How I Connected an Oura Ring to an AI Health Dashboard
A real Oura Ring API integration that feeds sleep, readiness, and activity data into an AI health dashboard. Here's exactly how I built it.
By Mike Hodgen
My mom wears an Oura Ring every day. Has for over a year. She likes the app, checks her sleep score most mornings, and then... nothing happens with that data. The Oura app told her she slept poorly. It didn't tell her why, and it definitely didn't connect the dots to her medication schedule, her specific health conditions, or the patterns her doctors actually care about. That gap — between raw biometric data and personalized, actionable health insight — is what pushed me to build an Oura Ring API integration that feeds her wearable data into an AI health system I'd already been developing.
The problem isn't unique to Oura. It's every wearable. Fitbit, Apple Watch, Whoop — they all collect incredible data and then serve it back to you with generic advice. "You slept 6 hours and 12 minutes. Try to sleep more." Thanks.
No one's doctor is logging into Oura Cloud. No one's cardiologist is checking HRV trends between appointments. That data sits in an app, disconnected from the health context that would make it useful.
The goal was straightforward: pull real biometric data from her Oura Ring and feed it to an AI system that already knows her health history — medications, conditions, lab results, doctor's notes. So the output shifts from "you slept poorly" to something like "your sleep efficiency dropped 12% over the past week, coinciding with the medication timing change on Tuesday — here's what to discuss with your doctor at Thursday's appointment."
Not a diagnosis. A pattern no human would manually catch across months of nightly data.
I'd already built a multi-agent health monitoring system with specialized AI agents covering different domains. The Oura Ring was the missing real-time data source that would make the Sleep Specialist agent actually dangerous — in a good way.
What the Oura Ring API Actually Gives You
Before you build anything, you need to know what the Oura v2 API actually returns. I went in expecting limited data. I was wrong. It's one of the cleaner wearable APIs I've worked with — well-documented JSON responses with genuinely useful granularity.
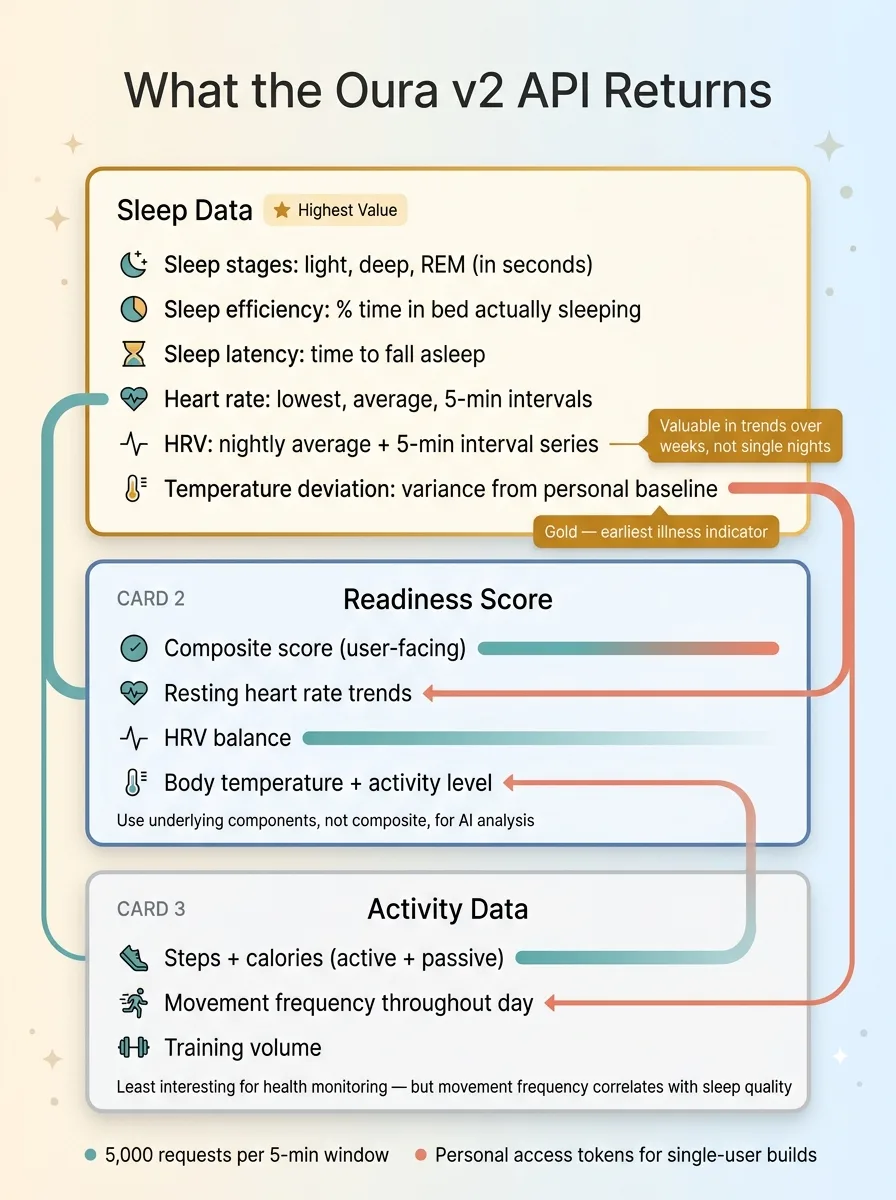 Oura API Data Structure Overview
Oura API Data Structure Overview
Sleep Data Structure
This is where the real value lives. For each sleep session, the API returns:
- Total sleep duration broken into light, deep, and REM stages (in seconds)
- Sleep efficiency — percentage of time in bed actually spent sleeping
- Sleep latency — how long it takes to fall asleep
- Heart rate during sleep — lowest, average, and the full time-series data in 5-minute intervals
