Debug Production Outage With AI: An 80-Agent Audit
How I used a multi-agent code audit to debug a production outage and trace 10 days of silent failure to a single over-aggressive catch block.
By Mike Hodgen
The Outage Nobody Noticed for 10 Days
Here's the scary version of a production outage: there is no outage. Nothing crashes. No alerts fire. The logs are clean. And the system has quietly stopped doing its job.
That's what happened to an internal analytics and scheduling subsystem for my DTC fashion brand in San Diego. A pipeline that pulled data, processed it, and fed a handful of downstream consumers just became a silent no-op. No 500s. No exceptions bubbling up. Scheduled jobs fired on time, every time, into the void.
I only caught it because a downstream number looked too flat. Not zero, which would have been obvious. Just flat. The kind of flat that could be a slow week or could be a dead pipeline. I went looking, and it was the second one.
Ten days. That's how long it had been broken before I noticed. Ten days of scheduled jobs running and producing nothing. Ten days of every dashboard reporting healthy while the actual work had stopped completely.
The bug itself turned out to be one line. I'll get to that. But the bug was never the scary part. The scary part was that everything reported green. Every health check passed. The job scheduler said it ran. The API said it returned. And underneath all of that, the system was doing absolutely nothing.
This is exactly the thing people don't think AI can do. The common assumption is that AI writes new code. Greenfield. Boilerplate. A fresh feature from a prompt. The skeptic in the room will tell you AI can't diagnose a live system that's failing silently, because that requires understanding, not generation.
I used AI to find this one. Specifically, I used 80 agents to do it. Here's how that actually worked, and where it broke.
Why I Reached for an Agent Audit Instead of a Debugger
My first instinct was the normal one: open the code, find the scheduled job, trace it through. But I stopped before I started, because of one detail. A single failure here didn't stay in one place. It cascaded across multiple downstream consumers, each one reacting to the same broken upstream state.
