AI Vector Search Cost Optimization: Index, Don't Re-Read
AI vector search cost optimization done right: enrich your corpus once into a searchable index, then answer every query for pennies instead of dollars.
By Mike Hodgen
The Naive Way Costs a Fortune (And Most People Build It Anyway)
Here's the mistake I see constantly. Someone wants AI to answer questions over a big pile of stuff. Ten thousand product photos. A legal case with 4,000 documents. A knowledge base that's grown for a decade. So they wire it up the obvious way: every time a question comes in, they pipe the whole corpus, or large chunks of it, to a model and ask it to figure out the answer.
It works. The demo looks great. Then the bill arrives.
This is where ai vector search cost optimization stops being a nerdy engineering topic and starts being a business survival topic. Because the naive approach has a fatal flaw: cost scales with the size of your library, not the size of your answer.
Think about what that actually means. If each query reads even a fraction of the library, you pay model token costs for that read. Every question. Forever. The model doesn't remember it answered something similar yesterday. It re-reads. It re-pays.
Run the math on a few hundred queries a day. Say each one chews through a slice of your corpus. You're now burning real money answering questions you've effectively answered before, over a library that barely changed since this morning.
I've watched founders get an AI quote and go pale. Not because the technology was wrong, but because the architecture guaranteed the cost would climb with usage. The more people used the feature, the worse the unit economics got. That's backwards. A feature should get cheaper to serve as you scale, not more expensive per query.
The frustrating part is that the expensive version is almost always the first one built, because it's the obvious one. You have a pile of stuff and a smart model, so you hand the pile to the model.
There's a better pattern. You pay the expensive cost once, then answer everything cheaply after. Let me show you how it works.
The Fix: Enrich Once, Search Forever
The pattern is simple to say and powerful in practice: pay the expensive AI cost one time to turn each item into structured, searchable data. Then answer every future question with a cheap database filter plus a vector lookup. The model never touches your raw library again at query time.
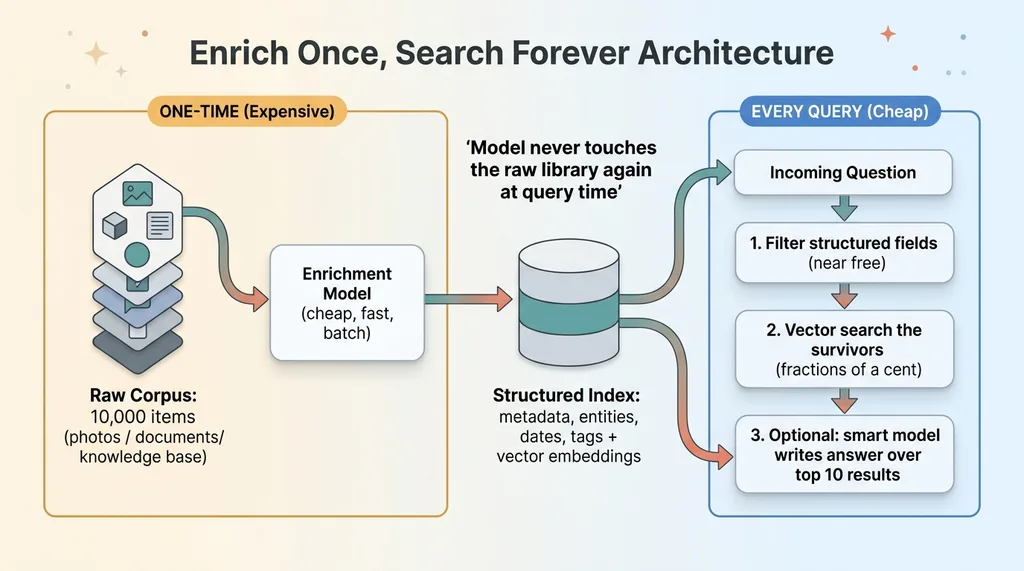 Enrich Once, Search Forever Architecture
Enrich Once, Search Forever Architecture
I call this the library-first approach, and it's the same principle behind why I stopped calling the AI at runtime wherever I could.
