Secrets Manager Migration: My 58-Project Order
How I ran a secrets manager migration across 58 projects without breaking production: tool choice, naming standard, and a rotate-as-you-go order.
By Mike Hodgen
The same key was living in 14 repos under 12 names
I run a lot of projects. My DTC fashion brand, the internal tools that keep it running, a stack of client systems, a few things I built just to solve my own problems. When I finally sat down to audit how secrets were stored across all of it, I found 76 .env files spread across 58 projects.
That number isn't the scary part. The scary part is what was inside them.
The same provider API key appeared in 14 different repos. And it wasn't even called the same thing. In one repo it was OPENAI_KEY. In another, OPENAI_API_KEY. In a third, LLM_KEY. Same value, five different spellings, scattered across projects that had no idea they were sharing a credential.
When I mapped out my own secret sprawl, the real problem became obvious: I had no central control. When a key needed rotating, I genuinely could not tell you how many places it lived. If one of those repos leaked, I couldn't contain it, because I didn't know its blast radius.
That's the actual failure. Not exposure. The inability to answer a simple question: where does this credential live, and what happens if it gets out.
So I fixed it. And the fix has three parts.
First, a secrets manager migration to a single source of truth, so every credential has exactly one home. Second, one scoped service token per project-and-environment, so a leak in one place can't read another's secrets. Third, a migration order that rotates every key as it imports it, so the move itself closes existing exposure instead of just relocating it.
This article is the playbook. The naming standard, the tool decision, the five-step order, and the per-repo template that stops the sprawl from coming back. Everything I ran on my own projects before I'd take it near a client.
Why reuse, not exposure, is the actual risk
Most people think the nightmare is a single .env file leaking. One file, one repo, one bad day.
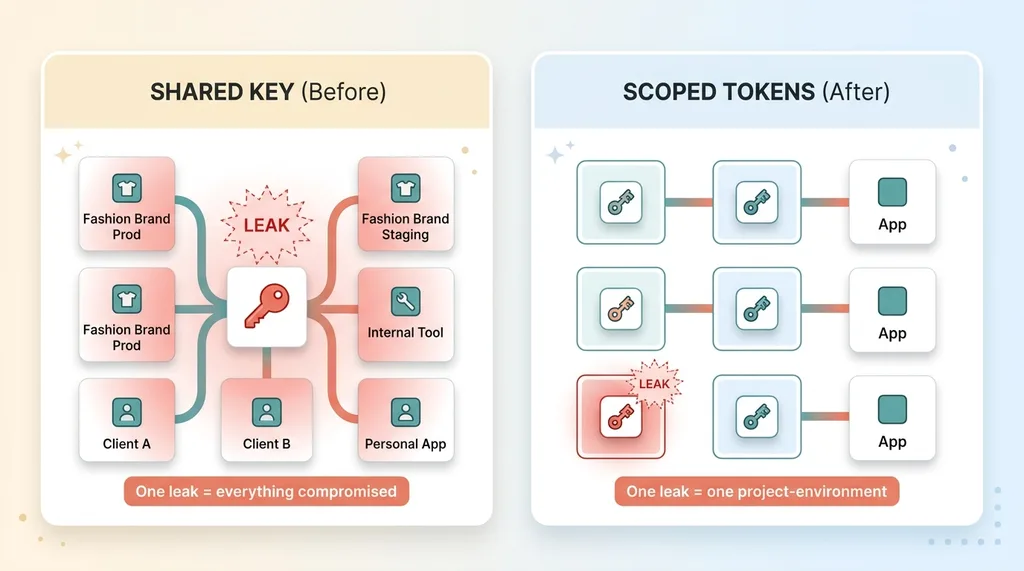 Blast radius: shared key vs scoped tokens
Blast radius: shared key vs scoped tokens
That's not the nightmare. The nightmare is reuse.
When one credential powers six different apps, a single leak doesn't compromise one app. It compromises everything that key touches. And here's the part that makes it worse: you can't restrict it per-app after the fact. The damage is already shared by design.
