Competitor Price Scraping That Survives Anti-Bot Walls
How I built reliable competitor price scraping that beats anti-bot blocks and controls cost, using stealth proxies where it matters and caching where it doesn't.
By Mike Hodgen
Why competitor price scraping breaks the moment it matters
I run three scraping jobs across my businesses. Competitor intel for my DTC fashion brand (prices, promos, review widgets), backlink outreach prospect discovery, and event and venue calendar discovery. Every one of them depends on competitor price scraping that actually returns data instead of a wall.
Here is the thing nobody tells you when they show you a scraping demo. The pages worth scraping are the exact pages built to block you.
The pages worth scraping are the ones built to block you
A promo banner that tells me a competitor just dropped prices 20 percent? Behind anti-bot defenses. A review widget that loads the social proof I want to track? Rendered in JavaScript after the page loads, so a basic fetch returns a blank shell. An outreach prospect list or a venue calendar with the dates I need? CAPTCHA, rate limit, or a flat 403.
The signal lives behind the defenses. That is not a coincidence. The pages carrying real competitive value are the ones companies pay to protect.
Three jobs, three different failure modes
My competitor intel job fails when the price renders client-side and I get the HTML before JavaScript fires. My outreach discovery job fails when the prospect directory flags my IP and serves a CAPTCHA. My venue calendar job fails when the listing site rate-limits me after a dozen requests.
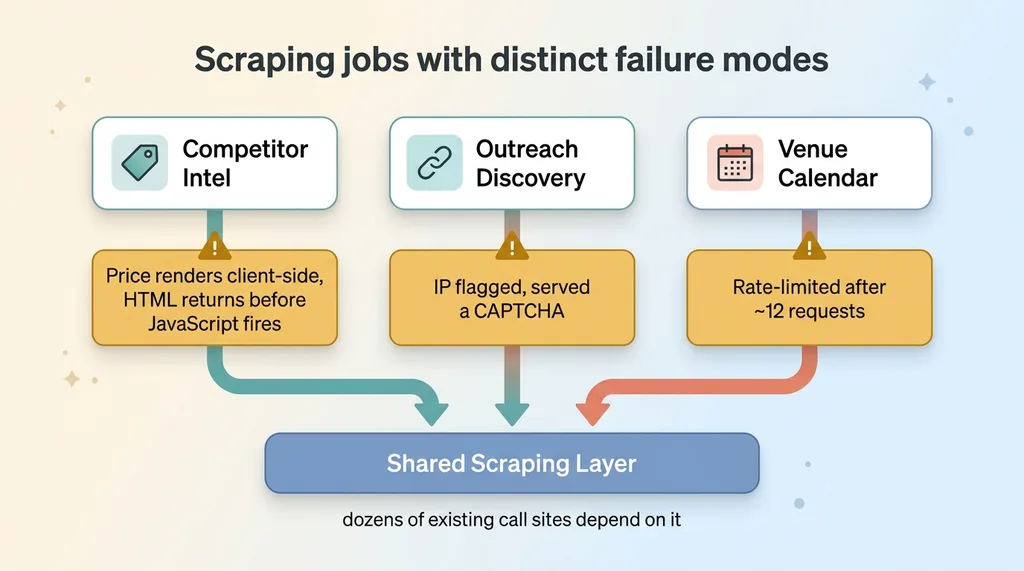 Three scraping jobs with three different failure modes
Three scraping jobs with three different failure modes
Three jobs. Three failure modes. One shared scraping layer underneath, with dozens of existing call sites depending on it.
Scraping is easy in a demo and brittle in production. The honest buyer question is this: how do you reliably track competitor prices when the sites you care about are designed to stop you? That is the actual problem, and it is not solved by a slicker scraper.
The trap of building your own proxy and stealth infrastructure
The instinct when you hit a 403 is to build your way out. Rotating residential proxies. A headless browser farm. A CAPTCHA solving pipeline. I considered all of it.
Then I remembered I sell clothes.
Running stealth infrastructure is a full-time job that has nothing to do with my business. Residential proxy pools degrade. Browser fingerprints get burned. Anti-bot vendors update their detection weekly, and now you are in an arms race you never wanted to enter, maintaining infrastructure instead of running your company.
So I do what I do with most hard primitives: I pay for the primitive and build the logic myself. I pay a managed scraping API to handle proxies, browser rendering, and anti-bot evasion. I build the part that matters to my business on top: what to scrape, when, how to cache it, and how to parse the result into something my tools can use.
The vendor fights the arms race. I stay focused on the data.
But there is an honest catch. A managed scraping API charges per request, and that cost compounds fast on scheduled re-scrapes. If you re-fetch 564 product pages every hour, you are lighting money on fire whether the prices changed or not.