What "enriching" actually means
Enriching means running each item through a model once and storing what comes back.
For photos: I run each image through a vision model a single time and extract a description, the objects in frame, dominant colors, the scene, the mood. I store that text, and I store an embedding of it (a numerical fingerprint that captures meaning).
For documents: I extract entities, dates, key facts, and a summary, then break the document into chunks and embed each one. Now every passage is searchable by meaning, not just keyword.
This is the expensive step. You pay it once, in a batch, up front.
What a query looks like after
After enrichment, a question becomes three cheap moves.
First, filter the structured fields. Date range, type, tag, category. This is a normal database query and it's effectively free.
Second, vector-search the survivors. Out of whatever passed the filter, find the handful that match the meaning of the question.
Third, and only if you need a written answer, hand the top five to ten results to a model and ask it to compose the response.
So "find the candid outdoor shots from the afternoon" stops being a 10,000-image read. It's a filter (afternoon, outdoor) plus a vector match (candid). The model, if it's involved at all, sees ten items, not ten thousand.
Cost now scales with the answer (a handful of items), not the library (thousands). That single inversion is the whole game.
The Cost Math That Makes This Obvious
Let me put rounded, illustrative numbers on it so the economics are unavoidable.
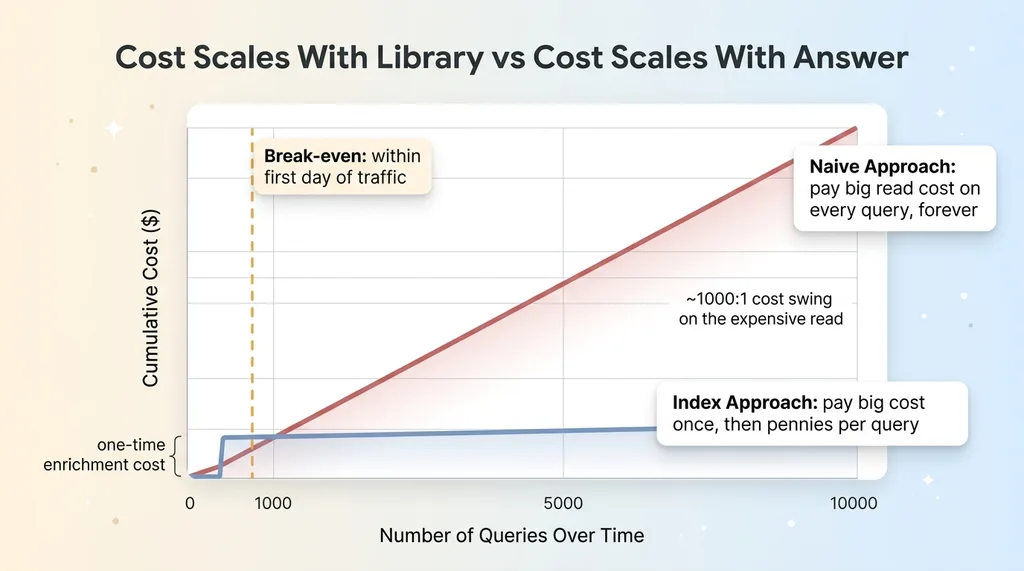 Naive vs Index Cost Curves
Naive vs Index Cost Curves
Say you have 10,000 items. Enriching all of them is a one-time batch job. You pay it once, and then it's done. Call it a fixed cost you swallow on day one.
Now look at what each query costs after that. A database filter is essentially free. An embedding lookup is fractions of a cent. And if you need a written answer, you're running one small model call over ten results instead of ten thousand. The difference between reading ten items and reading ten thousand is roughly a thousand-to-one swing on the expensive part of the bill.
Compare the two cost structures directly:
- Naive approach: pay the big read cost on every single query, forever.
- Index approach: pay the big cost once, then pay pennies per query, forever.
Break-even arrives almost immediately. Within the first day of real traffic, the index approach has already won, and from there the gap widens with every query.
