Secrets Management: I Mapped 76 .env Files of Sprawl
A scan of 76 .env files found one key in 14 projects. Here's how I mapped my secrets management blast radius and fixed it without printing a single value.
By Mike Hodgen
The number that doesn't matter, and the one that does
I scanned my portfolio of projects last month and found 76 .env files. Seventy-six separate files holding secrets management for everything I run: my DTC fashion brand, a dozen internal tools, the experiments that never shipped.
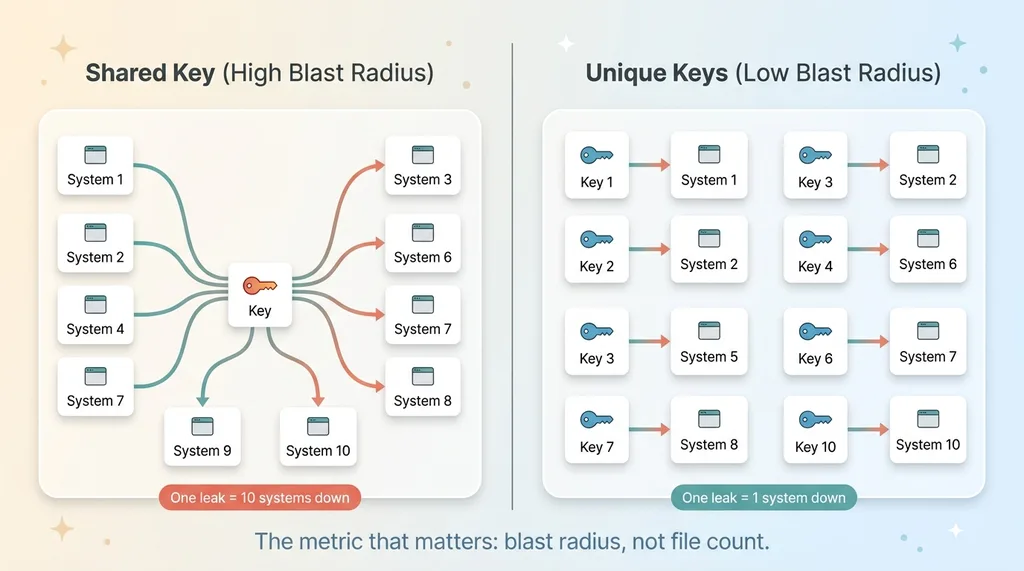 Blast radius: shared key vs unique keys
Blast radius: shared key vs unique keys
That number made me wince. It also doesn't matter.
The file count is a distraction. You can have a thousand .env files and be perfectly safe, or ten files and be one paste away from a disaster. The thing that actually determines your risk is not how many files exist. It's how far a single secret has spread.
Here's the reframe that changed how I think about this. A thousand .env files, each holding a unique key that powers exactly one system, is far safer than ten files all sharing the same key. In the first case, a leak burns one thing. In the second, one leaked credential takes down ten systems at once.
That's the real metric: blast radius. Not "how many files," but "if this one value leaks, how many separate systems die with it."
I didn't want to guess at the answer. So I built a scanner to measure it precisely across my own projects. No clients here, this is all mine, which means I can show you the actual numbers without anonymizing anything.
The results were worse than I expected in some places and better in others. One credential lived in 14 separate projects. A live payments key spanned six different businesses.
I'll walk through the whole scan, what it found, and the two-move fix that actually collapses the risk instead of just relocating it. Let's start with why this happens to everyone who moves fast.
Why secret sprawl happens (and why nobody notices)
Secret sprawl isn't a discipline failure. It's a structural one. If you don't have a central place to provision secrets, every project gets its keys by hand. And hand-provisioning has a predictable failure mode.
No central provisioning means hand-copying
You spin up project number nine. It needs to send email. You already have a working email API key sitting in project number three, so you copy it, paste it into the new .env, and move on. It works. You ship.
Multiply that across every key a project needs (email, payments, an LLM, a database) and across every new project you start. The same value ends up scattered across a dozen repos. Nobody decided to do this. It's just the path of least resistance when there's no single source to pull from.
This is exactly what speed costs. I move fast, I build a lot, and the tax for that is accumulated secret debt. The key doesn't expire when I forget where I put it. It just sits in repos waiting.
Different variable names hide the same value
Here's the part that makes it nearly impossible to catch by eye. The same credential lives in different repos under different variable names.
