Migrating Off a 3PL: The Data Cleanup Nobody Warns You About
Migrating off 3PL data cleanup isn't done when the load finishes. How I triaged 1,046 unsynced inventory rows without creating a new incident.
By Mike Hodgen
The Migration Isn't Done When the Data Loads
A while back I moved fulfillment off a 3PL for my DTC fashion brand here in San Diego. Part of that meant bulk-loading inventory during the cutover. The load ran. It "succeeded." Green checkmark, no errors, on to the next thing.
Weeks later, the real story showed up.
Of 1,781 inventory rows I'd loaded, 1,046 had never produced a single sync event. Not one. That means for more than half my catalog, the storefront and the warehouse could silently disagree about what was actually in stock, and nobody would get an alert. No flag, no error log, nothing. Just two numbers drifting apart in the dark.
That's the whole problem with migrating off a 3PL. The data cleanup nobody warns you about isn't the load. The load is the easy part. Reconciliation is the long tail, and it's where the damage actually lives.
If you've never thought hard about which number is true when your storefront and your warehouse disagree, start here: who is right about your stock, the shelf or the storefront. Because that disagreement is exactly what 1,046 unverified rows sets you up for.
Here's the fear I hear constantly from founders bringing fulfillment in-house: they know there's a mess waiting on the other side of the migration, they just can't see its shape yet. They've heard the horror stories. Phantom stockouts. Overselling SKUs they didn't actually have. Customers ordering things that don't exist.
That fear is correct. The mistake is treating it as a one-time event instead of a phase.
The data load gives you rows in a table. It does not give you confidence that those rows match reality. Those are two completely different things, and the gap between them is where I spent most of my time on this cutover.
Why 1,046 Rows of Silence Is Worse Than 1,046 Errors
A row that never synced has no opinion
A row that has never emitted a sync event isn't wrong. It's unverified. There's a difference, and it matters more than it sounds.
When two systems sync, they leave a trail: this number on the storefront was checked against this number in the warehouse at this time, and here's what happened. A row with no sync event has none of that. The system has no record that the storefront count and the physical count were ever reconciled. It has no opinion. It's just sitting there, loaded, assumed correct because nothing has contradicted it yet.
Silence reads as success
That's what makes silence more dangerous than errors. Errors get noticed. An error throws a flag, lands in a log, pages someone. Silence does the opposite. It reads as success right up until a customer orders something you can't ship.
 Errors versus silent rows, why silence reads as success
Errors versus silent rows, why silence reads as success
I've written before about why silence is not success. A system that never tells you it's healthy isn't healthy by default. It's just quiet. And quiet is exactly how a migration looks the moment before it bites you.
Here's the trap most people fall into next. They find the 1,046 silent rows and their instinct is to mass-correct everything. Run one big UPDATE, push the storefront numbers to the warehouse, call it clean.
That's how you turn a quiet problem into a loud incident.
Because most of those rows were already correct. If I'd blindly overwritten all 1,046, I'd have stomped on the ones that matched perfectly and manufactured real drift where none existed. The cure would have been worse than the disease. The whole point of making two systems agree on inventory is that you don't get to agreement by guessing in bulk.
The Triage: Three Buckets, Not One Mass Update
So I didn't run one update. I sorted the 1,046 silent rows into three buckets and treated each one completely differently. This is the part nobody tells you about, and it's where the actual work is.
