AI Cost Optimization on Large Datasets: Index, Don't Scan
AI cost optimization for large datasets: stop feeding 10,000 photos to a vision model per query. Enrich once, search a vector index, pay pennies.
By Mike Hodgen
The Math That Kills Most AI Products at Scale
I'm building a media app right now. The obvious version of it goes like this: a user types "find photos of this person at the beach," and the app sends every photo in their library to a vision model to check. Simple. Works great in a demo with 50 photos.
Now let me walk you through the numbers, because this is where AI cost optimization on a large dataset stops being an abstraction and starts being your P&L.
Say a single vision call costs a fraction of a cent. Round it to a third of a cent for the math. A user has 10,000 photos. One query scans the whole library, so that's 10,000 calls, or about $33 per query.
Now they run ten queries a day. That's $330 per user per day. Multiply by a few hundred users and you are burning five figures a day on inference for a feature you probably charge $10 a month for.
The reason this is so deadly is the shape of the curve. Cost equals library size times query volume. Both of those numbers grow as your product succeeds. The better you do, the faster you go broke.
Here's the CEO fear stated plainly: most people assume AI gets more expensive the more data you feed it. With the naive design, they are exactly right. Every new photo, every new user, every new query is another tax on the same broken architecture.
I see this everywhere, not just in media apps. Document search, support ticket triage, product catalogs. Someone builds the version where you "ask the model about the whole corpus," it looks brilliant on a tiny test set, and then it dies the moment real data shows up.
The fix is not a cheaper model. The fix is to stop scanning.
The Core Idea: Pay Once to Enrich, Pay Nothing to Retrieve
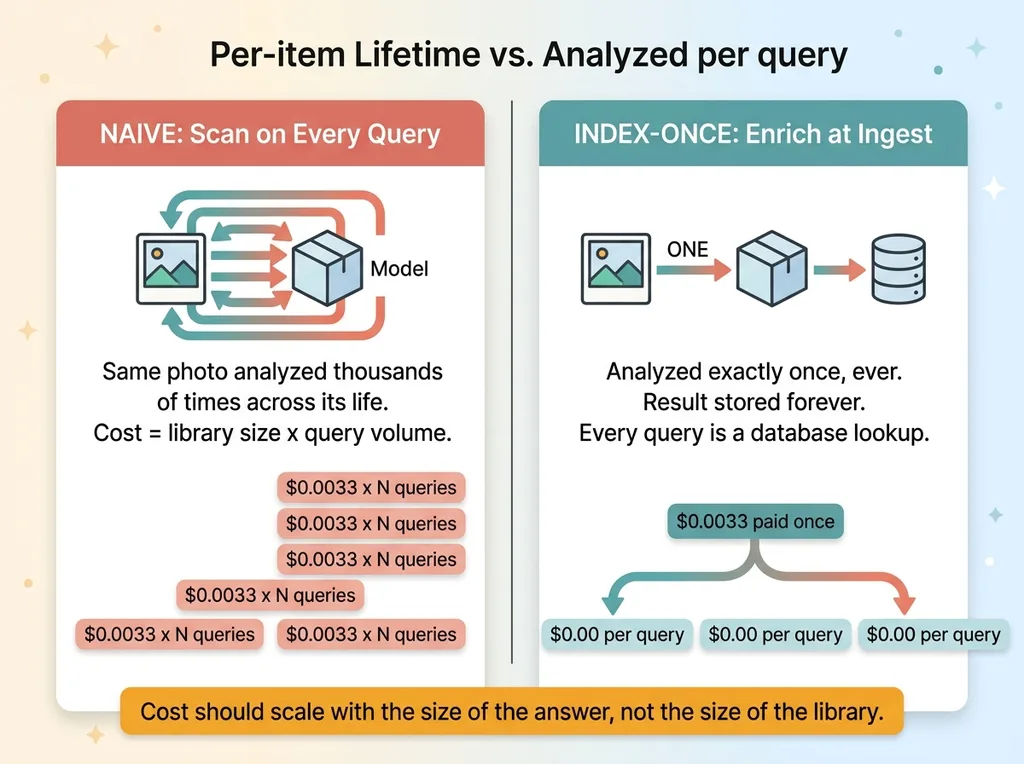
Here is the principle, and it's worth memorizing: your cost should scale with the size of the answer, not the size of the library.
