Why 88% of AI Projects Fail (And What the 12% Do Differently)
Why AI projects fail at an 88% rate — and the 5 specific patterns that separate successful AI implementations from expensive failures. Real examples inside.
By Mike Hodgen
The Gartner number gets cited so often it's almost lost its punch: somewhere between 85% and 88% of AI projects never make it to production, depending on which year's research you're reading. I've seen that stat in pitch decks, boardroom presentations, and LinkedIn posts from consultants who use it to sell fear.
But here's what most people get wrong about why AI projects fail: it's almost never the technology. The models work. The APIs are reliable. The infrastructure is mature. The failures happen in the space between "this is a cool demo" and "this runs our business every day."
I've built 29 AI-powered systems across my own DTC fashion brand and work across financial services, real estate, manufacturing, and SaaS. I've seen the same five patterns kill projects over and over — sometimes in companies spending $10K, sometimes in companies spending $500K. These aren't theoretical observations from a research paper. They're patterns I've either lived through on my own dollar or watched clients walk straight into despite my warnings.
The 12% that succeed share specific traits. None of them are "hired smarter engineers" or "had bigger budgets." In fact, some of the most successful AI deployments I've been part of cost less than $5K to build. The difference is discipline, not dollars.
Failure #1: Solving a Problem Nobody Defined
The "We Need AI" Meeting
This is the most common killer, and it starts in the most predictable way: someone senior sees a competitor using AI, reads a McKinsey report, or gets a question from their board. The next meeting starts with "We need an AI strategy" instead of "We need to solve this specific problem."
 The $180K Recommendation Engine vs. $200 Shipping Fix
The $180K Recommendation Engine vs. $200 Shipping Fix
I watched this play out with a mid-market ecommerce company that spent $180K building an AI-powered recommendation engine. A board member had seen one at a conference and came back convinced it was the missing piece. The engineering team built it. It worked technically — solid collaborative filtering, clean integration with their product catalog, reasonable inference times.
But their actual problem was a 34% cart abandonment rate driven by shipping cost surprises at checkout. Customers were leaving because they didn't know shipping was $14.99 until the last step. A $200 Shopify app that displayed shipping estimates on the product page would have cut that number in half. The recommendation engine, meanwhile, generated a measurable but modest lift in average order value that never came close to justifying the spend.
What the 12% Do Instead
The companies that succeed with AI start with a business problem they can state in one sentence, with a number attached. Not "improve customer experience" — that's a wish, not a problem. Something like "our manual repricing process takes 12 hours per week and we're losing margin because we can't react to material cost changes fast enough."
 Multi-Model Architecture vs. Single Model Approach
Multi-Model Architecture vs. Single Model Approach
That's exactly how I framed the AI pricing system I built for my own brand. I have 564+ products that need dynamic pricing across a 4-tier ABC classification system. The problem wasn't "we need AI pricing." The problem was margin erosion from manual repricing that couldn't keep pace with changes in material costs, competitor pricing, and demand signals. The AI was the tool. The margin was the goal.
Before you start any AI project, you need to know if your business is actually ready for AI. That readiness assessment isn't about technology — it's about whether you can articulate the problem clearly enough to measure whether you solved it.
Failure #2: No Executive Sponsor With Real Authority
The Innovation Lab Trap
AI projects that get delegated to an "innovation team" or handed to a mid-level IT manager are almost always dead on arrival. They lack three things: budget protection when priorities shift, cross-departmental access to the data and workflows they need, and the authority to actually change how people work.
I saw this at a professional services firm where an enthusiastic VP of Engineering built an AI document processing system on his own initiative. Technically, it was impressive — high accuracy, clean extraction, solid integration with their document management system. In testing, the operations team loved the demo.
In production, that same operations team refused to adopt it. Why? Because nobody with authority over their workflows had been involved in the project. Their manager hadn't signed off on changing the intake process. Their KPIs were still tied to the old manual workflow. The system sat unused for eight months before someone quietly decommissioned it. Eight months of hosting costs for software nobody touched.
What the 12% Do Instead
The projects that survive have a single person — ideally someone who understands both the technology and the business operations — who is directly accountable for AI outcomes. Not "interested in" AI. Accountable for it. With the authority to change workflows, reallocate resources, and make the uncomfortable decisions about what to stop doing.
