AI Ground-Truth Facts: The One Thing AI Can't Get Wrong
How I keep AI from confidently saying something legally false about a business: a ground-truth facts block the model treats as non-negotiable.
By Mike Hodgen
The Sentence That Was Compliant-Sounding and Illegal
A financial advisory firm came to me to set up AI for content generation and compliance scanning. They wanted help producing marketing copy faster and catching regulatory problems before a human ever had to read the page. Reasonable ask.
The most dangerous thing the AI could do turned out to have nothing to do with typos or tone. It was a single category of sentence: confidently describing the firm as a registered investment adviser.
Here's the catch. The firm isn't one.
It operates as a trade name (a DBA) under a national broker-dealer. Everyone calls it a registered investment adviser out of habit. The team does it. Prospects do it. It sounds right because firms that look like this one usually are registered advisers. But this one isn't, and saying it is can be legally false.
An AI that doesn't know that distinction writes a grammatically perfect, professional-sounding sentence that a regulator could treat as a material misstatement. And it writes it with total confidence, because nothing in its training told it to hesitate.
This is the part most people miss when they think about ai ground truth facts business risk. The threat isn't bad grammar. It's good grammar wrapped around a false fact. The smarter the model, the more convincing the lie, and the harder it is for a human reviewer to catch by reading it.
The fix is not a better model. I want to be blunt about that, because everyone reaches for the better model first. The fix is a ground-truth facts block: a short, citation-backed set of non-negotiable facts the model loads before it writes a single word, and is forbidden to contradict.
Get that block right and the firm's regulatory identity stops being something the AI improvises. Skip it, and you're one fluent sentence away from a compliance problem.
Why a Smarter Model Makes This Worse, Not Better
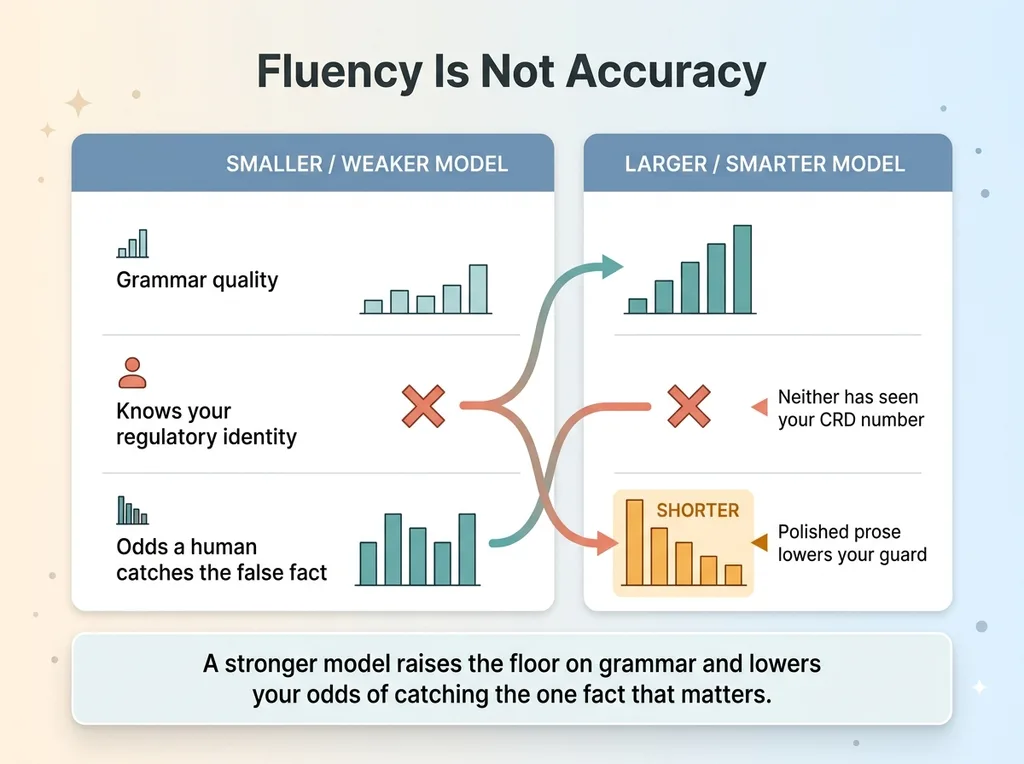
People assume a bigger, smarter model is safer. With this specific failure, the opposite is true.