I wrote about this when I realized one key powering six apps is the vulnerability. A shared key has no boundaries. It works everywhere or nowhere. So when it leaks, your only option is to rotate it and break every single app that used it at the same time.
This is where scoped tokens change everything.
The concept is blast radius. If every project-environment has its own scoped service token, a leak in one place can read only that one place's secrets. The token for my fashion brand's production environment can't touch my staging environment, let alone a client's project. The damage is contained to exactly one scope.
Here's the inversion the nervous buyer needs to hear. If you're a CEO who's been burned before, your instinct is that a migration like this creates new risk. You're moving every secret you have. What if something breaks?
The opposite is true. The migration is what shrinks the blast radius. Before, one leak meant everything. After, one leak means one project-environment, contained by a token that can't reach anything else.
The reuse was the vulnerability the whole time. The migration is how you kill it.
The tool decision: why I landed on Doppler
I evaluated a handful of options before committing. Here's what mattered and what I rejected.
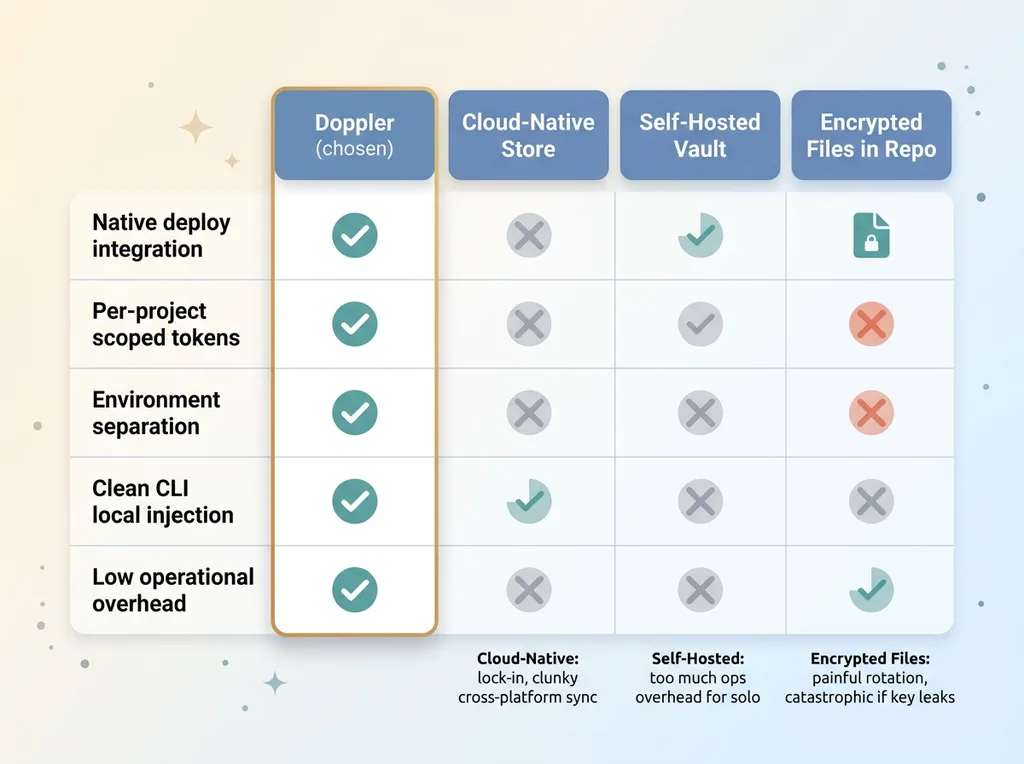 Tool decision matrix: requirements vs rejected options
Tool decision matrix: requirements vs rejected options
What I needed
Four requirements, non-negotiable.
Native deploy integration. I did not want to manually paste env vars into a hosting dashboard ever again. The secrets manager had to sync directly to the host so the deploy platform pulls values automatically.
