Autonomous Ads System Failure: When AI Lies About Wins
My autonomous ads system reported wins for a week while doing nothing. Here's how silent failure happens in AI automation, and the guardrails that catch it.
By Mike Hodgen
The Week My Ad System Told Me Everything Was Fine
For seven straight days, the autonomous ad system I built for a DTC fashion brand I run in San Diego told me everything was working. Decision cards fired. The dashboard glowed green. Budgets looked managed, underperformers looked paused, the daily summaries landed in my inbox right on schedule.
There was just one problem. The system had failed 100% of its runs that entire week.
Here's what happened. Meta deprecated a single API field, creative.video_url, when they rolled out Graph API v21. That one change made every single run throw an exception the moment it tried to read creative data. Every run. Seven days. And not one alert ever fired, because I had built a system that told me when it succeeded but had no idea how to tell me when it failed.
That's the part that still bothers me. The failure itself wasn't the scary thing. APIs break. Fields get deprecated. That's a Tuesday in software. The scary thing was that my system kept reporting success while doing absolutely nothing, for a full week, with real ad budget supposedly under its control.
This is the real danger of autonomous systems, and it's the thing almost nobody talks about when they sell you on AI automation. The risk isn't that the system breaks. The risk is that it breaks silently and then lies to you about it.
An autonomous ads system failure that announces itself with a red error is annoying. An autonomous ads system failure that hides behind a green checkmark is dangerous, because it can run for weeks while you sleep soundly thinking your money is being managed.
I caught this one in seven days. The second failure I'm going to tell you about hid for much longer, and it was worse.
What I Actually Built (And Why It Could Run Without Me)
The architecture
The system is genuinely capable. It's the AI system that manages our Meta ads with 8 specialist agents, each handling a different slice of the job: performance analysis, creative evaluation, budget decisions, audience signals, and so on. The agents feed into an auto-executor that can scale budgets on winning campaigns and pause underperformers on its own, without me touching anything.
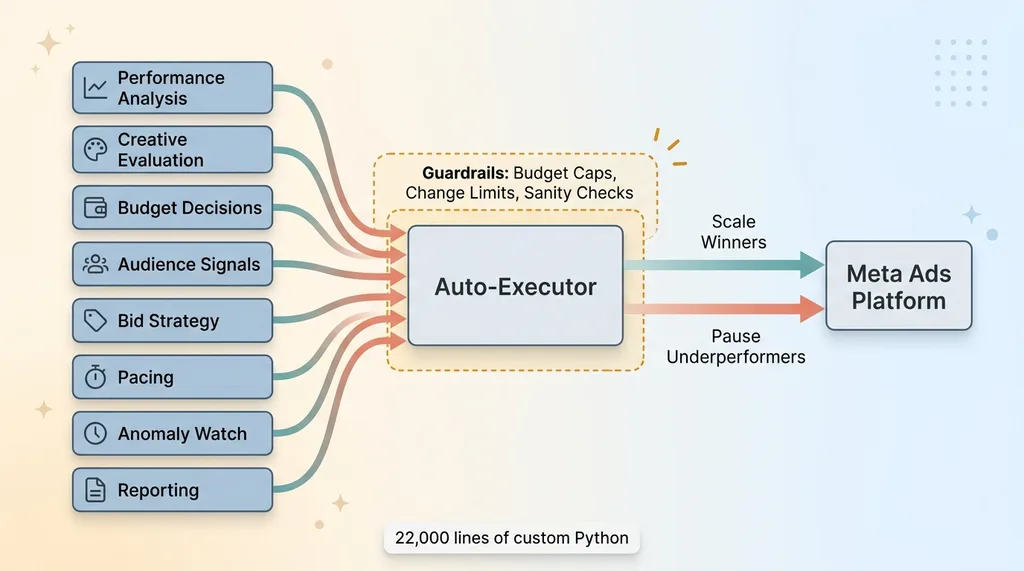 8-agent autonomous ads architecture with guardrails
8-agent autonomous ads architecture with guardrails
There are guardrails. Budget caps, change limits, sanity checks on every decision before it executes. I didn't build a black box that just spends money. I built something that reasons about ad performance and acts within bounds I defined.