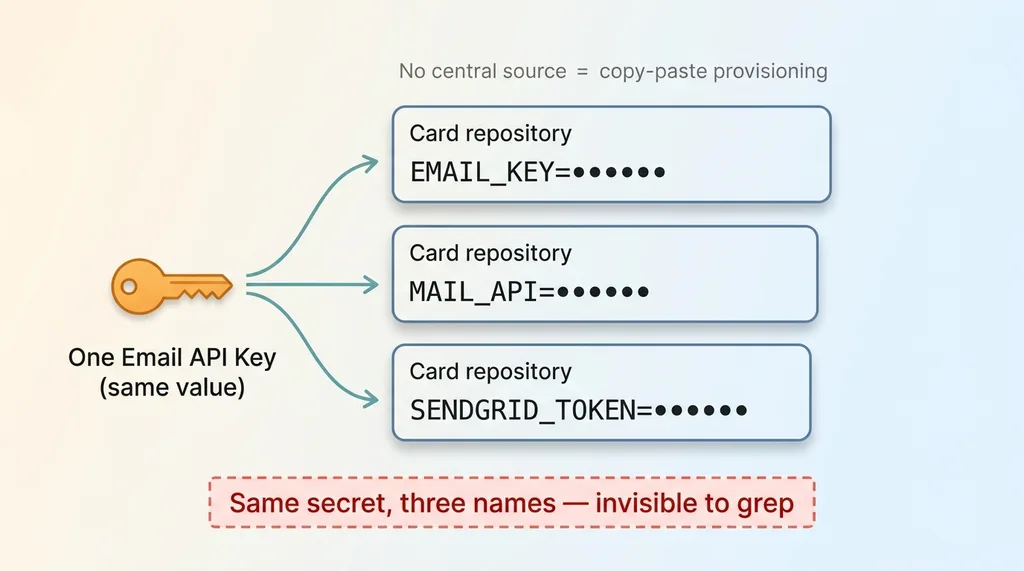 How secret sprawl happens via hand-copying and alias names
How secret sprawl happens via hand-copying and alias names
In one project it's EMAIL_KEY. In another it's MAIL_API. In a third someone named it SENDGRID_TOKEN. Same secret, three names.
So even a careful grep across your codebases won't find the connection. You search for the variable name and miss every repo that called it something else. The sprawl is invisible to the obvious tools, which is why most teams genuinely don't know their number. They've never had a way to measure it.
env file security breaks down here not because anyone was careless, but because the thing you'd need to track (the value, not the name) is the one thing you should never go looking at directly.
I built a scanner that fingerprints secrets without ever printing them
The hard constraint with any secrets management audit is obvious once you say it out loud: you cannot dump secret values into a report. A report full of your live API keys is itself a leak. So the scanner had to answer "which secrets are shared" without ever displaying a single secret.
Hash, never display
The trick is hashing. For every value the scanner finds in an .env file, it computes a one-way hash fingerprint and stores that, never the raw value. The hash is deterministic, so the same secret always produces the same fingerprint.
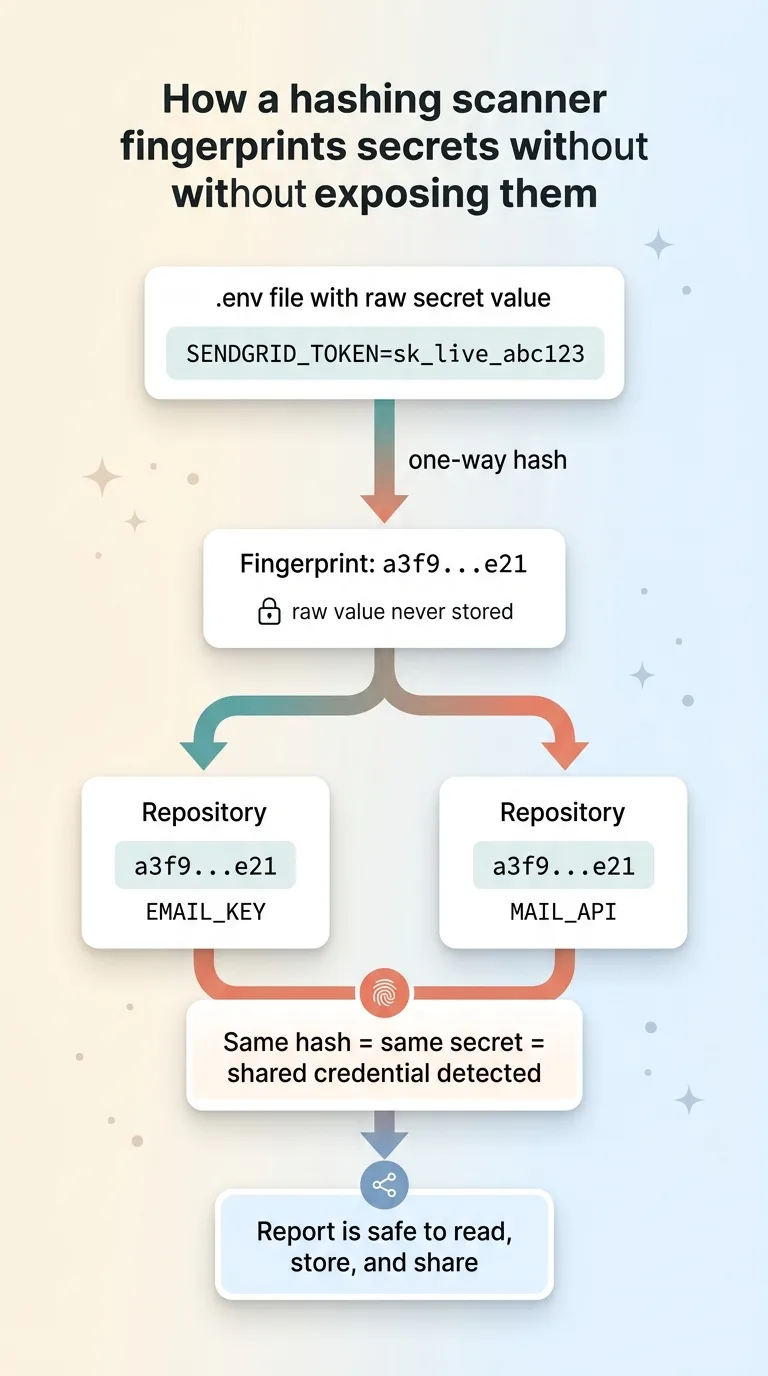 How the hashing scanner fingerprints secrets without exposing them
How the hashing scanner fingerprints secrets without exposing them
Same hash in two repos means same secret in two repos. I learn that two projects share a credential without the scanner ever knowing or showing what that credential is. The report is safe to read, safe to store, safe to share with a team.
It also sidesteps the variable-name problem completely. EMAIL_KEY and MAIL_API and SENDGRID_TOKEN all hash to the same fingerprint if they hold the same value. The naming chaos becomes irrelevant.