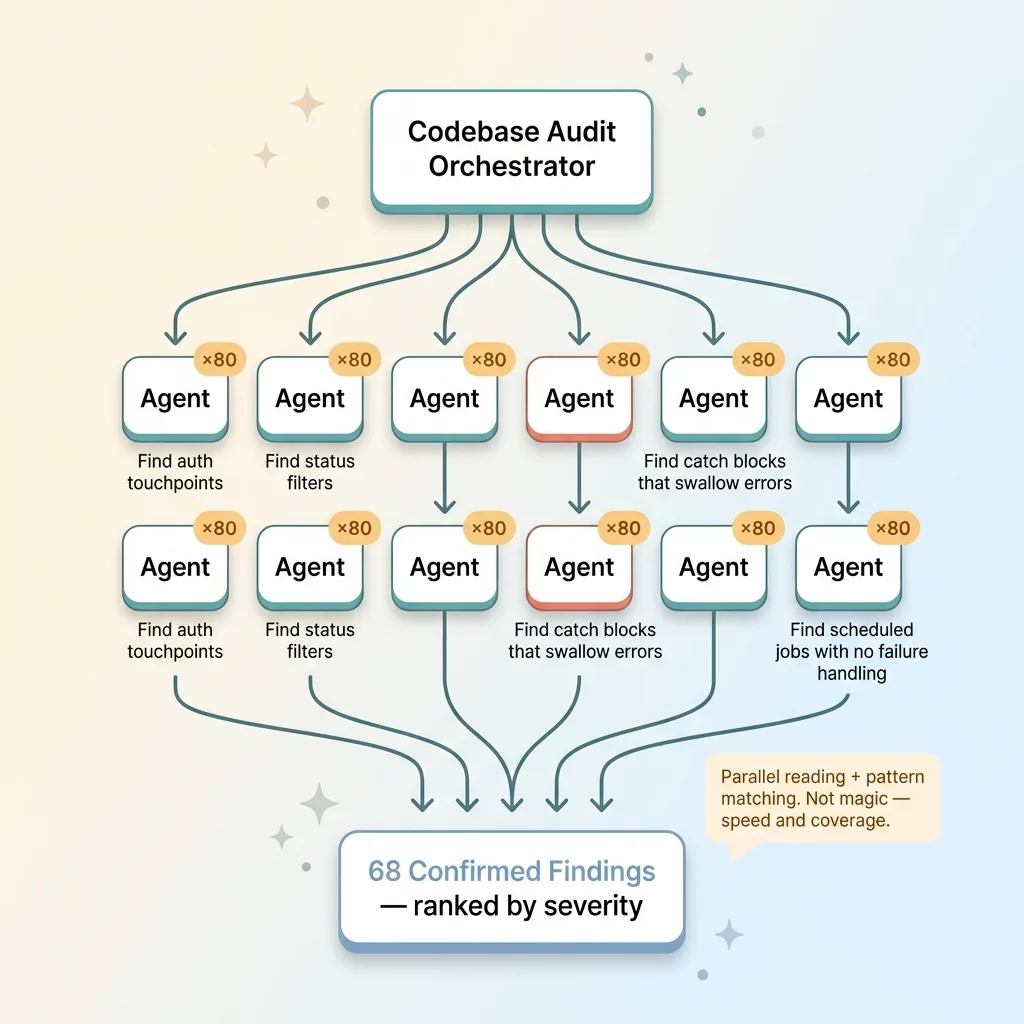 Fan-out audit: 80 agents reading the codebase in parallel
Fan-out audit: 80 agents reading the codebase in parallel
When a failure fans out like that, you don't actually know the blast radius. Tracing one stack trace by hand tells you about one path. It tells you nothing about the four other places that quietly broke as a side effect. I could have spent three or four hours following the obvious thread and still missed the secondary damage.
So instead of debugging one path, I audited everything in parallel.
I ran a fan-out audit: 80 agents reading different parts of the system at the same time, each with a specific assignment. Find every place that touches authentication. Find every consumer that filters on status. Find every catch block that swallows an error. Find every scheduled job with no failure handling. Each agent reads its slice, confirms or rejects specific failure modes, and reports back.
Let me be honest about what this is, because I'm allergic to hype. This is not magic. It's parallel reading and pattern matching across a codebase, faster than one human can do it. Eighty agents reading at once cover ground that would take me a full day to cover alone. That's the entire advantage. Speed and coverage, not intelligence in some mystical sense.
The output was 68 confirmed findings, ranked by severity. Not 68 guesses. Findings where the agent quoted the actual line, the actual filter, the actual swallowed exception, and explained the failure mode it created.
The important distinction here: this is a multi-agent code audit doing diagnosis, not generation. Nobody asked it to write a feature. The whole job was to read a live, failing system and tell me what was wrong with it. That's a fundamentally different task than the one most people picture when they hear "AI and code."
And it worked. Mostly. I'll cover the "mostly" in a minute.
Tracing the Outage to a Single Line
The audit pointed me at one connection in the token-refresh path. From there, the chain was plain to follow.