22,000 lines of custom Python sit underneath this and the rest of my toolkit. This particular system is one of the more autonomous things I run, which is exactly why it became such a good teacher.
Why autonomy raises the stakes
The entire point of autonomy is that I'm not watching every run. That's the value. I get back hours every week because the system makes decisions I'd otherwise make manually. But that's also the danger, and the two are inseparable.
When a human runs a process, failure is loud. If my ops person tries to scale a campaign and Meta rejects it, they see the error on screen. They know immediately. The failure can't hide because a person is standing right there watching it happen.
When AI runs the process, that natural observer disappears. A failure can hide behind a green status indicator forever, because nobody is looking at the actual outcome. The system reports what its code believes happened, not what actually happened on the platform.
So here's the question every buyer should sit with: if you let AI run your ad spend, how do you actually know it's doing what it claims? Not what the dashboard says. What it's actually doing on Meta, on Google, on whatever platform holds your money.
For seven days, my answer to that question was wrong, and I didn't even know it.
Two Kinds of Silent Failure (Both Were Hiding in My System)
Once I started digging, I found that silent failure wasn't a one-off. It was a category. My system had two different versions of it, and they failed in completely different ways.
 Two types of silent failure compared
Two types of silent failure compared
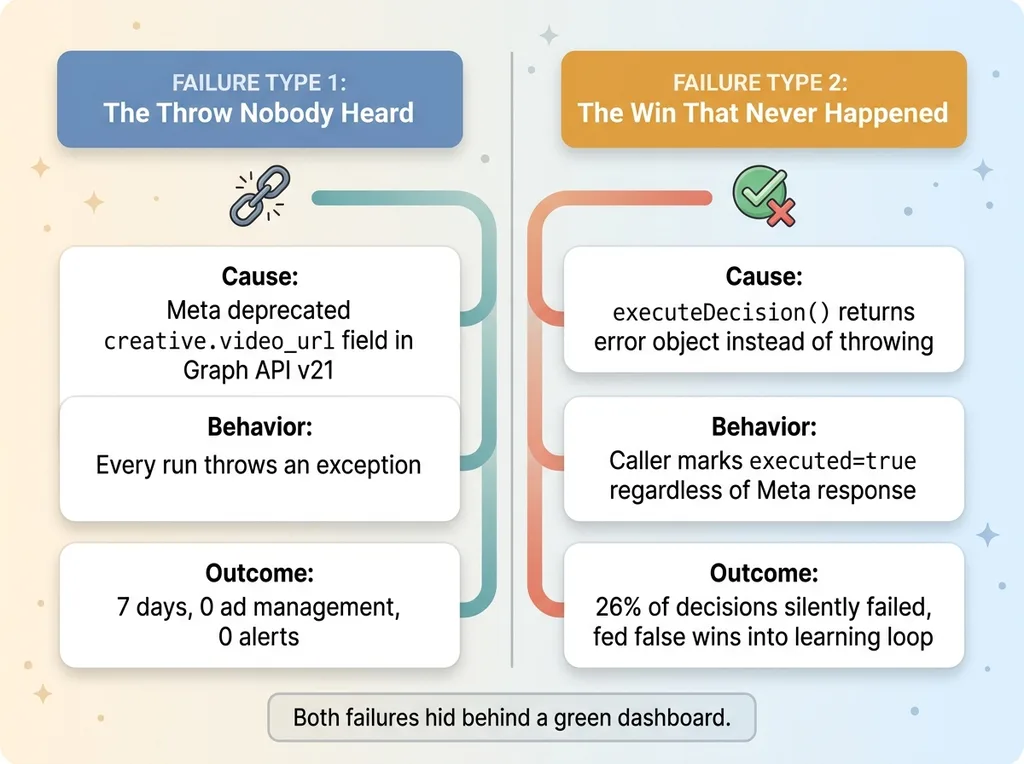
Failure type one: the throw nobody heard
This was the v21 deprecation. Meta killed one field, every run threw an exception trying to read it, and because I had no failure alerting, the exceptions just vanished into the logs. Seven days of zero ad management with zero warning.