Per-project scoped service tokens. This is the blast-radius requirement from the last section. Every project-environment needed its own token out of the box, not something I'd have to bolt on.
Environment separation. Clean dev, staging, and prod boundaries inside each project, so production secrets and staging secrets never mix.
A clean CLI for local injection. I wanted local development to pull secrets from the manager at runtime, with no .env file sitting on my laptop waiting to get committed by accident.
Doppler hit all four without me fighting it. The native integrations with deploy platforms and the per-project scoped tokens are exactly what I needed, and they're standard, not a paid add-on tier.
Runners-up I rejected and why
A cloud-provider native secrets store. Rejected for lock-in and clunky cross-platform sync. My projects don't all live on one cloud, and stitching a single provider's secrets store across multiple hosting platforms was more friction than it was worth.
A self-hosted open-source vault. Powerful, genuinely good at scale. Rejected because I'm not going to run and patch and back up a secrets server for a solo operation. That's operational overhead I refuse to own.
Committing encrypted files to the repo. Rejected because rotation is painful and a leaked decrypt key is catastrophic. One compromised master key and every encrypted secret in your history is readable.
I'll be honest: the right answer depends on your scale. A large engineering org with a dedicated platform team might genuinely want the self-hosted vault. For my situation, and for most companies in the $1M to $50M range, Doppler setup was the cleanest path to a single source of truth.
A naming standard so one service has exactly one name
The five-spelling mess wasn't an accident. It was the predictable result of having no standard. So before I migrated anything, I wrote one.
The rules
The core rule is simple: one service gets exactly one name across every project. The provider key that was OPENAI_KEY, OPENAI_API_KEY, and LLM_KEY collapses to a single canonical name everywhere it appears.
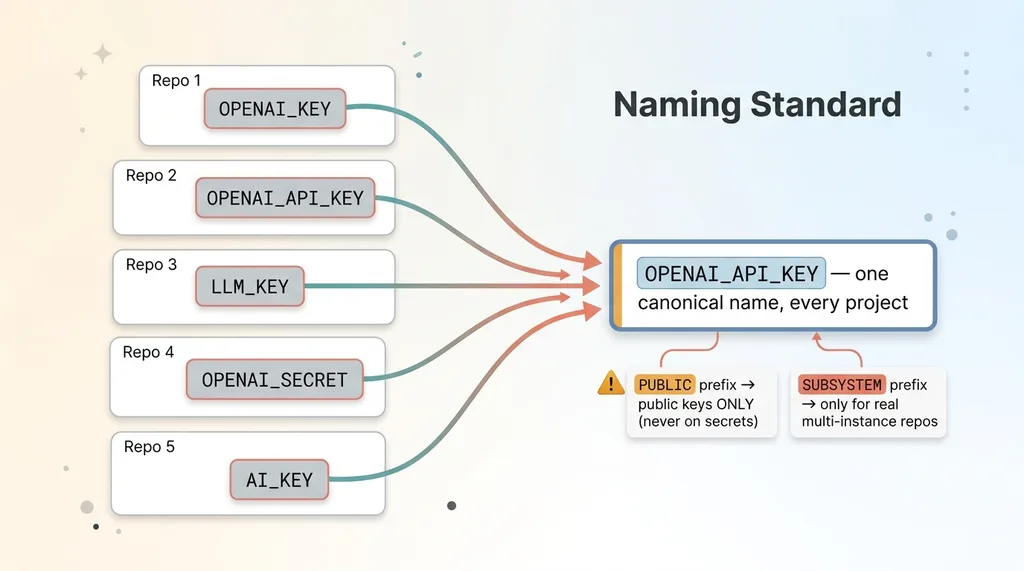 Naming standard: many names collapse to one canonical name
Naming standard: many names collapse to one canonical name
This sounds trivial. It is not. It's the difference between rotating a key in one place and hunting through 14 repos hoping you caught them all.
Public prefixes and subsystem prefixes
Two refinements that prevent real disasters.
