The AI Native Tech Stack: 5 Primitives Power Everything
An AI native tech stack lets one operator ship across dozens of industries fast. Here are the 5 owned primitives I reuse on every build.
By Mike Hodgen
Why the Stack Never Changes (Even When the Industry Does)
Last quarter I shipped software for telehealth, a law practice, custom manufacturing, real estate, healthcare, and ecommerce. On the surface, none of these products look anything alike. A patient intake flow has nothing in common with a deal analyzer or a quoting configurator.
Underneath, they are identical.
That is the part nobody tells you. I run what amounts to a one-operator AI studio that has shipped across nine-plus unrelated industries in a single quarter, and I do it by riding the exact same five owned primitives every single time. The business logic on top changes. The substrate does not.
This is the entire secret to moving between industries in days instead of quarters. When the foundation is fixed and battle-tested, you stop re-solving infrastructure and start solving the actual problem. My commit history tells the story better than I can: 1,900-plus commits across those projects, almost none of them spent wiring up auth or deployment or database isolation. That work was already done. Done once, reused everywhere.
Most people get this backwards. They treat every new project as a blank page and rebuild the plumbing from scratch, or they rent a different pile of vertical SaaS for each problem and end up unable to change anything. Both are slow. Both are expensive. Both fail the moment you need to move fast.
An ai native tech stack is not a list of tools you happen to use. It is a deliberate, owned substrate that you standardize on so hard that the next project starts mostly finished.
The rest of this article names the five primitives I build on, explains why each one was chosen for ownership rather than rental, and shows how a fixed stack turns "this will take a quarter" into "this ships this week." I picked these five carefully. Each earns its place.
The Five Primitives, Named
Here is the whole stack. Five categories, same every time, owned and controlled rather than a heap of subscriptions stitched together.
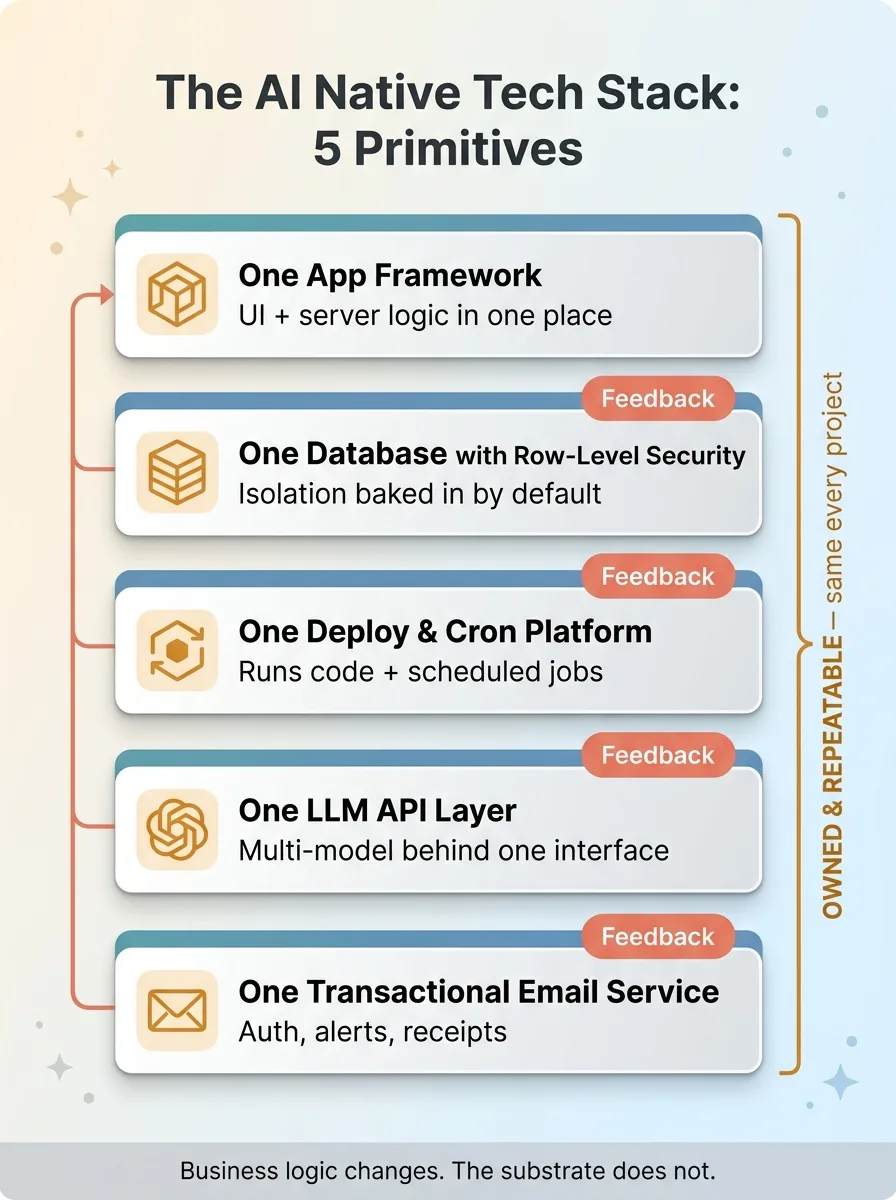 The Five Primitives Stack
The Five Primitives Stack
One app framework
This is the UI and the server logic living in one place, so I'm not maintaining a separate frontend and backend that drift apart. It is the same framework on every project because context-switching between frameworks is pure waste, and one framework means one mental model, one deploy story, one set of patterns I already know cold.
