How to Reduce AI API Costs: Cache the Thinking
Most teams re-run the whole AI pipeline on every tweak. Here's how I reduce AI API costs by caching the expensive reasoning so iteration is free.
By Mike Hodgen
The bill that scared a CEO off experimentation
I was building an AI product that runs a multi-agent pipeline to produce a finished, designed output. Think concept to polished piece, all the reasoning and assembly handled by a chain of model calls.
And every time I tweaked the layout or adjusted a style, the whole pipeline fired again from scratch.
The model re-did work it had already done. It re-made the same selections, re-wrote the same copy, re-generated the same source assets, all to hand me a slightly different arrangement of identical material. At one point I re-rendered an entire finished piece three times just to fix two text-legibility bugs. I paid full model cost each time for zero new thinking.
That is the moment where most CEOs flinch. If you want to reduce AI API costs, you first have to confront the assumption that's quietly killing your spend: that every iteration of an AI feature costs real money, so experimentation is something you ration.
I see it constantly. A team ships an AI feature, watches the bill climb, and decides that touching it is expensive. So they stop iterating. The product stops improving. The thing that was supposed to make them faster makes them cautious.
Here's the part nobody tells you. That cost is almost never a law of nature. It's a design flaw.
The expensive thinking in an AI pipeline should happen once. The refinement afterward, the layout tweaks and the style adjustments and the legibility fixes, should be free. When you bundle those two things together, you pay full price for every cosmetic change. When you separate them, you stop paying for thinking you already did.
That single split is the biggest lever I know for cutting generative pipeline costs. Let me show you exactly how it works.
Why most AI pipelines re-pay for the same work
A typical generative pipeline bundles two completely different kinds of work into one run. Once you see the difference, you can't unsee it.
There's the reasoning: which items to select, what story or structure to build, what captions and copy to write, generating any source assets like background images. Every bit of that is a model call. That's the expensive part.
Then there's the rendering: taking all that decided material and arranging it into a specific layout with specific typography, spacing, and styling. That part is cheap, deterministic code. No model required.
The reasoning costs real money. The rendering costs basically nothing.
The pipeline doesn't know what changed
The problem is that most pipelines have no memory. When you ask for a font-size change, the pipeline doesn't know that's all you changed. It just re-runs the whole thing.
So it re-makes every selection. Re-writes every caption. Re-generates every asset. Then it arranges the freshly-redone material into the layout with the bigger font.
A cosmetic tweak costs exactly the same as a fresh start. The pipeline can't tell the difference because it never recorded what it decided the first time. The reasoning evaporates the instant the run finishes.
Reasoning and rendering get tangled together
This is the single most common way I see teams burn credits. They build the pipeline as one continuous run because that's the obvious way to build it. Concept goes in, finished piece comes out, and every step in between is wired together.
It feels clean. It's a disaster for cost.
And this isn't an exotic problem. It shows up in any expensive generative pipeline. Document generation that re-writes the whole document to fix a heading. Image composition that re-generates every layer to nudge one element. Report writing that re-runs all the analysis to change a chart color.
Same disease every time: the expensive reasoning and the cheap rendering live in one inseparable run, so you pay model prices for decisions the model already made.
The fix: separate the reasoning from the rendering
The fix is to split the pipeline into two modes.