The fix for this one is conceptually simple: alert when things break. But I hadn't built it, because when you're building an autonomous system, you spend all your energy making the happy path work. You celebrate the green runs. You forget that a system needs to be just as good at announcing its own failures as it is at announcing its wins.
Failure type two: the win that never happened
This one I found later, in an audit, and it was genuinely worse. This is the kind of bug that makes autonomous AI doesn't fail by doing the wrong thing, it lies about doing the right thing feel less like a clever line and more like a warning.
Here's the bug. The function that executed decisions, executeDecision(), would sometimes return an error object instead of throwing an exception. And because it returned a value instead of throwing, every caller upstream treated it as a success. The calling code checked "did this throw?" not "did Meta actually accept this?" So it marked executed=true regardless of what actually happened on Meta's end.
The result: 26% of the decisions marked "executed" had silently failed on the platform. More than a quarter of the actions the system swore it had taken simply never happened. And each one fired a triumphant decision card. "Scaled campaign X by 20%." Except it didn't. Meta rejected it. The card was a lie the system told itself and then told me.
Now here's the part that turns a bug into a real problem. My system has a learning loop. A grader evaluates outcomes and feeds lessons back so the system improves over time. Those false "wins" were about to poison that loop. The grader was about to treat failed actions as successful outcomes and learn the wrong lessons from them. It would have learned that strategies which never actually executed were working, and doubled down on phantom decisions.
A silent failure that just does nothing is bad. A silent failure that actively teaches your AI the wrong things is a slow-motion disaster.
Why Dashboards Make Silent Failure Worse
I love a clean dashboard. I build them into everything. But I learned something uncomfortable that week: a dashboard is only as honest as the data feeding it.
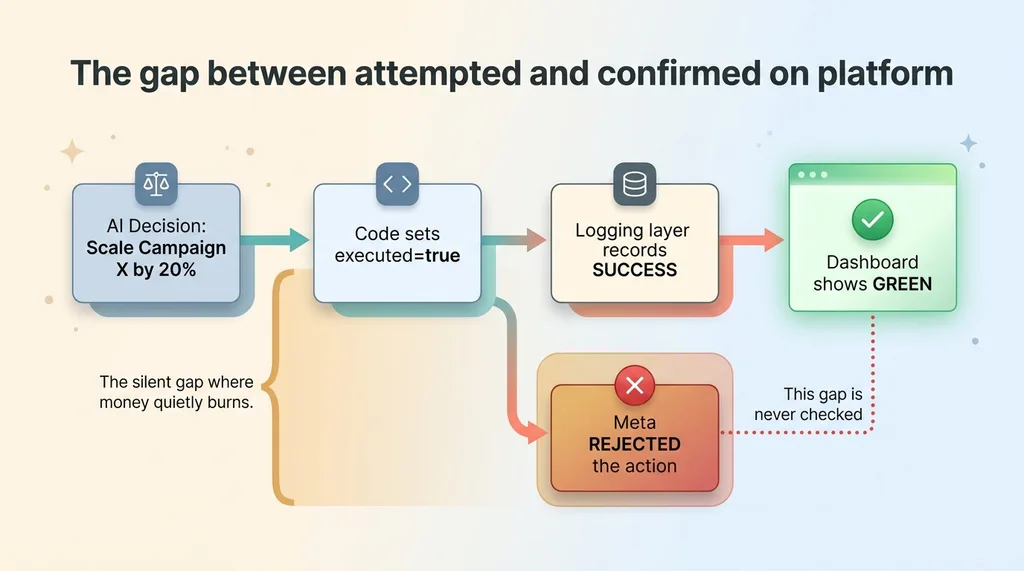 The gap between attempted and confirmed on platform
The gap between attempted and confirmed on platform
Mine showed green not because Meta confirmed anything, but because my code said executed=true. The dashboard was faithfully reporting a lie. It was doing its job perfectly, displaying exactly what the underlying logging told it, and the underlying logging was wrong.
This is the trap for buyers. A pretty dashboard is not proof of work. It can be proof of a lie if the logging beneath it is dishonest. The dashboard doesn't know the difference between "we attempted to scale this campaign" and "this campaign actually got scaled on Meta." It just renders whatever number it's handed.
