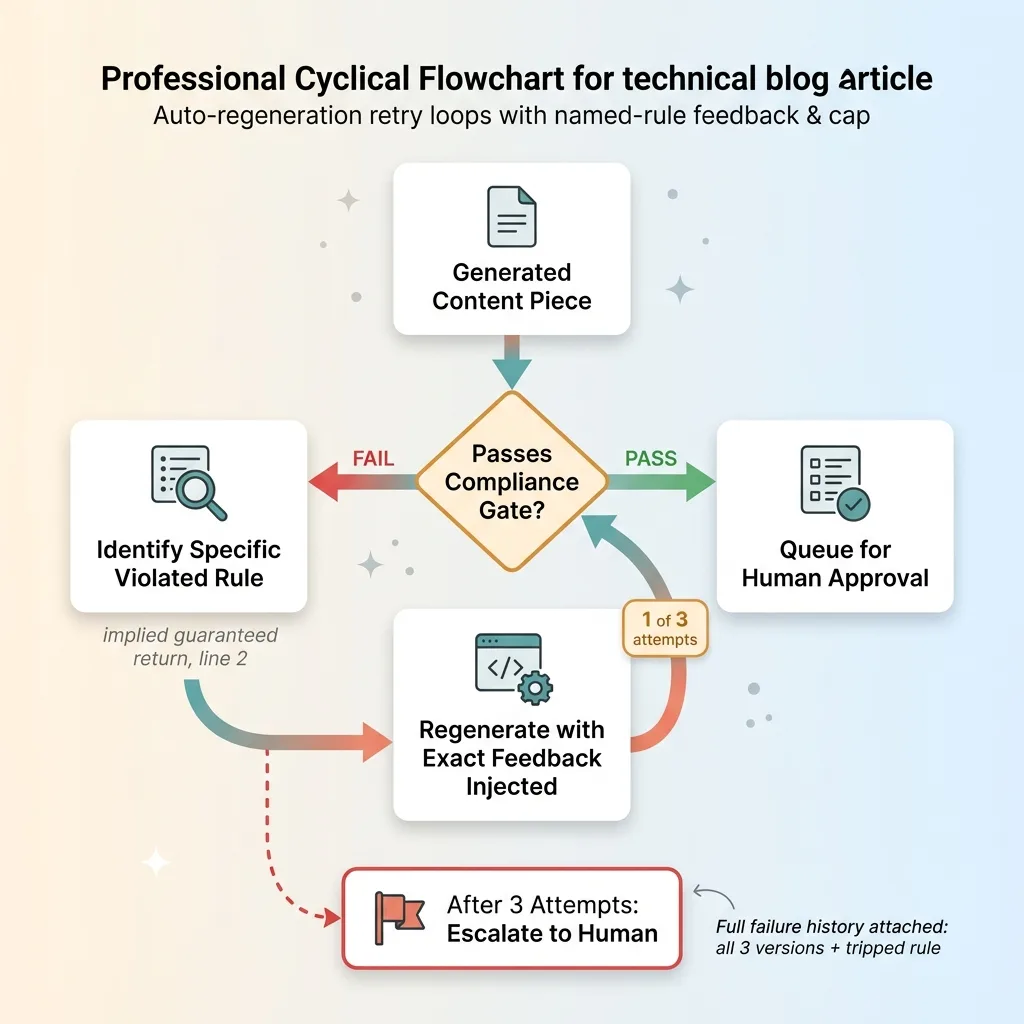 Auto-regeneration retry loop with named-rule feedback and cap
Auto-regeneration retry loop with named-rule feedback and cap
This matters for two reasons. One, an uncapped loop will burn tokens forever on a piece that can't be salvaged. Two, if a piece fails three targeted regenerations, that's a signal. The content idea itself probably has a structural problem the model can't fix by rephrasing.
After the cap, it escalates to a human with the full failure history attached. The human sees what was attempted, which rule kept tripping, and all three versions.
I'll be honest: some pieces never get salvaged automatically. That's fine. That's exactly what the human escalation is for. The goal was never 100% automation. The goal was to handle the 90% that's mechanical so the human only spends time on the 10% that needs judgment.