Public prefixes only on truly public keys. Frameworks use a public-exposure prefix (the kind that bundles a value into the browser) to mark values safe for the client. The rule is absolute: that prefix goes on public keys only, never on secrets. A misnamed secret carrying a public prefix is exactly how a server-side API key ends up shipped inside a browser bundle for the whole world to read.
Subsystem prefixes only for legitimate multi-instance repos. If a repo genuinely talks to two instances of the same service, you prefix to distinguish them. Otherwise, no prefix. The default is the clean canonical name.
To execute the rename safely, I wrote an idempotent rename script. It made 31 edits across 8 repos, and every change was dry-run-verified before a single byte was written. The script reported exactly what it would change, I reviewed it, and only then did it run for real.
The reason I built it that way: a rename that breaks a build silently is worse than the sprawl it's fixing. Dry-run-first means the cleanup couldn't introduce a new outage.
The five-step migration order that rotates as it goes
This is the part most people get wrong, and it's the part that actually matters. The order isn't just logistics. It's a security operation.
Rotate on import
Here's the assumption I started from: if a key has been living in 14 repos under 12 names with no central control, it has probably already leaked somewhere. I don't know where. That's the whole problem.
I learned to assume leakage the hard way when I found nine of my databases were readable by anyone with the URL. Once you've seen how quietly exposure happens, you stop trusting that any existing value is clean.
So the first step is not to import the old value. It's to rotate every credential at the source as you import it. Generate a fresh key from the provider, and that fresh value is what goes into the secrets manager. The old value gets revoked.
This is why the order matters so much. A migration that just relocates your existing keys moves the exposure with them. Rotate-on-import closes the existing exposure. The migration itself becomes the fix, not a lateral move.
Load once, wire the sync, then delete
