Configurable Product Software Architecture Done Right
How I built a configurable product software architecture that handles real complexity without bloat: data as config, code as engine, and a one-file plugin registry.
By Mike Hodgen
The Trap: Building Five Engines for a Business That Needs Two
A custom manufacturing client came to me with a configurable product software architecture problem that looked simple on the surface and was anything but. They made window treatments. Shades, blinds, the kind of product where a customer picks a fabric, a size, a mount type, and the price changes based on the combination.
Their instinct was to build software that could handle every product family they might ever sell. Roller shades today, but maybe motorized systems, maybe outdoor screens, maybe shutters, maybe something they hadn't even named yet. Five product types on the whiteboard, five separate engines to handle each one.
This is the trap, and AI makes it worse. When generating code is cheap, building five speculative engines in an afternoon feels free. It is not free. Every engine is code that has to be tested, maintained, and reasoned about during every future change. Five engines means five times the surface area for bugs. Five pipelines to fork. Five places a single change ripples through and breaks something you forgot existed.
Most of that code would serve products that might never sell. You pay to build it, then you pay forever to maintain it, and the payoff is a system that does things nobody asked for.
The buyer doubt underneath all this is fair and worth saying out loud: how do you handle real product complexity without building something so tangled it costs a fortune every time you want to change it?
The answer is not "build less." It is "build for what you can prove, and design so the rest is cheap to add later." Those are two different disciplines. The first is about data. The second is about architecture. Get both right and complexity stops being expensive.
Query the Order Mix Before You Write a Line
The first thing I did was not draw a diagram. I ran a SQL query against their actual order history.
 Order Mix Data Killing Speculative Engines
Order Mix Data Killing Speculative Engines
The result settled the argument fast. Roughly 83% of volume was one core product. About 13% was accessories. The speculative families they were excited about, the ones that justified three of the five planned engines, were essentially zero. Not "small." Zero.
Real numbers killed three engines before a single line of code existed.
This is the move most teams skip. Scope is a data question, not an opinion. The list of products you're excited to support and the list of products that actually generate revenue are almost never the same list, and the gap is where over-engineering lives.
I make this case constantly: let real data decide scope before you build. The order table already knows what your business is. You just have to ask it.
The discipline that came out of this is simple to state. Build for the demand you can prove. Design for the demand you can't yet. Those are different commitments. Proven demand gets a working engine. Unproven demand gets a clean seam to plug into later, and nothing more.
For the buyer, this is also a cost conversation, and a direct one. You do not pay to build engines nobody uses. You do not pay to maintain them year after year. You do not pay for the bugs they introduce into the products that actually sell. The query that took ten minutes saved months of speculative work and the ongoing tax that comes with it.
Two engines justified by data beat five engines justified by a meeting.
Data as Config: Product Options Live in Tables, Not Code
Once scope was settled, the architecture split into two halves. The first half is data as config, and it's where most of a product configurator actually lives.
The three-layer option model
Product types, option groups, and options all live as data rows. Not code. A roller shade is a product type. "Fabric," "size," "mount type" are option groups under it. "Linen White," "Charcoal," "Inside Mount" are options inside those groups. Three layers, all rows in tables, all editable without touching the codebase.