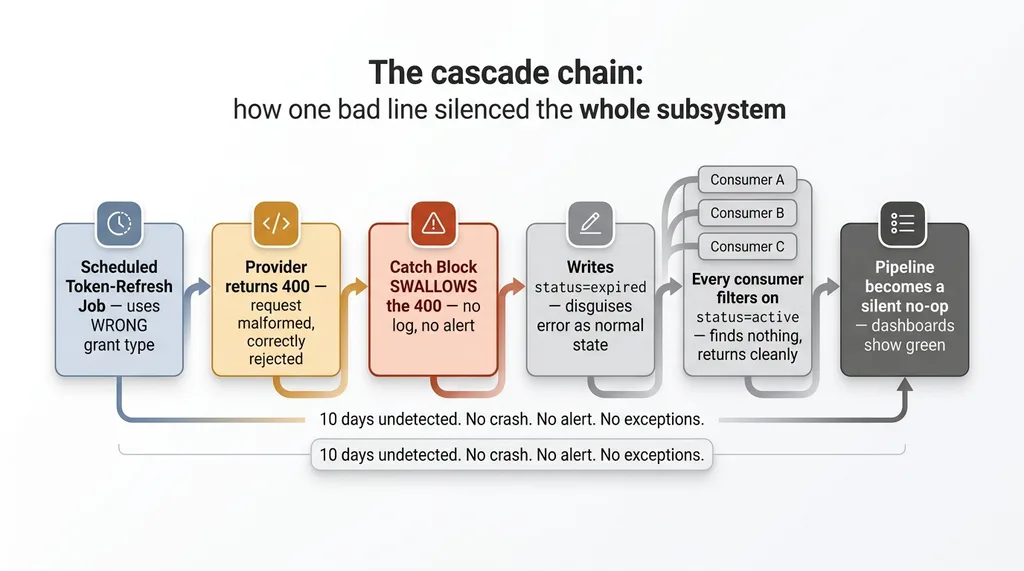 The cascade chain: how one bad line silenced the whole subsystem
The cascade chain: how one bad line silenced the whole subsystem
The wrong grant type
A scheduled token-refresh job ran on a timer to keep API connections alive. For one connection, that job used the wrong grant type. Not a typo in a secret, not an expired credential. The wrong kind of refresh request entirely for that provider.
The provider did exactly what it should. It returned a 400. The request was malformed, so it got rejected. That 400 was the truth. The system just refused to listen to it.
The catch block that lied
Here's where one bad line turned a recoverable error into a ten-day silent failure.
The refresh code was wrapped in a catch block. When the 400 came back, that catch block swallowed it. It didn't log the error at a level anyone would see. It didn't alert. Instead, it wrote status=expired to the connection record and moved on, as if expiry were a normal, expected outcome.
That single decision is the whole story. I wrote up the deeper version of this in an over-aggressive catch block, because it deserves its own post. A genuine error got disguised as a normal state.
Now follow the chain. Every downstream consumer hard-filtered on status=active. That was their first line: pull the active connections, ignore everything else. Sensible on its own. But with the connection now marked expired, every consumer looked at the list, found nothing active to process, and returned cleanly. No work. No error. A quiet 503 here, an empty result there. All of it reported as normal operation.
So the chain was: wrong grant type, 400 from the provider, swallowed by a catch block, mislabeled as expired, filtered out by every consumer, pipeline becomes a no-op.
One mislabeled status field turned an entire subsystem off. And because expired is a state the system is designed to handle gracefully, nothing complained. The reason the dashboard showed zeros and nobody noticed is that zeros from an "expired" connection look identical to zeros from a quiet day.