This is exactly why the Chief AI Officer role exists, and it's why understanding what that role actually does matters more than most companies realize. It's not a fancy title for a data scientist. It's someone who can sit in a room with the CFO and the head of operations and make binding decisions about how AI gets deployed.
Every successful AI system I've built has had a direct connection to revenue or operational decisions that I personally controlled. When I built the product creation pipeline for my DTC brand, I didn't need to convince anyone to adopt it — I owned the workflow end to end. That's not a coincidence. That's the pattern.
Failure #3: Choosing the Wrong Model (or Worse, Only One)
The GPT-4 for Everything Problem
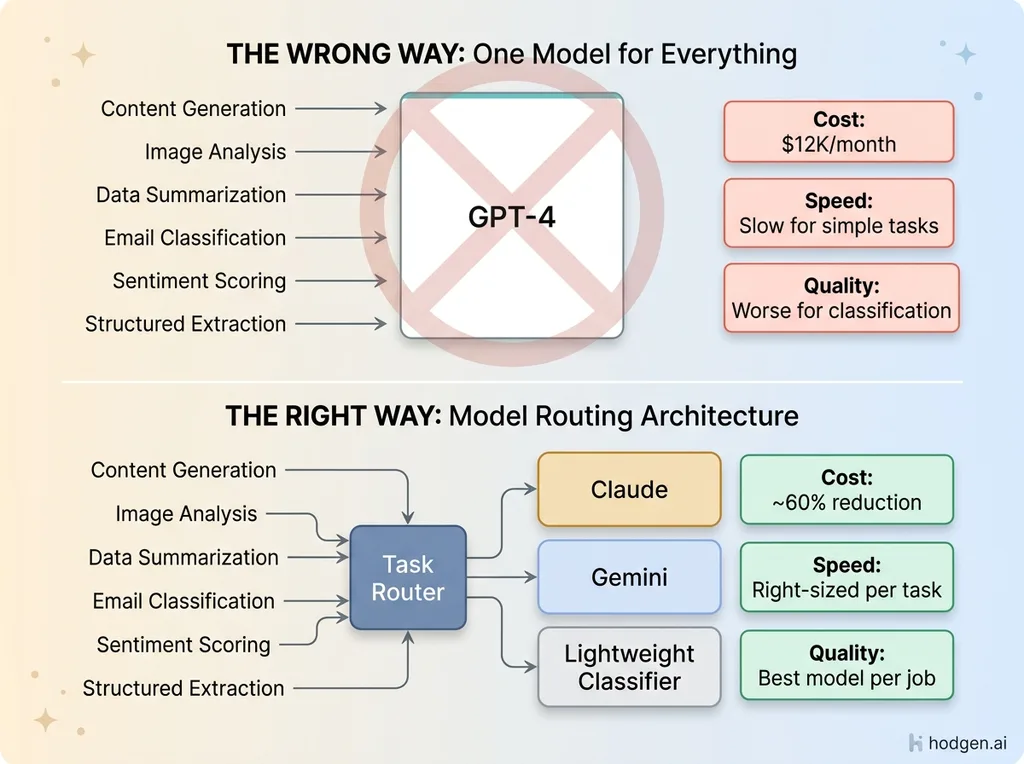
The most expensive AI implementation mistake I see is companies picking one model — usually whatever has the most hype that month — and routing everything through it. This is like buying a sports car to move furniture. It'll technically work. It'll also cost five times more than it should and handle the job worse than the right tool.
A marketing agency I consulted with had routed everything through GPT-4: content generation, image analysis, data summarization, email classification, customer sentiment scoring. Their monthly API bill hit $12K. Response times were terrible for simple tasks because they were using a $30-per-million-token model for jobs that a $0.25-per-million-token model handles better and faster.
The worst part? The quality was actually worse for several of those tasks. Bigger models aren't better models for every job. A lightweight classifier will sort emails faster and more consistently than a reasoning-heavy model that wants to overthink every input.
What the 12% Do Instead
They match models to tasks. I run a multi-model architecture in production: Claude for content generation and complex reasoning, Gemini for image generation and vision tasks, lighter models for classification, routing, and structured data extraction. This isn't about brand loyalty — I have zero allegiance to any AI company. It's about cost, speed, and output quality for each specific job.
