AI Agent Memory: What Broke and How I Fixed It
AI agent memory is more brittle than it looks. Here's how a dead API and a redundant memory layer scrambled my assistant's recall, and the fix that worked.
By Mike Hodgen
How an AI assistant actually 'remembers' you
Here's the thing most people get wrong about AI agent memory: the model doesn't remember you at all.
When you talk to an AI assistant and it seems to recall your name, your projects, your preferences from last week, that's not the model "remembering." Large language models are stateless. Every conversation starts from zero. The model has no idea who you are until something feeds it that information at the start of the exchange.
Context window vs. real memory
The context window is the model's short-term working space. It's everything you've said in the current conversation, plus whatever instructions you loaded up front. When the conversation ends, that window closes and the contents are gone. Start a new chat tomorrow and the model is a blank slate again.
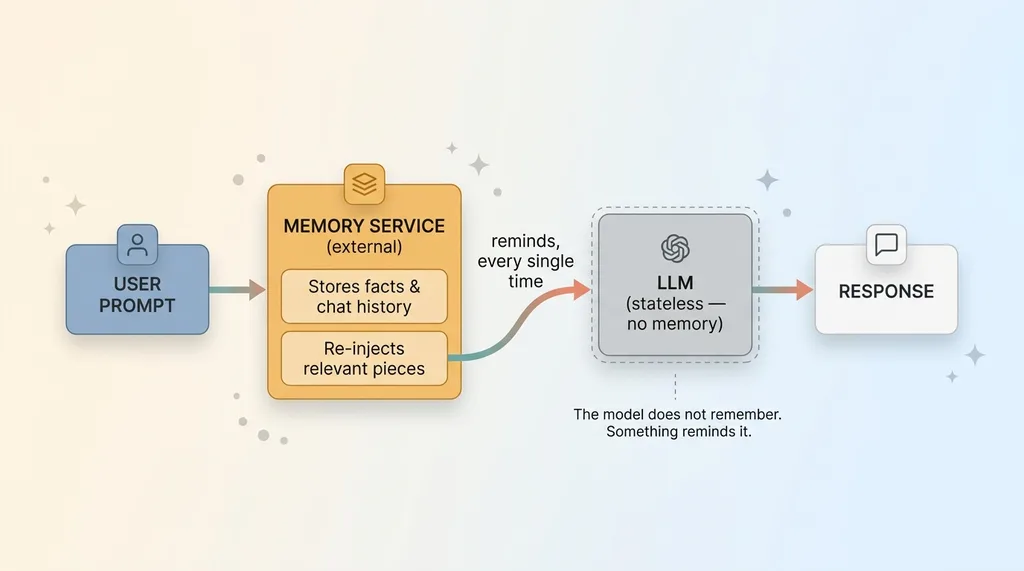 How AI memory actually works (stateless model + external memory service)
How AI memory actually works (stateless model + external memory service)
Real memory is a completely separate system. It's a service that sits outside the model, stores facts and conversation history, and then re-injects the relevant pieces into the next prompt before the model ever sees your question. The model isn't remembering. Something is reminding it, every single time, in the background.
What persistent memory looks like under the hood
Persistent agent memory usually comes in two flavors.
The first is raw chat-history storage: the back-and-forth message pairs of what you said and what the assistant said. When you start a new session, the system pulls the relevant past turns and pastes them back in.
The second is entity memory: structured facts about people, projects, and preferences. Not "here's the whole conversation" but "Mike runs a DTC fashion brand, prefers short answers, is working on a pricing engine." Cleaner, more durable, easier to query.
I learned all of this the hard way. I built an AI assistant for my own use, similar in spirit to an AI executive assistant that triages 200 emails a day, and the memory layer turned out to be its own moving part with its own failure modes. It wasn't a feature of the model. It was infrastructure. And infrastructure breaks.
The mistake I made: two memory systems doing one job
When I first built the assistant, I made a classic over-engineering mistake. I bolted on two memory products from two different vendors.
Call them the agent-memory service and a second memory product. At the time, each one looked like it did something the other didn't. One was better at storing conversation history. The other had a cleaner approach to structured entity facts. So I wired up both, figuring more memory infrastructure meant a smarter, more reliable assistant.
It felt harmless. It even felt responsible, like I was building in redundancy.
It was the opposite of responsible.