People also overestimate the cost of embeddings. They're cheap to generate and cheaper to store than most teams expect. Storing 10,000 embeddings is not a budget line that should scare anyone.
There's a second benefit that compounds. Once the index exists, you can iterate on AI output for nearly nothing. Want to reword the answers, change the format, tune the tone, try a different prompt? You're operating over your cheap index, not re-reading the library. Experimentation that would've been prohibitively expensive becomes basically free.
One honest caveat: enrichment quality matters far more than enrichment cost. The one expensive step is the one you should not cheap out on. If your vision model writes lazy descriptions, every downstream query inherits that laziness. Spend properly on the step you only pay for once.
The Same Pattern, Three Different Corpora
I've built this exact architecture across wildly different domains. The subject matter changes completely. The pattern doesn't move an inch.
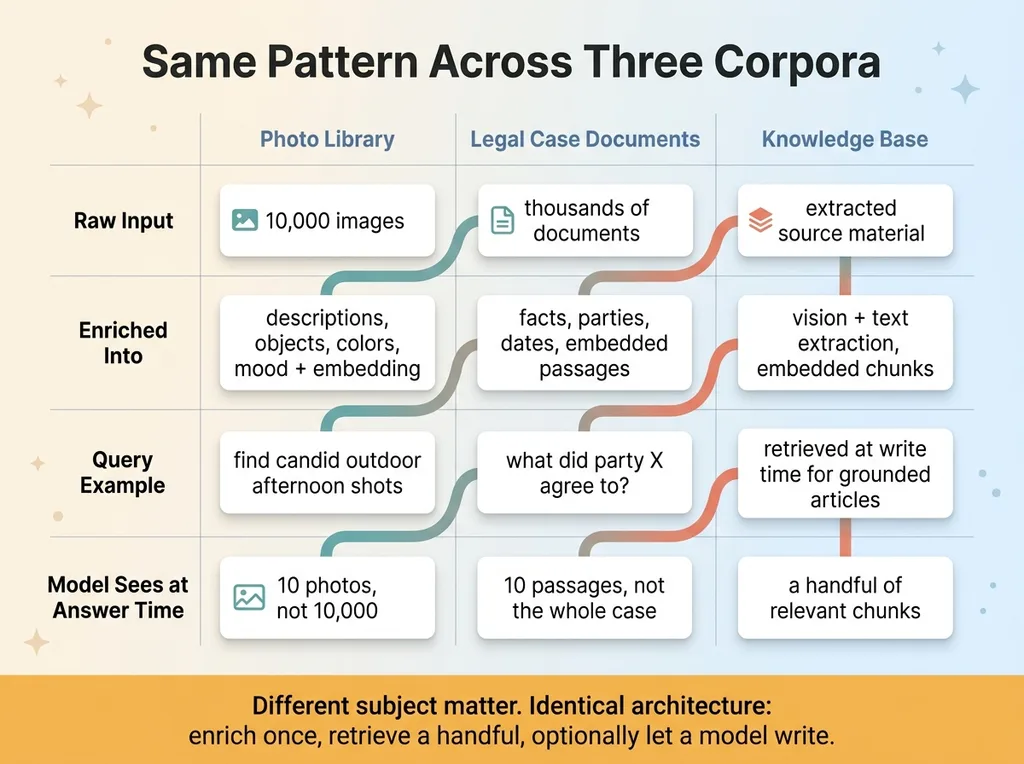 Same Pattern Across Three Corpora
Same Pattern Across Three Corpora
A media library you can ask questions of
One project was a consumer product that builds curated photo collections. The naive version would have a model squinting at 10,000 photos on every single request, which is exactly the cost trap I described up top.
Instead, every photo got enriched once into searchable metadata and an embedding. Now "find the candid outdoor shots from the afternoon" is a filter plus a vector query. The vision model already did its work, once, months ago. Each new request rides on that single investment.
A case brain for thousands of documents
Another was a legal-case knowledge system sitting on thousands of documents. Lawyers ask the same file the same kinds of questions over and over, which is the textbook setup for this pattern.
