Field Level Encryption: One Module I Reuse Everywhere
How I built a reusable field level encryption module with AES-256-GCM, versioned key rotation, and a decrypt audit log for any app touching sensitive data.
By Mike Hodgen
The Problem: Every New App Reinvented Encryption Badly
Here's a pattern I noticed only after it had already cost me time on three separate projects.
Every time I started building something that touched regulated data, a health monitoring system, a payments startup client, an app holding personal financial details, encryption got handled differently. Inconsistently. Badly, if I'm honest.
Sometimes a sensitive column was encrypted. Sometimes the one right next to it wasn't, because we ran out of time or somebody forgot. Sometimes the audit trail got skipped entirely because it felt optional during the build.
The worst part wasn't even the inconsistency. It was that none of these apps could answer the one question a regulator or a nervous enterprise customer actually asks: who decrypted this record, and when?
That question has nothing to do with whether your data is encrypted. You can have flawless AES everywhere and still have no answer. And when you can't answer it, "we encrypt everything" sounds like a guess instead of a control.
Each app was a one-off. Different library, different format, different decisions made by whoever was on the keyboard that week. That's how you end up with five different encryption approaches across a portfolio and zero confidence in any of them. You can't audit five different things. You can barely remember how they work.
So I stopped reinventing it.
I built one drop-in field level encryption module and standardized on it. Now I copy the same file into any project that touches health, financial, or personal data. Same format, same rotation behavior, same audit logging, same test suite. One decision, made once, reused everywhere.
This is the part most teams get wrong. They treat encryption as a per-project problem. It isn't. It's a per-organization standard that should be boring, tested, and identical across everything you ship. Below is exactly how mine works and why each design choice exists.
What Field Level Encryption Actually Means (And Why It Beats Disk Encryption)
Let me define this plainly, because the terms get muddled constantly.
Encrypt the field, not just the disk
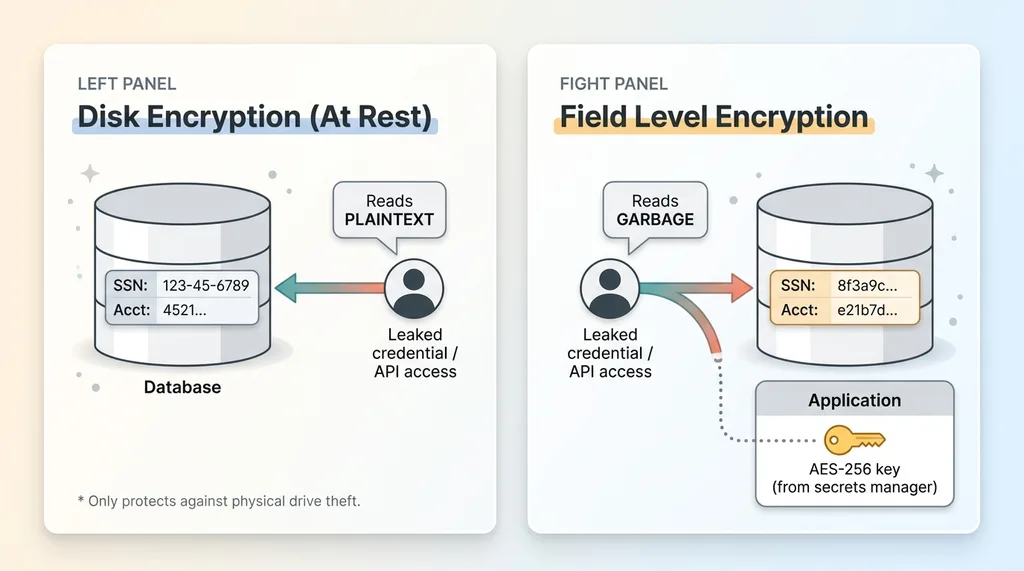
Disk encryption, what most vendors mean when they say "encryption at rest," protects you against one thing: someone physically stealing a hard drive. That's it. If a laptop walks out of a data center, the contents are scrambled.
It does nothing if someone gets read access to your database through the application, a leaked credential, or a misconfigured API. The disk decrypts transparently for anyone the system already trusts. To an attacker with a valid connection, encryption at rest is invisible. They read plaintext.
Field level encryption is different. The sensitive value itself is ciphertext in the row. A Social Security number, a medical note, a bank account, it sits in the column as scrambled bytes. If someone dumps the entire table, they get garbage. No key, no data.
This is the practical defense against the whole class of incident where a public key or anon role accidentally gets read access and someone pulls your entire users table. With field level encryption, what they pull is useless.
Keys the database itself never holds
Here's the design point that matters most: the database never holds the key.
 Disk encryption vs field level encryption attack surface
Disk encryption vs field level encryption attack surface
The application holds it, injected at runtime from a secrets manager, never committed to the repo, never sitting in the same place as the data it protects. If the key lived in the database, field encryption would be theater. Dump the table, find the key, decrypt everything.