 Why a smarter model makes this failure worse
Why a smarter model makes this failure worse
A larger model doesn't know your regulatory identity. It has never seen your CRD number or your broker-dealer agreement. What it has seen is millions of documents where firms that look exactly like yours are registered investment advisers. So it pattern-matches, and it reproduces that pattern with the full confidence of a model that has read the entire internet.
There's no internal signal that says "I'm unsure about this firm's legal status." The model doesn't know it's guessing. It's not lying on purpose. It's improvising on a fact it was never given, and a smarter model improvises more fluently.
That's exactly the kind of output you can't catch by reading it. I wrote about this when an AI invented a Fed rate cut that never happened. The sentence was clean. The numbers were plausible. The event was fiction. Fluency is not accuracy, and the better the model gets at fluency, the more dangerous the gap becomes.
So a stronger model raises the floor on grammar and lowers your odds of catching the one fact that matters. You read a polished paragraph, your guard drops, and the false claim sails through review.
The only real fix is to stop letting the model improvise that category of fact at all. Not "ask it nicely to be careful." Remove the decision from its hands.
This is the same principle behind why I lock the AI to a fixed catalog on my DTC brand. The model doesn't invent product names or prices. It works from a known truth I hand it. Your regulatory identity deserves the same treatment. Some facts are too expensive to leave to a probabilistic guess, no matter how good the guesser has gotten.
What a Ground-Truth Facts Dossier Actually Is
A ground-truth facts dossier is a compact, citation-backed set of standing facts the model loads on every scan and every generation, before it writes anything. It's not a policy binder. It's a tight block of non-negotiables, and every line is load-bearing.
The shape of the document
Short on purpose. For this firm, the dossier was under a page. A long document dilutes attention; the model treats a wall of text as background. A short block of hard facts gets treated as rules.
 Anatomy of a ground-truth facts dossier
Anatomy of a ground-truth facts dossier
Here's the kind of thing that went in, anonymized:
- The firm is a trade name (DBA) operating under a national broker-dealer. It is not itself a registered investment adviser.
- Advisors hold dual capacity: both brokerage and advisory. Copy must not imply one exclusively.
- One named role's title must read exactly one specific way, with no variation.
- The phrases "fee-only" and "commission-free" are per-se misleading in this firm's structure and must never appear.
- Certain brand assets are explicitly out of scope and must not be referenced.
That's the texture. Identity, scope, titles, banned phrases, boundaries. Each one is a place where being wrong is expensive.
Why citations matter
Every fact in the dossier carries a citation to the source rule, regulation, or internal authority it comes from.
Two reasons. First, the model can reference why a fact is true, which makes its flags more useful to the human reviewing them. Second, and more important, the citation lets a human trust the line. When my compliance reviewer sees "fee-only is prohibited" with the rule attached, they don't have to relitigate it. They can verify it once and move on.
A fact without a citation is just an assertion. In a regulated context, an unsourced assertion is exactly the thing you're trying to eliminate. So the dossier holds itself to the same standard it imposes on the AI. Every line is sourced, short, and treated as non-negotiable. If you want the deeper mechanics, I broke down encoding a firm's legal facts as ground truth in a companion piece.
How the Model Treats It as Non-Negotiable
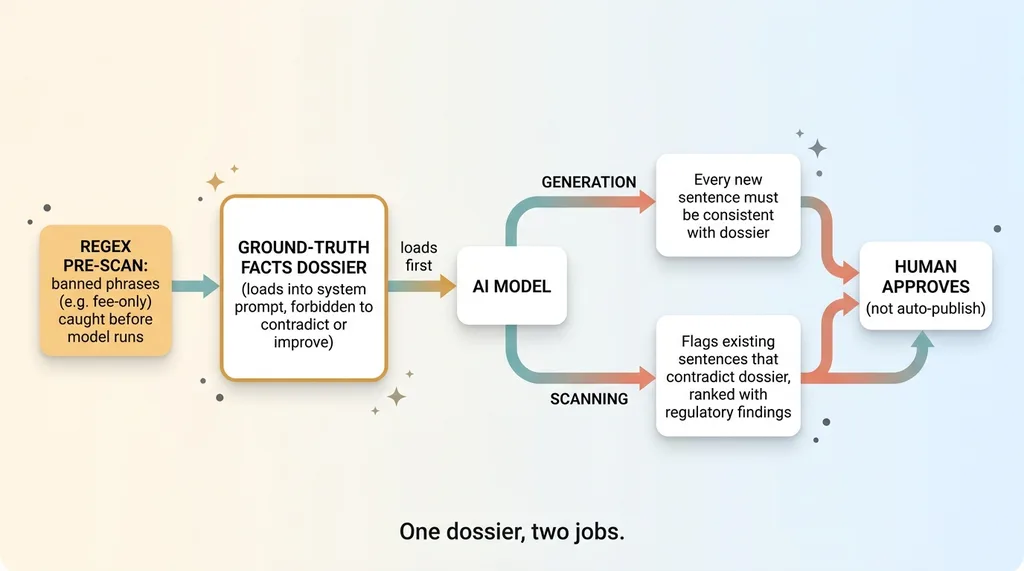
The dossier loads into the system prompt as ground truth, framed explicitly as facts the model is forbidden to contradict or "improve." That last word matters. Without it, a helpful model will smooth over a fact to make a sentence read better and break it in the process.
