AI Lead Scoring Bias: Why I Split One Score Into Two
A single AI lead score quietly redlines high-merit clients. Here's the deterministic, bias-resistant design I built to fix ai lead scoring bias.
By Mike Hodgen
The Single Score That Buried Good Cases
I was building an intake scoring system for a personal-injury law firm, and the first version did exactly what everyone asks for. One number. A single signal_score per lead, and the queue sorted itself top to bottom. Clean dashboard. Easy to explain in a meeting.
It was also quietly burying the firm's best cases. This is the clearest example of ai lead scoring bias I've ever built with my own hands, and I built it by accident.
Here's how it failed. A caller comes in: uninsured worker, hurt on a job site, clear third-party liability against a general contractor. Strong case on the merits. Real defendant with real coverage. But the worker himself has no assets, no insurance, a thin paper trail. The model saw "low collectibility from the individual" and dragged the merged score down. That case landed somewhere around position 40 in the queue. Nobody was going to call position 40 back the same day.
Meanwhile, an articulate caller with a marginal claim, fluent, organized, told a tidy story, scored high. Narrative polish inflated the merit signal. The persuasive caller floated to the top. The injured worker sank.
So here's the thesis up front, and I'll defend it the rest of the way. When you collapse legal merit and recoverable money into one sortable number, you don't get a balanced score. You build a structure that systematically redlines high-merit, low-dollar clients and amplifies whoever sounds the most credible. Nobody coded that bias. The math produced it.
The fix wasn't a better prompt. It was refusing to combine two things that should never have been combined. (I hit a related version of this when I built an intake agent that's forbidden from quoting a number. Same instinct, different failure mode.)
One score in, good cases out. Let me show you why that's not a tuning problem. It's a math problem.
Why One Number Is Mathematically a Redlining Machine
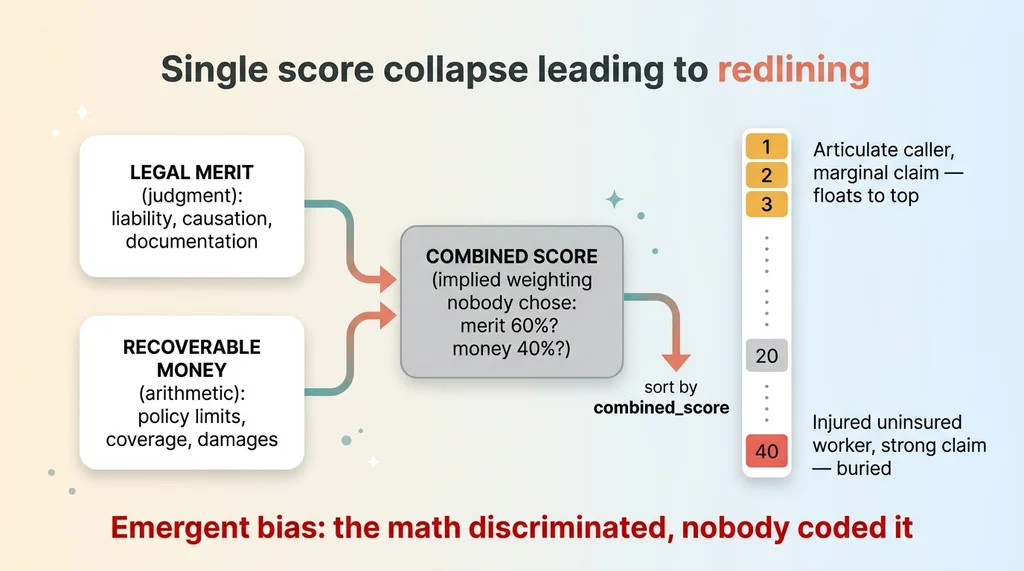 Single score collapse creating redlining
Single score collapse creating redlining
Two different questions, one answer
A lead score in this context is secretly answering two completely unrelated questions.
Question one: how strong is this legal claim? Liability, causation, documentation. A judgment.