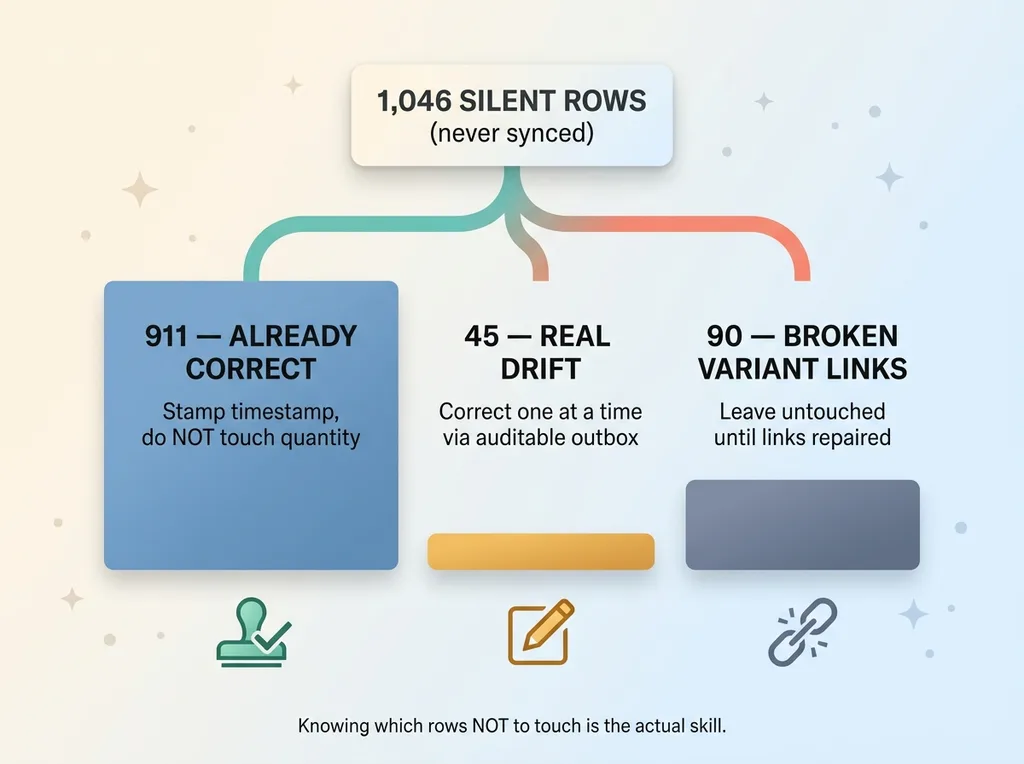 The 1,046 silent rows breakdown into three triage buckets
The 1,046 silent rows breakdown into three triage buckets
911 already correct: stamp, don't touch
The biggest bucket by far. 911 rows where the storefront quantity and the warehouse quantity already matched. They weren't wrong at all. They were just unverified, which is why they showed up as silent.
These needed a sync timestamp stamped on them so the system would stop treating them as unreconciled. No quantity change. Not a single unit moved. The data was right; the system just didn't know it was right yet. Stamping these is the difference between "we think this is correct" and "we confirmed this is correct on this date."
If I'd touched the quantities on these 911 rows, I'd have created the exact problem I was trying to solve.
45 with real drift: correct through the outbox
The middle bucket. 45 rows with genuine residual drift, mostly single-unit discrepancies left over from the handoff off the 3PL. This is classic inventory cutover residue: the storefront said 4, the shelf had 3, and somewhere in the transfer the difference fell through a crack.
These got corrected one at a time, through an auditable outbox, so every change was logged with a reason and fully reversible. More on that pattern in a second. The key point: 45 corrections, not 1,046. The drift was real but tiny, and isolating it from the noise is the entire game.
90 with broken variant links: leave them alone
The bucket people get wrong. 90 rows where a missing variant link meant the row pointed at nothing coherent. The inventory record existed, but the thing it was supposed to be attached to didn't resolve cleanly.
Correcting the quantity on these would have been pure guessing. You can't reconcile a number against a product you can't reliably identify. So I deliberately left all 90 untouched until the variant links were repaired. Fixing the quantity first would have just locked in a wrong answer against a broken reference.
The discipline lesson buried in all of this: knowing which rows not to touch is the actual skill. Anyone can run an UPDATE. The judgment is in the restraint.
The Auditable Outbox: Why Every Correction Got Logged
For those 45 drift corrections, I didn't write the new quantities directly into the inventory table. Every change went through an outbox first.