- Heart rate variability (HRV) — average for the night, plus the 5-minute interval data
- Respiratory rate — breaths per minute
- Temperature deviation — how far body temp deviated from the personal baseline
That temperature deviation data is gold. It's one of the earliest indicators of illness onset, and for tracking medication effects, it's more reliable than self-reported symptoms. A consistent +0.3°C deviation over several nights tells you something is changing physiologically before the person feels it.
HRV is the other standout, but with a caveat: daily HRV snapshots are nearly meaningless. The value is in trends over weeks. A single night of low HRV means nothing. Three weeks of declining HRV average tells a story.
Readiness and Activity Scores
Readiness score is Oura's composite metric combining recovery indicators: resting heart rate trends, HRV balance, body temperature, previous day's activity level, and sleep quality. The API gives you both the composite score and the contributing factors, which is what you actually want. The composite score is fine for a user-facing summary, but for an AI agent doing pattern analysis, the underlying components are far more useful.
Activity data covers steps, total calories burned (active + passive), movement frequency throughout the day, and training volume. Honestly, the activity data is the least interesting part for my use case. My mom isn't training for a marathon. But movement frequency — how often she's getting up and moving versus staying sedentary — turned out to matter for correlating with sleep quality.
Rate Limits and Gotchas
Rate limits are generous: 5,000 requests per 5-minute window. For a single-user dashboard pulling daily data, you'll never come close. I make about 4 API calls per sync — sleep, readiness, activity, and heart rate — once per day.
Authentication: personal access tokens work fine for a single-user build like this. You generate one in the Oura developer portal and you're done. If you were building a multi-user product, you'd need the full OAuth2 flow, which adds complexity but is standard.
The gotcha that caught me: data isn't available until several hours after waking. Oura processes the previous night's data on-device and syncs it to their cloud, but there's a lag. My first cron job ran at 6 AM and got nothing. Moving it to 10 AM solved it. If your user wakes up late, you might need a retry mechanism. I added a simple one — if the sleep data for the expected date isn't there, retry in two hours, max three attempts.
The Pipeline: Oura to Database to AI
The architecture is simple on purpose. I've built enough systems to know that over-engineering the plumbing is how projects die. No Kafka. No event streaming. No microservices. A cron job, an API call, a database write, and an agent trigger.