The bug was one line in a catch block. It was invisible because the failure was wearing the costume of a normal state.
What the Audit Got Wrong (And Why That Matters)
I want to be straight about the parts that didn't work, because that's where most AI write-ups go quiet.
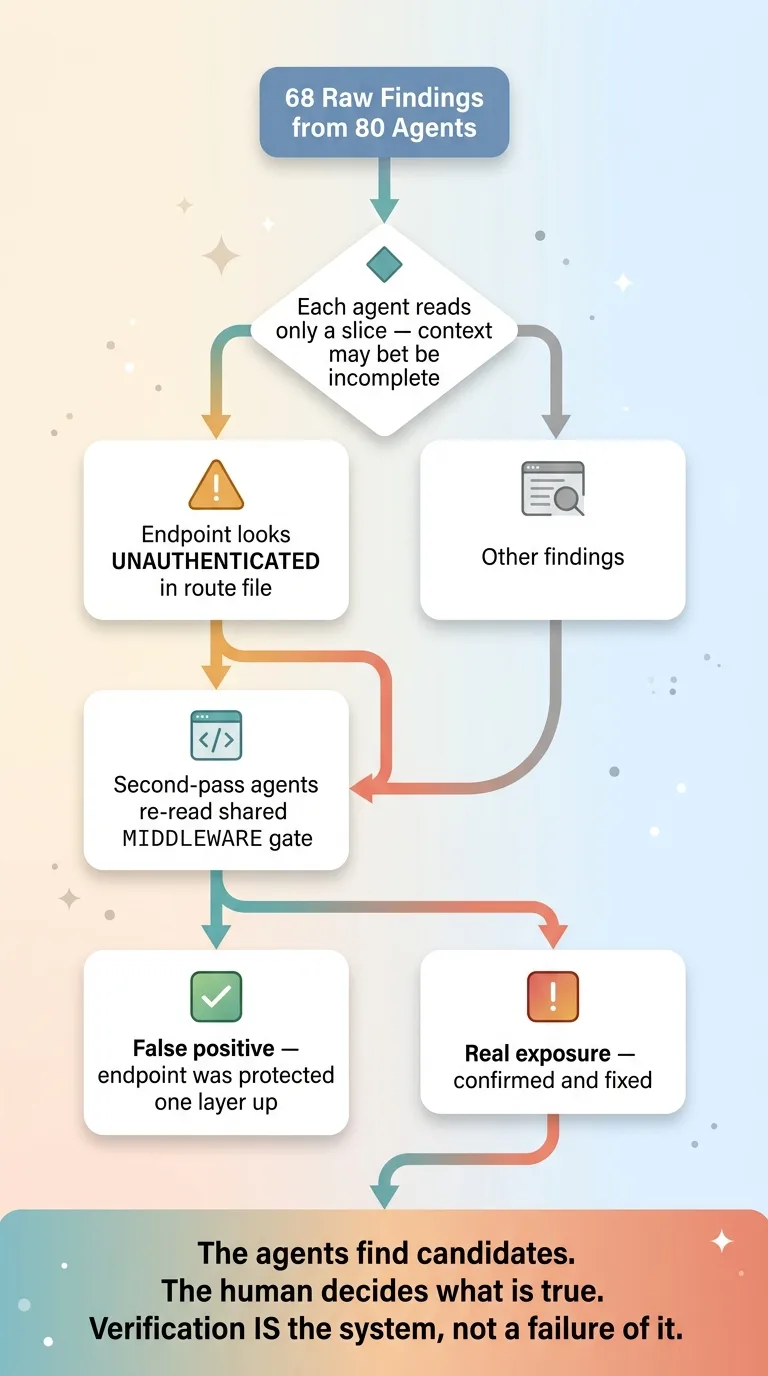 False positives and the human verification pass
False positives and the human verification pass
The audit flagged several endpoints as "unauthenticated." Open to the internet, no auth gate, anyone could hit them. That's a real and serious finding if it's true. It was not true for all of them.
Several of those endpoints were actually protected by middleware. The auth gate lived one layer up, in a shared middleware function that wrapped the routes. The agents that read the route files didn't have that middleware in their context window, so from where they were reading, the endpoint looked wide open. False positive.
This is the failure mode of any multi-agent audit. Each agent reads a slice. A slice can be misleading. An endpoint that looks unauthenticated in isolation can be fully gated by code the agent never saw.
So I did the thing the design requires. I had a second pass of agents re-read the actual middleware gate before I touched anything. Once they had the protective layer in context, those findings collapsed. The endpoints were fine.
Here's the broader point, and it's the one that separates useful AI work from dangerous AI work. A multi-agent audit produces noise. You cannot ship its conclusions blindly. Out of 68 findings, some were real and severe, some were real and minor, and some were ghosts created by limited context.
A human verifying the totals is not a failure of the system. It is the system. The 80 agents find candidates. The person decides what's true. AI diagnosis still requires someone who knows what a false positive looks like and bothers to check before acting. Skip that step and you'll spend a day fixing problems you never had.
The Real Problems the Audit Surfaced
While I was hunting one silent outage, the audit found things I wasn't even looking for. This is where a real root cause analysis on a live system earns its money.