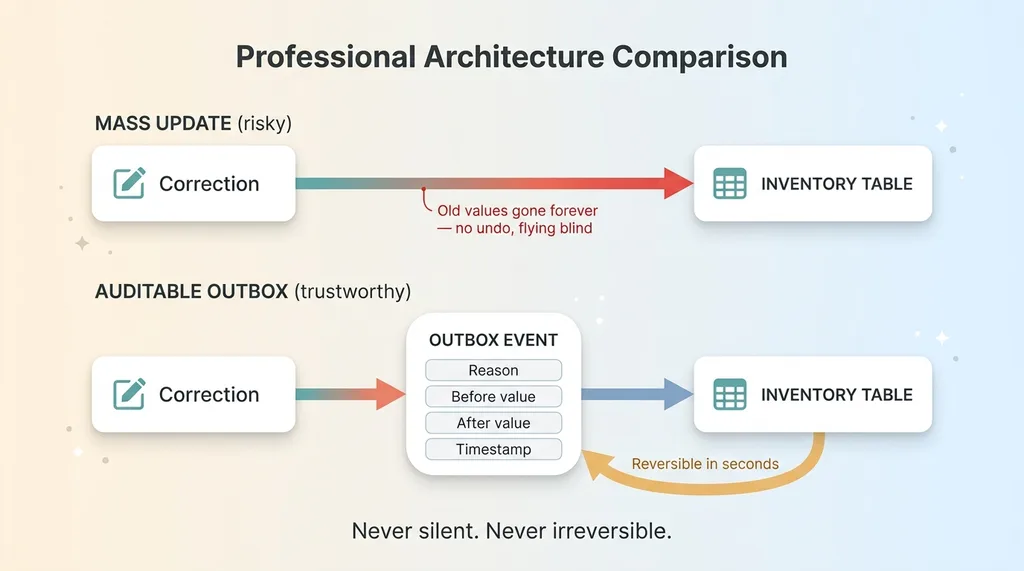 Auditable outbox versus mass UPDATE
Auditable outbox versus mass UPDATE
In plain terms: instead of mutating inventory in place, each correction became a recorded event. A reason for the change. The before value. The after value. A timestamp. Then the event applied the change. The inventory got fixed, but now there was a permanent record of what it used to be and why it moved.
Here's why that matters. If one of those 45 corrections turned out to be wrong, I could see exactly what happened and reverse it in seconds. Before value is right there. I'm not reconstructing history from memory or hoping I remembered the original number.
Now contrast that with the mass-UPDATE approach. You change a thousand rows in one statement. It works. But the moment it's done, the old values are gone. If something's off, you have no idea what those rows were before you touched them. You're flying blind on your own correction.
That's the difference between a migration you can trust and one you just hope worked.
I apply the same rule to anything that moves money or stock: it should never be silent and it should never be irreversible. If a system is going to change a number that affects whether a customer gets their order, I want a log of it and I want an undo button. The outbox gives me both. For 45 rows it took longer than a bulk update. It also meant I could sleep.
The Spot-Check Page: Let a Human Verify Before Any Bulk Action
Before I stamped those 911 "already correct" rows, I built a spot-check page.
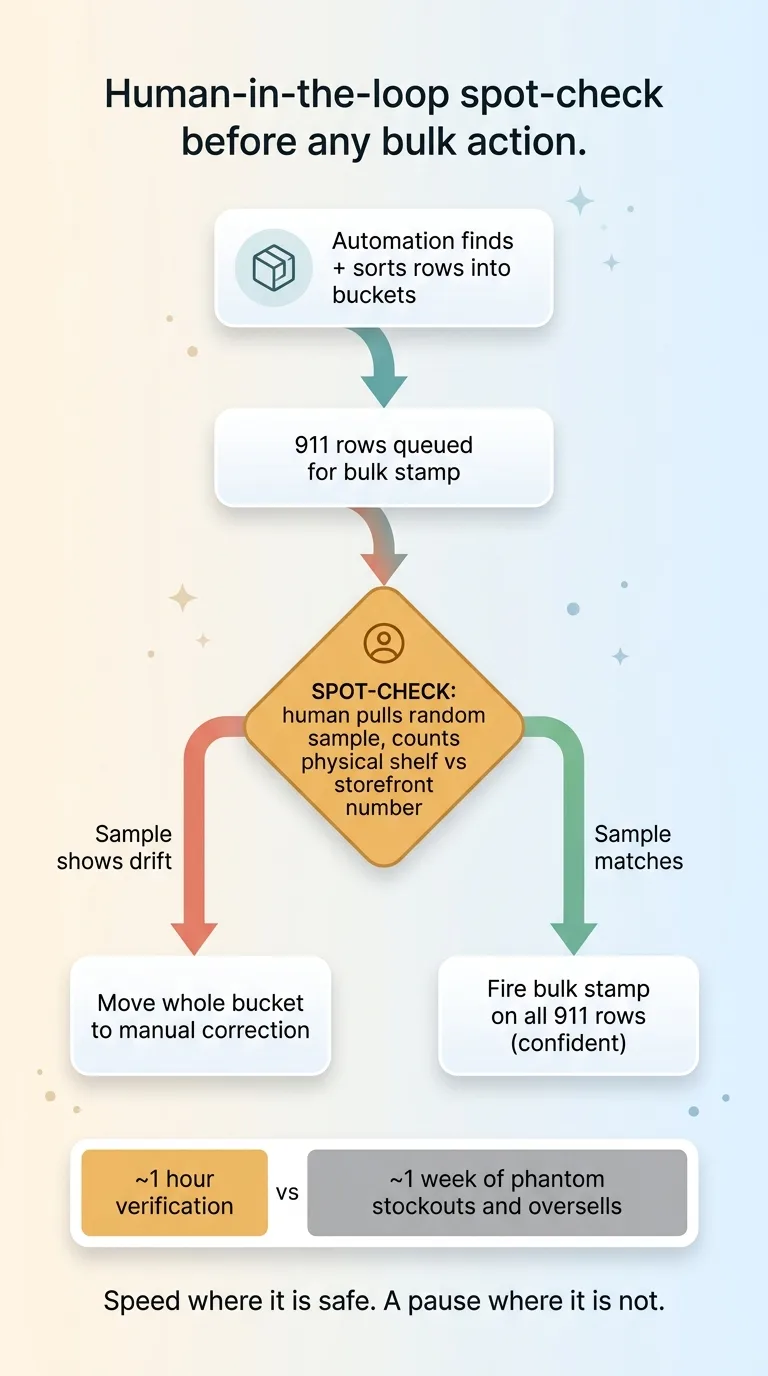 Human-in-the-loop spot-check before any bulk action
Human-in-the-loop spot-check before any bulk action
The idea is simple. Before any bulk stamp or correction ran, an operator could pull up a random sample of the affected rows and physically confirm the storefront number matched what was actually on the shelf. Walk to the rack, count the units, compare. Real eyes on real product.
That human-in-the-loop checkpoint is what made it safe to stamp 911 rows at once. I wasn't asserting those rows were correct on faith. I was sampling enough of them, by hand, to be confident the bucket as a whole was sound. If the sample had shown drift, the whole bucket would have moved into the manual-correction pile instead.