One database with row-level security
This is where the data lives, with isolation baked in at the row level by default. It is the same on every build because data isolation is the one thing you cannot retrofit cheaply, so I standardize on a single pattern and never deviate (more on this below, because it's the primitive everyone skips).
One deploy-and-cron platform
This is where the code runs plus the scheduled jobs that keep it alive: the nightly syncs, the pricing runs, the report generators. It is the same every time because deployment and scheduling are solved problems, and re-solving them per project is months of life you don't get back.
One LLM API layer
This is the intelligence layer, and it is almost always multi-model behind a single internal interface so I can route a content task to one model and an image task to another without rewriting anything. It is the same on every build because the model landscape changes constantly, and an internal abstraction means I swap models without touching business logic. I wrote about why I use multiple AI models if you want the deeper reasoning on cost and quality routing.
One transactional email service
This is the single channel everything authenticates and notifies through: password resets, magic links, alerts, receipts. It is the same every time because email deliverability is a dark art, and once you solve sender reputation and authentication properly, you want to reuse that work forever rather than fight spam folders on every new product.
Five primitives. Owned and repeatable, not rented and scattered. That is the foundation.
Why Row-Level Security Is the Primitive Everyone Skips
Most fast builds get the database right and the access control wrong.
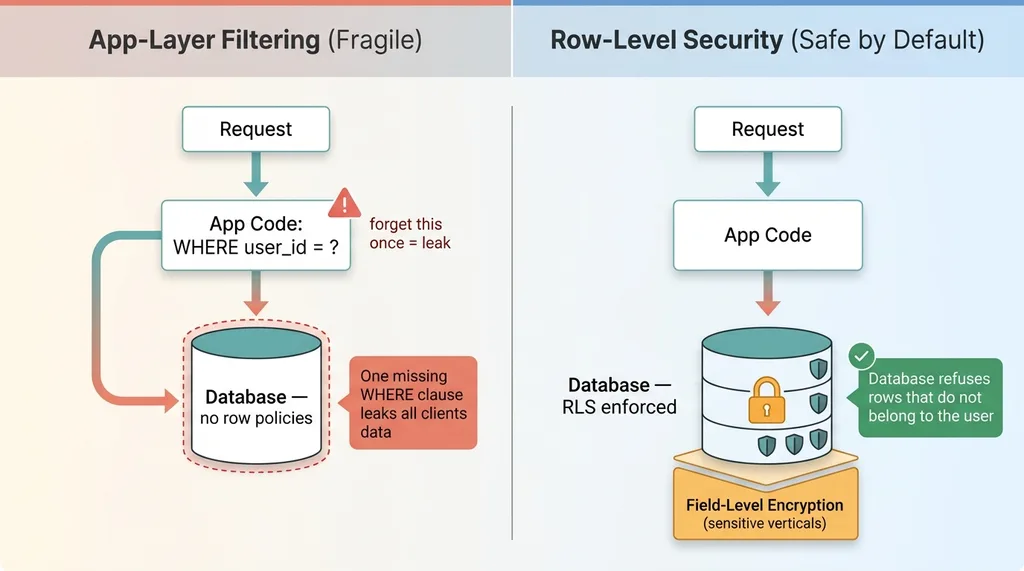 Application-layer filtering vs Row-Level Security
Application-layer filtering vs Row-Level Security
People know how to model data. They design clean tables, set up relationships, write fast queries. Then they handle access control in the application layer with a WHERE clause that filters by user, and they assume that's enough. It is not enough. The day someone forgets that WHERE clause, one client's data leaks into another client's view.