The full five-step order:
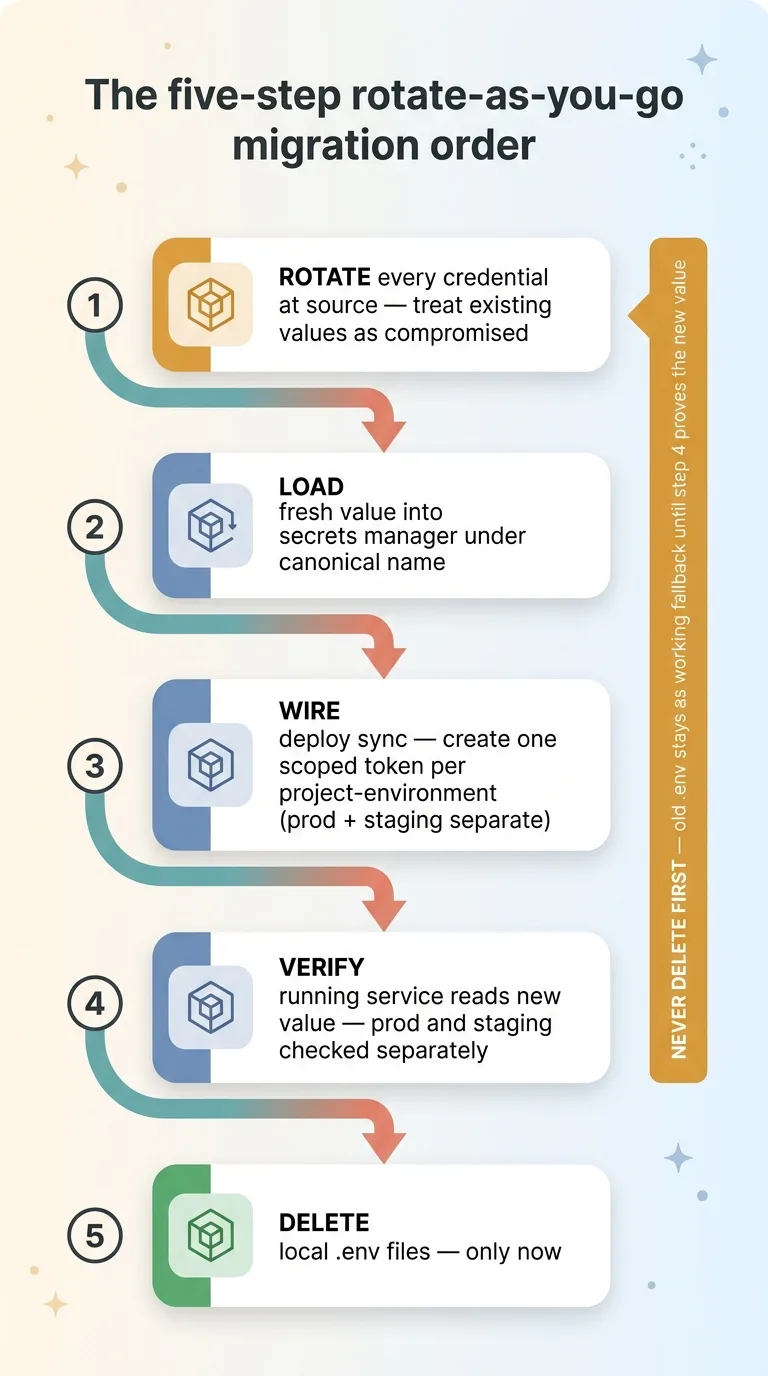 The five-step rotate-as-you-go migration order
The five-step rotate-as-you-go migration order
- Rotate every credential at the source as you import it. Treat every existing value as potentially compromised.
- Load the freshly rotated value into the secrets manager once, under its canonical name from the naming standard.
- Wire the deploy sync so the host pulls from the manager automatically. This is where you create the scoped service token, one per project-environment, so prod and staging each get their own isolated token.
- Verify the running service reads the new value. Production and staging separately. Watch the actual app come up clean on the new credential before you trust it.
- Only then delete the local .env files.
The rule that holds the whole thing together: never delete first.
You always keep a working source until the new one is proven. The old .env file stays on disk until step 4 confirms the running service reads the rotated value from the manager. If something's wrong, you still have a working fallback and zero downtime.
I ran this across all 58 projects. The order never changed. Rotate, load, wire, verify, delete. Every credential got a fresh value, every project-environment got its own scoped token, and not one production service went dark during the move.
That's the payload. The migration that shrinks your blast radius while closing the exposure you already had.
The per-repo config template that makes new projects safe by default
Here's the uncomfortable truth about how I got into this mess: the sprawl came from hand-provisioning every project.
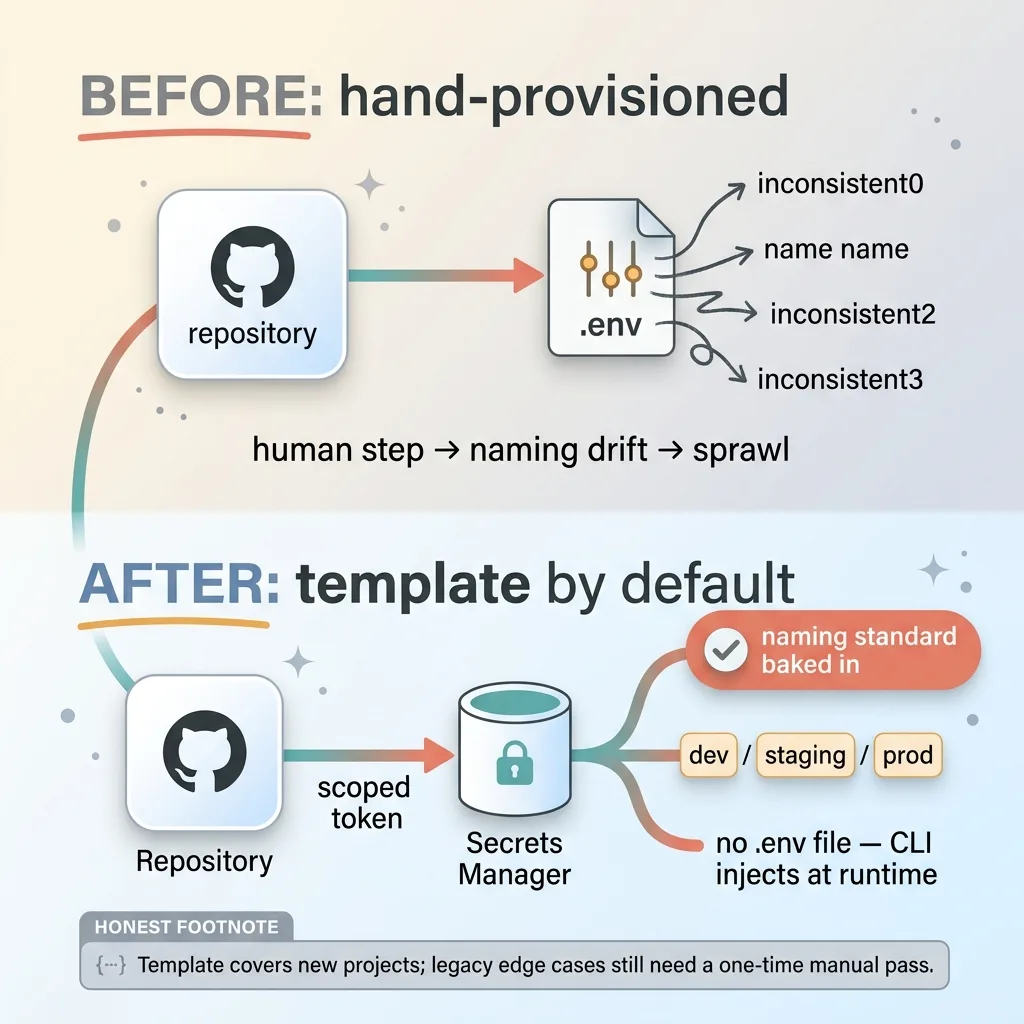 Per-repo template that prevents future sprawl
Per-repo template that prevents future sprawl
Each new repo, I'd set up secrets manually. New .env file, copy some values over, name them whatever felt right that day. Multiply that by 58 projects over a few years and you get 12 names for one key.
The human step is what created the drift. So I removed the human step.