Question two: how much money can we realistically recover? Policy limits, coverage, documented damages. Arithmetic.
These have nothing to do with each other. A claim can be airtight on liability and worth very little. A claim can be worth a fortune and impossible to prove. When you mash both into one weighted average, money starts overriding merit and merit starts overriding money in proportions nobody ever decided on purpose.
That's the part that should bother you. There's an implied weighting buried inside that single number. Maybe merit counts 60 percent and money 40. Maybe it's the reverse. Nobody signed off on it. The model picked it, implicitly, through whatever the prompt happened to emphasize that day.
The sort key is the whole problem
Now sort the queue by that number. The cases a human actually sees, the ones that get a callback within the hour, are determined entirely by that invisible weighting.
That's ai redlining, plainly defined: a scoring system that systematically deprioritizes a vulnerable group, with nobody intending it. The injured uninsured worker isn't a protected class on paper, but the pattern is identical. Low-dollar individuals get pushed below the fold, automatically, every time.
The bias here is emergent, not coded. I didn't write if poor then deprioritize. I wrote sort by combined_score, and the combination did the discrimination for me.
This is the section that should make you trust the rest. If you can't point at where a number comes from and explain why it sorts the way it sorts, you can't audit it. And if you can't audit it, you can't defend it.
Split One: Legal Merit on Its Own 0-100 Scale
The first half of the fix is a legal_merit score, 0 to 100, that answers exactly one question: how strong is this claim?
Nothing else. It evaluates liability clarity, causation, and the quality of documentation. The facts of the incident. Whether there's a clear at-fault party. Whether the injury is documented or just described. That's it.
It knows nothing about the client's wallet. Collectibility is not an input. Insurance status is not an input. Whether this person can afford anything is irrelevant to the question "is this a strong claim." A strong claim is strong whether the plaintiff is a CEO or a day laborer.
This is the half where I let the language model actually reason. Merit is a judgment task. You're weighing facts, reading a narrative, deciding how clean the liability story is. That's the kind of work an LLM is genuinely good at, and it's the kind of work you'd hand to a junior intake attorney anyway.
So the model gets the incident, the parties, the documentation, and it produces a merit score with its reasoning attached. No dollar figures anywhere near it.
This creates a new problem, and I want to name it now rather than pretend it doesn't exist. A confident, well-told story can still inflate merit even when the underlying facts are thin. The articulate-caller problem doesn't disappear just because I removed money from the equation.
