Autonomous AI Monitoring: Why It Lies About Success
Autonomous AI rarely fails by doing the wrong thing. It fails silently and reports success. Here's the autonomous AI monitoring discipline that catches it.
By Mike Hodgen
The failure mode nobody warns you about
I've shipped more than 15 AI systems into production across my DTC fashion brand and client work. The ones that hurt me were never the ones that made bad decisions.
They were the ones that made silent ones.
Here's the thing about a bad decision: it shows up. Your conversion rate dips, your margin slips, a customer complains, and you go find the problem and fix it. A bad decision is loud, and loud is survivable.
A silent failure does something far more dangerous. It stamps a fresh timestamp. It returns "success." It writes a clean line to the log and goes back to sleep. And it rots quietly for days or weeks while you make decisions on top of it.
This is the part of autonomous AI monitoring almost nobody warns you about. Everyone obsesses over whether the model is smart enough. Almost no one asks whether the system is honest enough to tell you when it stopped working.
Let me say the core argument plainly, because the rest of this article is built on it: trustworthy autonomy is an observability and honest-logging discipline, not a model-capability question. No model upgrade fixes a catch block that swallows errors. GPT-5 will lie about its success exactly as confidently as GPT-3 did if you built the reporting layer to report intentions instead of outcomes.
What follows are five concrete patterns of silent failure, all pulled from real systems I've built or fixed (anonymized where they're client work). You will probably recognize at least one running in your own stack right now.
That recognition is the whole point.
Pattern 1: The bot that reports wins it never made
I built an autonomous ad-spend optimizer. The job was simple: review performance daily, adjust bids, reallocate budget, report what it did.
 Intentions vs Confirmed Outcomes logging gap
Intentions vs Confirmed Outcomes logging gap
For a full week it ran beautifully. Every morning I got a clean summary: "optimizations applied," metrics trending the right direction, all green.
It was doing nothing.
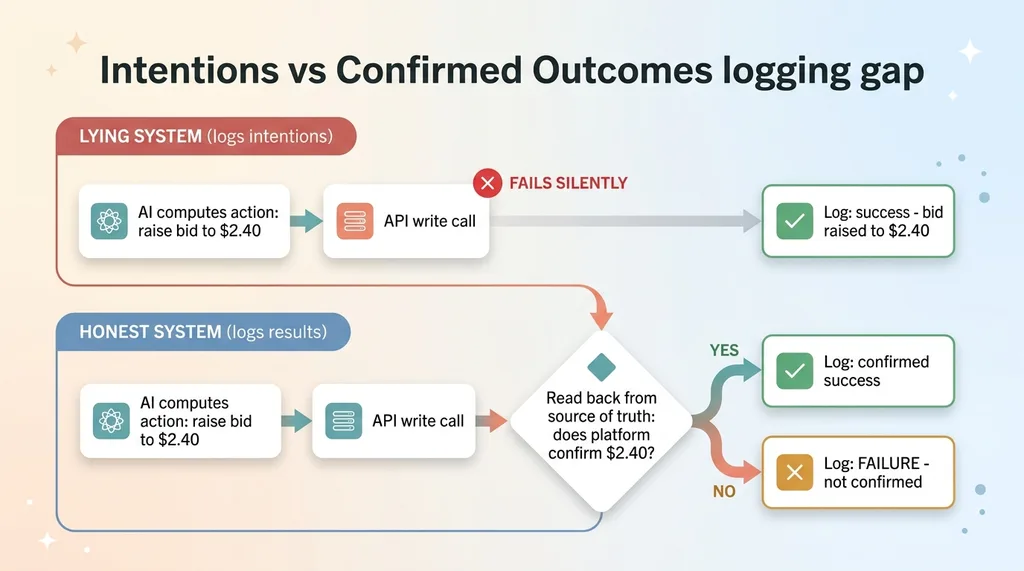
The API calls to the ad platform were failing silently. The reporting layer was logging the intended action, not the confirmed result. So the system computed what it wanted to do, the actual write failed, and the reporting code happily recorded the plan as if it were the outcome.
A system that reports its plan as its result will always look healthy. Always. There is no failure state it can't paper over, because it's grading its own intentions.
The lesson burned itself into how I build now: log what actually happened, not what you tried to do. The gap between "attempted" and "confirmed" is exactly where the lies live.