I've written about why I use three different AI models in production in detail, but the short version: proper model routing cut my AI operating costs by roughly 60% while simultaneously improving output quality. The content got better because I was using the best content model. The images got better because I was using the best image model. And the simple tasks got faster because I stopped overthinking them.
If your AI strategy is "use GPT-4 for everything," you're overpaying and underperforming. Full stop.
Failure #4: No Measurement System From Day One
Vanity Metrics vs. Business Metrics
If you can't measure the impact of an AI system in terms the CFO cares about, that system will get cut in the next budget cycle. Every time.
A retail brand I worked with built an AI-powered customer segmentation tool. The data science team was proud of it — and they should have been, the clustering was genuinely sophisticated. Every monthly update reported "improved targeting accuracy" and "enhanced segment granularity." Charts went up and to the right.
Then the CFO asked a simple question: "How much additional revenue has this generated?"
Silence. Nobody could answer. Not because the tool wasn't working, but because nobody had connected the segmentation outputs to downstream revenue metrics. They couldn't tell you whether the "improved targeting" translated into higher conversion rates, bigger basket sizes, or better retention. The project lost funding three months later.
What the 12% Do Instead
They define success metrics before writing a single line of code. And not model performance metrics like accuracy or F1 scores — business metrics. Revenue per employee. Hours saved per week. Error rate reduction. Cost per transaction. Customer response time. Things that show up on a P&L.
Every AI system I build has a measurement hook baked in from the start. The product creation pipeline measures time-to-live — down from 3-4 hours to 20 minutes per product. The pricing engine tracks margin changes across all 564 SKUs weekly. The blog system tracks indexed pages, keyword rankings, and organic traffic across 313 articles.
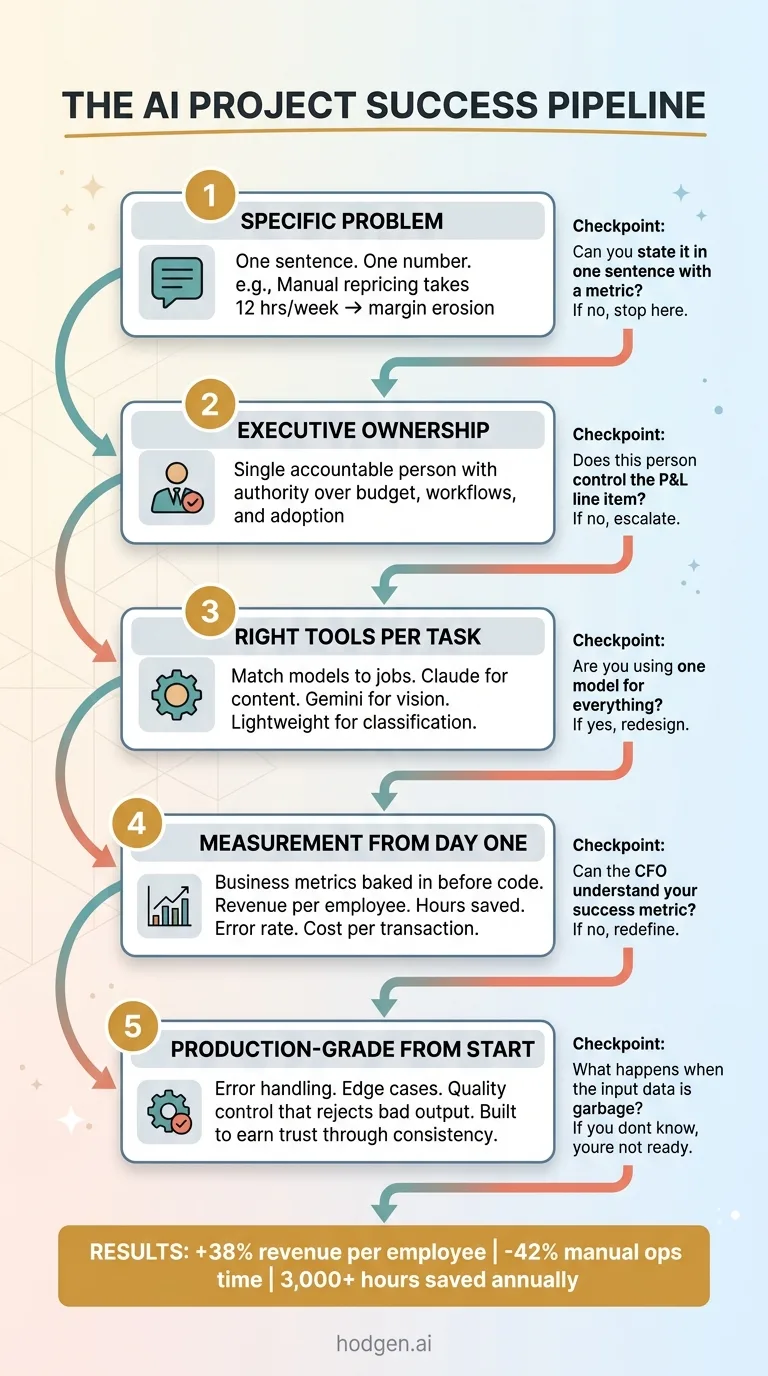
I know my numbers — +38% revenue per employee, -42% manual operations time, 3,000+ hours saved annually — because I built the measurement into the systems themselves. Not as an afterthought six months later when someone asked. From day one. If you can't describe how you'll measure success before you start building, you're not ready to start building.