 Ground-truth dossier wired into generation and scanning
Ground-truth dossier wired into generation and scanning
The block does two jobs.
On generation: every sentence the model writes must be consistent with the dossier. If it's drafting a bio and the dossier says the firm is not a registered investment adviser, that phrase simply cannot appear. The constraint is upstream of the writing.
On scanning: any existing sentence that contradicts the dossier is flagged as a violation, ranked right alongside actual regulatory findings. This is the part that earns its keep. The same facts that constrain new writing also audit the old writing. One dossier, two uses. You point the scanner at 200 pages of legacy copy and it surfaces every place someone called the firm an adviser years ago.
Where I can be deterministic, I am. Certain banned phrases get a regex pre-scan before the model ever runs. "Fee-only" never reaches a judgment call. It's caught by a pattern match, flagged, and stopped. I don't ask a probabilistic model to enforce a rule that a three-line regex can enforce with certainty. Save the model's judgment for the genuinely fuzzy cases.
To be clear about the workflow: the model drafts and the model flags, but a human approves. This is not auto-publish. The ground-truth block shrinks the volume of things the human has to catch and raises the odds they catch the dangerous ones. It does not remove the human. On a regulated workflow, anyone selling you full automation is selling you liability.
Finding the Facts That Belong in the Block
The dossier should be small. This is the mistake I see people make once they understand the idea: they try to encode everything they know about the company. Don't.
 The test for what facts belong in the dossier
The test for what facts belong in the dossier
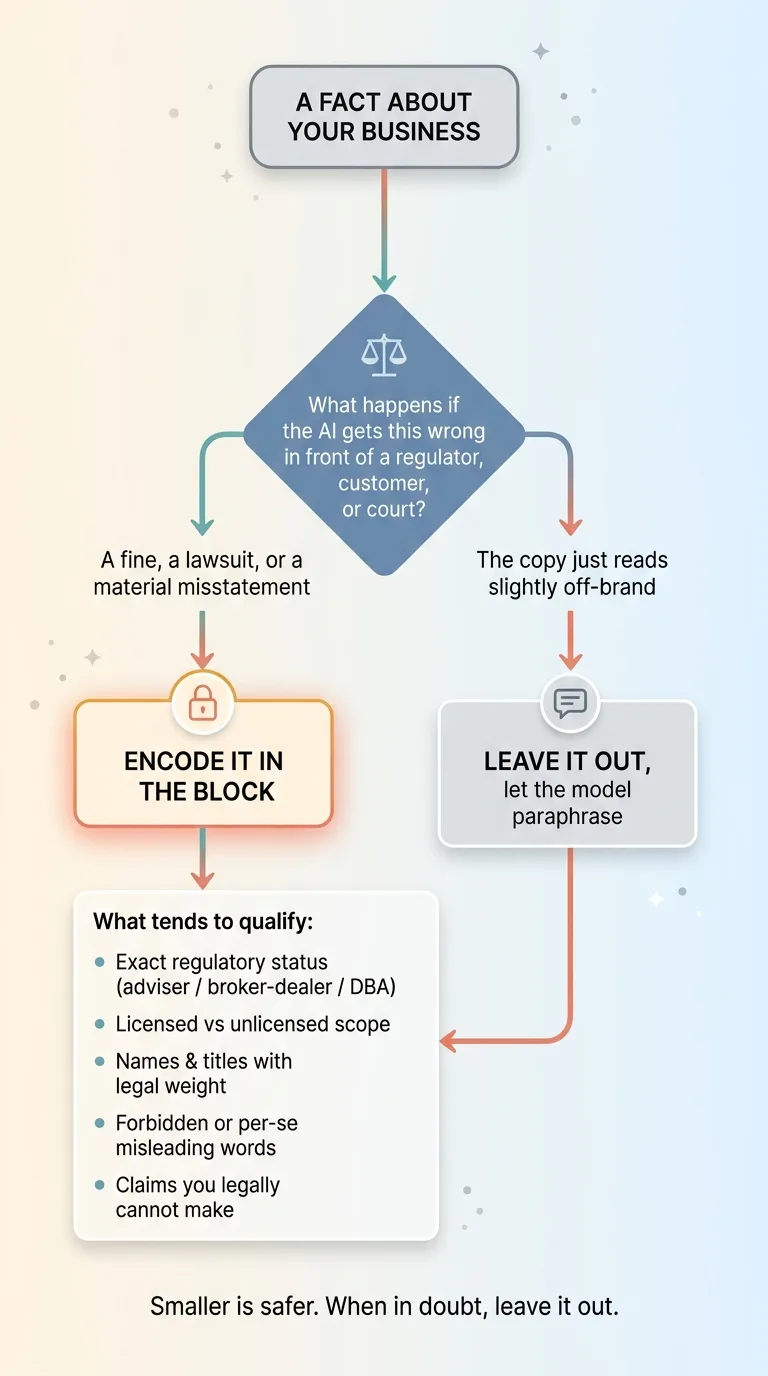
Most facts about your business are fine for the AI to paraphrase. Your founding year, your service areas, your general approach, your values. If the model rewords those, nobody gets hurt. You only encode the handful where being wrong is expensive, legally false, or per-se misleading.