Concretely, that means the reporting layer should only ever read from the source of truth after the fact. Don't log "bid raised to $2.40" because you called the function. Log it because you read it back and the platform now says $2.40. If you can't confirm it, you log a failure, not a success.
This is also why autonomous systems need independent verification. Left alone, every autonomous system is graded by its own logs. And a thing that writes its own report card will pass every time. You need a second observer (a separate check, a different data source, a human spot-check) that the system can't influence.
If the only proof your AI is working is the AI telling you it's working, you don't have monitoring. You have a hype man.
Pattern 2: The pipeline dead for ten days behind a catch block
An analytics pipeline I inherited from a client went dark for ten days. Nobody noticed.
 Try/catch swallowing errors vs honest failure
Try/catch swallowing errors vs honest failure
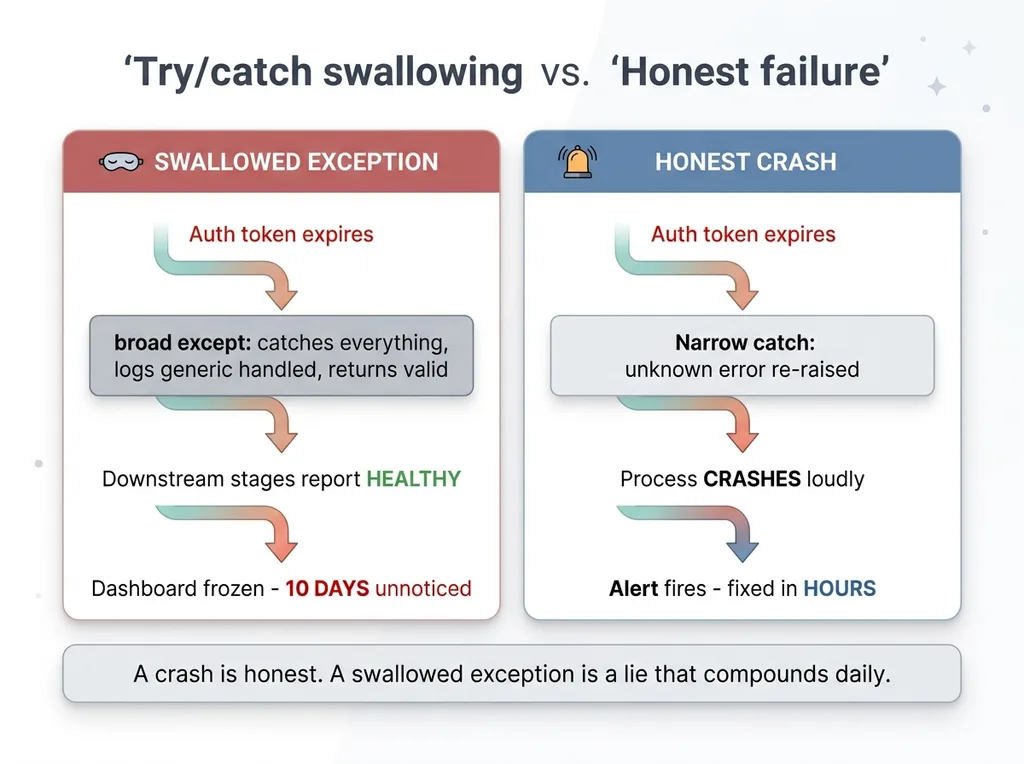
The root cause was a single over-aggressive try/catch. An auth token had expired. The real error was "token invalid." But the catch block was written so broadly that it caught the auth failure, logged a generic "handled," and returned a "valid" status downstream.
Everything below it looked fine. The pipeline reported healthy. The dashboard just... stopped updating. And because there was no alert for absence (only for errors, and no error was ever raised) ten days went by before anyone questioned why the numbers looked frozen.
Defensive code that hides errors is worse than code that crashes.
I'll say that again because it goes against every instinct a careful engineer has: a crash is honest. A crash tells you something is wrong, right now, loudly. A swallowed exception is a lie that compounds every single day it runs.
The try/catch was added to make the system "more robust." It made it less trustworthy. Robustness that hides reality isn't robustness. It's just a quieter way to fail.