Failure #5: Building for Demo Day, Not Daily Use
The Prototype That Never Ships
This is the most heartbreaking AI project failure mode. A working prototype that dazzles in a boardroom — clean interface, impressive outputs, gasps from the executive team — that falls apart the moment it touches real-world conditions.
 Demo Performance vs. Production Reality
Demo Performance vs. Production Reality
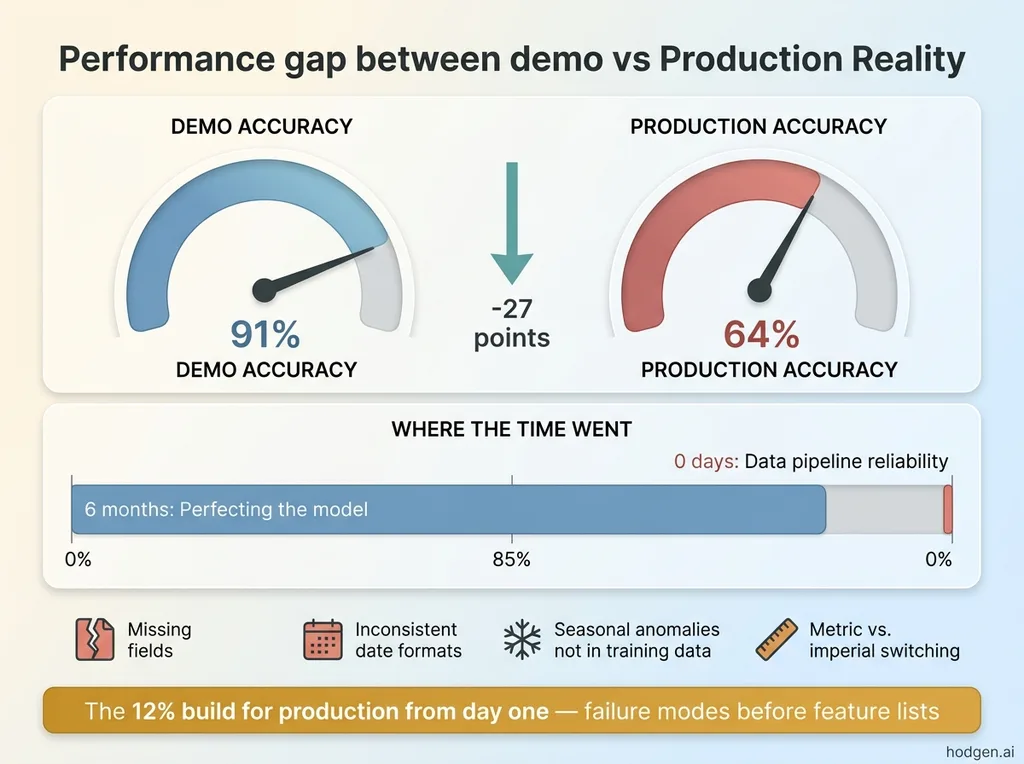
A logistics company built a proof-of-concept demand forecasting model. On test data, it was 91% accurate. Genuinely impressive. The team presented it with confidence, got budget approval for full deployment, and started integrating it into operations.