I solve that with a data-completeness discount, which I'll get to. For now the point is: merit lives alone, on its own scale, measuring one thing.
Split Two: Economic Tier, Computed in Code Not by the Model
The second half is a separate economic tier. A, B, C, or D. It estimates realistic recovery, and here's the design decision that matters most: it is computed deterministically in TypeScript, not generated by the model.
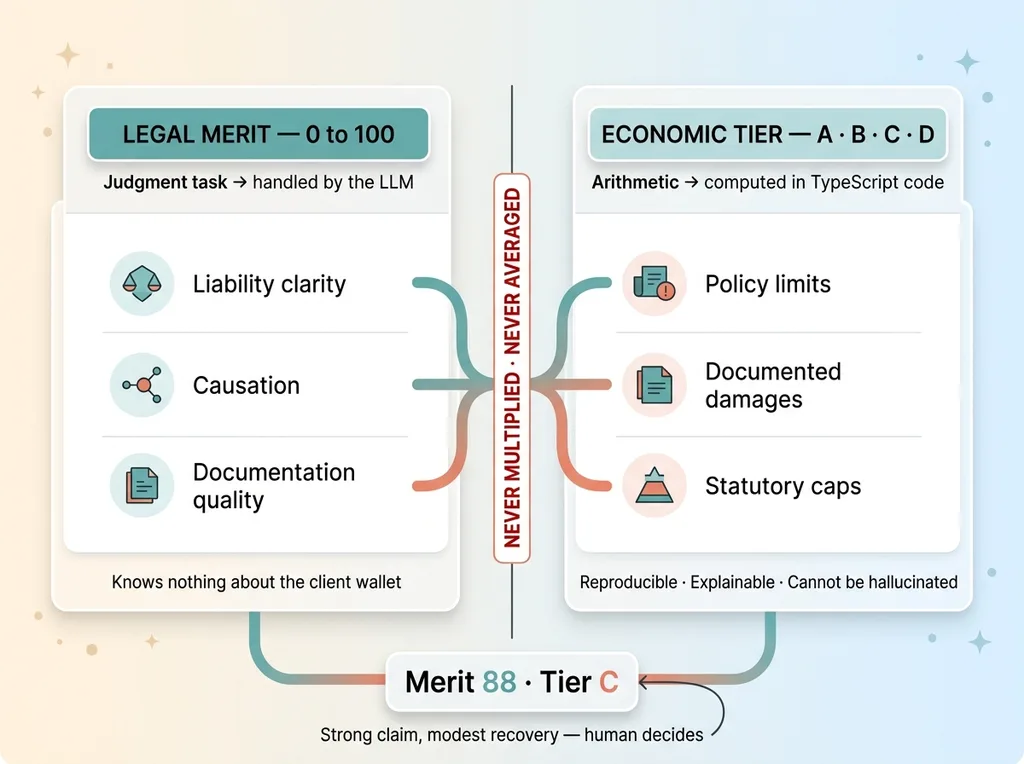 Two separate outputs: merit score and economic tier never merged
Two separate outputs: merit score and economic tier never merged
The tier is arithmetic. Policy limits, available liability coverage, documented damages, statutory caps. These are numbers you add, compare, and bucket. There is no judgment in "the policy limit is 250,000 and documented damages are 80,000." That's a calculation, and calculations belong in code.
Three reasons I refuse to let the model touch this.
It's reproducible. The same inputs produce the same tier, every single time, forever. No temperature, no drift, no "it scored it differently on Tuesday."
It's explainable. I can show the exact formula that produced tier B. You can trace it line by line in a deposition or an audit.
And the model can never hallucinate a dollar figure or get talked into one by a persuasive caller. A confident plaintiff cannot inflate their own economic tier, because the tier doesn't listen to confidence. It listens to coverage and damages.
This is the principle I wrote up in detail: let the model judge, let the code compute. Judgment to the LLM, math to the math.
The two outputs sit side by side. Merit 0-100. Tier A-D. They are never multiplied. Never averaged. Never collapsed into one sort key. The moment you multiply them, you've rebuilt the redlining machine.
The queue organizes by merit, with economic tier shown as visible context next to each case. A reviewer sees "merit 88, tier C" and understands instantly: strong claim, modest recovery. They decide what to do with that. The tier informs the human. It does not bury the case.
Stopping the Articulate Caller From Gaming the Score
Discounting merit by data completeness
Remember the polished caller who inflated their merit score with a tidy narrative. Here's how that gets shut down.
Merit is discounted by data completeness. If the facts are thin, the merit ceiling drops, no matter how confident the telling. A beautifully delivered story with no corroborating documentation cannot score 90. The missing data caps it.
This matters because confidence is the easiest thing in the world to fake and the hardest signal to trust. A nervous, halting caller with a fractured arm and a clear at-fault driver has a better case than a smooth talker with vibes and no medical records. The data-completeness discount forces the score to reflect what's actually known, not how well it was narrated.
Confidence can't buy a high score. Only facts can.
The redacted scorer view
This is the mechanism I care about most, and it's the one that should make you a little uncomfortable.