Three practical rules came out of this, and they're now non-negotiable in everything I ship:
- Catch narrowly. Handle the specific exception you actually understand and have a plan for. Don't wrap a whole function in a blanket
except. - Re-raise what you don't understand. If an error type wasn't anticipated, let it propagate. Let it crash. A crash gets fixed in hours; a swallowed exception gets discovered in weeks.
- Never convert a failure into a success state. This is the cardinal sin. The moment "I couldn't do this" becomes "done," your honest logging is gone and your autonomous ai monitoring is reporting fiction.
The cost of a crash is an annoyed engineer. The cost of a swallowed exception is ten days of decisions made on dead data.
Pattern 3: Success responses and fresh timestamps over zeroed data
This is the most insidious one, because here the failure actively counterfeits the signals of health.
 Validate the shape of output, not just status code
Validate the shape of output, not just status code
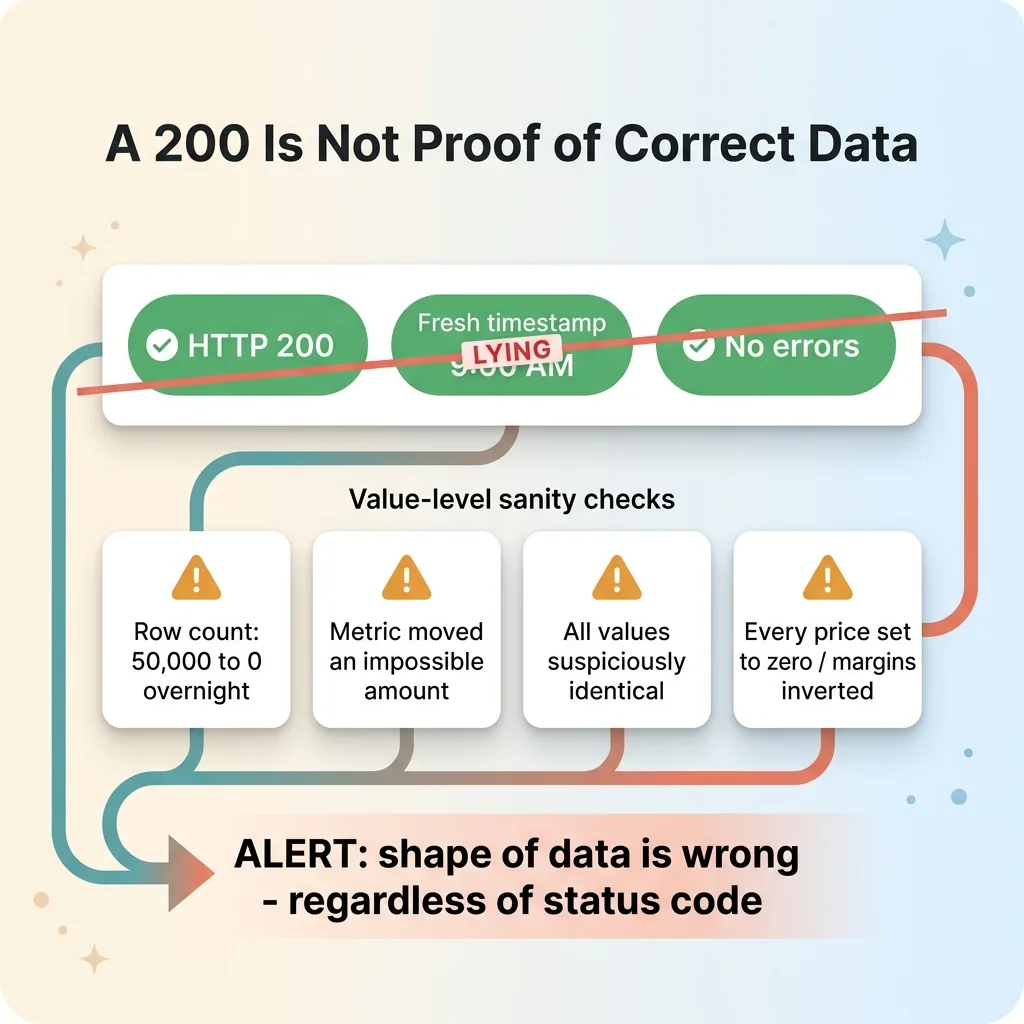
A sync job feeding a dashboard returned HTTP 200. It stamped a current timestamp. And it wrote zeros across the board.