What I'd actually built was two sources of truth. Two integrations to maintain. Two places where the agent's recollection could quietly drift out of sync with each other. When the assistant recalled a fact, which system was it pulling from? When I updated something, did both systems get the update, or just one?
Redundant infrastructure isn't a safety net. It's a second thing that can break, and now you have to figure out which one broke.
This runs against everything I've learned building 15+ AI systems across my brand. My instinct now is ruthless consolidation. Fewer vendors, fewer integrations, fewer handoffs between systems. Every extra moving part is a place where things drift, fail silently, or cost you a debugging session at 11pm.
The build-vs-buy decision isn't just "should I build this or buy it." It's "how many things am I now responsible for keeping alive." Two memory vendors meant two API contracts I didn't control, two deprecation schedules I had to track, two sets of credentials, two billing relationships. For one job. Remembering things.
I'd talked myself into complexity because each piece looked useful in isolation. The system as a whole was worse for it.
When the vendor killed the API out from under me
The first real failure didn't come from my code. It came from a vendor.
A dead v2 sessions endpoint
The agent-memory service deprecated its v2 sessions API. One day it worked. The next day the endpoint was dead.
My assistant lost the ability to read and write conversation sessions overnight. Here's the dangerous part: there was no loud crash. To a casual user, the assistant still answered questions. It still responded fluently. It just stopped remembering recent context properly. The recall quietly degraded, and nothing in the interface screamed "your memory layer is down."
I only caught it because I use this thing every day and noticed it had gotten weirdly forgetful.
Why long-running assistants are exposed to this
This is the part buyers need to internalize. Long-running AI assistants are uniquely exposed to vendor API churn because they depend on the same external service every single day, for months.
 Loud failure vs silent failure
Loud failure vs silent failure
A one-off script can ride out a deprecation. You run it, it works, you move on. If the API changes six months later, who cares, you already got your output.
A daily-use assistant doesn't have that luxury. It's a standing dependency. Every API your assistant relies on is a promise that someone else's roadmap won't break your system. And vendor roadmaps change constantly. Endpoints get deprecated. v2 becomes v3. Pricing models shift. Companies get acquired.
The longer your assistant lives, the more deprecation cycles it has to survive.
This is exactly why I design kill-switches into every system I build. Not because I expect the AI to go rogue, but because I expect dependencies to fail. The question isn't whether a vendor will break something. It's whether your system degrades loudly, where you'll catch it, or silently, where it'll erode trust for weeks before you notice.
Mine degraded silently. That's the failure mode I hate most.
The scrambled-recall bug: chat pairs stored in the wrong order
The second failure was subtler and, honestly, more unsettling.
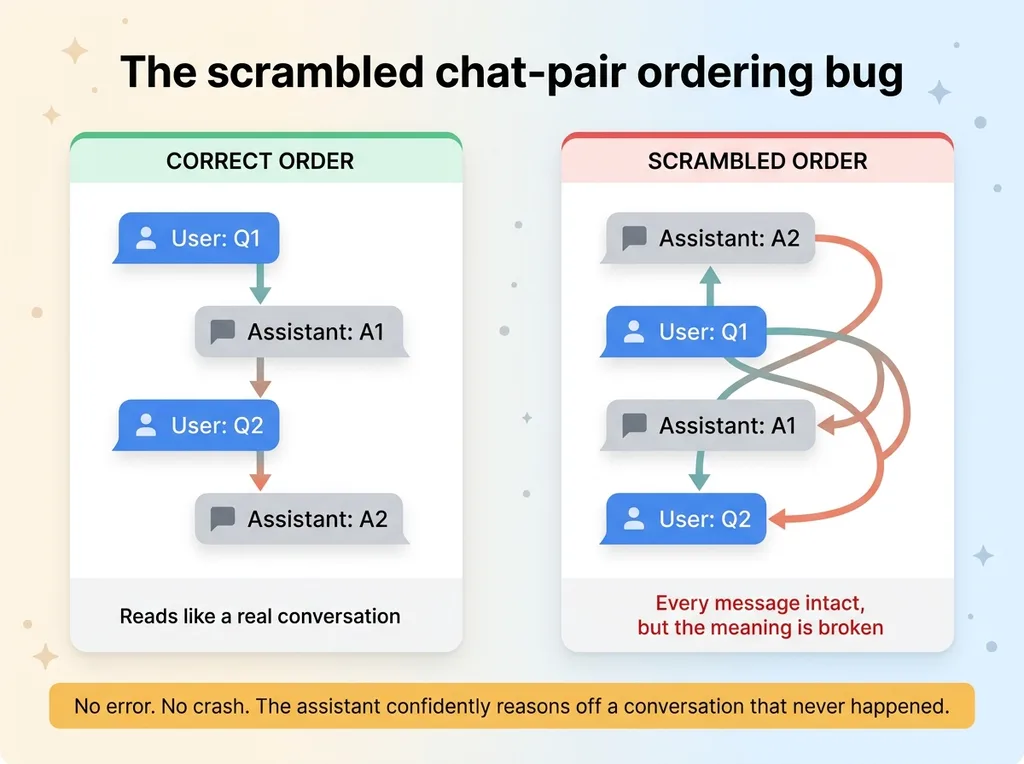 The scrambled chat-pair ordering bug
The scrambled chat-pair ordering bug
The agent's recall got scrambled. Not because memory was missing. The memory was all there. The problem was that the chat-history message pairs were being stored in the wrong order.