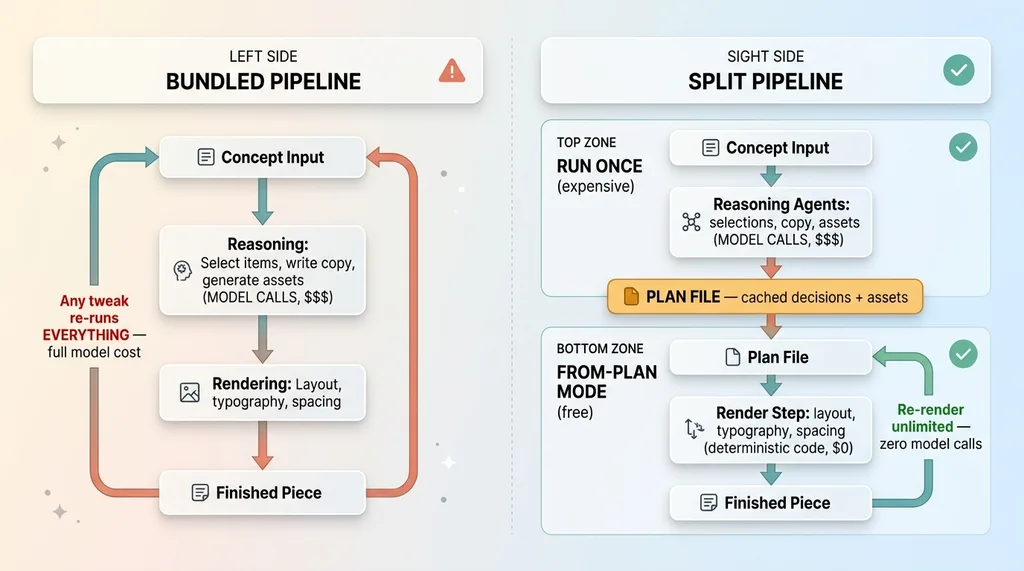 Bundled vs. Split Pipeline (the core fix)
Bundled vs. Split Pipeline (the core fix)
One mode does all the expensive thinking once. The agents make their selections, build the structure, write the captions, and generate any source assets. This is the real run, and yes, it costs real model money. That's fine. We only do it once.
Then I persist every one of those decisions and every generated asset to a plan file. The plan file is the cached output of the expensive reasoning. It's the model's brain, frozen in place.
The second mode is a from-plan mode. It takes that saved plan and re-renders any layout or style change using only the cached material. Zero further model calls. The reasoning is already done and sitting in the file, so the render step just reads it and arranges it.
This is the same principle I keep coming back to in every system I build: let the model judge and let the code compute. The model's job is judgment. The code's job is everything deterministic. When you keep those jobs separate, you stop paying model prices for code work.
It's also the same pattern I used when I stopped calling the AI at runtime in another system entirely. Do the expensive thinking ahead of time, cache it, and serve from the cache.
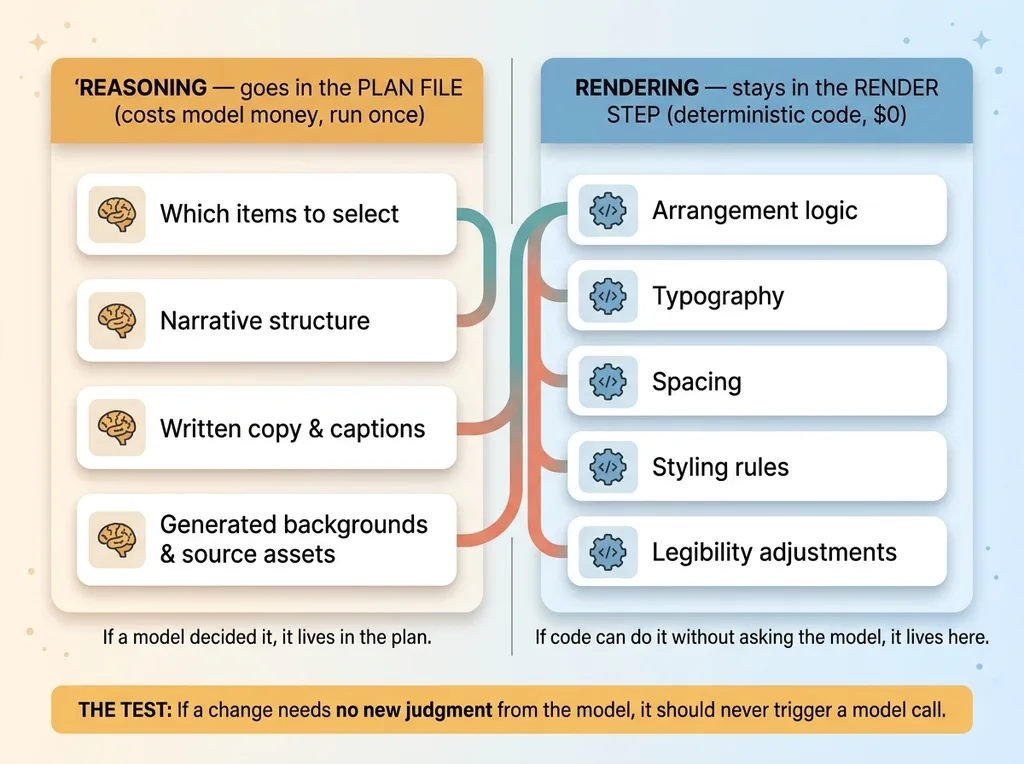
What goes in the plan file
The plan holds everything that required judgment. The selections the agents made. The narrative structure they built. The written copy and captions. The generated backgrounds and source assets.