 Per-item lifetime: analyzed once vs analyzed per query
Per-item lifetime: analyzed once vs analyzed per query
The naive design scales with the library. Every query touches everything. The right design touches almost nothing at query time, because you already did the expensive work earlier.
You spend model tokens once, at ingest, to turn each item into structured, searchable data. A caption. Tags. A vector embedding that captures meaning. After that, every query is a database operation. Database operations cost effectively nothing compared to model calls.
So the work moves from "happens on every query, forever" to "happens once per item, ever." That's the entire trick. You front-load the cost and amortize it across every future search.
This is not a photo-specific idea. It generalizes immediately:
- Documents, enrich each file once with a summary and embedding, then search the index.
- Audit and compliance files, extract entities and dates at ingest, query with a filter.
- Support tickets, classify and embed on arrival, retrieve by similarity.
- Product catalogs, tag and embed each SKU once, then match instantly.
Any large corpus you want AI to reason over fits this shape.
The mental shift is from "ask the model about the library" to "ask the database, then maybe ask the model about three results." That little word "maybe" is where most of your savings live. Most queries never need a model call at all once the data is indexed properly.
What Actually Happens at Ingest (The Expensive Step You Only Pay Once)
The ingest pipeline is where the discipline lives. Done right, you spend a model call on almost none of your raw data.
 Ingest pipeline funnel: cheap filters before model calls
Ingest pipeline funnel: cheap filters before model calls
Cheap signals first, model calls last
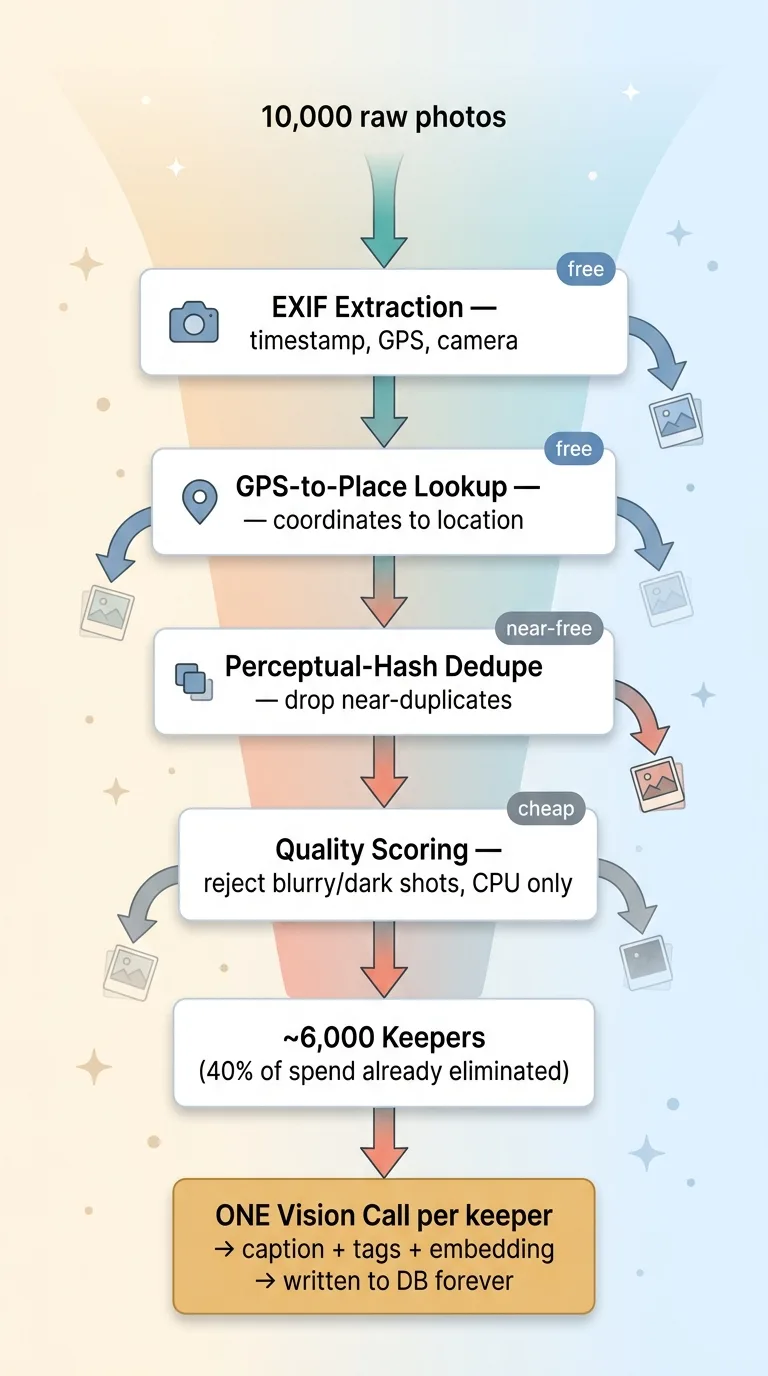
Before any photo goes near a vision model, it runs a gauntlet of free or near-free checks.