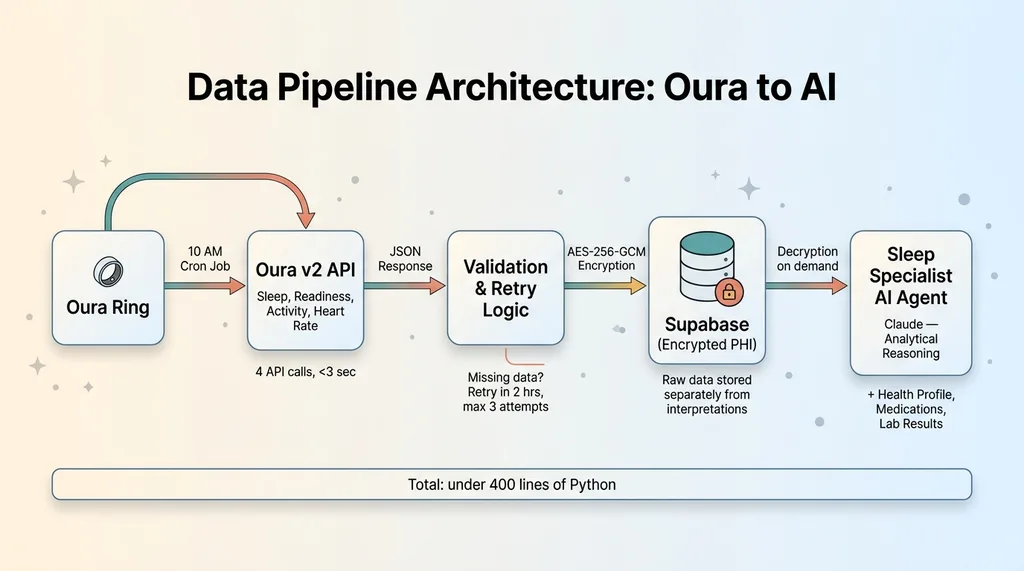 Data Pipeline Architecture: Oura to AI
Data Pipeline Architecture: Oura to AI
Nightly Data Sync
A Python script runs on a scheduled cron at 10 AM Pacific. It pulls the last 24 hours of sleep, readiness, and activity data from the Oura API. The script validates the response — confirms the expected date's data is present, checks for null fields that would indicate a partial sync — and either writes to the database or schedules a retry.
Total sync time: under 3 seconds. The Oura API responds fast.
Storage and Encryption
This is real health data. Even for a family project, I treat it like PHI. All biometric data is encrypted with AES-256-GCM before it hits the database. I wrote about the full approach in encrypting health data in Supabase — the short version is that data is encrypted at the application layer before storage, so even a database breach exposes nothing readable.
Encryption keys are managed separately from the database. The data at rest is ciphertext. The AI agent decrypts only what it needs, when it needs it, for the duration of the analysis.
Feeding the Sleep Specialist Agent
Here's where it gets interesting. The Sleep Specialist is one agent in a multi-agent health architecture I built. Each agent has a domain — sleep, cardiology, medications, nutrition, and so on. The Sleep Specialist receives the Oura data as structured context alongside the patient's existing health profile: current medications, known conditions, recent lab work, and historical sleep data.
One key design decision: I store the raw Oura data and the AI's interpretation separately. This matters. As the AI's understanding of the patient improves over time — more data, refined health context, updated medication lists — I want it to re-analyze historical data with fresh eyes. If you only store the interpretation, you lose the ability to get better retrospectively.
The multi-model architecture handles which AI model does what. The Sleep Specialist uses Claude for the analytical reasoning and recommendation generation. Different models handle different aspects based on what they're best at.
Total code for the entire pipeline: under 400 lines of Python. The real complexity isn't the plumbing. It's teaching the AI what matters in the data for THIS specific person — which metrics to weight, which patterns to flag, and which correlations are noise versus signal given her particular health context.
How Biometric Data Changes AI Health Recommendations
This is the part that matters. Not the architecture, not the API calls. The actual difference in output quality when an AI health agent has real biometric data versus operating without it.
Generic vs. Personalized
Before the Oura Ring API integration, the AI health team worked with self-reported symptoms, medication lists, and lab results uploaded after doctor visits. The advice was accurate but generic. "Aim for 7-8 hours of sleep." "Stay hydrated." "Report any new symptoms to your doctor." All true. All useless.