The verification cost about an hour. Skipping it could have cost a week of phantom stockouts and oversells, plus the customer service mess that follows. An hour against a week is not a close call.
This is the broader long tail of leaving a 3PL: the cleanup keeps surfacing, and you need a way to check your own work before you commit to it at scale.
It also reflects how I build everything. Every system I ship stops for a human before it does anything it can't easily undo. The automation does the heavy lifting, finding the rows, sorting the buckets, applying the stamps. But the decision to fire a bulk action waits for someone to look. Speed where it's safe, a pause where it isn't.
A Repeatable Playbook for Post-Migration Reconciliation
If you're moving off a 3PL or running any inventory cutover, here's the framework I'd hand you. It's the same one I ran on my own brand.
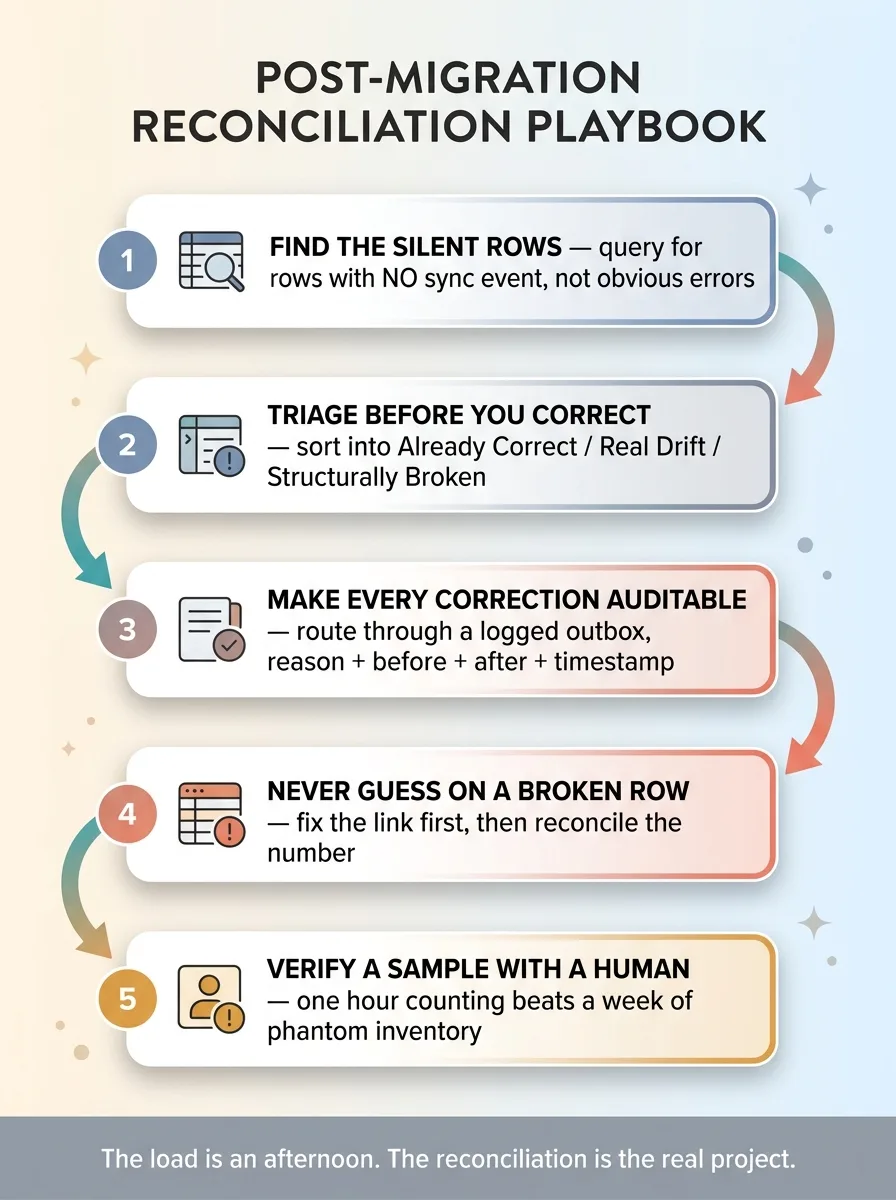 The repeatable post-migration reconciliation playbook
The repeatable post-migration reconciliation playbook
Find the rows that never synced
Don't query for obvious errors. Query for rows with no sync event. The visible errors will get caught anyway, that's what makes them errors. The silent rows are the ones that loaded "successfully" and never got verified against anything. Those are the ones that hurt you later.
Triage before you correct
Sort the silent rows into three buckets:
- Already correct. Storefront and warehouse match. These need a timestamp, not a quantity change.
- Real drift. Genuine discrepancies, usually small, left over from the handoff. These need correction.
- Structurally broken. Missing links or references that point at nothing coherent. These need a structural fix first, not a number.
Skip the triage and you'll overwrite the good rows to fix the bad ones.
Make every correction auditable and reversible
Route real-drift corrections through a logged outbox. Reason, before value, after value, timestamp. If a correction is wrong, you want to see it and undo it. Never run a bulk UPDATE that erases the original values. The record of what a number used to be is worth more than the convenience of changing it fast.