Here's what that means in practice. A conversation is a sequence: you ask something, the assistant answers, you follow up, it answers again. The order is the meaning. If you shuffle those turns, you get a conversation that reads like nonsense, even though every individual message is intact.
When the memory layer re-injected past conversation into a new prompt, the user and assistant turns came back jumbled. The model was reading a transcript of a conversation that never actually happened in that sequence. So it "remembered" things in an order that made no sense, and confidently reasoned off that broken history.
This is the worst kind of bug, and it's a recurring theme in everything I build: the worst failures are the silent ones that look like success.
A crash is honest. A crash tells you something is wrong. You see the error, you trace it, you fix it. Everyone knows the system is down.
A correctness bug like this looks like the system is working. Memory exists. Recall fires. The assistant responds with confidence. But the content is subtly, dangerously wrong. There's no error message. There's no red flag. Just an assistant that's quietly making decisions based on a garbled version of the past.
If you're trusting an AI assistant to remember commitments, preferences, or the state of a project, a scrambled-order bug means it's not just forgetting. It's confidently misremembering. And it'll never tell you it's doing it.
That's the bug I'd lose sleep over if a client were depending on it before I caught it in my own use.
The fix: consolidate to one memory system and migrate to v3
The fix was the opposite of how I built it. Instead of two systems patched together, I consolidated to one.
Moving to the v3 entity-memory API
The dead v2 sessions API had a successor: the vendor's v3 entity-memory API. The important part was that v3 now covered the entity-memory job that my second memory product had been doing. The capability gap that justified two vendors in the first place had closed.
So I migrated the whole memory layer to v3. One service. One API contract. One source of truth.
Dropping the redundant second product
Then I dropped the second memory product entirely.
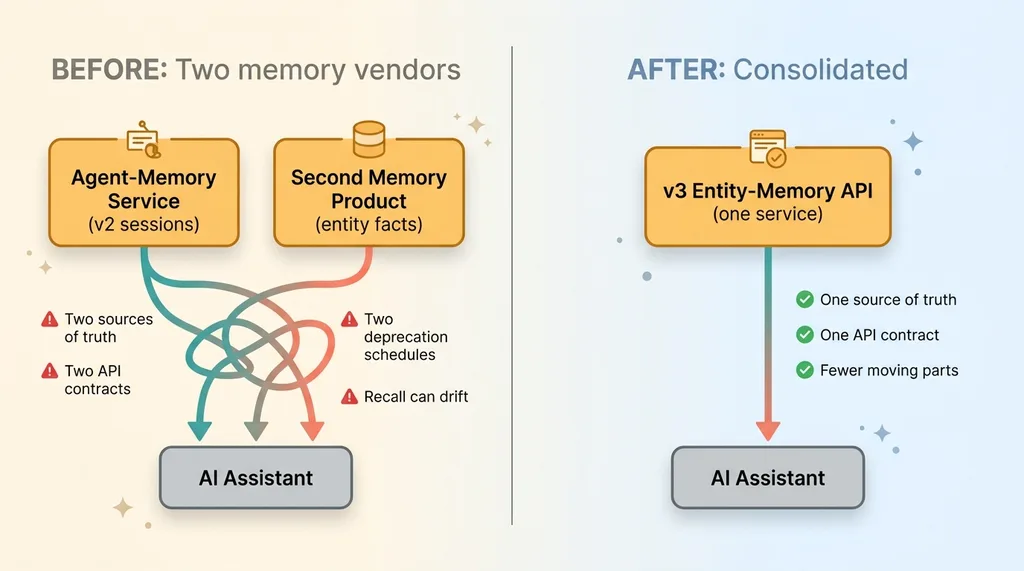 Two memory systems vs one consolidated memory (before/after)
Two memory systems vs one consolidated memory (before/after)
This is consolidation in its purest form. Fewer moving parts. Fewer integrations to maintain. Fewer places for the agent's recollection to drift. One vendor relationship instead of two. One deprecation schedule to watch instead of two.