Computing blast radius per secret
Once every value is fingerprinted, the rest is counting. The scanner tracks:
- Distinct values: how many genuinely unique secrets exist across the portfolio
- Total occurrences: how many times any secret appears anywhere
- Variable-name aliases: every name a given fingerprint hides behind
- Reused values: any fingerprint that shows up in more than one project
That last category is the whole point. For each reused secret, the scanner produces a blast-radius map: a list of exactly which projects die if that one value leaks.
This is the difference between knowing you have a problem and knowing precisely how bad each problem is. "I have secret sprawl" is a vague worry. "If this one email key leaks, these 14 named projects can be impersonated to my customers" is a work ticket with a priority attached.
The scanner took an afternoon to write. Most of that afternoon was making sure it never logged a value by accident, because a debugging print statement in the wrong place would defeat the entire purpose.
What the scan actually found
I ran it across all 76 .env files. Here's the raw output.
The headline numbers
- 76 .env files
- 1,147 total secret occurrences
- 402 distinct variable names
- 70 reused values (the same secret living in more than one project)
Read those together. 402 different variable names, but only a fraction of those represent unique secrets, because the same value hides under multiple names. And 70 of my secrets are shared across project boundaries. Seventy separate credentials where a single leak hits more than one system.
The 1,147 occurrences across 76 files tells you the surface area. Every one of those is a place a key could leak from. But the 70 reused values tell you the damage. That's the number that matters.
The three keys that scared me
The aggregate is abstract. The specifics are not.