So the problem is not just blocking. It is blocking and cost, at the same time.
That sets up a two-part goal that shaped everything I built. Beat the blocks where they actually happen. Cut the spend where they do not. Most people solve one and ignore the other, then wonder why their competitive intelligence either returns garbage or costs a fortune.
Migrating to a v2 scrape API without breaking dozens of call sites
When my scraping vendor released a v2 API with better anti-bot handling, I had a problem most people underestimate. All three of my tools called an older scraping function. The v2 API had a completely different request and response shape.
I had dozens of call sites depending on the old structure. A naive migration means touching every one of them, and every touch is a chance to break something in production.
Keep the response shape identical
The rule I set was simple. Preserve the exact response shape every existing call site expected.
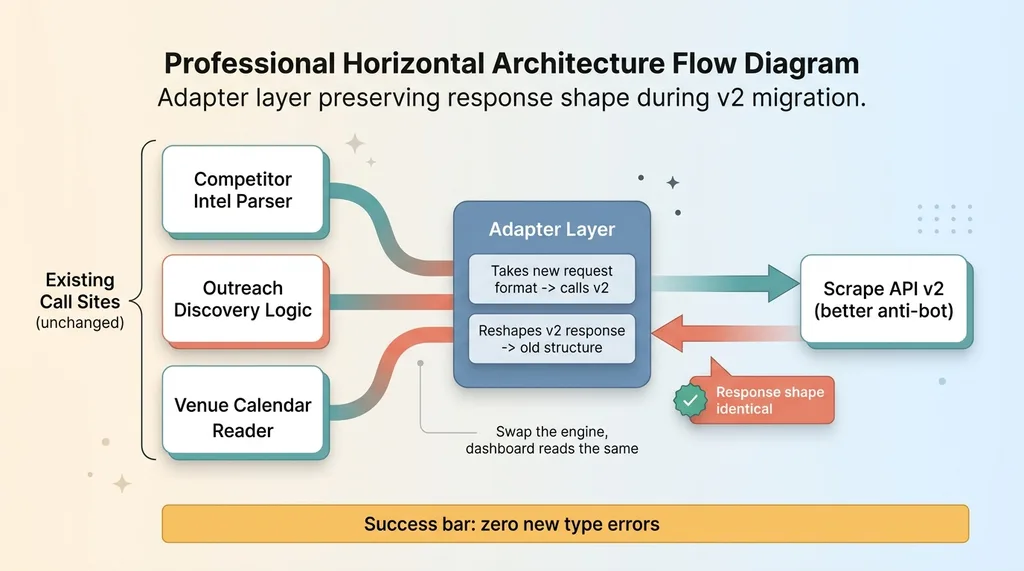 Adapter layer preserving response shape during v2 migration
Adapter layer preserving response shape during v2 migration
I wrapped the v2 call in an adapter. The adapter takes the new request format, calls v2, then reshapes the response back into the old structure my tools already understood. Nothing downstream changed. Not the competitor intel parser, not the outreach discovery logic, not the venue calendar reader.
This is the un-sexy part that decides whether a migration ships or stalls. Nobody writes a case study about an adapter layer. But it is the difference between a one-day swap and a two-week firefight.
Zero new type errors as the success bar
My success bar was concrete and boring. Migrate all three tools, run the type checker, ship with zero new type errors.
Not "it seems to work." Not "I tested the happy path." Zero new type errors across the whole codebase, because the response shape was identical and the contract held.
The mental model is this. You can swap the engine under a running car as long as the dashboard still reads the same. The driver never knows. My tools never knew the underlying scraping API changed. They kept asking for data in the old shape and kept getting it.
The win here is risk control, not cleverness. The boring engineering decision (an adapter that preserves the contract) is what let me upgrade the anti-bot capability without betting the whole system on it.
Stealth proxies only where blocking actually happens
Here is the insight that cut my costs and kept my data quality high at the same time. Stealth proxy mode is not a global switch. It is a per-target decision.
Stealth mode means residential IPs, browser fingerprinting, full page rendering. It works against aggressive anti-bot walls. It is also slower and more expensive per request, sometimes several times the cost of a basic fetch.
If you turn it on globally, you pay the premium on every page, including the ones that never blocked you in the first place. That is the mistake I see most often.
Turning on stealth selectively
I turned stealth on only for the surfaces that actually got blocked. Outreach prospect discovery, where the directories flagged my IPs. Competitor promo and review-widget scrapes, where the content rendered client-side behind defenses. Venue calendars, where the listing sites rate-limited fast.
Three categories. Those got the heavy machinery.