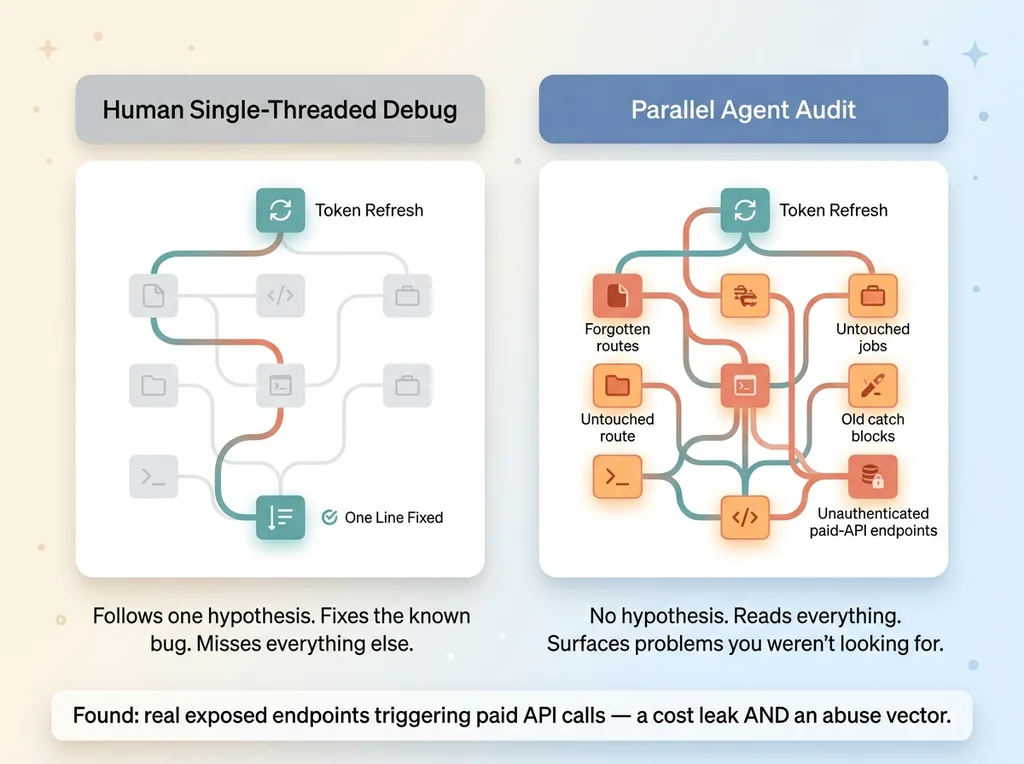 Single-threaded human debug vs parallel agent audit coverage
Single-threaded human debug vs parallel agent audit coverage
A handful of those endpoints really were exposed. Not the false positives, the real ones. Internet-reachable, no authentication, and worse, they triggered paid API calls when hit. Anyone who found the URL could fire off requests that cost me money on every call.
That's two problems in one. A cost leak, because every unauthenticated hit ran up a metered bill. And an abuse vector, because nothing stopped someone from hammering it on purpose. Neither had anything to do with the outage I came to fix.
I never would have found these in a single-threaded debug session. If I'd opened the code and traced the token-refresh path by hand, I'd have fixed the one line and walked away clean, with these exposures still sitting there live. The whole reason they surfaced is that the agents read everything, not just the path I suspected was broken.
That's the actual argument for using AI on a live system. A human debugging follows a hypothesis. You think you know where the problem is, so that's where you look. The audit doesn't have a hypothesis. It reads the routes I'd forgotten existed, the jobs nobody had touched in months, the catch blocks written two years ago by someone who's no longer around.
A handful of confirmed exposures, found while chasing an unrelated bug. That's coverage no single debug session gives you, because no single debug session looks where it doesn't expect to find something.
The Fixes That Stop It Happening Again
Finding the bug is the easy part. Making sure this class of failure can't hide for ten days again is the real work. Two fixes did most of it.