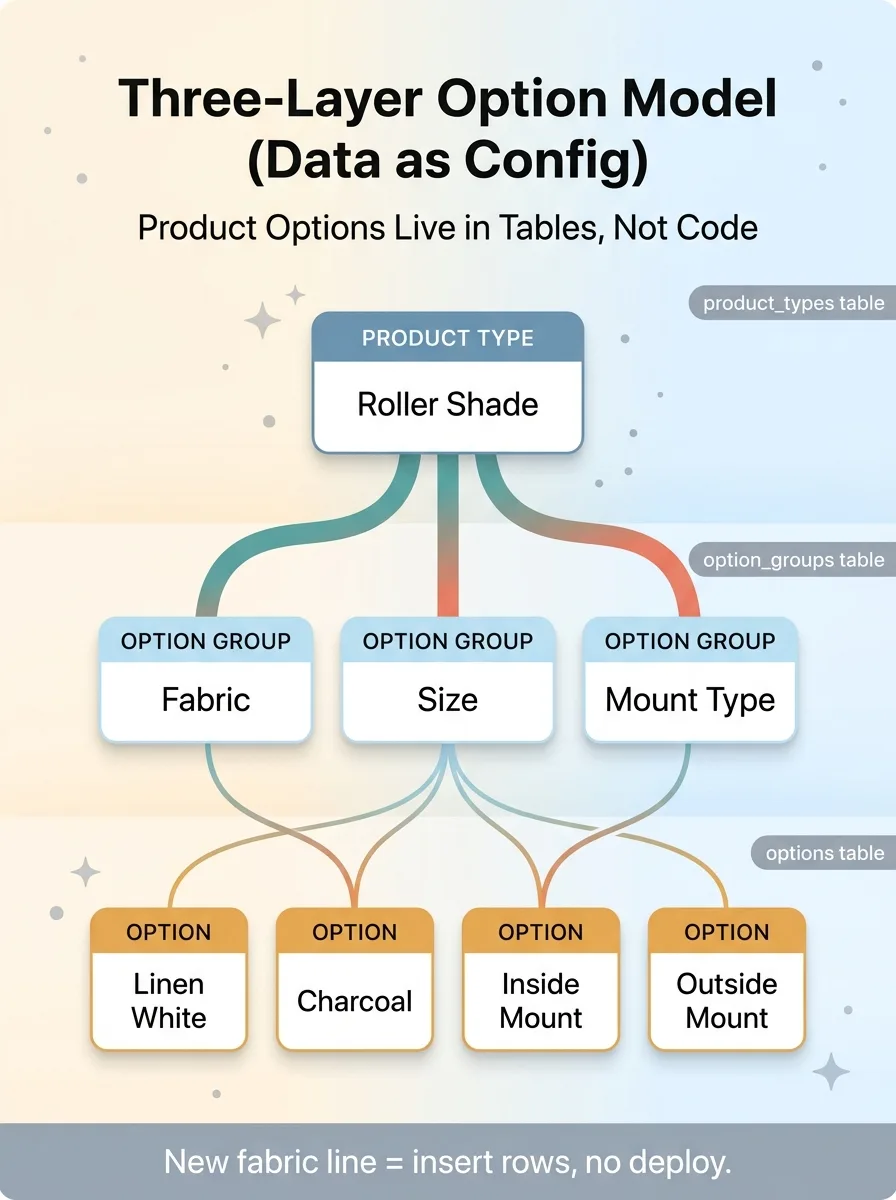 Three-Layer Option Model (Data as Config)
Three-Layer Option Model (Data as Config)
This is the data-as-config half of the data-as-config, code-as-engine pattern, and it's the difference between a catalog that grows by data entry and one that grows by software project.
Why a new option is a row, not a deploy
Here is the test that matters. When this manufacturer launches a new fabric line next spring, what does it take to support it?
The answer is data entry. Someone on their team inserts rows for the new fabrics. The configurator picks them up automatically. No engineer, no deploy, no release window, no risk to the products already selling.
Contrast that with the common failure. In a lot of systems, every product variation is baked into conditional logic. if fabric == "linen" and mount == "inside" scattered across the code in a dozen places. Every new option means editing that logic, retesting it, and praying you didn't break a branch you forgot about. That is what makes configurators brittle and expensive to change. It's also why so many of them calcify a year after launch and nobody wants to touch them.
A new fabric line should be a Tuesday afternoon for someone in operations, not a quarter of engineering time. When options are data, it is.
Code as Engine: Assembly Logic Behind a Shared Contract
The second half is code as engine, and it handles the things data tables genuinely cannot.
Assembly and pricing logic involves real rules. Unit math. Physical constraints. A shade has a minimum and maximum width. The fabric yardage depends on dimensions you can't enumerate as rows because they're continuous. The price isn't a lookup, it's a calculation. That belongs in code, because it's actual logic, not configuration.