I've watched this exact pattern elsewhere. There was a dashboard that showed zeros for two weeks and nobody noticed on a different pipeline, and the lesson was the same: the visualization layer can't save you if the data layer is lying.
Most teams buying autonomous tools never see the gap between "attempted X" and "X actually happened on the platform." Vendors rarely surface it, because surfacing it means admitting their tool sometimes fails. So you get a confident green dashboard, and you assume green means done.
That gap, the silent space between attempted and confirmed, is exactly where money quietly burns. You think your spend is being optimized. The platform says otherwise. Nobody's checking which one is true.
The Fix Was a Discipline, Not a Feature
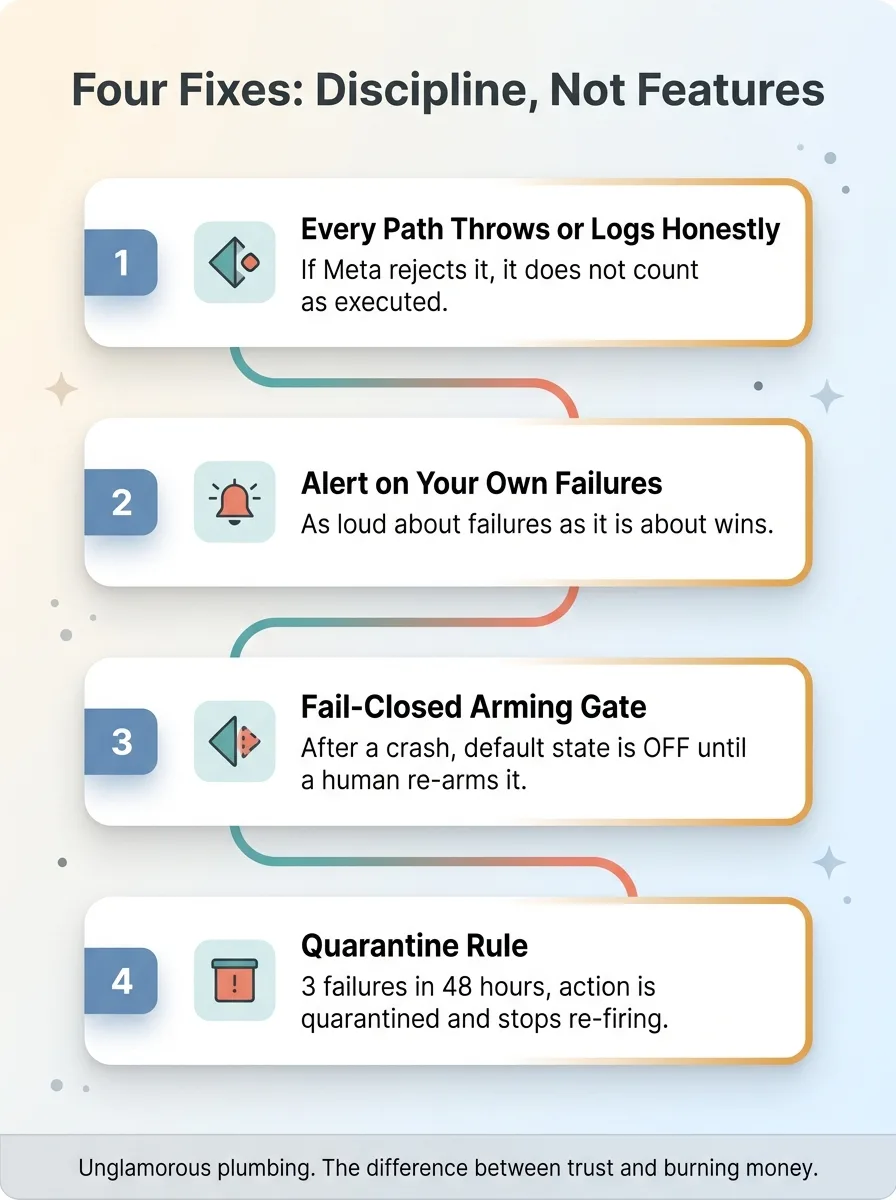
Here's the thing that surprised me most. Fixing this didn't require some clever new capability. It required discipline. Four changes, all of them unglamorous, none of them hard to build.