Each document was enriched once into facts, parties, dates, and embedded passages. A question gets answered against the index, not by re-reading the file every time someone needs it. The model sees the ten most relevant passages, not the entire case. The answer is faster and the cost per question drops to near nothing.
A knowledge base that actually knows things
A third was a domain knowledge base feeding content generation. Source material got extracted once through vision and text extraction, then retrieved at write time so generated articles are grounded in real expertise instead of generic filler.
The architecture is identical across all three: photos, legal documents, knowledge bases. Enrich once into structured, embedded data. Retrieve a handful at query time. Optionally let a model write the final answer over that handful.
What ties it together is using the right model for each job. I use different models for different jobs deliberately here: a cheap, fast model handles the bulk enrichment, and a smarter, more expensive model only shows up at answer time, working over ten items instead of ten thousand. You spend big-model money where it's actually worth it, and nowhere else.
Where This Pattern Breaks (And What I Do About It)
This isn't magic, and I'd rather tell you the limits than have you discover them in production. There are three real ones.
 Where the Pattern Breaks and the Fixes
Where the Pattern Breaks and the Fixes
Stale index. The moment your library changes, your index is out of date for those items. If you treat enrichment as a one-time script you run once and forget, you'll be answering questions against a frozen snapshot. The fix is to build an incremental enrichment job: when an item is added or changed, enrich just that item. Not the whole corpus, just the delta. Make it a pipeline, not a one-off.
Questions that genuinely need the whole corpus. "How many documents mention X?" or "what's the total across all records?" are aggregate questions. That's a database job, not a vector job. Vector search finds things that are similar in meaning; it does not count or sum reliably. Don't force vector search to do math. Route those queries to a real query engine.
Facts you cannot get wrong. Vector search returns plausible neighbors, not guaranteed-correct ones. For most questions, the closest matches are exactly what you want. For high-stakes answers, "close enough" isn't good enough, and your answer should not depend on whether retrieval happened to surface the right chunk.
This is where I stopped trusting retrieval for facts that matter. For anything critical, I either inject the must-be-correct facts directly into the prompt or keep a human in the loop. Retrieval is a great way to find candidates. It's a bad way to guarantee correctness.
And one more time, because it's the thing that quietly determines everything: enrichment quality is the ceiling on every answer you'll ever serve. Get that step right.