Row-level security fixes this by making isolation the default at the database level. Every row knows who can see it. There is no forgotten WHERE clause because the database itself refuses to return data that doesn't belong to the requesting user. You have to actively work to leak data, instead of actively working to prevent it.
I'll be honest about how I learned this matters. I have audited my own systems and found a database that was one anonymous key away from being world-readable. Everything looked fine in the app. The UI filtered correctly. But the underlying table had no row-level policies, so anyone with the public key could have queried the whole thing directly. That is the kind of mistake that ends a company in a regulated vertical.
The reason RLS is the same on every build is simple: you cannot bolt isolation on later. Retrofitting it means re-examining every table, every policy, every query path, under pressure, after you already have customer data. You bake it in from row one or you pay for it forever.
For the sensitive verticals (health data, financial records, legal cases) I layer field-level encryption on top of RLS so that even a policy mistake doesn't expose readable data. Defense in depth.
Here is the honest limitation: RLS is unforgiving and easy to get subtly wrong. A policy that looks correct can have a gap you don't notice until an audit. Which is exactly why I standardize on one tested pattern across every project. I'm not reinventing isolation each time and re-introducing the same subtle bug. I solve it once, prove it, reuse it.
Shared Infrastructure: One Email Account, One Bank-Data Layer, Many Products
The primitives are not just repeated patterns. They become genuine shared infrastructure.
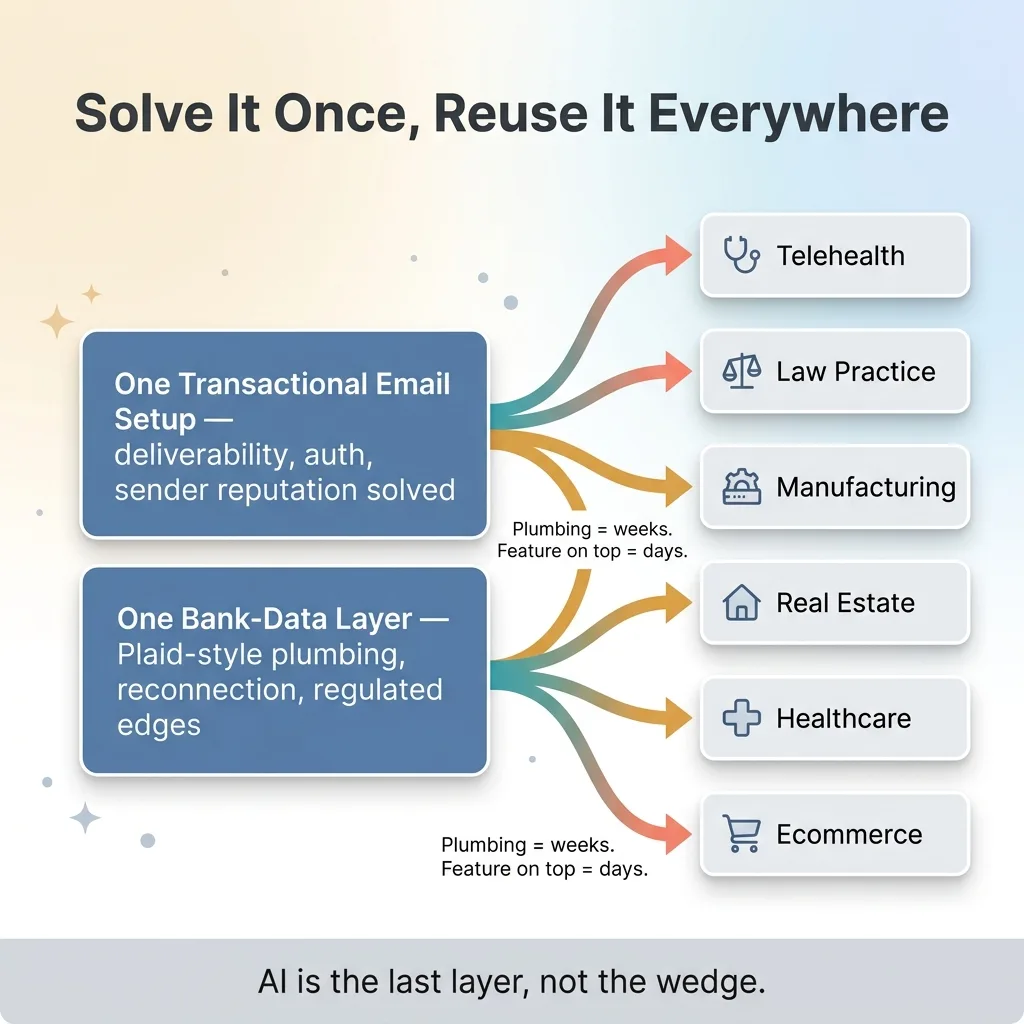 Shared infrastructure powers many products
Shared infrastructure powers many products
Take transactional email. I run email for a dozen separate projects through one carefully architected sending setup. Deliverability, authentication, sender reputation, all of it solved once and reused everywhere. When I spin up a new product, I do not think about whether password reset emails will land in spam. That problem was solved months ago and it stays solved. New product, same reliable email backbone, zero new work.