If a model decided it, it lives in the plan.
What stays in the render step
The render step holds everything deterministic. The arrangement logic. The typography. The spacing. The styling rules. The legibility adjustments.
 Reasoning vs. Rendering split, what goes where
Reasoning vs. Rendering split, what goes where
If code can do it without asking the model anything, it lives in the render step.
Here's the test I use, and it's the whole thing in one sentence. If a change doesn't require new judgment from the model, it should never trigger a model call. Bigger font? No new judgment. Different background color? No new judgment. Re-render from the plan, free. The moment you find yourself triggering a full pipeline run for a change like that, you've found the leak.
What this actually saved
Back to those two text-legibility bugs.
After the split, fixing them cost nothing. I re-rendered the entire finished piece three times to dial in the layout, and not one of those re-renders touched the model. The plan file already held every decision and every asset. The render step just read them and laid them out differently each time.
Before the split, each full re-run cost real credits and several minutes of waiting. After, refinement was instant and free.
I'm not going to pretend the first run got cheaper. It didn't. The expensive reasoning still costs what it costs. What changed is that the expensive run now happens once per piece of real work, and all the fiddling afterward is free.
That's the honest math. You don't eliminate the cost of thinking. You stop paying it over and over for the same thoughts.
Here's a mental model for your own spend. Count how many of your AI feature's runs are genuinely producing new reasoning versus re-rendering decisions the model already made. In most pipelines I audit, the majority of runs are the latter. People re-running the whole machine to adjust presentation.
The reasoning-rendering split is the biggest single cost lever I know, but it's not the only one. There's also searching the index, not the library, which cuts spend a different way by not feeding the model more than it needs to answer. Different lever, same goal. But if I could only fix one thing in most pipelines, it would be this split.
When caching the plan is the wrong move
Now the honest part, because plan caching is not a magic wand and treating it like one will burn you.