Never guess on a broken row
A structurally broken row does not get a quantity guess. Fix the link, the reference, the mapping first. Then reconcile the number against something real. Guessing here just locks a wrong answer into a broken structure.
Verify a sample with a human before bulk action
Before any mass stamp or correction, have a person confirm a sample against physical reality. An hour of counting beats a week of phantom inventory.
One honest note: this whole process took longer than the original bulk load did. By a lot. That's the part people underestimate. The load is an afternoon. The reconciliation is the real project.
Bringing Fulfillment In-House Without the Data Becoming a Liability
If you're a founder weighing whether to leave your 3PL, here's the straight version.
The data mess is real. You will end up with cutover residue, silent rows, and discrepancies that don't show up until a customer hits one. That part is not avoidable. What is avoidable is getting burned by it.
The brands that get hurt are the ones who treat the data load as the finish line. The load runs, it's green, they move on. The residue surfaces weeks later as oversells and angry support tickets, and by then they've lost the thread on what actually changed.
The brands that come through clean treat reconciliation as a first-class phase. They find the silent rows. They triage instead of mass-correcting. They log every change so it's reversible. They put a human in front of any bulk action. It's not glamorous, and it takes longer than anyone wants. It also works.
I've run this cutover on a real brand with real customers and real inventory on real shelves. Not from a deck. When I tell you the 911-row stamp and the 90 untouched rows mattered, it's because I lived the version where getting that wrong costs you a week.
If you're thinking about bringing fulfillment in-house without breaking the data, this is exactly the kind of work I do hands-on. Not advising from a slide. Sitting in the actual cutover with you, deciding which rows to touch and which to leave alone.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call