Now take bank-data integration. I built a single layer that connects to bank accounts (the Plaid-style plumbing that every financial product needs) and that one layer powers multiple unrelated financial products. The hard, regulated, error-prone part of connecting to financial institutions gets built once. After that, shipping a new financial product is a matter of business logic on top of plumbing that already works.
This is the part people underestimate. The plumbing is what takes the time. Connecting to a bank, handling reconnection flows, dealing with institutions that change their APIs, managing the regulated edges. That is weeks of careful work. The actual product feature on top might be two days.
So the more boring and reusable I make the substrate, the faster the next product ships. I am never re-solving deliverability. Never re-solving bank connectivity. Never re-solving auth. Those are done.
There's a phrase I keep coming back to: AI is the last layer, not the wedge. Everyone wants to lead with the model because it's the exciting part. But the model is the easy part to add once the plumbing exists. The unglamorous infrastructure underneath is what separates a demo from a product that actually runs in production for real customers.
What I Rent vs. What I Own
Here is the decision rule behind the whole stack.
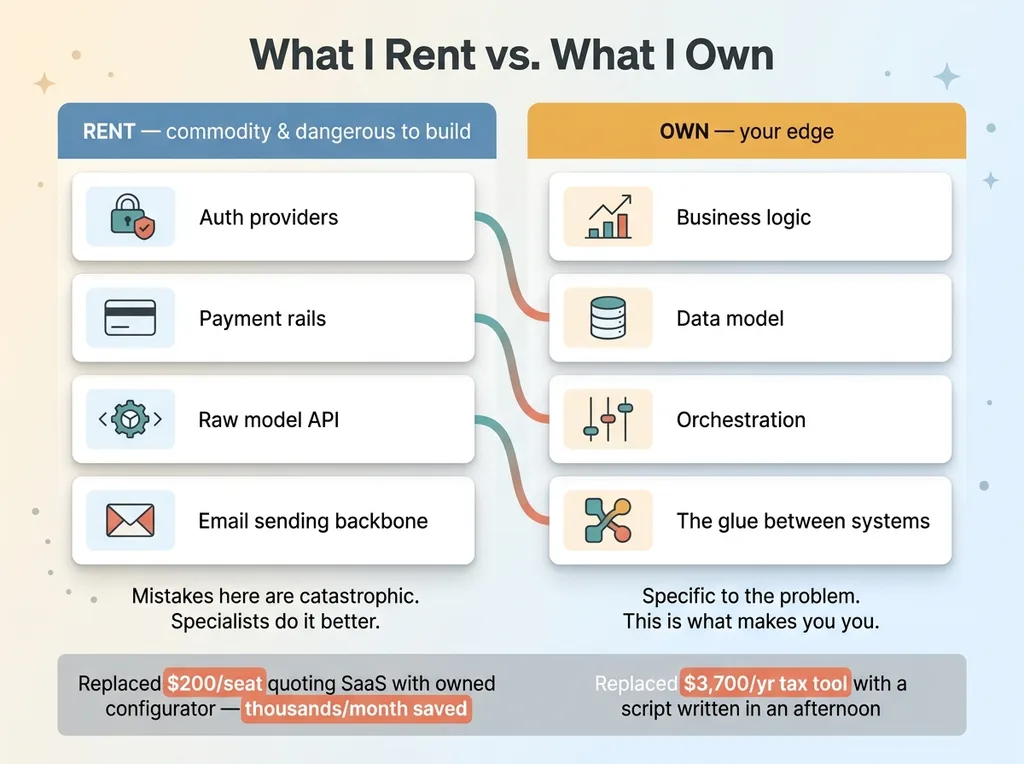 Rent vs Own decision rule
Rent vs Own decision rule
I rent the primitives that are commodities and dangerous to build myself. Auth providers, payment rails, the raw model API, the email sending backbone. These are solved problems where a mistake is catastrophic and where dozens of full-time engineers at specialized companies have already done the work better than I ever could. Building my own auth is how you end up with a breach. Building my own payment processing is how you end up out of compliance. I pay for those.