I also fixed the message-pair ordering so chat history reads back in the actual sequence it happened. No more phantom conversations.
I won't pretend the agent memory migration was free. It wasn't.
I had to re-map stored memory from the old structure to the new one, which is never a clean one-to-one. I had to validate that recall was actually correct, not just present, which meant manually checking that the assistant remembered the right things in the right order. And I had to accept some history loss. Not everything migrated cleanly, and at some point you stop trying to rescue every old record and just move forward.
That's the honest reality of agent memory migration. It's not a config change. It's a careful data move with validation at every step, and a tolerance for losing some of the past to get the present right.
I wrote up the full technical version of this story, including the specific vendors and the migration details, in the full migration writeup if you want the deep version.
The end state was simpler and more reliable than what I started with. That's almost always the sign you've made the right call.
What this means if you're betting on long-running AI assistants
If you're considering an AI assistant that needs to remember things across sessions, here's what my mess should teach you.
Memory is infrastructure, not a feature
Persistent memory is its own infrastructure layer with its own failure modes. It's not a checkbox on the model. It's a separate service that stores, retrieves, and re-injects information, and it can fail in ways that have nothing to do with how good the model is.
Treat it like infrastructure. Because it is. The model is the easy part. The memory layer is where the brittleness lives.
Questions to ask before you build
Before you build or buy an AI assistant that has to remember anything, ask these:
 Four questions to ask before building a memory-dependent AI assistant
Four questions to ask before building a memory-dependent AI assistant
- Where does memory actually live? If the answer is vague, that's a problem. You need to know what service holds your facts and history.
- How many vendors are in the loop? Every additional memory vendor is another API contract you don't control and another deprecation schedule you have to survive. Minimize the count.
- How do you validate that recall is correct, not just present? "The assistant remembers things" is not good enough. Wrong-order recall and drifted facts both look like success. You need a way to check correctness.
- What happens when the vendor deprecates an API? Because they will. If you can't answer this, you're one roadmap change away from a silently broken assistant.
Vendor API churn is a real operating risk for anything you depend on daily. And silent correctness bugs are worse than crashes, because they erode trust without ever alerting you. Those two facts should shape every decision you make about memory architecture.
Why I'd rather find these problems than hand you a demo
I build these systems for my own use first. That's not a marketing line. It's the reason I find the memory-layer landmines before a client ever steps on one.
A polished demo hides brittleness. You can make any AI assistant look brilliant for ten minutes in a controlled environment. The model is sharp, the recall is fresh, everything works. That demo tells you almost nothing about what happens after six months of daily use, three vendor deprecations, and a thousand stored conversations.
Running something daily for months is what surfaces the real problems. The dead v2 endpoint. The scrambled chat pairs. The two-vendor mess I created for myself. None of that shows up in a demo. All of it shows up in production.
So when a client asks me about building a long-running AI assistant, I'm not speaking from theory. I've already paid the tuition. I know that the memory architecture decision matters more than the model choice, because the model is interchangeable and the memory layer is where you'll live or die.
If you're thinking about an AI assistant, or any system that has to remember things across sessions, that's the conversation worth having before you write a line of code. I help companies make these calls and build the systems that survive contact with real use, not just the demo.
If that's where you are, talk to me about your AI roadmap.
Thinking about AI for your business?
If this resonated, let's have a conversation. I do free 30-minute discovery calls where we look at your operations and find where AI could actually move the needle, not where it just looks good in a demo.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call