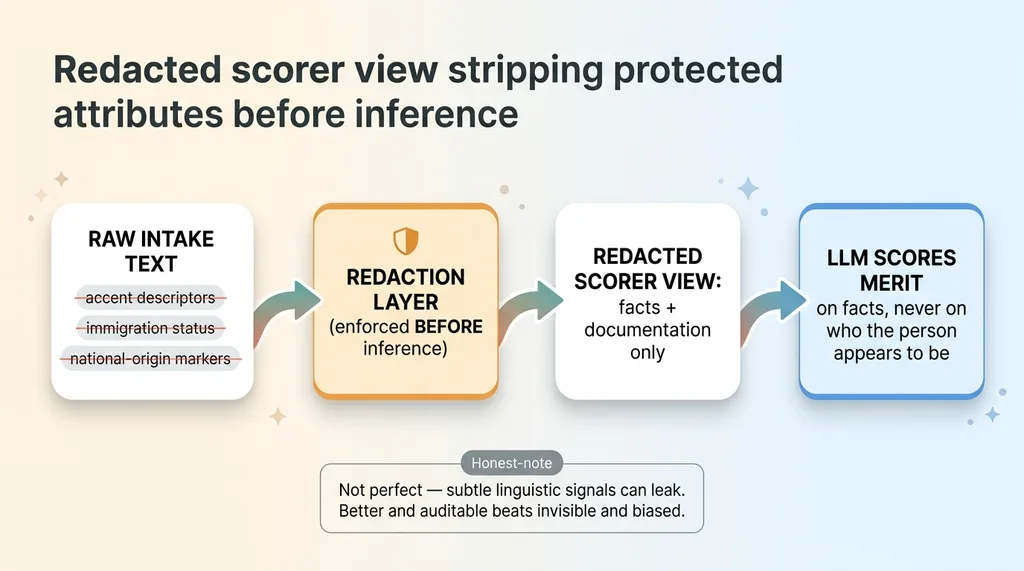 Redacted scorer view stripping protected attributes before inference
Redacted scorer view stripping protected attributes before inference
Before the model ever sees an intake, a redacted scorer view strips out accent descriptors, immigration status, and national-origin markers. The LLM scores merit on facts and documentation, never on who the person appears to be.
I built this because the original single-score version was doing something ugly without being told to. It was rewarding fluent English. It was quietly punishing the exact people most likely to be injured on a job site, immigrant workers, non-native speakers, the population this kind of firm often represents.
Sit with that. A tool meant to qualify clients for a firm that litigates discrimination was replicating discrimination at the front door. Not because anyone wanted it to. Because the raw intake text carried those signals and the model picked them up.
The redacted view is the same family of guardrail I describe in how I stop AI from embarrassing a client. You decide what the model is allowed to see, and you enforce it before inference, not after.
I won't pretend redaction is perfect. Subtle linguistic signals can leak through, and I keep tightening it. But scoring on redacted text is dramatically better than scoring on raw text, and "better and auditable" beats "invisible and biased" every time.
Every Weak Lead Still Goes to a Human
Here's the guardrail that matters more than any score.