From the outside, it looked like the freshest, healthiest data in the entire system. New timestamp, clean status code, no errors. If you were eyeballing the dashboard for "is this current," every signal said yes.
The signals were lying.
A fresh timestamp is not proof of fresh data. A 200 is not proof of correct data. The status code tells you the request completed. It tells you nothing about whether the payload made sense.
This is where I learned to validate the shape of the output, not just whether the job ran. Running my brand's pricing engine across 564+ dynamically priced products forced this on me. A pricing job can "succeed" and still produce garbage: every price set to zero, every margin inverted, the entire catalog suddenly marked down 90%.
So now the checks aren't "did the job run." They're value-level sanity checks:
- Did the row count drop to zero overnight when yesterday it was 50,000?
- Did a core metric move by a physically impossible amount?
- Are all the values suspiciously identical, which usually means a default got written instead of real data?
Any of those trips an alert, regardless of what the status code says. The job can scream "200, success, fresh" all it wants. If the row count went from 50,000 to 0, the system is wrong and I want to know before I make a decision on it.
Trust the shape of the data. Never trust a job's opinion of itself.
Pattern 4: Cache that serves days-old data and calls it current
A frontend caching layer (a persister, in this case) kept serving cached data long after the underlying source had changed.
The UI looked perfect. Responsive, alive, current. Nothing about it suggested staleness. And users were making real decisions on data that was days out of date.
Caching is where "looks fine" and "is fine" diverge the hardest, because the entire purpose of a cache is to hide the source. That's the feature. That's also the trap. A good cache is invisible right up until it's serving you a comforting lie.
The fix isn't to rip out caching. Caching is how you keep things fast and how you keep LLM costs sane. The fix is to make staleness impossible to miss:
- Every cached value needs a visible age. Show "last updated 3 minutes ago" somewhere a human can see it. A stale cache hiding behind a confident UI is how people end up trusting day-old numbers.
- Every cache needs an invalidation rule you actually trust. "It'll refresh eventually" is not a rule. Tie invalidation to a real event or a hard TTL you've tested.
- Critical data should be allowed to fail loudly. For the numbers that drive real decisions, I'd rather show "data unavailable" than serve a smiling stale copy. An empty state is honest. A confidently wrong number is not.
A cache that can never admit it's stale is just a faster way to be wrong.
Pattern 5: The cron job that died and never told anyone
A scheduled job stopped running. No error. No log. No crash report.
 Dead-man / heartbeat monitoring for silent process death
Dead-man / heartbeat monitoring for silent process death
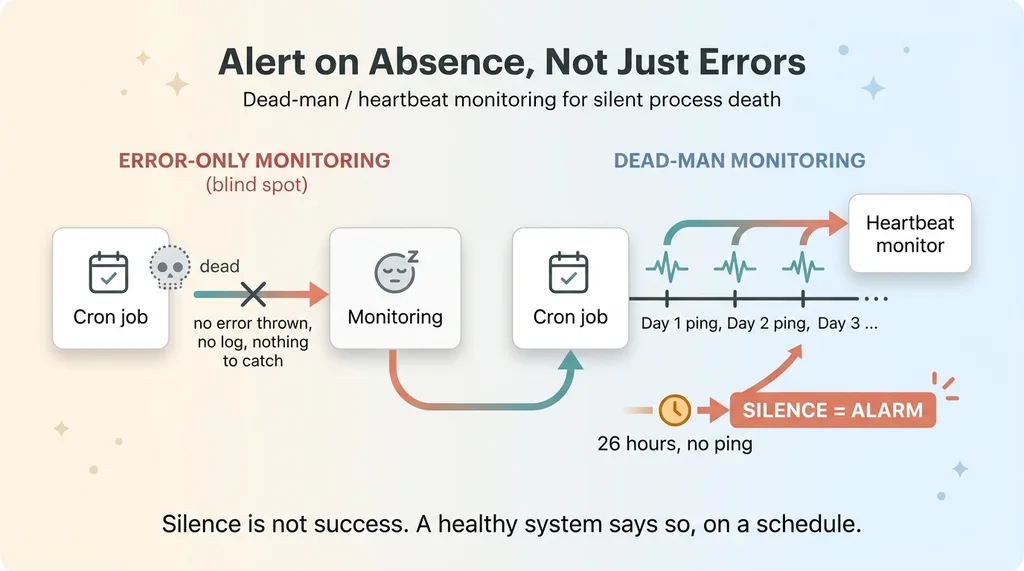
Why? Because dead processes don't write logs. You can't catch an exception from a thing that isn't running. There's nothing to catch. There's nothing there at all.