First, EXIF extraction. The photo already carries metadata: timestamp, camera, GPS coordinates. Pulling that costs nothing. A quick GPS-to-place lookup turns coordinates into "Encinitas, California." Still no tokens spent.
Next, perceptual-hash dedupe. People take eight nearly identical shots of the same sunset. A perceptual hash lets you detect near-duplicates and drop them before you ever pay to analyze them. Why caption the same beach five times?
Then quality scoring. Blurry, dark, accidental pocket shots get rejected by a cheap CPU check. You will never surface that garbage in a result, so you never pay to understand it.
Only the survivors make it through. I call them keepers.
One vision call per keeper, not per query
Each keeper gets exactly one vision call. That call produces a caption, a set of tags, and a semantic embedding. All of it gets written to the database, attached to that item forever.
Notice the difference. In the naive design, a single photo might get analyzed thousands of times across its life, once per matching query. Here it gets analyzed once, ever.
In my own pipeline, the dedupe and quality gates routinely cut the number of expensive calls by a large margin before any model runs. A library that looks like 10,000 photos is often 6,000 keepers after dedupe and quality filtering. That's 40% of your model spend gone before you start.
This is the same discipline I apply across every system I build: let the cheap, deterministic code do the filtering, and reserve the model for the one judgment call that actually needs intelligence. The model is the expensive specialist. You don't send it the easy stuff.
Why Retrieval Becomes a SQL Filter Plus a Vector Lookup
Once the data is enriched, a query like "find this person on that trip" stops being a model problem and becomes a database problem. Let me decompose it.