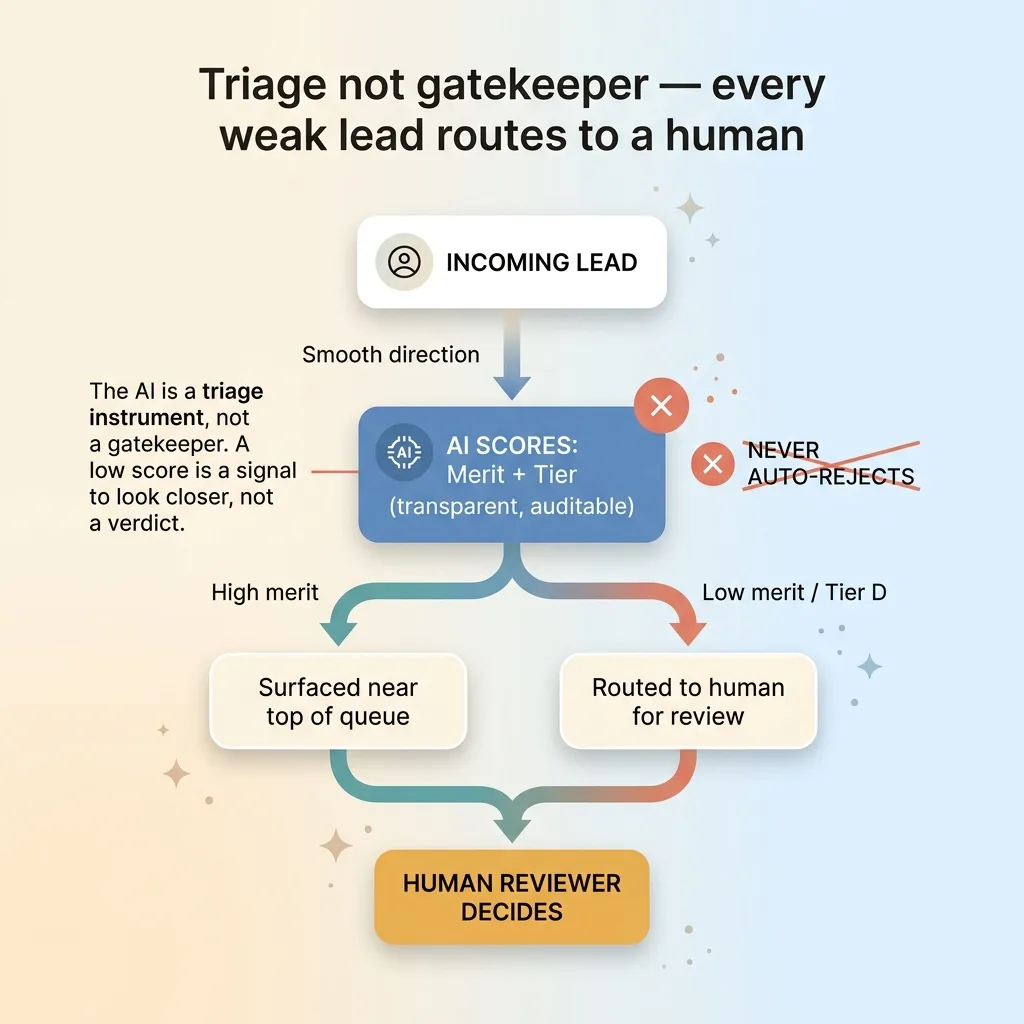 Triage not gatekeeper, every weak lead routes to a human
Triage not gatekeeper, every weak lead routes to a human
The system sorts and surfaces. It never auto-rejects. A low merit number or a tier D does not drop a lead out of the pipeline. It routes that lead to a human for review.
The AI is a triage instrument, not a gatekeeper. It decides what to look at first. It never decides what to throw away. Nobody gets filtered out by a machine, and no case quietly disappears because a model didn't like the numbers.
This is the same principle I apply everywhere I deploy AI in a real operation: every weak lead still routes to a human. The model accelerates the work. A person owns the decision.
That's the answer to the black-box fear, completely. Nothing here is autonomous. Every lead carries two transparent numbers, merit and tier, both of which a human can interrogate and override. A reviewer can ask "why is this merit 62" and get a real answer. They can ask "why is this tier C" and trace the arithmetic.
A low score is a signal to look closer, not a verdict. The strong-liability uninsured worker who used to land at position 40 now shows merit 88, tier C, and a human sees that combination and knows exactly what they're looking at: a real case worth pursuing for reasons the dollar figure alone would have hidden.
End to end, you can audit it. Every number has a source. Every decision has a person attached. That's the standard.
What an Auditable Scoring System Actually Buys You
The lesson here is bigger than law firms.