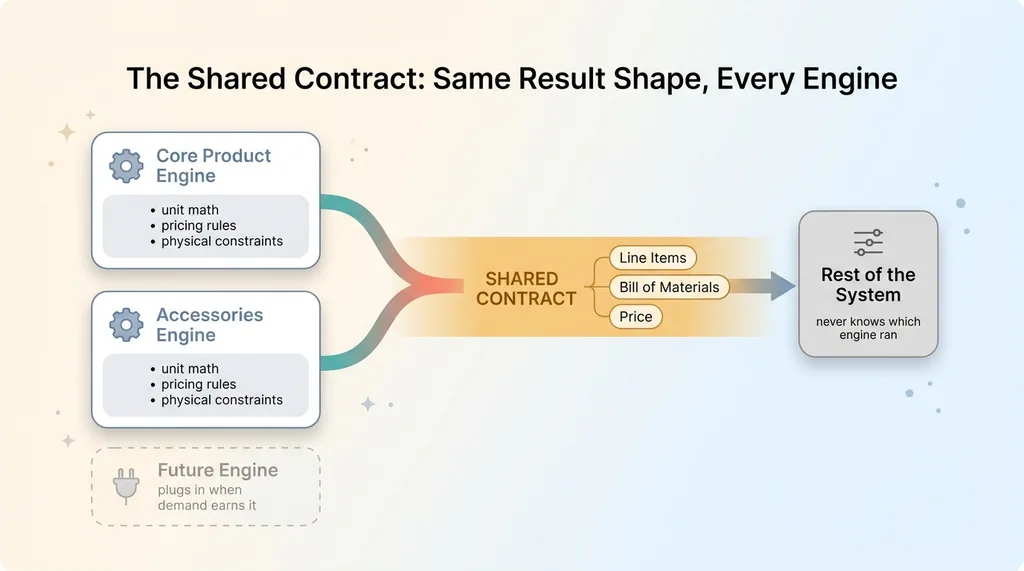
Every engine returns the same result shape
The single most important design decision in the whole system was the shared contract. Every engine, no matter the product family, returns the same result shape: line items, a bill of materials, and a price.
 Shared Contract Making Engines Interchangeable
Shared Contract Making Engines Interchangeable
That uniformity is what makes engines interchangeable. The rest of the system never has to know which engine ran. It asks for a result, gets the same shape every time, and moves on.
Two engines, not five
We built exactly two engines. The core product and accessories. Both sit behind the shared contract. Both produce identical output structures even though their internal logic is completely different.
This matters more than the engines themselves. The contract is the seam. It's the part of the architecture that lets the system grow without forking. The engines are just implementations behind it, and implementations are replaceable. The contract is the thing you protect.
Building only the two engines that the order data justified meant the contract had two implementations to prove it worked. Not five untested ones to prove it might. The seam was real, exercised, and ready for the next engine whenever demand actually earned one.
The Plugin Registry: Adding a Product Family Is One File
This is the payoff, and it's where the configurable product software architecture earns its keep.
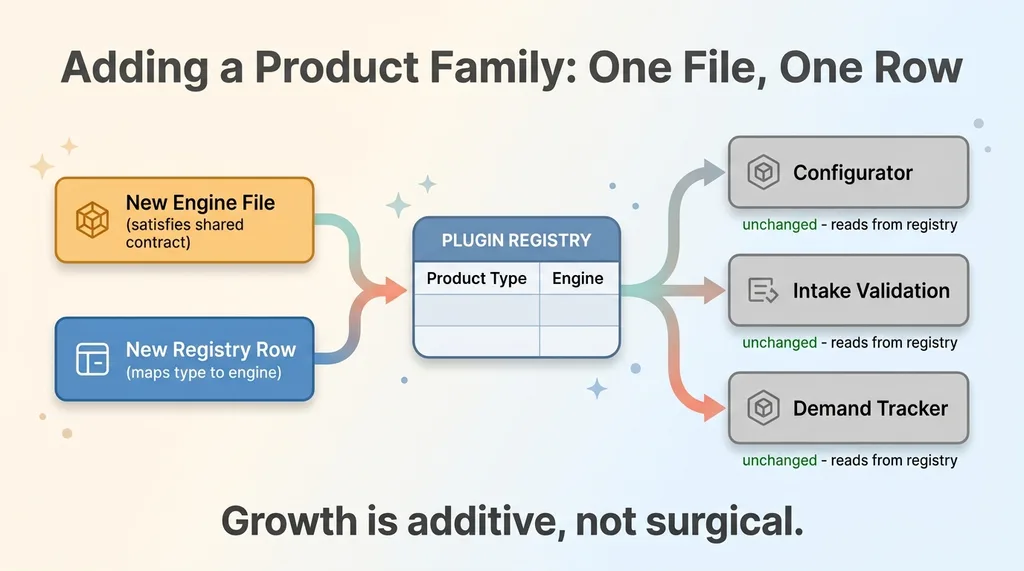
The system uses a plugin registry pattern. In plain terms, that's a lookup table mapping a product type to the engine that handles it. The configurator doesn't contain logic about which engine to call. It looks the product type up in the registry, gets the engine, and runs it.