 Query decomposition: SQL filter then vector lookup
Query decomposition: SQL filter then vector lookup
The metadata filter narrows first
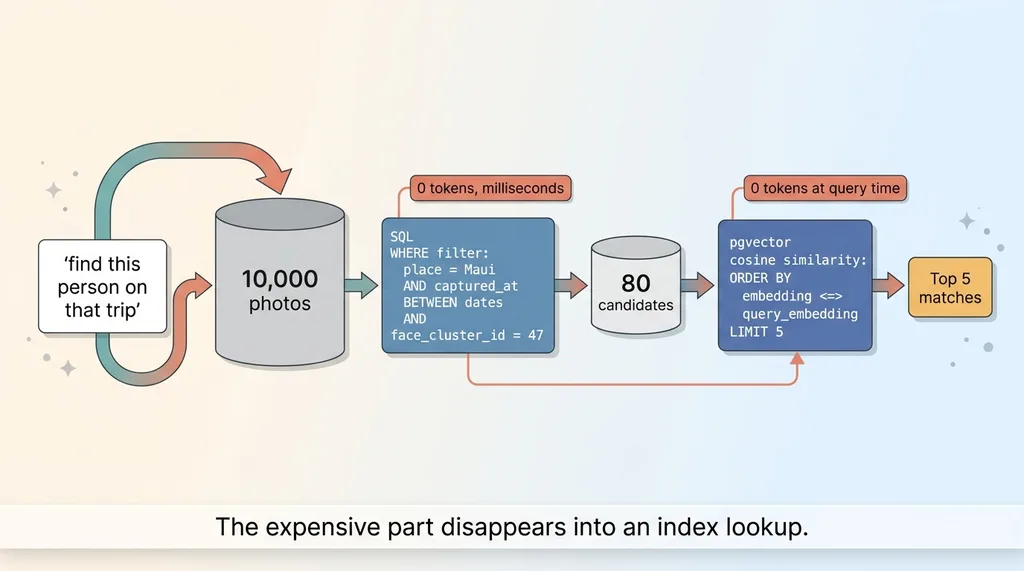
"That trip" means a place and a date range. "This person" means a detected face cluster. All three of those are structured fields sitting in columns.
So the first move is a plain SQL WHERE clause:
WHERE place = 'Maui'
AND captured_at BETWEEN '2024-06-01' AND '2024-06-10'
AND face_cluster_id = 47
Zero tokens. This filter might take you from 10,000 photos down to 80 candidates in a few milliseconds. The expensive part of the problem just disappeared into an index lookup.
The embedding handles meaning
What's left is the fuzzy part. "Beach vibes," "the celebration," "that golden hour shot." Those aren't exact fields. They're meaning, and meaning is what embeddings are for.
This is where pgvector earns its keep. You store the embedding for each keeper in a vector column, build an index on it, and run a cosine similarity search to return the top-K matches:
SELECT id, caption
FROM photos
WHERE place = 'Maui' AND face_cluster_id = 47
ORDER BY embedding <=> query_embedding
LIMIT 5;
That <=> operator is the cosine distance. You're ranking the 80 candidates by how close they are in meaning to the query, and returning the best five. Still no model call at query time. The model already did its work at ingest.
This is the heart of a good RAG indexing strategy, and the thing most teams get backwards: the index is the product, not an afterthought you bolt on later. If you treat the index as a cache you'll someday optimize, you've already lost the cost battle.
The broader principle here is one I keep coming back to: let the model judge and let the code compute. Vector embeddings retrieval is deterministic math over precomputed data. There is no reason to spend a single token to run it.