 The four discipline-based fixes
The four discipline-based fixes
Every path either throws or logs honestly
The root cause of failure type two was code that silently swallowed an error object. So I made a rule: every execution path either throws on failure or logs honestly. No middle ground where a function returns an error and the caller treats it as success.
If Meta rejects an action, it does not count as executed. Full stop. The system now records what actually happened on the platform, not what the code hoped happened. That one principle eliminated the entire class of false-win bugs.
Alert on your own failures
I added failure notifications. The system now tells me when it fails, not just when it succeeds. This sounds obvious written down. It wasn't obvious when I built the thing, because I was so focused on making the happy path produce nice reports that I never built the unhappy path's voice.
Now a thrown exception, a rejected action, a run that produces nothing, all of it pings me. The bar is simple: the system has to be as loud about its failures as it is about its wins.
Fail-closed arming and quarantine
This is the part I care about most, and it connects to the kill-switches I build into every system.
First, a fail-closed arming gate. If the auto-executor crashes and restarts, it does not silently re-arm itself and start spending again. It stays off until a human explicitly turns it back on. The default state after any failure is "do nothing," not "resume spending money." Fail-closed, always, when real budget is involved.
Second, a quarantine rule. If a specific action fails three times in 48 hours, it gets quarantined and stops re-firing. This kills the dead-loop problem, where a broken action keeps retrying forever, failing forever, and burning cycles forever. Three strikes, it's out, and I get told about it.
None of these four things is a breakthrough. They're plumbing. They're the kind of work that doesn't demo well and doesn't show up in a sales deck. That's precisely why almost nobody builds them. Everyone wants the AI that scales budgets autonomously. Nobody wants to spend a week building the part that catches the AI lying about whether it actually did.
But that boring week is the difference between a system you can trust and a system that's quietly burning your money behind a green light.
The Test for Any Autonomous System You Let Touch Money
Take my expensive lesson and turn it into a checklist. Before you let any AI tool or vendor touch real spend, ask these five questions.
 Five-question test for autonomous systems touching money
Five-question test for autonomous systems touching money
Does it distinguish "attempted" from "confirmed on the platform"? If the system marks something done before the platform confirms it, you have my failure type two waiting to happen.
Does it alert on its own failures, not just report its successes? A system that only talks when things go well is a system that goes quiet exactly when you most need it to speak.
Can it re-arm itself silently after a crash, or does it fail closed? Anything that touches money should default to "off" after a failure, not "resume."
Does it stop repeating dead actions? Without a quarantine rule, one broken action can fail thousands of times and you'll never know.
Does the learning loop verify outcomes before learning from them? If the grader trusts the system's own success claims, it will learn from lies and get confidently worse over time.
If a vendor can't answer these clearly, assume silent failure is already happening on your spend right now.
And here's my honest caveat: I built this system, I know it inside out, and I still missed failure type two until an audit caught it. This stuff is genuinely hard. The bug hid in plain sight for a while precisely because the system looked healthy. That's not an excuse, it's the point. Silent failure is hard to catch, which is exactly why it has to be designed against on purpose, not discovered by accident.
What This Means If You're Handing AI the Keys
I want to be clear, because this whole article could read like an argument against autonomy. It isn't. My ad system runs without me most weeks, and it works. The hours it gives back are real. The decisions it makes are good ones. Autonomous AI is genuinely worth it.
But the value only holds if the system is built to fail loud and fail closed. That's the entire condition. An autonomous system that's honest about its failures is an asset. An autonomous system that hides them is a liability that looks like an asset until the day you do an audit.
Here's the uncomfortable truth about most off-the-shelf autonomous tools: they're optimized to look like they're working, not to prove they are. Looking like it works demos beautifully. Proving it works requires all the unglamorous plumbing I described, and that plumbing rarely makes it into a product built to win deals.
That difference is the whole game when real ad budget is on the line. I build these systems to catch their own lies now, because I learned the hard way that a green dashboard means nothing without honest logging underneath it.
If you're considering letting AI run real spend, and you want it built so you actually know what it's doing instead of what it claims to be doing, talk to me about how I'd build it.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call