One engine file, one data row
When a new product family eventually earns its place through real demand, here's what adding it takes.
One engine file that satisfies the shared contract. One data row registering it in the plugin registry. That's the whole job.
You're not editing the configurator. You're not editing intake. You're not hunting through the codebase for every place that needs a new conditional branch. You write one file, add one row, and the family exists.
No pipeline fork
Everything that consumes the registry picks up the new family automatically. The configurator sees it. The intake validation sees it. The demand tracker sees it. None of them changed, because none of them ever hardcoded the list of products in the first place. They all read from the registry.
 Plugin Registry - Adding a Product Family
Plugin Registry - Adding a Product Family
This is the direct answer to the buyer doubt from the start. Growth is additive, not surgical. You're not performing open-heart surgery on a working system every time the business expands. You're adding a part to a system designed to accept parts.
The plugin registry pattern is cheap to extend and hard to break, and those two properties come from the same source. There's no scattered conditional logic to get out of sync, because there are no scattered conditionals. There's a registry and a contract, and new things plug into both. The system that took data discipline to scope correctly now takes almost nothing to grow.
That's the inversion that makes this worth doing. Most systems get harder to change as they grow. This one stays the same difficulty: one file, one row, every time.
One Bill-of-Materials Brain Feeds Everything
The shared contract pays off a second time, and this is where the design really compounds.
 One BOM Brain Feeds Three Consumers
One BOM Brain Feeds Three Consumers
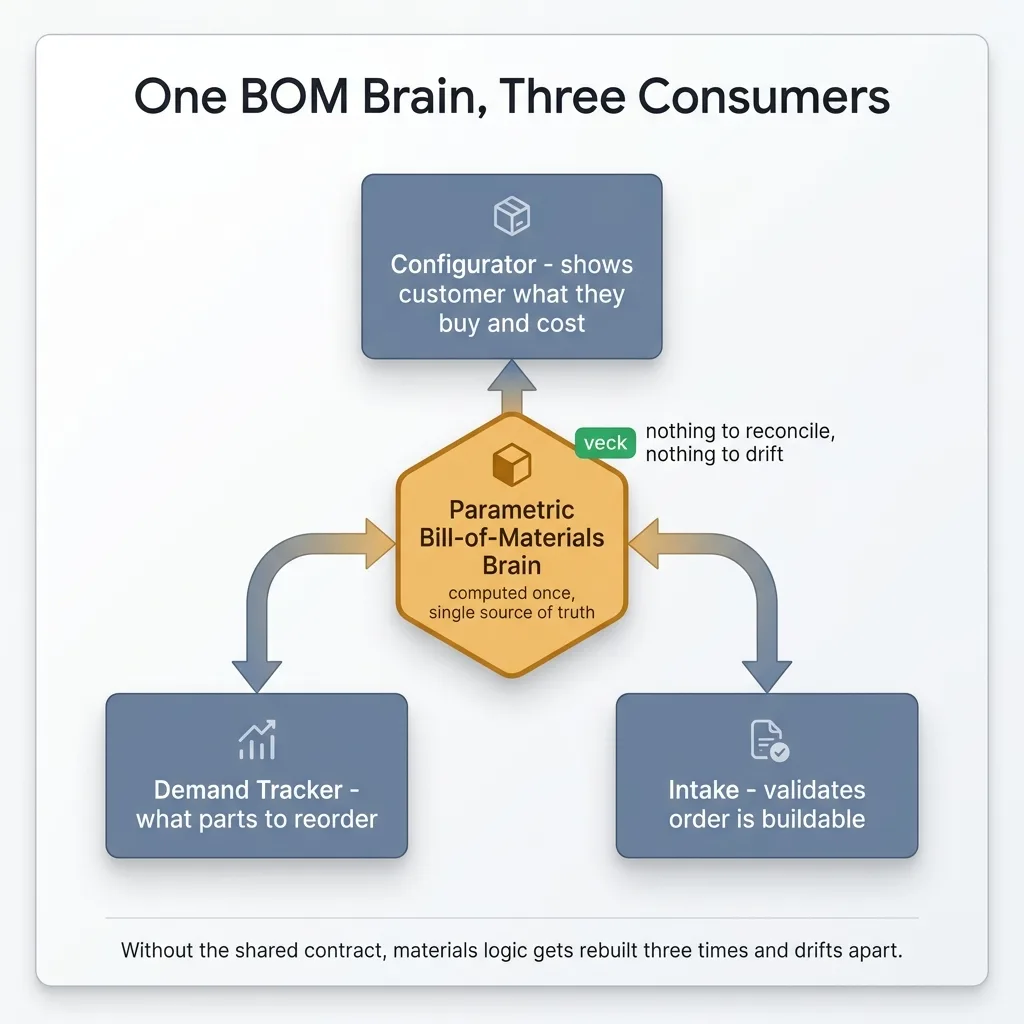
Because every engine produces the same bill-of-materials shape, a single parametric bill-of-materials brain powers three different parts of the business from one source of truth.
The configurator uses it to show the customer what they're buying and what it costs. The demand tracker uses it to figure out what parts to reorder across every open job at once. Intake uses it to validate that an incoming order is actually buildable. One BOM logic, three consumers.
This is the entire reason the contract discipline is worth the up-front thought. Without it, you'd rebuild materials logic three times, once for each consumer, and watch them drift apart over months until the configurator quotes one bill of materials and the warehouse orders a different one. I've seen that drift sink real operations. Reconciling it after the fact costs more than building it right would have.