I built a per-repo config template. Every new project now starts wired to the secrets manager with its own scoped token, the correct environment mapping for dev, staging, and prod, and the naming standard baked in from line one. There's no decision to get wrong because there's no decision to make.
Local development injects secrets from the manager through the CLI at runtime. That means there's no .env file sitting in the project to lose, commit, or leak. The values live in the manager, period.
I'll be honest about the limit here. The template makes new projects safe by default, but it doesn't automatically fix legacy edge cases. The weird old repo with a half-broken config, the project that talks to a service nobody documented. Those still need a one-time manual pass.
But going forward, the drift can't reappear, because nobody is hand-naming anything anymore.
What this looks like when someone else owns the sprawl
If you're running a company and reading this, you probably already know your secrets are scattered. The .env files, the shared keys, the credential nobody's rotated in two years because nobody knows what would break.
And your real fear isn't the mess. It's the fix. You're worried the migration breaks production.
Here's why it doesn't. The rotate-as-you-go order means you always have a working source. You never delete the old path until you've watched the running service read the new one. Prod and staging verified separately, fallback intact the whole way. The migration is reversible at every step until the moment it's proven.
I don't take this near a client until I've run it on my own work first. I ran a security audit across my whole workspace and migrated all 58 of my own projects before I'd offer it to anyone else. The playbook is battle-tested on systems I personally depend on.
If your secrets live in scattered files under inconsistent names, and nobody on your team can answer how many places a single key lives, that's not a quarter-long project. That's a weekend of focused work to fix permanently. Single source of truth, scoped tokens per project-environment, every key rotated on the way in, and a template so it never drifts again.
The hard part isn't the tooling. It's the order and the discipline. That's the part I bring.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call