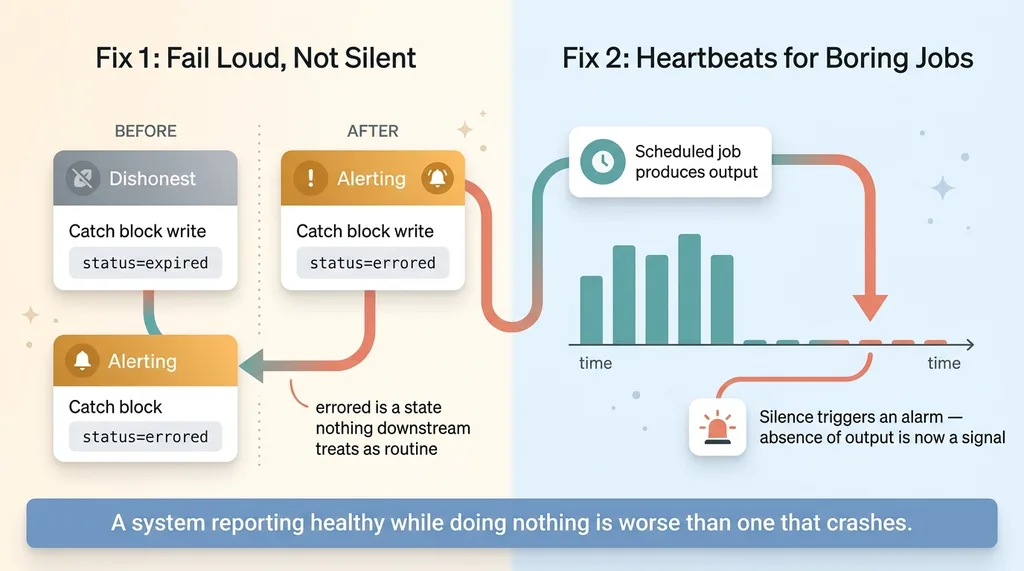 Two preventive fixes: fail loud and heartbeat monitoring
Two preventive fixes: fail loud and heartbeat monitoring
Fail loud, not silent
The catch block was the root of everything, so that's where the first fix went. A catch block must never write a state that downstream code treats as normal.
A failed token refresh is not an expired token. Those are different things and they need different states. So now a failed refresh marks the connection errored, not expired, and it fires an alert. Errored is a state nothing downstream treats as routine. It demands attention.
The principle: errors should be loud. The moment you catch an exception and quietly write a normal-looking value, you've built a trap for your future self. The whole disaster came from a catch block trying to be helpful and ending up dishonest.
Heartbeats for the boring jobs
The second fix is monitoring, but a specific kind. Most monitoring watches for things going wrong. This watches for things going quiet.
I added heartbeat monitoring to the scheduled jobs. If a job that should produce work produces nothing for too long, that silence itself triggers an alarm. The absence of output is now a signal, not a non-event. I wrote about the broader idea in automations that email me when nothing is wrong, because silence is the most dangerous status a system can have.
A system that crashes gets noticed. Someone gets paged, a graph spikes, a customer complains. A system that reports healthy while doing nothing is far worse, because everyone believes it's fine. The fix is to treat "no work happening" as a failure state worth waking up for.
AI Can Diagnose Your System, Not Just Build New Ones
Come back to the doubt I opened with. The skeptic says AI only writes greenfield code. Prompt in, fresh feature out. It can't understand a real system well enough to find a failure buried in it.
This was the exact opposite of greenfield. There was no new code to write. The job was to read a live production system, map a single failure as it cascaded across dozens of consumers, and trace it back to one line in a catch block that was lying about what happened. That's diagnosis under real stakes, with real money and real data on the line.
And it worked, with one honest caveat. It took direction. It took a second verification pass to kill the false positives. It took someone who could look at a finding and know whether it was real or a ghost from a missing context window. The 80 agents didn't solve this on their own. They made it possible for one person to cover a day's worth of reading in an hour and then make the calls that mattered.
That combination, AI for coverage and a human for judgment, is the whole thing. I don't just hand a client a model and wish them luck. I wrote about why in I don't just advise on AI, I build it, because the difference between advice and a working system is most of the value.
If you've got a subsystem that might be quietly broken, or a nagging sense that something is reporting healthy while doing nothing, that's the kind of problem I get hired to find and fix. The silent failures are the expensive ones, precisely because nobody's looking.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call