Here's the test I use. Ask: what happens if the AI gets this fact wrong in front of a regulator, a customer, or a court? If the answer is "a fine, a lawsuit, or a material misstatement," it goes in the block. If the answer is "the copy reads slightly off-brand," it stays out.
What tends to qualify, across industries:
- Your exact regulatory status (adviser vs. broker-dealer vs. DBA).
- Your licensed-versus-unlicensed scope, the line you legally cannot cross in your claims.
- Names and titles that carry legal weight and must read one specific way.
- Words that are forbidden or per-se misleading in your space.
- Claims you legally cannot make, even when they're true-ish.
For a health firm, the qualifying fact might be a treatment boundary you can't advertise. For a manufacturer, it's a certification you either hold or don't, with no rounding up. For a financial trade name, it's the identity problem I opened with.
The discipline is this: every line in the dossier has to earn its place. Smaller is safer, because a short block is one the model actually respects and a human can verify end to end in ten minutes. A bloated dossier is one nobody maintains, which means it goes stale, which is its own failure. When in doubt, leave it out and let the model paraphrase. Reserve the block for the facts that would cost you real money to get wrong.
What This Doesn't Solve (And Where It Still Breaks)
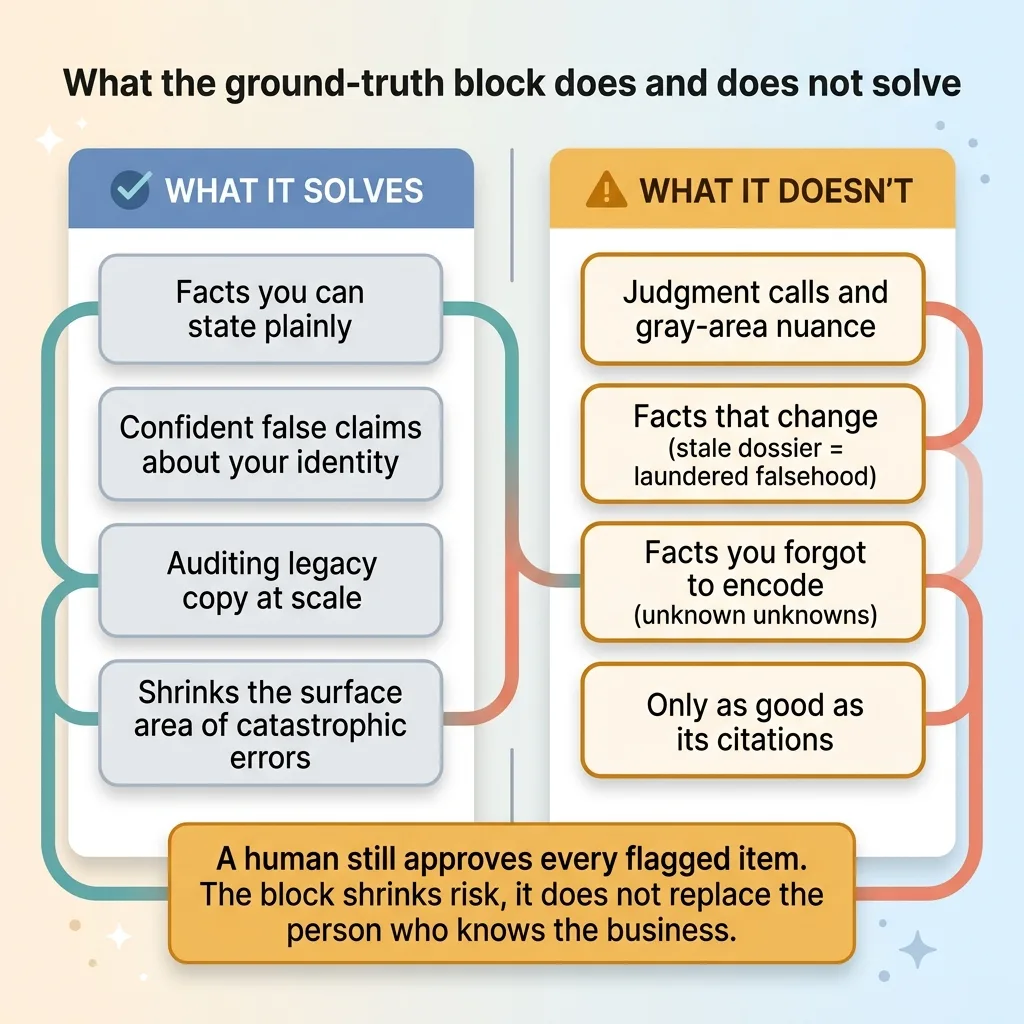
I'd be lying if I told you this eliminates risk. It reduces a specific, catastrophic category of error. Here's what it doesn't touch.
 What the ground-truth block does and does not solve
What the ground-truth block does and does not solve
It handles facts you can state. It does not handle judgment calls or nuance. Whether a particular claim is "misleading in context" is sometimes a real question a compliance officer has to weigh, and the dossier can't make that call for you. It can flag the obvious banned phrase. It can't adjudicate the gray area.