How to Tell If Your Business Has This Problem
Quick self-diagnosis. You probably have this problem if any of these sound familiar.
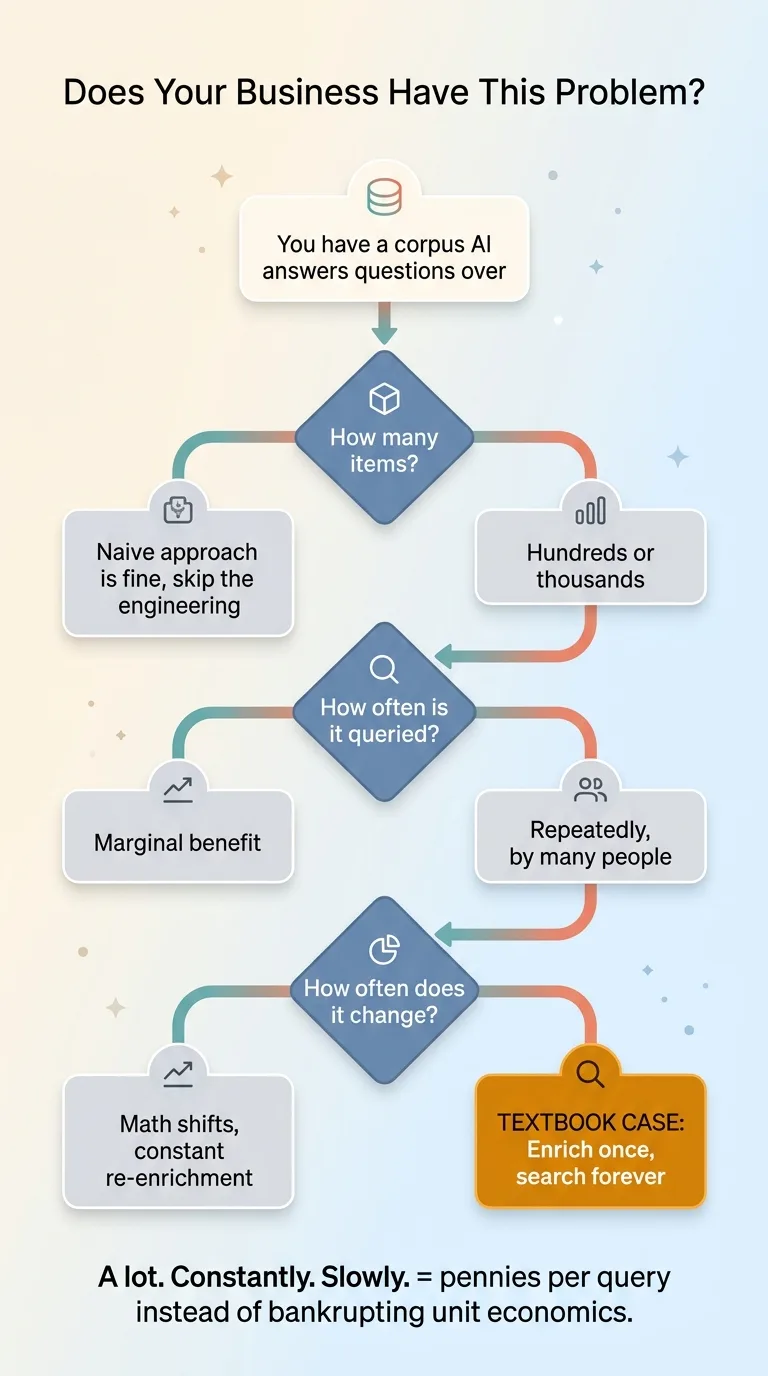 Self-Diagnosis Decision Tree
Self-Diagnosis Decision Tree
- You've got a large pile of media, documents, records, or support tickets that people repeatedly ask questions about.
- You got an AI quote or a usage bill that genuinely scared you.
- A vendor proposed an architecture that "sends everything to the model" on every request.
The tell is repeated queries over a slow-changing corpus. That's the sweet spot for enrich-once-search-forever. You pay the enrichment cost once and then amortize it across thousands of cheap queries.
If your corpus is tiny, say a few dozen items, the naive approach might be fine and the engineering isn't worth it. If your corpus changes every single minute, the math shifts too, because you're constantly re-enriching. Most businesses sit comfortably in the middle, with a large library that grows steadily but isn't churning by the second.
Three questions to gut-check yours:
- How many items? (Hundreds or thousands, not dozens.)
- How often is it queried? (Repeatedly, by multiple people.)
- How often does it change? (Daily or weekly is ideal, not by the minute.)
If the answers are "a lot," "constantly," and "slowly," you have a textbook case. This is the difference between an AI feature that costs pennies to run and one that quietly bankrupts your unit economics as it gets popular.
The Architecture Decision That Decides Your AI Bill
Here's the part most people miss. The choice between "read the library every time" and "enrich once, search forever" is usually made early, often by accident, by whoever first wires up the AI. And it sets your cost structure for the entire life of the feature.
Most teams default to the expensive one. Not because they evaluated the options, but because the expensive one is the obvious one. You have a pile of stuff and a smart model, so you hand the pile to the model. It demos beautifully. The architecture is decided before anyone runs the math, and by the time the bills show up, it's baked in.
I've built this index-first pattern across photo libraries, legal documents, and knowledge bases. It is nearly always the difference between an AI capability you can afford to run at scale and one you can't. Same feature, same quality of answer, two completely different cost curves.
If you've got a corpus you want AI to work over and you're worried about the bill, that architecture call is exactly the kind of thing I sort out before a single line of expensive code gets written. The decision is cheap to make correctly up front and painful to unwind later. Let's talk about your corpus before it's pointing in the wrong direction.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call