I use AES-256-GCM specifically. The 256 is the key size. The GCM part matters more than people realize. GCM gives you authentication on top of confidentiality, which means the module can detect tampering. If a single byte of ciphertext gets flipped, decryption fails loudly instead of silently returning corrupted plaintext. You want that failure. Silent corruption in a medical record is a nightmare you find out about at the worst possible moment.
Inside the Module: A Versioned Ciphertext Format
The thing that makes this module reusable instead of a science project is one design decision: a versioned ciphertext format.
Why a version prefix matters
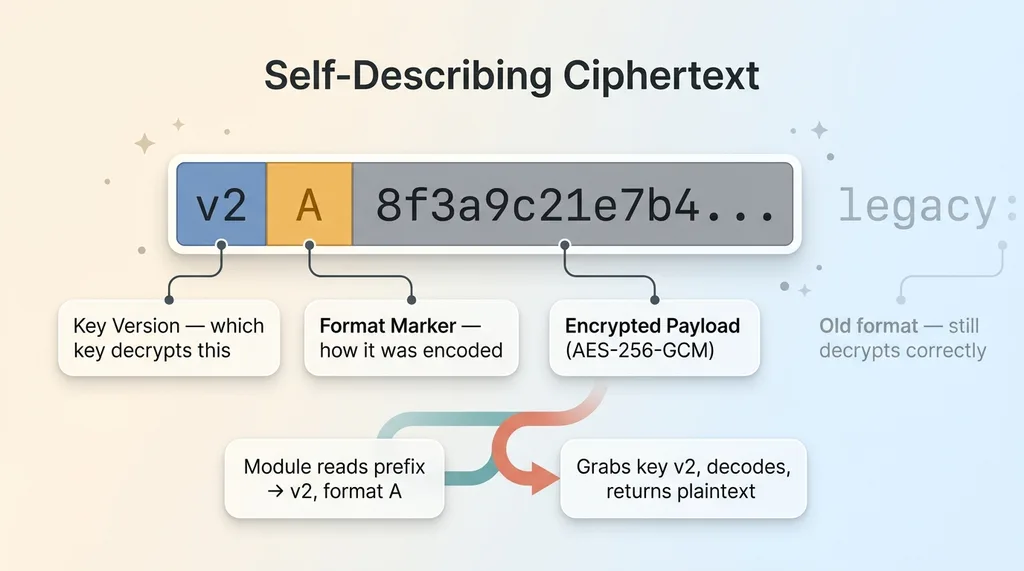
When the module encrypts a value, it doesn't just store raw ciphertext. It stores a short prefix that identifies which key version and which format were used, followed by the encrypted payload.
 Versioned ciphertext format anatomy
Versioned ciphertext format anatomy
That prefix is tiny. A few bytes. But it's the single decision that makes rotation and migration possible without downtime.
When the module reads a value, it looks at the prefix first. The prefix tells it: this row was written with key version 2 and format A. So it grabs key version 2, applies the right decoding, and returns the plaintext. New writes use the current key version. Older rows carry an older prefix and still decrypt correctly, because the module knows exactly how they were written.
Without the prefix, you'd have to know out-of-band which key encrypted which row. That's unworkable the moment you have more than one key in play. The prefix makes every ciphertext self-describing.
Backward compatibility with legacy data
There's also a backward-compatible legacy format built in. Data written before I standardized on this module carries a different marker, and the module recognizes it and decrypts it correctly.
This matters more than it sounds. It means adopting the standard doesn't require a risky one-pass migration of every existing row. Old data keeps working. New data uses the current standard. You converge over time instead of in one terrifying maintenance window.
For the buyer, the takeaway is this: adding encryption to a new project is copying one file and changing one prefix string. It's a packaged standard with a stable interface, not a custom build each time.
This is the org-standard angle. If you want the Supabase-specific walkthrough of getting this running against a real database, I covered that separately in encrypting PHI in Supabase. This article is about why I made it a reusable standard in the first place.
Key Rotation Without Downtime or a Migration Nightmare
Ask most engineering teams when they last rotated their encryption keys and you'll get a long pause.
The honest answer is usually never. Because they assume rotation means decrypting and re-encrypting the entire database in one shot, which sounds like a downtime event and a chance to corrupt everything at once. So it never happens, and keys live for years, which is exactly the risk you were trying to avoid.
New writes use the new key, old data still decrypts
The versioned format makes rotation gradual instead of catastrophic.