It doesn't handle facts that change. If the firm's structure changes, the firm registers as an adviser next year, or a title gets updated, the dossier is now wrong. And here's the trap: the AI will inherit that stale fact with the same total confidence it had when the fact was true. A wrong dossier is more dangerous than no dossier, because it launders a falsehood through your own controls. You need a review cadence and a named owner who updates it. No owner, no trust.
It can't catch a fact you forgot to encode. The unknown unknowns. If nobody put a particular forbidden claim in the block, the model will happily write it. The dossier is only as complete as the people who built it.
And it's only as good as its citations. A wrong citation is worse than none, because it makes a false fact look verified.
This is exactly why a human still approves every flagged item. The ground-truth block shrinks the surface area of catastrophic errors. It does not replace a person who knows the business. Anyone who tells you AI removes that person entirely in a regulated context hasn't shipped in one.
Encode the Non-Negotiables Before You Let AI Write a Word
Every business has a handful of facts the AI must never improvise.
For a financial trade name, it's regulatory identity. For a health firm, it's a compliance boundary. For a manufacturer, it's a certification claim. Different industries, same shape: a small set of facts where being wrong is expensive, and a model that will confidently get them wrong unless you take the decision away from it.
So build the ground-truth block first. Then let the model write. The constraints come before the cleverness, not the other way around. That ordering is the whole game. It's why my content systems on my DTC brand never invent a price, and it's the first thing I set up when I ship AI content in a regulated industry.
This is the actual work. Not a slide that says "AI for compliance." A short, sourced, maintained dossier wired into both generation and scanning, with a regex layer for the phrases that should never reach a judgment call, and a human who approves what gets published.
If your AI is one confident sentence away from saying something legally false about your own company, that's a solvable problem, and a fast one. I build these. I don't just advise on them.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call