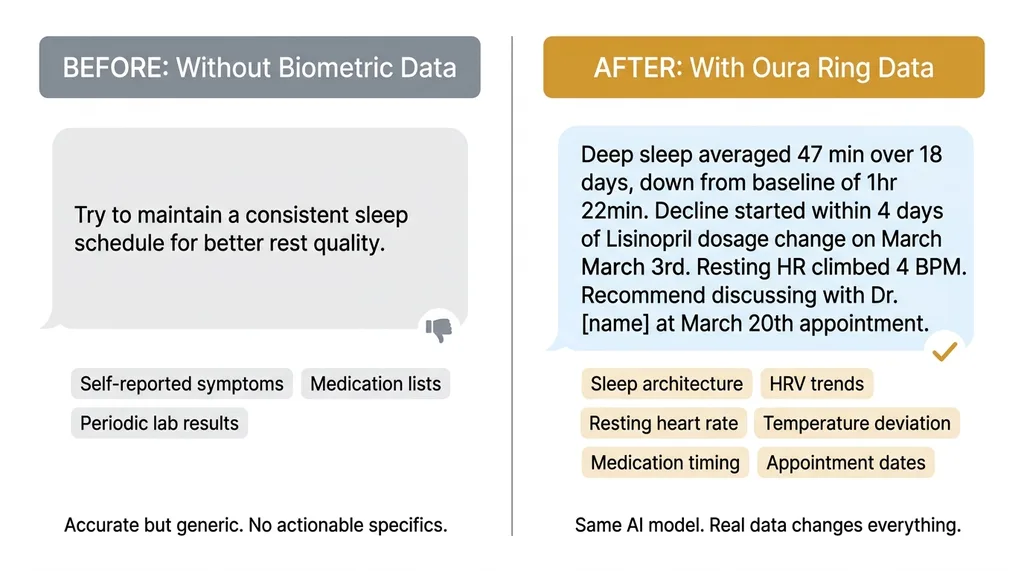 Generic vs. Personalized AI Health Output
Generic vs. Personalized AI Health Output
After integration, the AI sees actual sleep architecture, not self-reports. My mom would say "I slept okay" on a night where her deep sleep was 38 minutes (her baseline is 1 hour 20 minutes) and her resting heart rate was 6 BPM above trend. "Okay" to her meant she didn't consciously wake up. The data told a completely different story.
The AI went from generic to specific:
Before: "Try to maintain a consistent sleep schedule for better rest quality."
After: "Deep sleep has averaged 47 minutes over the past 18 days, down from your 3-month baseline of 1 hour 22 minutes. This decline started within 4 days of your Lisinopril dosage change on March 3rd. Resting heart rate has climbed 4 BPM over the same period. Recommend discussing both trends with Dr. [name] at your March 20th appointment — specifically whether the timing or dosage adjustment could be contributing."
Same AI. Same reasoning model. Radically different output because of real data.
A Real Example: Catching a Pattern
Here's one that convinced me this was worth building. Over about six weeks, the system noticed that her HRV consistently dropped on the day following any night where sleep efficiency fell below 78%. Not surprising on its own. But the AI correlated those low-HRV days with her self-reported fatigue scores from a simple morning check-in I added later. The correlation was tight — 87% of days where she reported fatigue above 6/10 were preceded by sub-78% efficiency nights AND followed by HRV drops of 8ms or more.