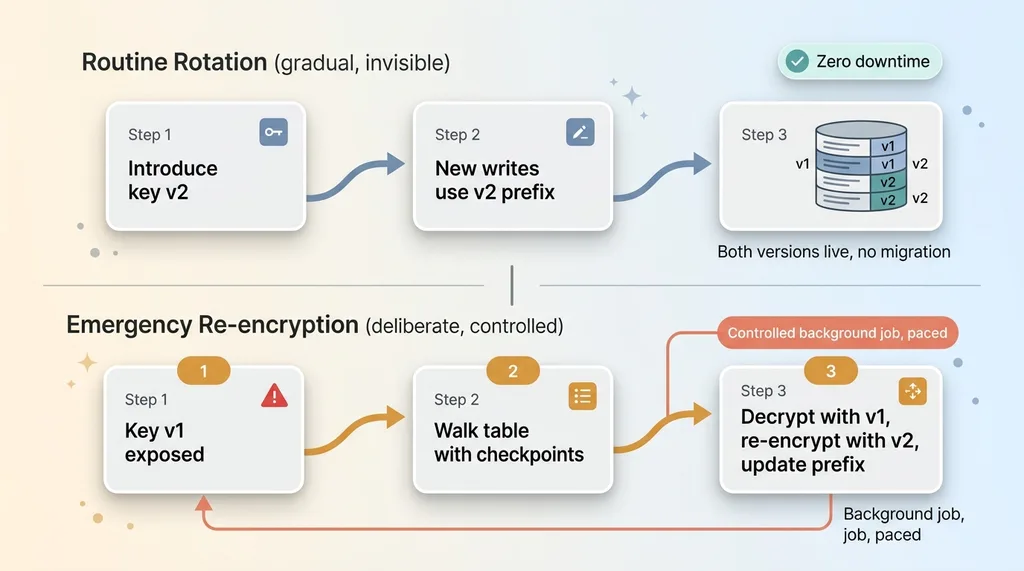
You introduce a new key version. You point new writes at it. That's the entire active step. From that moment, fresh data is encrypted with the new key and carries the new prefix.
Old rows? They keep decrypting fine. Their prefix says "key version 1," so the module reaches for key version 1 and decrypts them. Nothing breaks. No migration ran. You have two key versions live at the same time, and the module handles both transparently.
This is a key rotation strategy that's operationally boring on purpose. And boring is precisely what you want in security. The exciting security stories are the ones where something went wrong.
When you actually need to re-encrypt
Sometimes gradual isn't enough. If a key was exposed, you can't leave old rows sitting there encrypted with a compromised key just because nobody's touched them lately.
 Gradual key rotation vs emergency re-encryption
Gradual key rotation vs emergency re-encryption
For that, you re-encrypt. You can do it lazily, re-encrypting each row with the new key the next time it's written. Or you run a controlled background re-encryption, walking the table, decrypting with the old key, re-encrypting with the new one, and updating the prefix, all at a pace you control with checkpoints.
The difference is that re-encryption becomes a deliberate operation you reach for when you need it, not a prerequisite for every rotation. Routine rotation is gradual and invisible. Emergency re-encryption is a separate, controlled job. Separating those two is what makes rotation something you'll actually do.
The Audit Log: Answering Who Decrypted What, When
This is the part that separates a real compliance posture from "we encrypt our data."
Logging decrypt events without ever logging plaintext
Encryption protects the data. The audit log proves access. They're different jobs and you need both.
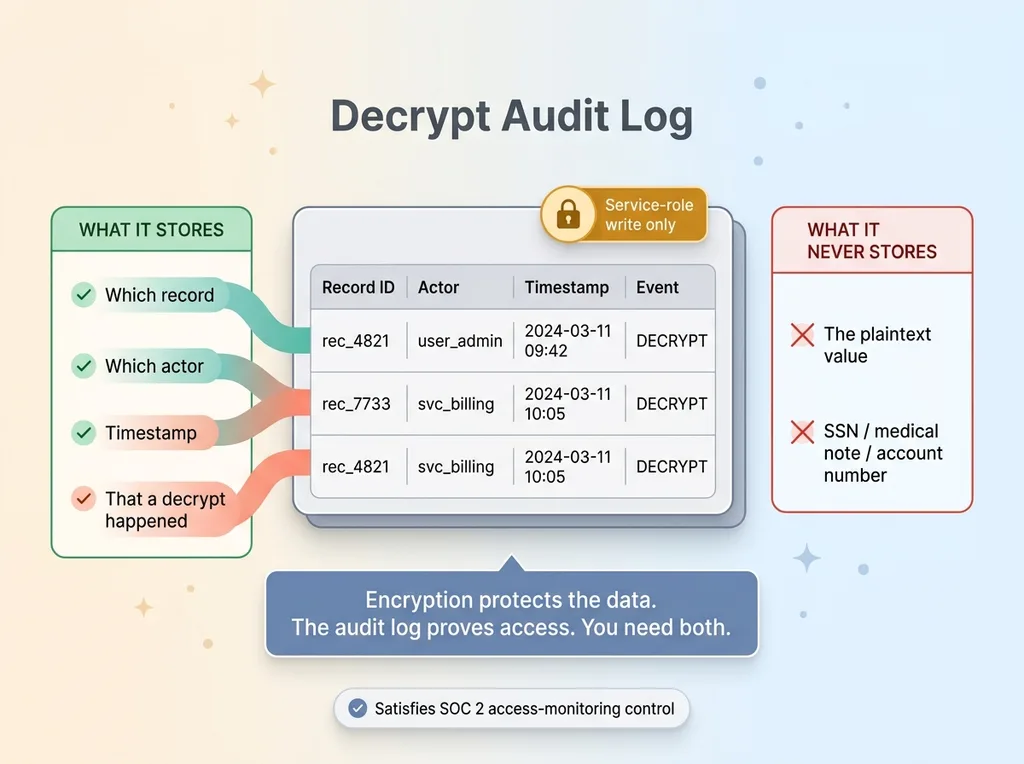
Every time the module decrypts a value, it records an event: which record, which actor, what timestamp. So when the question comes, and with regulated data it always comes, you run a query instead of starting a forensic investigation.