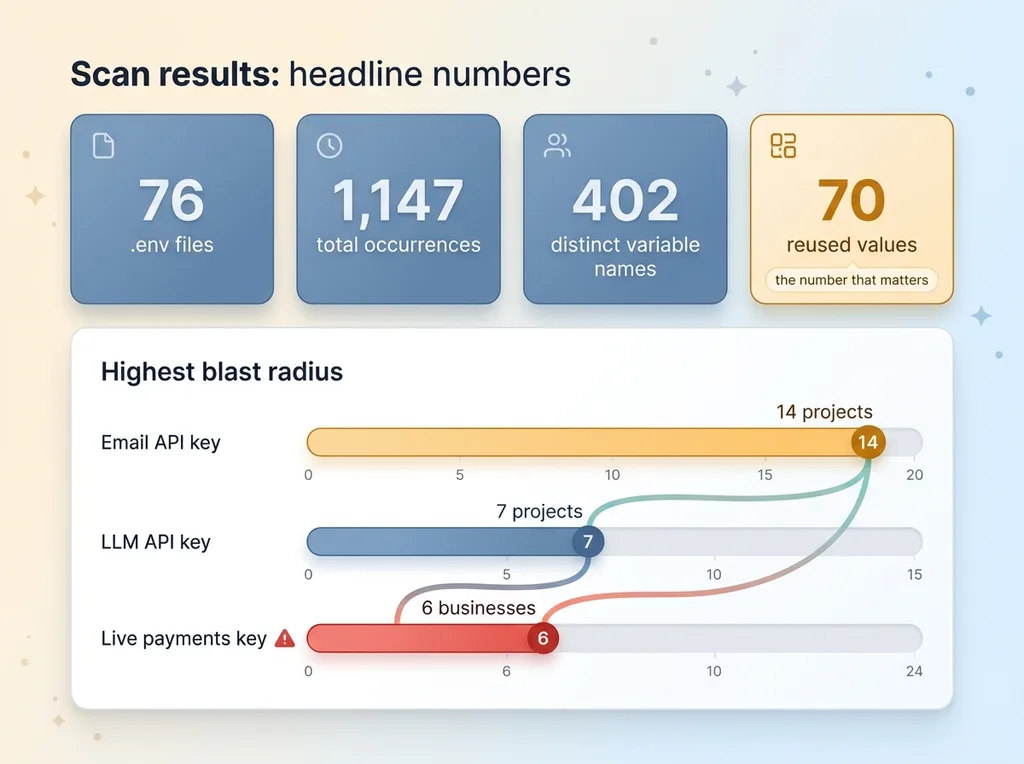 Scan results: headline numbers and the three scariest shared keys
Scan results: headline numbers and the three scariest shared keys
One email API key in 14 separate projects. Leak that single value and someone can send email as me from 14 different products. Every one of those projects can be impersonated to its customers. Fourteen blast points from one paste.
One LLM API key across 7 projects. Less catastrophic in terms of impersonation, but a leaked LLM key gets run up into the thousands of dollars fast, and it's seven systems' worth of usage all billing to the same compromised credential.
One live payments processor key across 6 different businesses. This is the one that made me close the laptop and walk around the block. A live payments key isn't test data. Leak it and six separate businesses' money is exposed at the same moment, through one credential.
On top of those, database admin credentials were crossing project boundaries too, which is a familiar flavor of mistake. I've written before about how nine of my databases were readable by anyone with the URL. A shared admin credential is the same category of risk: one exposure, many systems open at once.
If you're a CEO reading this and quietly wondering whether your team has done the same thing, the honest answer is they almost certainly have. The only question is the number, and you haven't measured it yet.
The fix is two moves, in order
The order matters more than anything. Do these out of sequence and you make the problem worse.