The pages that needed it vs the ones that didn't
Everything else ran on the cheaper default path. Slow-changing competitor catalog pages. Static info pages. Plain HTML that a basic fetch handled fine.
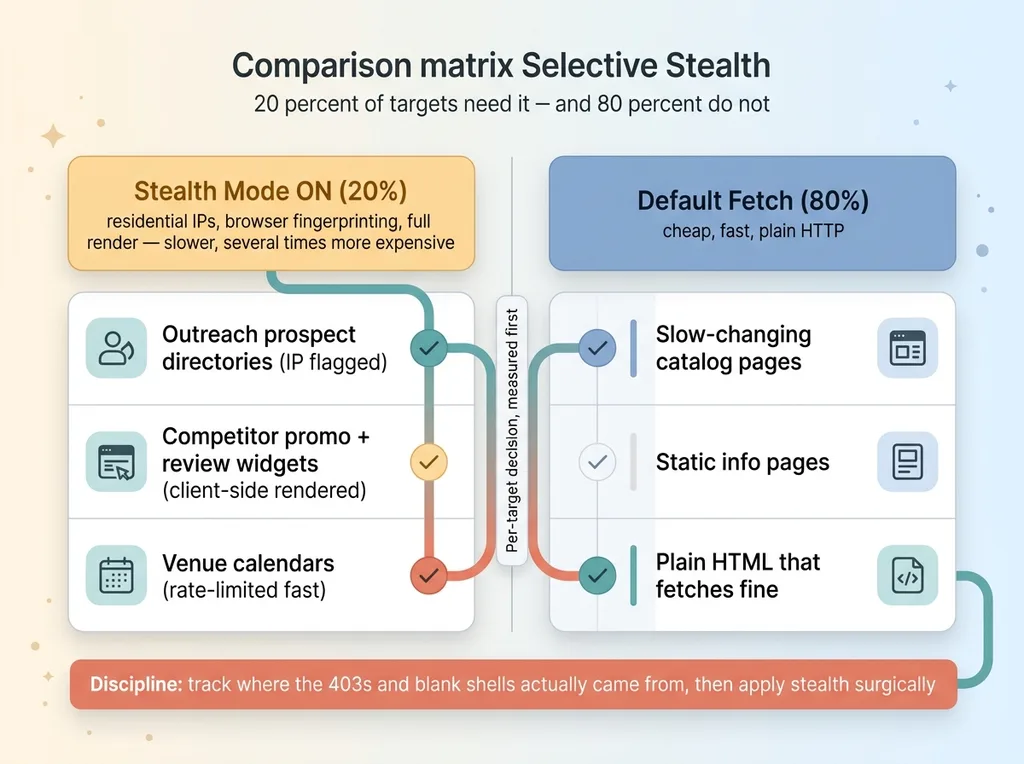 Selective stealth, the 20 percent that needs it vs the 80 percent that doesn't
Selective stealth, the 20 percent that needs it vs the 80 percent that doesn't
The discipline is measuring before you spend. I tracked where the 403s and blank shells actually came from, then applied the expensive tool surgically. Not "this whole job needs stealth." Instead, "these specific targets need stealth, the rest do not."
The buyer takeaway: anti-bot scraping is not all-or-nothing. The skill is knowing which 20 percent of your targets need the heavy machinery and routing only those through it. The other 80 percent runs cheap.
This selective stealth layer is what feeds the competitive intelligence system I run. It is also what powers my AI backlink outreach pipeline, where the prospect directories were the most aggressive blockers of the three. Same scraping layer underneath, different stealth decisions per target.
Scraping cost control with time-based caching
Selective stealth handles the blocking half. Caching handles the cost half. And scheduled re-scrapes are where spend quietly balloons if you are not paying attention.
Re-fetching the same competitor page every hour when its price changes once a week is pure waste. You pay for the request, you get back identical data, and you do it 168 times before anything actually changes. Multiply that across hundreds of pages and the bill is brutal.
Two days for slow-changing pages, 12 hours for fast churn
I added time-based caching tuned to how fast each surface actually changes.
A 2-day cache for slow-changing pages. Competitor catalog pages, static info pages, anything that updates on a weekly or monthly rhythm. There is no reason to re-scrape those more than every couple of days.
A 12-hour cache for fast-churning surfaces. Event listings and venue calendars that update through the day. Those need fresher data, so they refresh twice daily instead of every two days.
The cache window matches the reality of the source. Not a single global TTL applied blindly to everything.
Per-call overrides for when fresh matters
Sometimes I need a fresh pull regardless of the cache. A manual check before a pricing decision. A high-priority verification on a specific competitor. So I built a per-call override that forces a live fetch and bypasses the cache.