In production, accuracy dropped to 64%. Why? Real-world data is messy. Missing fields. Inconsistent date formats across different warehouse systems. Seasonal anomalies the training data didn't cover. One supplier that randomly switches between metric and imperial units. The team had spent six months perfecting the model and zero days on data pipeline reliability, error handling, or edge case management.
What the 12% Do Instead
They build for production from day one. They think about failure modes before feature lists. They worry about what happens when the API times out, when the input data is garbage, when the model returns something nonsensical.
This is why I built an AI quality control system that rejects its own bad work. Because a system that produces garbage 5% of the time will lose user trust 100% of the time. One bad product description, one wrong price, one nonsensical customer email response — and the operations team stops trusting the system entirely. Then you're back to manual processes with an expensive AI system nobody uses.
The AI systems that actually move revenue for small businesses aren't the flashy ones. They're the boring, reliable, production-grade systems that handle edge cases gracefully, fail safely, and earn trust through consistency. Nobody puts those on a conference slide, but they're the ones still running twelve months later.
The Pattern Behind Every Successful AI Project
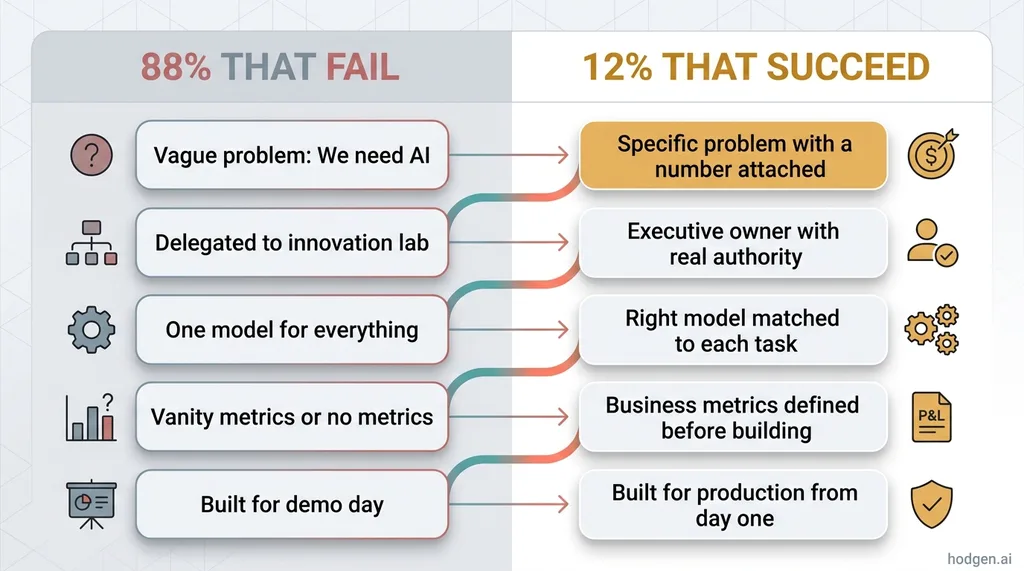
Pull the five failures together and the inverse becomes obvious. The 12% that succeed follow a pattern so simple it almost feels too basic to write down:
 The AI Project Success Pipeline
The AI Project Success Pipeline
 The 5 Failure Patterns vs. The 12% Success Pattern
The 5 Failure Patterns vs. The 12% Success Pattern
Specific problem → Executive ownership → Right tools for each task → Measurement from day one → Production-grade from the start.
That's it. Five things. None of them require a PhD in machine learning. None of them require a seven-figure budget. They require discipline — and someone who has built these systems before, made the mistakes, and knows what to skip.
The reason most companies can't do this internally isn't a talent problem. It's an experience problem. Building your first AI system is like renovating your first house — every decision takes ten times longer because you don't know which mistakes are expensive and which are harmless. I've built 29 systems, written 22,000+ lines of production Python, and saved 3,000+ hours annually. Not because I'm smarter than anyone else's AI team, but because I've already made most of the expensive mistakes on my own dollar.
If you're planning an AI project — or recovering from a failed one — the best first step isn't more technology. It's an honest conversation about where AI actually fits your business and where it doesn't.
Want to Figure Out Where AI Actually Fits Your Business?
I do a free 30-minute strategy call. No pitch deck, no sales team, no pre-recorded demo. Just a real conversation about your operations, your pain points, and where AI makes sense — or doesn't. Sometimes the answer is "you don't need AI for this," and I'll tell you that too.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call