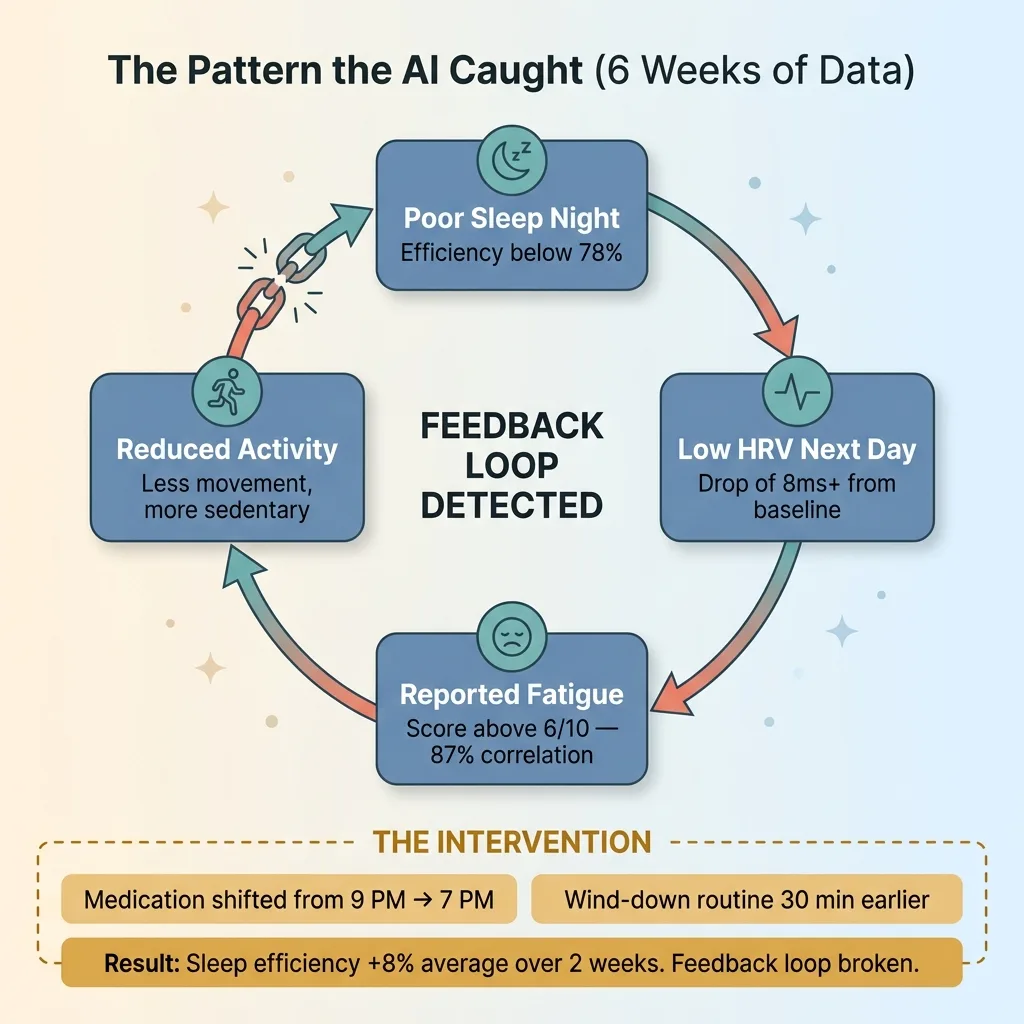 Feedback Loop Pattern Detection
Feedback Loop Pattern Detection
The AI mapped the chain: poor sleep → low HRV → reported fatigue → reduced activity → another poor sleep night. A feedback loop.
The recommendation was specific and modest: shift her evening medication from 9 PM to 7 PM (based on research about that drug's half-life and sleep architecture impact), and start her wind-down routine 30 minutes earlier. She made both changes. Over the next two weeks, sleep efficiency improved by 8% on average, and the low-HRV-to-fatigue chain broke.
I want to be honest about the limitations. The AI didn't diagnose anything. It didn't prescribe anything. It surfaced a pattern across data streams that no human — not her, not me, not her doctor in a 15-minute appointment — was going to manually cross-reference across 42 days of nightly biometric data, medication timing logs, and self-reported symptoms. It generated a question for her doctor, who confirmed the medication timing adjustment was reasonable.
That's the value. Continuous monitoring and correlation across months of data, producing specific talking points for medical professionals. Not replacing them.
What I'd Do Differently (And What's Next)
What worked: The simple pipeline. Storing raw data for re-analysis. Keeping the AI firmly in an advisory role. The restraint to not over-engineer the infrastructure paid off — the whole system was functional within a weekend.