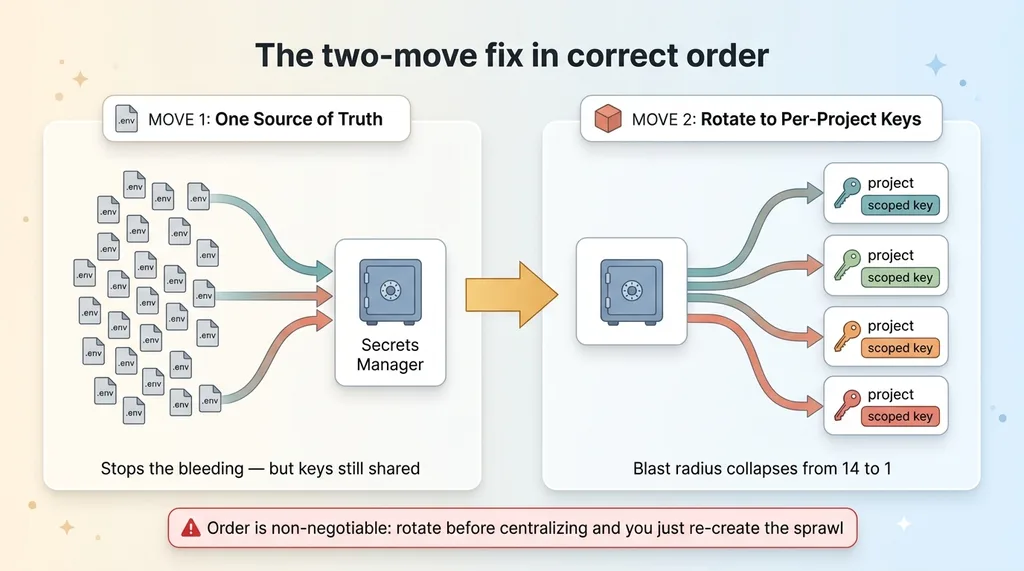 The two-move fix in correct order
The two-move fix in correct order
One source of truth first
Move one: get every secret into a single secrets manager. I use Doppler as the destination, but the principle holds for any real secrets manager. One scoped access token per repo-plus-environment, and the actual secret values live in one place instead of 76 files.
This stops the bleeding. It doesn't fix the blast radius yet, but it gives you somewhere to manage everything from, and it gets the values out of plaintext files scattered across your machine and your git history. I wrote up the full process of moving 58 projects' secrets to one source of truth if you want the mechanics.
After this move, your secrets are centralized but still shared. That email key is still the same value in 14 projects. You've changed where it lives, not how far it reaches.
Then rotate to per-project least-privilege keys
Move two is the one most teams skip. Now that you have a source of truth, you rotate the shared values into per-project, least-privilege keys.
The 14 projects sharing one email key each get their own distinct key, scoped to only what that project actually needs. Now the blast radius for any single leak collapses from 14 to one. That payments key spanning six businesses becomes six separate keys, one per business.
Here's why the order is non-negotiable. If you rotate before you have a source of truth, you just generate 14 new keys and scatter them back into 14 .env files. You've done a lot of work to recreate the exact sprawl you started with. The source of truth is what makes least-privilege keys manageable instead of being a fresh mess.
I'll be honest: move two is the slow, unglamorous part. Move one feels like progress and gives you a clean dashboard. Move two is tedious key-by-key rotation with no visible reward except that your risk quietly drops. Most teams stop after move one. The blast radius is still there. They've just organized it.
The rule that prevents this from coming back
Cleaning up is pointless if you re-sprawl in six months. So here's the rule, stated plainly:
Every new project pulls its own scoped key from the source of truth. It never inherits a copy.
Least-privilege by default. When project number 15 needs to send email, it does not borrow project number three's key. It gets a fresh key, scoped to exactly what project 15 does and nothing more. A key that powers one thing can only ever leak one thing.
Contrast that with the convenient habit: grab the key you already have, paste it in, ship. That habit is how all 70 of my reused values happened. It's faster in the moment and it's the entire source of the problem.
I won't pretend the discipline is free. Provisioning a fresh scoped key for every new project is more friction than copy-paste. But the friction is small and the payoff is that your worst-case leak stays small forever.
This isn't a one-time panic cleanup. It's a repeatable audit habit. I run this kind of check as part of a security audit across 58 codebases, and the secret-fingerprinting scan is one lens of many. It pairs with knowing how to triage alerts too, because most committed-secret alerts are noise and the skill is separating the real fan-out risk from the false positives that waste your week.
Most teams are sitting on this and don't know the number
If your team copy-pastes keys between projects, and almost every fast-moving team does, you have a blast-radius number you've never measured. You don't know it because the obvious tools can't see it. The same secret under three different variable names is invisible to grep, and nobody is going to manually diff 76 .env files.
The danger isn't really that you'll get breached. Breaches happen to everyone eventually. The danger is that one breach takes down a dozen systems instead of one, because a single leaked credential was quietly powering all of them.
The scanner took an afternoon to write. It turned a vague background worry into a prioritized list: here are your 70 reused secrets, here's the blast radius of each, here's which three to rotate first. That's the work I do across a portfolio. Find the hidden risk, quantify it precisely, then sequence the fix so you stop the bleeding before you do the slow cleanup.
If you want to know your number, I'll help you map your own secret sprawl. Not a panic audit, just a clear measurement of how far your credentials have spread and which ones to fix first.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call