The critical rule: the log never contains plaintext. It records that a decrypt happened, not what was revealed. There's no point protecting data with AES-256 if you then dump the decrypted value into a log table that's easier to read than the original. The audit log proves a decrypt occurred. It does not become a second copy of your sensitive data.
Service-role-only access
The audit table is writable only by the service role. The application's normal users can't read it, can't write to it, can't tamper with it. An attacker who compromises a regular user account can't quietly delete their own tracks.
 The decrypt audit log and what it does/does not store
The decrypt audit log and what it does/does not store
This is what satisfies the SOC 2 control around monitoring access to sensitive data. Auditors don't just want to hear that data is protected. They want evidence that access is logged, that the log is tamper-resistant, and that you can produce it on demand.
Here's the framing I give every CEO: "we encrypt our data" is table stakes. Everyone says it. "We can produce a complete log of every decrypt event, by actor and timestamp, in a table users can't touch" is what passes an audit and what reassures an enterprise customer doing vendor due diligence.
And to be clear, encryption plus an audit log still isn't the whole compliance picture. I wrote about why encryption alone doesn't make you compliant because too many teams check the encryption box and assume they're done. They aren't. But this module covers two of the controls that actually get scrutinized.
Proving It Works: A 14-Test Suite That Travels With the Module
Security code you can't trust is worse than no security code. No security code at least keeps you honest about your exposure. Security code you believe in but never verified gives you false confidence, which is how you end up surprised.
 The 14-test suite that travels with the module
The 14-test suite that travels with the module
So the module ships with a 14-test suite, and the tests travel with it. Every project that copies the module inherits the proof.
The tests cover the things that actually go wrong:
- Encrypt/decrypt round trips for every supported data type, confirming what goes in comes back out unchanged.
- Tamper detection. A flipped byte in the ciphertext must fail authentication, not silently decrypt to garbage. This is the GCM guarantee, and I test it because a guarantee you haven't verified is just a hope.
- Legacy-format compatibility. Data written in the old format still decrypts correctly after adopting the standard.
- Rotation correctness. Data encrypted under an old key still decrypts after a new key is introduced, which is the whole promise of the versioned format.
This is the same discipline I apply to anything money- or health-related. Deterministic, tested, verifiable. No "it worked when I tried it." Either the suite is green or the module doesn't ship.
The companion practice here is keeping the secrets out of the codebase in the first place. The module assumes keys come from a secrets manager at runtime, and I've written separately about keeping sensitive data out of your repo, because the best encryption in the world doesn't help if the key is sitting in your git history.
What This Means If You're Storing Regulated Data
If you're a CEO storing health, financial, or personal data, two fears are probably sitting in the back of your mind.
The first: that doing encryption properly is a big custom project you'll have to fund and babysit. The second: that if an enterprise prospect or a regulator asks who accessed a specific record, you don't actually have an answer.
A properly designed module turns the first fear into a one-file decision per app. Encryption, rotation, and audit logging come built in from day one instead of getting bolted on in a panic the week before a security review. And it turns the second fear into a query instead of a fire drill.
Let me be honest about the limits, because that matters more than the pitch.
This is one layer. It does not replace access controls. It does not replace a signed BAA where one is legally required. It does not replace row-level security or proper authentication. If those are broken, this module won't save you.
What it does is specific and valuable: it makes a database dump useless to whoever steals it, and it makes "show me everyone who accessed this record" a question you can answer in seconds. Those are two of the things that go wrong most often and embarrass companies most publicly.
If you're handling regulated data and you're not confident your encryption and audit story would survive a vendor security review, that's exactly the kind of thing I standardize when I come in. One module, one standard, applied across everything you ship, instead of five different approaches and zero confidence.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call