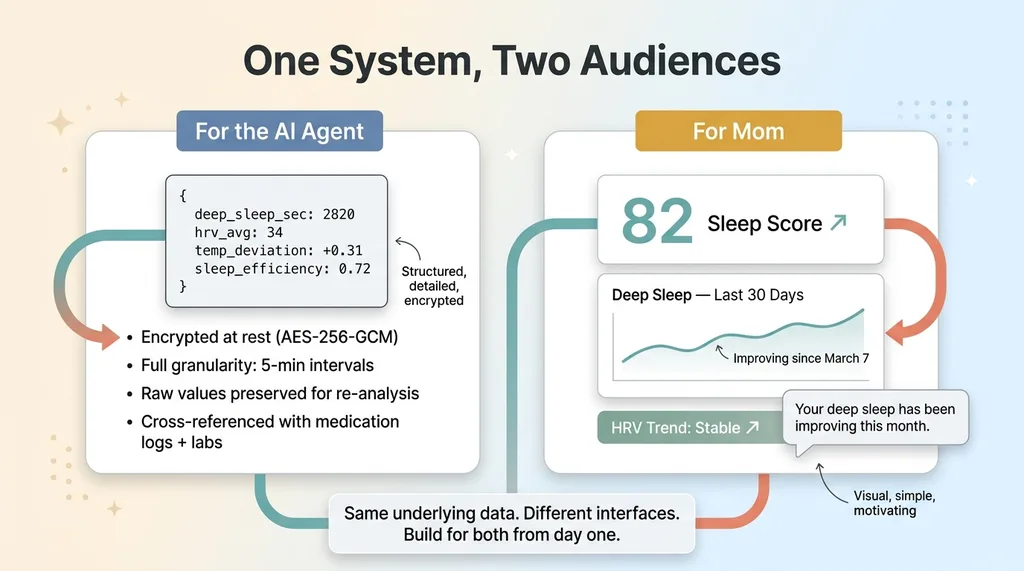 Two-Audience Dashboard Design
Two-Audience Dashboard Design
What I'd change: I'd add a daily health check-in component from day one. I bolted it on later, and it immediately improved the AI's output quality. Oura data is objective but incomplete. A 2-minute morning questionnaire — mood (1-10), energy (1-10), any new symptoms, pain level — gives the AI the subjective context it needs to interpret the biometric data properly. Sleep efficiency of 72% means something different on a day she reports feeling great versus a day she reports brain fog. I should have started with both data streams.
I'd also add trend visualization sooner. I built a data pipeline, but my mom doesn't care about the AI's reasoning chain. She wants to see a graph showing her deep sleep improving over the past month. The dashboard needs to serve two audiences: the AI (structured data, encrypted, detailed) and the human (visual trends, simple, motivating). I built for the AI first. I should have built for both simultaneously.
What's next: Lab result integration. When bloodwork comes back, I want the AI to correlate changes in things like thyroid levels or inflammation markers with biometric trends from the same period. That correlation — bloodwork plus 90 days of continuous biometric data — is where the real insight will come from.
I'm also exploring whether Apple Health data can supplement Oura for daytime metrics. Oura is primarily a sleep and recovery device. Daytime heart rate, blood oxygen, and activity data from an Apple Watch would fill the gap between waking and sleeping hours.
Building Health AI Systems That Actually Help People
The pattern here — connect a data source, store it securely, feed it to a specialized AI agent with domain context — applies far beyond health. But health is where the stakes make it worth getting right. Where lazy engineering or sloppy data handling has real consequences.
The difference between a toy project and something useful is whether it changes a real person's behavior or health outcome. This one did. My mom's sleep is measurably better. Her doctor has better data to work with. She caught a medication interaction pattern that might have gone unnoticed for months.
For anyone considering building with wearable APIs: start with one data source, one user, one specific question you want the AI to answer. Don't try to build a platform. Don't think about scale. Build a tool that helps one person with one problem. The Oura Ring API integration I built serves exactly one person, and it's one of the most impactful things I've built with AI.
This is the same approach I take with businesses. Not health dashboards specifically, but AI systems that connect real data to real decisions. If your company has data sitting in apps that never talks to each other — your CRM doesn't know what your inventory system knows, your customer service team can't see what your ops dashboard shows — that's the same problem. Disconnected data, generic outputs, and no one doing the cross-referencing.
Thinking About AI for Your Business?
If any of this resonated — whether it's the data integration problem, the gap between having data and getting insight from it, or just the idea of building AI systems that actually do something useful — I'd be happy to talk through what that looks like for your business. I do free 30-minute discovery calls where we dig into your operations and figure out where AI could make a real, measurable difference.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call