I own the business logic, the data model, the orchestration, and the glue. This is the layer that is specific to the problem and that gives me an edge. I wrote a full breakdown of this principle in pay for primitives, build the logic, because it's the single most important decision in the whole stack.
Most companies make one of two mistakes. They rent their business logic through vertical SaaS and then discover they cannot change it when their process evolves. Or they build their own commodity infrastructure and waste months reinventing auth and email.
The owned, repeatable middle layer is the answer. It's what lets one operator compete with an agency.
Concrete examples. I replaced a $200-per-seat quoting SaaS with an owned configurator that does exactly what the business needs and costs nothing per seat. Across a team, that's thousands a month back. I replaced a $3,700-a-year tax tool with a script that runs the same calculation in seconds. The script took an afternoon to write and it'll run for years.
Rent the dangerous commodities. Own the logic that makes you you.
How a Fixed Stack Turns Days Into the New Timeline
Here is the payoff.
 Fixed stack means projects start 60-70% done
Fixed stack means projects start 60-70% done
Because the substrate is identical every time, a new project starts at roughly 60 to 70 percent done on day one. Auth is wired. Row-level isolation is enforced. Deployment and cron are configured. Email sends reliably. The LLM interface is ready to route to whichever model the task needs. None of that is new work. It's battle-tested code I've shipped across many industries.
The only genuinely new work is the business logic and the domain rules. That's the 30 percent that actually matters, and it's the only part the client is really paying for.
This is why I can move from a manufacturing quoting tool to a telehealth intake flow to a real estate deal analyzer without a ramp-up period. The domain is different. The substrate is identical. I'm not learning new infrastructure on each project; I'm pointing infrastructure I already trust at a new problem.
If you want proof of the velocity this enables, I documented shipping 10 projects in a single week. That pace is not possible if you rebuild the foundation each time. It's only possible because the foundation never changes.
Now the honest limit. A fixed stack is a constraint, and constraints have a cost. Occasionally a project genuinely needs something off-stack: a specialized database, a different runtime, a model with capabilities my standard layer doesn't cover. That happens. When it does, I go off-stack deliberately, knowing I'm trading velocity for the specific thing the project needs. But it's rare. The vast majority of problems fit the five primitives, and pretending you need something exotic is usually just an excuse to rebuild plumbing you should have reused.
The discipline is in resisting the urge to customize the foundation. Keep it boring. Keep it fixed. Spend your creativity on the business logic where it actually pays off.
The Stack Is the Reason One Person Can Replace a Team
The reason I can act as a company's Chief AI Officer and actually ship working systems, not just hand over a slide deck, is this owned, repeatable stack.
When a CEO hires me, they are not paying for me to discover infrastructure from scratch on their dime. They get a substrate that has already shipped across many industries, already survived production, already had the security bugs found and fixed. The expensive, slow, dangerous part is done before I start. What's left is the work specific to their business, which is the only work worth paying for.
That changes the economics in three ways. Faster time to live, because day one starts at 60 to 70 percent. Lower long-run cost, because you own the systems instead of renting vertical SaaS forever at $200 a seat. And security baked in from row one instead of bolted on after an audit scares everyone.
This is the difference between someone who advises and someone who builds. I wrote about that distinction in I build it, not just advise on it, because most "AI consultants" deliver recommendations and leave the actual building to a team you still have to hire.
If you're tired of vendors who deliver slides and SaaS bills, the stack is how I deliver working systems instead. Same five primitives, your business logic on top, live faster than you'd expect.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call