 Time-based caching tiers with per-call override
Time-based caching tiers with per-call override
The default protects the budget. The override handles the exceptions. Most calls hit the cache and cost nothing. The few that genuinely need fresh data get it.
The result is fewer paid requests, the same data quality, and the expensive stealth-proxy spend stays concentrated on the targets that actually need it instead of getting wasted on redundant re-fetches.
This is the same way I keep AI and data costs low at scale. The principle is identical. Do not pay repeatedly for work you already did. Cache the result, match the refresh rate to reality, and override only when fresh genuinely matters. The savings come from cutting redundant paid calls, not from negotiating a cheaper rate.
What this looks like as a repeatable competitive intelligence system
Step back and look at the three pieces together. An adapter layer that preserves every call site. Selective stealth applied only where blocking happens. Tiered caching matched to how fast each source changes.
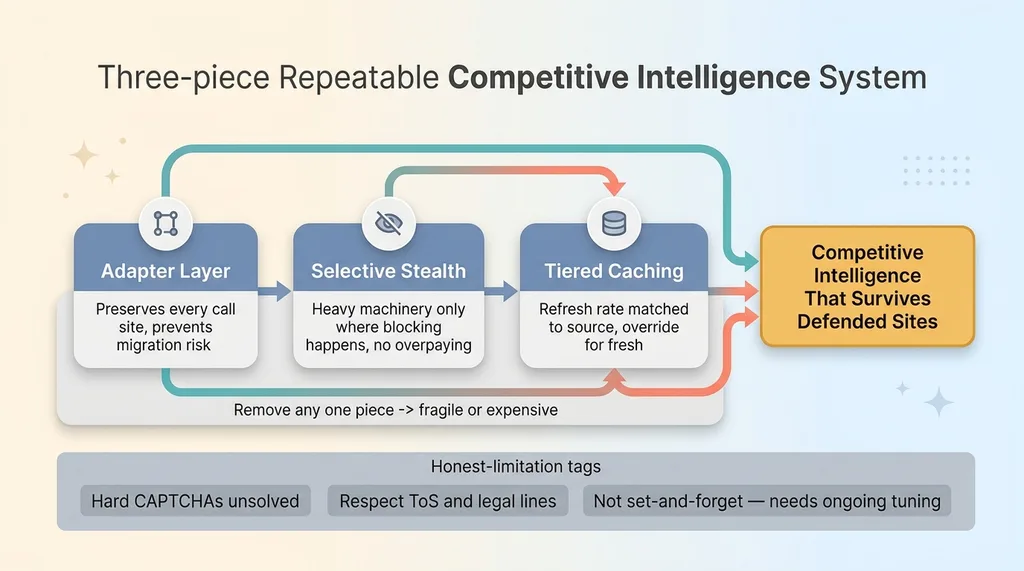 The three-piece repeatable competitive intelligence system
The three-piece repeatable competitive intelligence system
That combination is the pattern, not a one-off hack. It is competitive intelligence automation that survives contact with real, defended websites instead of falling over the first time a competitor updates their anti-bot rules.
Each piece solves a specific failure. The adapter prevents migration risk. Selective stealth handles blocking without overpaying. Caching controls cost without sacrificing freshness. Remove any one and the system gets fragile or expensive.
Now the honest limitations, because pretending otherwise would be a lie.
Some sites you still cannot reliably scrape. Hard CAPTCHA walls that require human solving. Aggressive rate limits that throttle you no matter how clean your proxies are. Those exist, and no architecture beats all of them.
You also need to respect terms of service and the legal lines on what you collect and how. Just because you can scrape something does not mean you should, and "I built a clever workaround" is not a defense worth relying on.
And this is not set-and-forget. Competitors change their defenses. A target that worked last month starts blocking next month. The system needs ongoing tuning, which means someone has to own it.
The value here is in the boring engineering decisions. The adapter, the per-target stealth flags, the cache windows. Not the AI buzz. The unglamorous architecture is what makes it survive in production.
How I'd build this for your business
If you are trying to track competitor prices, find link opportunities, or monitor any defended source, and you keep getting blocked or burning through budget, the fix is rarely a fancier scraper.
It is the architecture around it. An adapter so you never break what already works. Stealth applied surgically to the targets that actually block you, not globally. Caching matched to how fast each source genuinely changes, with an override for when fresh data matters.
I built this for my own DTC brand and for client tools across outreach, pricing, and monitoring. The same three pieces, tuned to each business.
As a Chief AI Officer, I build these systems inside your business. Not a slide deck about what competitive intelligence automation could theoretically do. The actual working pipeline, running against the real sites you care about, with the cost controls already in place.
If your competitor intel is either returning garbage or costing too much, that is a fixable problem. Usually in days, not months.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call