When You Still Call the Model (And Why It Stays Cheap)
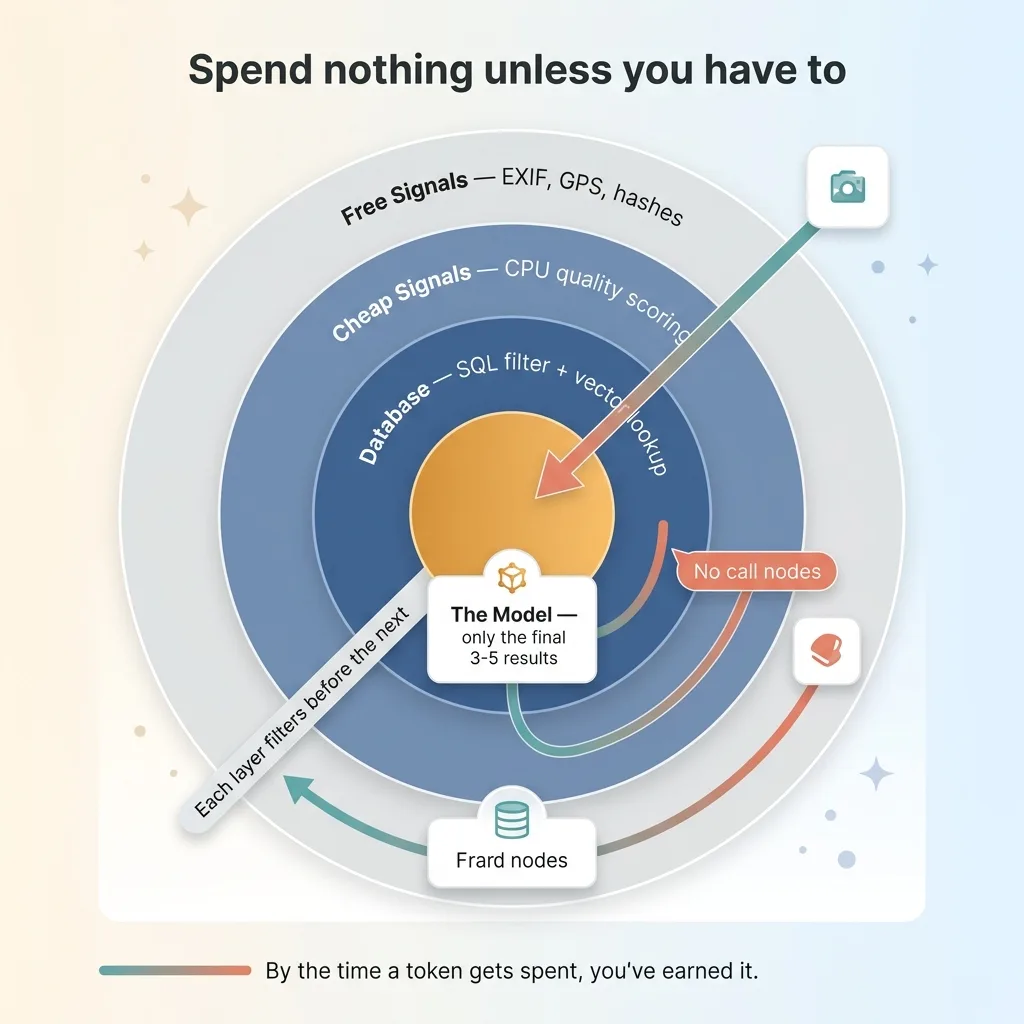
I'm not going to pretend you never touch the model at query time. You do. There are real cases for it:
 Layered 'spend nothing unless you have to' filtering hierarchy
Layered 'spend nothing unless you have to' filtering hierarchy
- Summarizing the top results into a natural-language answer.
- Answering a complex question about the matches ("which of these were taken indoors?").
- Generating a caption for a brand-new upload that just arrived.
The difference is everything. In the naive design you passed 10,000 items to the model. Here you pass the three to five items that survived retrieval. Your cost is bounded by the size of the answer, not the size of the library.
A summary over five captions costs a fraction of a cent. A summary over 10,000 costs a small fortune and won't even fit in the context window. Same feature, two completely different cost structures, decided entirely by what you put in front of the model.
There's a second layer of savings on top of this. Once you've made that first expensive call, you can iterate on AI output for almost nothing after the first run. If a user refines their question or you want to reformat the answer, you're not re-paying the full cost each time. You cache the expensive reasoning and iterate cheaply on top of it.
That's the pattern across every well-built system: layers of "spend nothing unless you have to." Free signals filter before cheap signals. Cheap signals filter before the database. The database filters before the model. And caching filters before re-running the model. By the time a token actually gets spent, you've earned it.
The Cost Curve, Before and After
Let me make this visceral with round numbers.