The Append-Only Audit Trail That Makes It Defensible
Having clean AI content is one thing. Surviving an examination is another. The difference is the audit trail.
Every approval gets stamped with a tracking number and written to an append-only log. That log is never deleted, never edited. This is what turns "we use AI for content" into "we can prove exactly what we published, why it was compliant, and who signed off."
What gets stamped on every approval
The log records, for every single piece:
 Append-only audit trail record fields
Append-only audit trail record fields
- Which piece it was, full content as published.
- Which rules it passed in the gate.
- How many regeneration attempts it took to get clean.
- Who approved it, the actual licensed advisor.
- When they approved it, timestamped.
- The final platform destination.
In a FINRA context, this is the record the firm needs. If a regulator asks "who approved this post and on what basis," the answer is a tracking number that pulls up the entire history. Not a vague "our compliance process reviewed it."
Why nothing is ever deleted
Append-only is the whole point. An editable log is worthless as evidence. If you can change the record after the fact, a regulator has no reason to trust any of it. The value of the ai content audit trail comes entirely from the fact that it can't be quietly altered.
There's a second benefit that the advisors care about more than the firm does. The advisors are experts, not marketers. They're nervous about putting their name on content. The append-only log protects them. Every piece they approved has a clean paper trail showing it passed the rules before they ever saw it. If a question comes up later, the record has their back, not just the firm's.
Where the Human Still Has to Approve
Let me be clear about what this is not. This is not full automation, and it shouldn't be.
The gate clears the obvious stuff and the rule-based violations. But a human advisor still gives final sign-off on every piece before it publishes. No exceptions.
Why keep the human? A few reasons the rules can't cover.
There are judgment calls the rule set can't encode. Brand voice. Whether a piece, while technically compliant, lands the wrong way given current market conditions. Context the model simply can't see, like a client situation the advisor knows about and the system doesn't.
And the plain fact of it: liability lives with a licensed human. You cannot offload regulatory responsibility onto a model. The advisor's name is on it, so the advisor approves it.
This is the pattern in every AI system I ship, it stops for a human. The win isn't removing the person. The win is making their job small and high-leverage instead of large and error-prone.
Before this system, an advisor reviewing a week of multi-platform content was wading through dozens of posts looking for problems. Now they're glancing at a handful of pre-cleared pieces and making a yes-or-no call. Same accountability, a fraction of the time, far less risk of fatigue-driven mistakes.
And in a multi-advisor setup, each advisor only ever approves their own content. The gate handles the per-platform disclosure differences automatically, so nobody's manually tracking which platform needs which disclaimer.