 Decision: when to cache vs. re-run (the line)
Decision: when to cache vs. re-run (the line)
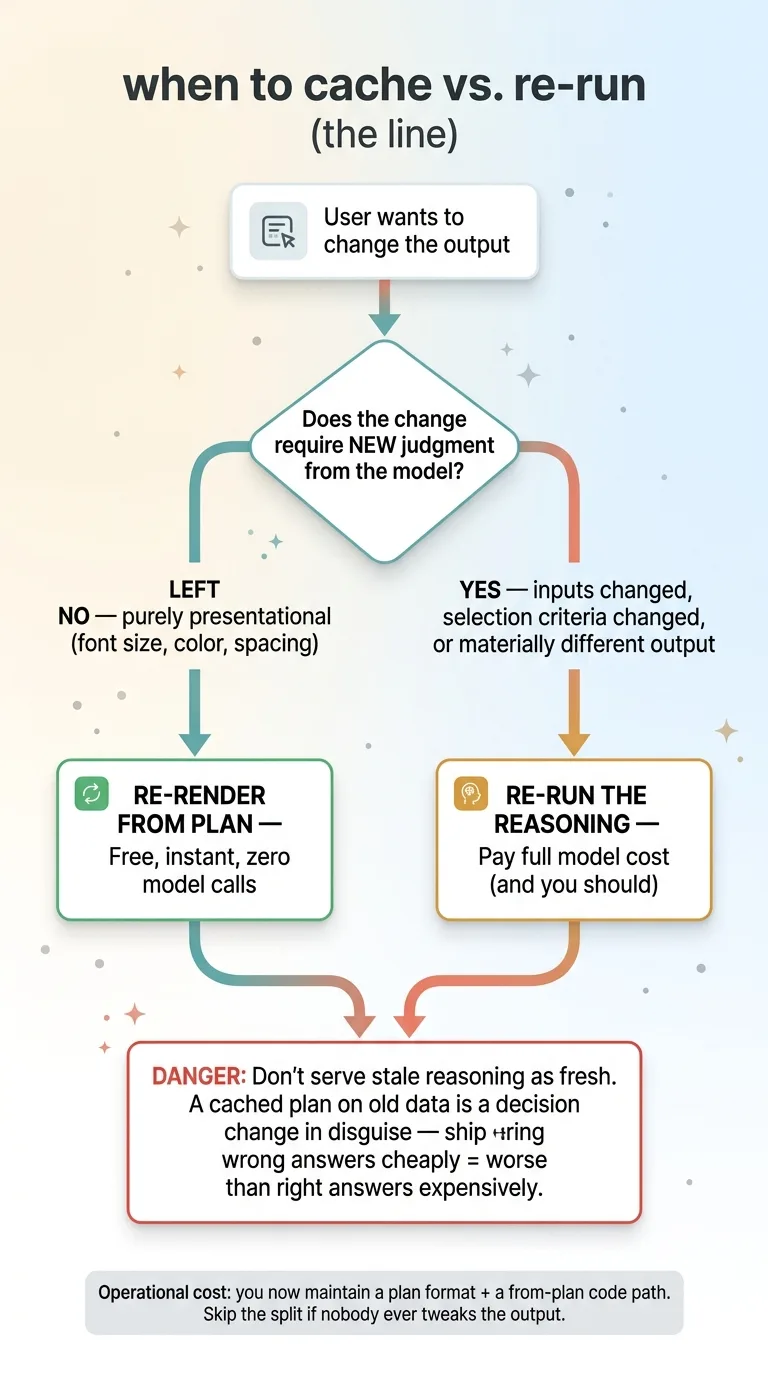
Plan caching only works when the reasoning is genuinely stable and the change is purely presentational. That's the entire condition. If the underlying inputs change, if the selection criteria change, or if the user wants a materially different output, you have to re-run the expensive part. And you should.
The failure mode here is real. Don't cache stale reasoning and serve it as if it were fresh. That's how you ship wrong answers cheaply, which is worse than shipping right answers expensively. A cached plan based on last week's data is not a presentation change. It's a decision change wearing a disguise.
The discipline is knowing exactly where the line sits. Presentation change, free re-render from the plan. Decision change, re-run the reasoning. Get that line wrong and you either overpay or you serve garbage.
There's also an operational cost I won't hide from you. Once you split the pipeline, you maintain a plan format and a from-plan code path. That's real engineering. Two modes to test, a file format to version, a render step that has to faithfully reconstruct from cached material.
For pipelines that almost never get re-rendered, the split may not be worth building. If your AI feature produces something nobody ever tweaks, you don't have an iteration problem, so don't solve one.
The point is to make the choice deliberately. Don't cache everything by reflex, and don't refuse to cache out of inertia. Look at how your feature actually gets used and decide on purpose.
How to find this leak in your own AI feature
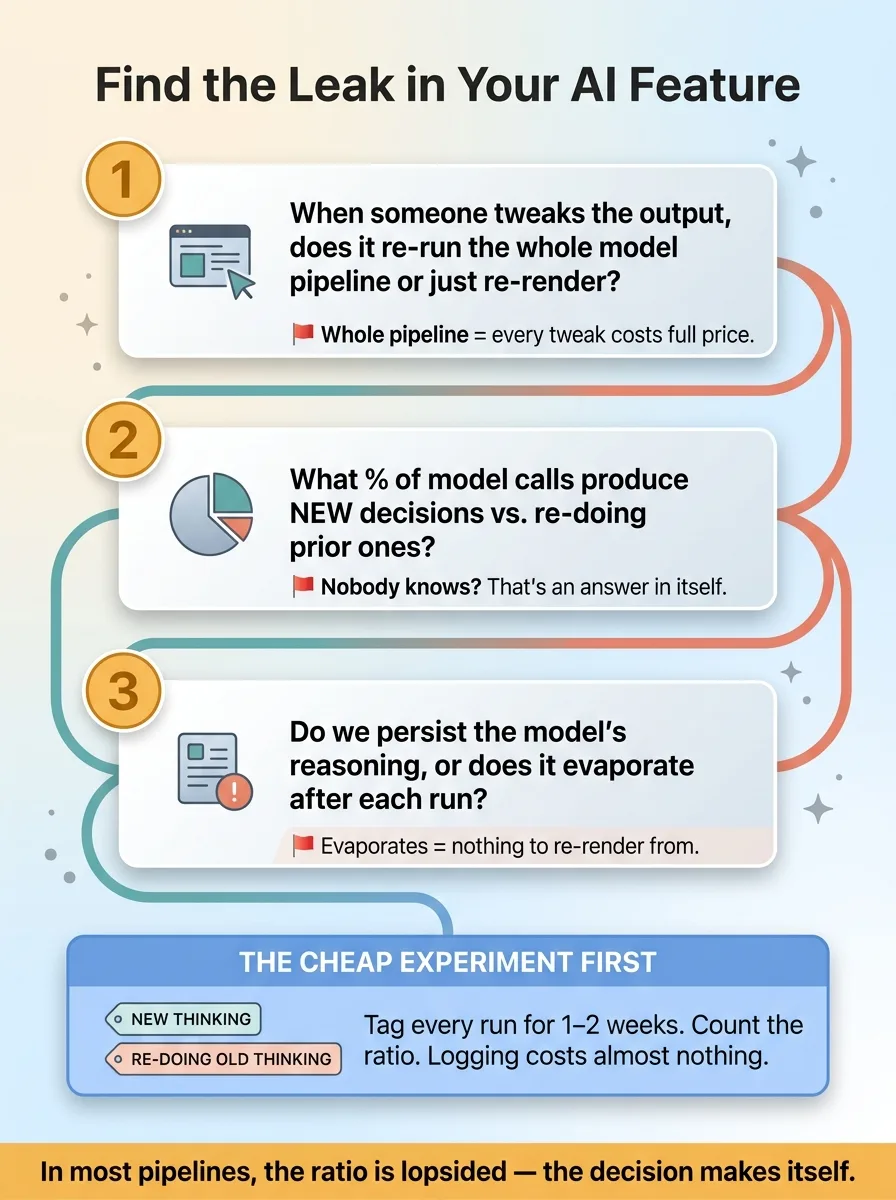
You don't need to be technical to find this. You need three questions and the discipline to ask them.
 Three diagnostic questions + the cheap logging experiment
Three diagnostic questions + the cheap logging experiment
Three questions to ask your team
One: when someone tweaks the output of our AI feature, does it re-run the whole model pipeline or just re-render? If the answer is "the whole pipeline," every tweak is costing you full price.
Two: what percentage of our model calls produce genuinely new decisions versus re-doing prior ones? If nobody knows, that's an answer in itself.
Three: do we persist the model's reasoning anywhere, or does it evaporate after each run? If it evaporates, you can never re-render cheaply because there's nothing cached to re-render from.