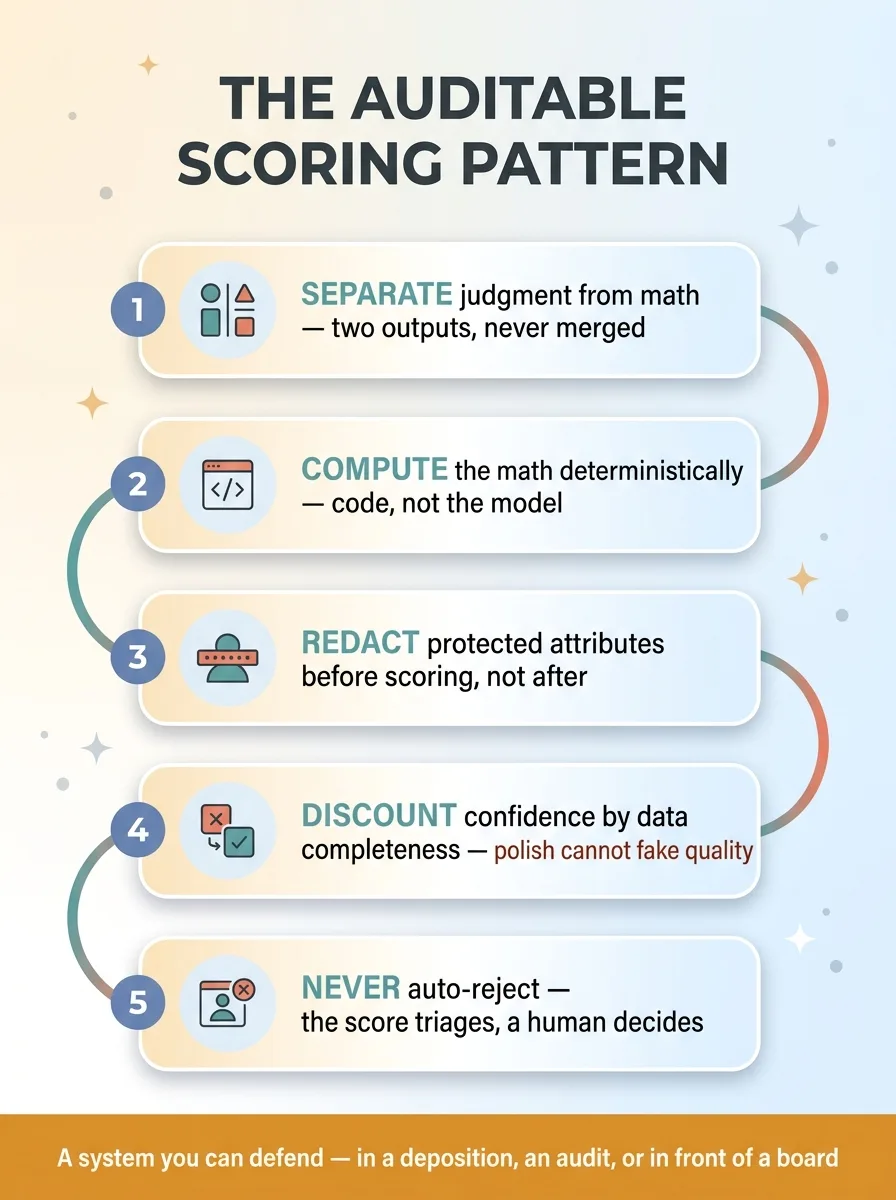 The five-part reusable auditable scoring pattern
The five-part reusable auditable scoring pattern
Any time you let an AI fold merit and money into one number and sort by it, you've built a quiet bias machine. It doesn't matter if it's leads, loan applicants, job candidates, or support tickets. Combine two unrelated questions into one sortable score and the math will discriminate for you, on dimensions nobody chose.
The fix is a pattern you can reuse:
- Separate the judgment from the math. Two outputs, never merged.
- Compute the math deterministically. Code, not the model, for anything arithmetic.
- Redact protected attributes before scoring, not after.
- Discount confidence by data completeness, so polish can't fake quality.
- Never auto-reject. The score triages. A human decides.
Do all five and you get something most AI deployments can't offer: a system you can defend. In a deposition. In an audit. In front of a board asking how the algorithm makes decisions. You can point at every number and say where it came from and why it sorted the way it did.
That's the difference between AI that looks impressive in a demo and AI that survives contact with a regulator. I've shipped both kinds. The defensible kind takes more design and is worth every hour.
This is the work I actually do when I build AI into an operation instead of a slide deck. Not "add a score." Pull the score apart, find where it's quietly redlining someone, and rebuild it so a human can stand behind it.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call