What This Looks Like Across Platforms and Advisors
Back to the original ask: one-click weekly content across multiple platforms for multiple non-marketer experts. Here's the full flow, start to finish.
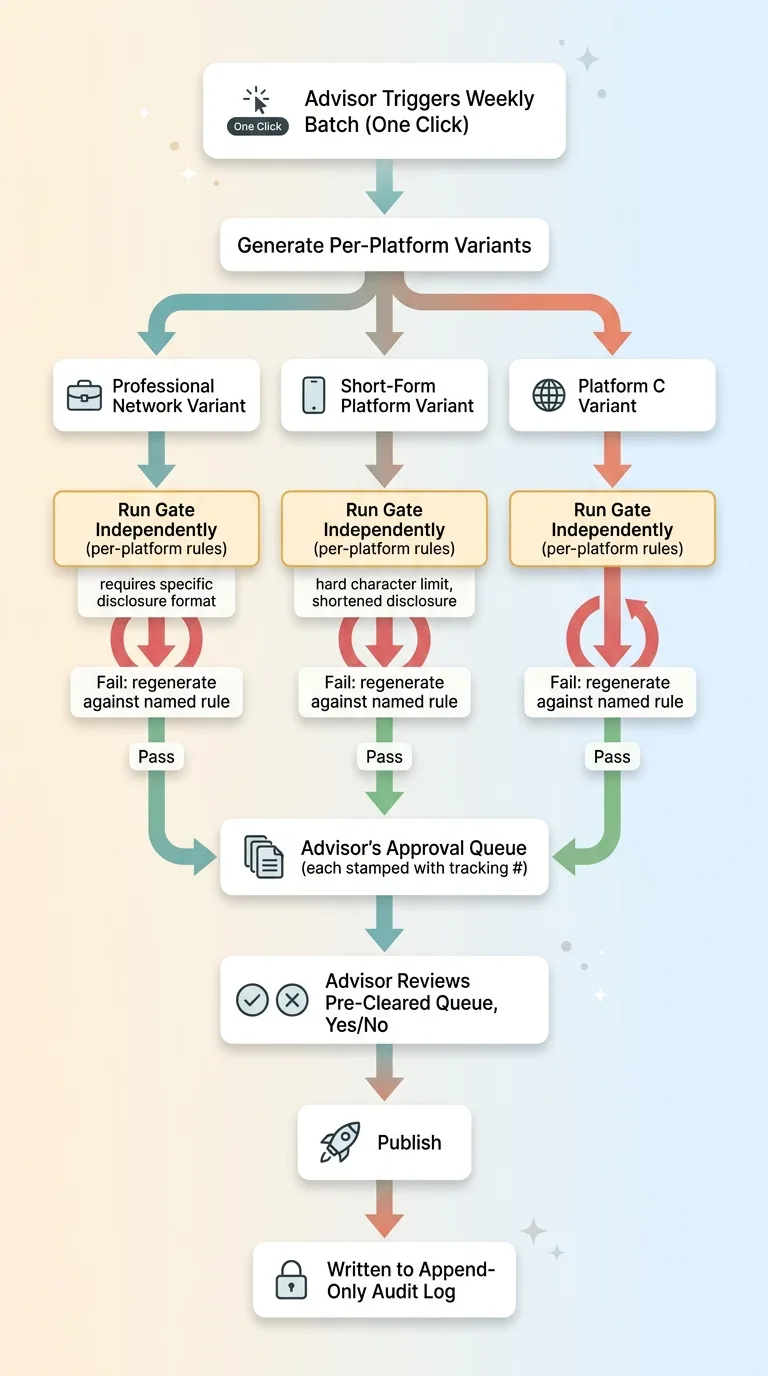 Full multi-platform multi-advisor one-click weekly content flow
Full multi-platform multi-advisor one-click weekly content flow
An advisor triggers a weekly batch. One action. The system generates per-platform variants of each content idea, because what works on a professional network isn't what works on a short-form platform.
Each variant runs the gate independently. This is where per-platform rules matter. One platform requires a specific disclosure in a specific format. Another has a hard character limit that forces the disclosure to be handled differently, maybe a shortened version or a link. The gate knows the difference and checks each variant against its own platform's rule set.
Failures regenerate against their specific named rule. Survivors land in that advisor's approval queue, each stamped with a tracking number. The advisor reviews their pre-cleared queue, approves, and approved pieces publish and get written to the append-only log.
The practical outcome is the thing the firm actually wanted. The experts get to be experts. They're financial advisors, not compliance officers and not marketers. They push a button, glance at clean content, approve it, and move on with their day.
Meanwhile the firm gets genuine multi-platform reach across all its advisors without a single bad post becoming a liability. The volume scales. The risk doesn't.
That's the trade I'm always chasing in regulated social media automation: more output, not more exposure.
Automating Content in a Regulated Industry Without the Liability
So here's the question every regulated buyer asks me, stated plainly: how do you automate content when one bad post creates real liability?
The answer is structural, not aspirational. The compliance gate content pipeline puts the check in the middle, not at the end. Failures self-correct against the specific named rule that tripped them. Everything that ships carries a defensible, append-only audit trail.
The model does the volume. The rules do the enforcement. The human does the judgment. Each part doing the job it's actually good at.
This isn't a content trick. It's the pattern I build into every regulated client system, whether it's content, document processing, or client communications. The compliance logic lives in code, the judgment stays with a licensed human, and the record survives an examination.
If you're sitting on a content backlog because every post has to go through legal review, your bottleneck isn't your people. It's the architecture. You've got smart, busy experts rubber-stamping stacks of posts, and that's both slow and risky.
I'd rather see what your actual rules look like. Tell me what your rule set looks like, the prohibited claims, the required disclosures, the firm-specific bans, and I can tell you fairly quickly whether this pattern fits. Start here.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call