If your team can't answer these cleanly, that's the leak. Not maybe. That uncertainty is the symptom.
The cheap experiment first
Before anyone redesigns anything, do the cheap thing. Instrument the pipeline to log which runs were full reasoning runs versus cosmetic re-runs.
Just count them. For a week or two, tag every run as "new thinking" or "re-doing prior thinking." Then look at the ratio.
You can't fix a cost you can't see, and most teams have never measured this. They feel the bill climbing but they have no idea what fraction of it is genuinely necessary. The logging costs you almost nothing and it tells you whether the split is worth building before you spend a dollar building it.
In my experience the numbers are usually lopsided enough that the decision makes itself. When most of your runs are re-doing old thinking, the case for caching the plan is obvious.
Cheap experimentation is a design choice, not a budget line
Let me go back to the fear I opened with, because it deserves a straight answer.
The worry that every iteration of an AI feature costs real money is completely justified, but only when the pipeline is built carelessly. It's a property of bad architecture, not of AI itself.
When the expensive thinking runs once and refinement is free, experimentation stops being something you ration. It becomes something you do constantly. You tweak, you re-render, you tweak again, all for nothing. And constant cheap iteration is exactly how good AI products get good. Nobody ships great output on the first try. They ship it on the fortieth, after thirty-nine free re-renders.
That's the difference between an AI feature your team is afraid to touch and one they improve every single day.
This is the kind of design decision I make in every system I build. Figure out which part is expensive, run it once, and make everything downstream cheap. It's not clever. It's just discipline applied to the question of what actually costs money and what only looks like it does.
If your AI spend is climbing and you genuinely can't tell whether you're paying for new thinking or re-paying for old thinking, that's worth a look. Most of the time the answer is sitting in a pipeline that forgot to remember what it already decided. See where your AI spend is leaking.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call