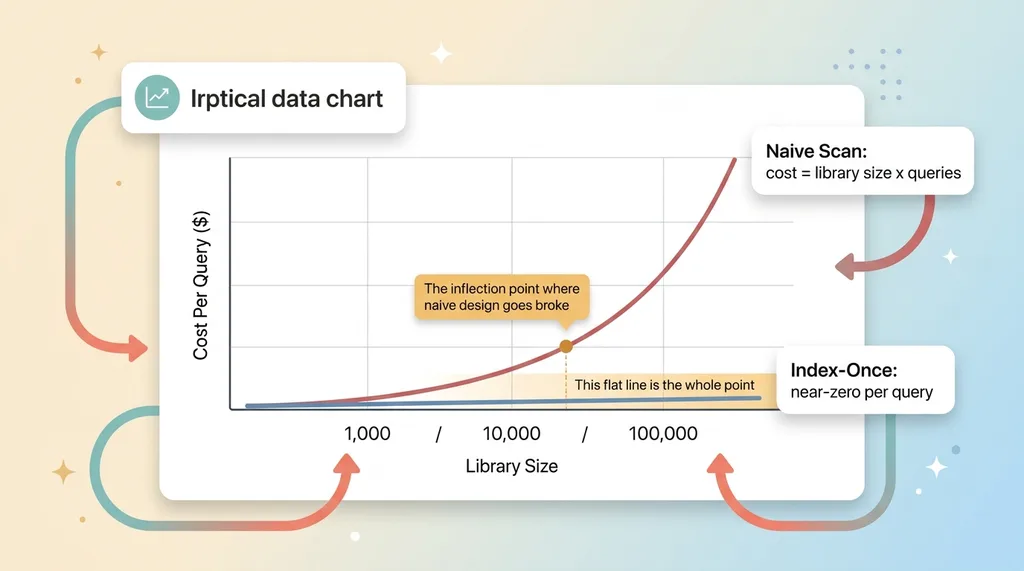 Naive scan vs index-once cost curve
Naive scan vs index-once cost curve
Naive design: cost = library size × queries. Unbounded. Grows with both axes at once.
Index-once design: cost = one-time enrichment (paid as data arrives, then amortized forever) + near-zero per query.
Now watch the inflection point.
At 1,000 items, both approaches look fine. The naive scan is a few dollars per query, annoying but survivable. Nobody notices the problem in a pilot this size. This is exactly why the problem hides.
At 100,000 items, the naive approach is a money pit. A single query scans 100,000 photos. Ten users running ten queries a day will bankrupt the feature. Meanwhile the indexed approach barely moves. You paid to enrich those 100,000 items once as they arrived, and each query still touches five results. The per-query cost at 100,000 items is essentially identical to the per-query cost at 1,000.
That flat line is the whole point.
Now the honest tradeoffs, because there's no free lunch:
- The ingest pipeline is more engineering up front. Dedupe, quality scoring, embedding generation, indexing. That's real work before you ship.
- Embeddings cost storage. Each vector takes space, and at scale that's a real line item, though storage is orders of magnitude cheaper than inference.
- You have to re-enrich if you change your schema. Decide to add a new tag dimension? You may need to re-run ingest across the library.
I'll say it plainly: that up-front complexity is the price of a flat cost curve. It's not optional for anything that intends to grow. You either pay the engineering cost once, at the start, or you pay the inference cost forever, scaling with every user you add.
The Difference Between a Product and a Money Pit
Here's why I'm writing this for you and not just for engineers.
Most AI features die in pilot for exactly one reason: nobody modeled the cost at scale. The team tested on a small dataset where the naive approach looked fine, the demo was beautiful, everyone got excited, and then real data showed up and the bill exploded. The feature got quietly killed and labeled "AI doesn't work for us."
It's one of the most common ways AI projects fail before they ship. The architecture was never built to survive its own success.
The choice between scanning the library and searching an index is the difference between a viable product and one that loses money on every single user you acquire. Same feature. Same model. Completely different business.
And this isn't a photo trick. I apply the same enrich-once, retrieve-cheap pattern across document corpora, asset libraries, support archives, and product catalogs. Anywhere AI has to reason over a large and growing dataset, the math is the same.
If you're building or buying an AI feature that has to work over a large dataset, the cost model needs to be designed before the demo, not discovered after. By the time you see the bill, the architecture is already poured in concrete and ripping it out is expensive.
That's the conversation worth having early. If you want, I'll look at your architecture before you scale and tell you honestly whether your cost curve is flat or whether it's a time bomb.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team. Just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call