With the contract, the BOM is computed once and consumed everywhere identically. The customer sees the same parts the warehouse orders and intake validates against. There's nothing to reconcile because there's nothing to drift.
One honest limitation. A genuinely novel product with a fundamentally different cost structure, something where the BOM doesn't fit the existing shape, may need real engine work. That's fine. That's exactly the case where demand has earned the investment. The architecture isn't designed to make every product free. It's designed so that the products fitting your proven model are nearly free, and the genuinely new ones get the engineering they deserve when they prove they deserve it.
The Pattern That Keeps AI-Built Systems From Bloating
Here's the lesson, and it's more important now than it was two years ago.
AI makes it trivial to generate code. That sounds like a pure win, and it changes the failure mode. Over-engineering used to be expensive enough that budgets stopped it. Now you can spin up five speculative engines in an afternoon and feel productive doing it. Then you spend the next two years drowning in the maintenance of code that serves products nobody buys.
The discipline that matters now is restraint, and it has three parts.
Let real data decide scope. Run the query before you draw the diagram. Build for proven demand.
Design the seam so growth is additive. A shared contract plus a plugin registry means new product families are one file and one row, not a surgical operation across the codebase.
Keep options as data and logic as code. Catalog changes become data entry. Real rules stay in engines. Neither one bleeds into the other.
These aren't five clever tricks. They're the same handful of primitives that power everything I build, applied with judgment about what to build now and what to leave a clean opening for. That judgment is the entire game. It's the difference between a system that's cheap to change for years and one that calcifies six months after launch.
If you're staring at a product configurator project and worried about it becoming the expensive mess that nobody wants to touch, the decision that prevents that happens before any code gets written. It's scoping with data and designing the seam. That's the work I do first, every time.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call