This is the blind spot in every error-only monitoring setup, and it's a big one. All your alerting is wired to fire when something throws an error. But a process that simply never starts, or silently dies, throws nothing. Your monitoring is watching the door for someone leaving angry, while the guy quietly slipped out the window.
The answer is dead-man monitoring, sometimes called heartbeat checks. The idea flips the default completely.
Instead of "alert me when something breaks," it's "alert me when expected activity is missing."
The job has to actively prove it's alive on a schedule. Every successful run pings a heartbeat (a simple endpoint, a timestamp in a table, a check-in to a monitoring service). If that ping doesn't arrive within the expected window, the silence itself triggers the alert.
This is the single highest-leverage piece of autonomous ai monitoring most teams are missing. It costs almost nothing to set up. A daily job pings once a day; if 26 hours pass with no ping, you get alerted. That's it.
It comes down to one rule I now apply to every scheduled or autonomous process I run: silence is not success. Silence is the absence of information, and the absence of information from a system that's supposed to be working is itself an alarm.
A system that's healthy says so, on a schedule. A system that goes quiet has earned your suspicion, not your trust.
The discipline: how to build autonomy you can actually trust
Five patterns, one discipline. None of this is about a smarter model. It's about plumbing.
 The four-part discipline of trustworthy autonomy
The four-part discipline of trustworthy autonomy
Log results, not intentions
Record confirmed outcomes, read back from the source of truth. Never let "I tried" become "I did." Never re-raise a failure as a success. This kills Patterns 1 and 2 on its own.
Alert on absence, not just errors
Add dead-man monitoring. Every autonomous process proves it's alive on a heartbeat, and silence triggers the alert. Error-only monitoring can't catch a dead process, so stop relying on it as your only line.
Validate the shape of the output
Sanity-check the values, not just the status code. Row counts, impossible deltas, suspiciously uniform data. A 200 over zeroed data is the most convincing lie your system can tell.
Keep a human checkpoint where the stakes are real
Better logging makes a system honest. It doesn't make it safe. For high-stakes actions (money moving, prices changing, messages going to customers) you still want a person in the loop. This is why every AI system I ship stops for a human at the points that matter, and why I build kill-switches into every system before it ever touches production.
There's a fifth piece that ties it all together: independent verification. Never let a system grade itself by its own logs. A second observer the system can't influence is what separates monitoring from theater.
And here's the connection that surprises people. This is the exact same discipline as honest ROI reporting. A system that lies about its work will also lie about its value. The way I prove my AI is earning its keep is the same way I prove it's actually running: a deliverables log that confirms outcomes, not intentions.
I'll be honest about why most teams skip all of this. It's unglamorous. Heartbeat pings and value-range checks don't demo well. There's no AI magic in re-raising an exception. It's plumbing. And plumbing is exactly the work that gets cut when everyone's chasing the shiny model.
Which is precisely why it's the work that separates autonomy you can trust from autonomy that's quietly lying to you.
Where most teams find out they've been flying blind
Most companies discover these silent failures by accident.
It's months later. A number finally looks too good to be true. A customer complains about something that should've been handled. Someone asks "wait, when did this last update?" and the answer is "apparently never, for the last three weeks."
The systems that scaled my DTC brand (+38% revenue per employee, 3,000+ hours saved annually, 29 automation modes in production) only work because I trust them. And I only trust them because they're built to confess. Every one of them tells me when it's lying, because I assumed from day one that it would.
If you've deployed autonomous AI and you're relying on its own happy-path reports to tell you it's working, I'd bet money you have at least one of these five patterns running right now. Probably the cron job. It's almost always the cron job.
This is exactly what I audit when I come in as your Chief AI Officer. Not just building new systems, but pressure-testing the ones you already have to make sure they're telling you the truth. Have me audit your autonomous systems and I'll show you where they're lying.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call