The OAuth Token Refresh Bug That Cost Me 10 Days of Data
A single catch block assumed any error meant token expiry. The credential was fine. Here's the OAuth token refresh bug that silently killed my pipeline.
By Mike Hodgen
Ten Days of Silence Nobody Heard
The first sign of an oauth token refresh bug is almost never an error message. It is a number that should be moving and isn't.
A credential-refresh job for my DTC fashion brand in San Diego quietly flipped one connection to "expired." Nothing crashed. Nothing alerted. The job ran, decided a token was dead, wrote that decision to the database, and moved on like it had done its job.
Downstream, every consumer that pulled data from that connection filtered for active-only credentials. Sensible behavior. Except now there were no active credentials for that source, so a whole class of data just stopped flowing. No exception. No red dashboard. No email. Just absence, which is the one thing monitoring rarely catches.
I found it ten days later. Not because anything broke, but because a metric that should have been climbing was a flat line. When a number that always moves stops moving, your gut knows before your brain does.
So I pulled the actual token and probed it directly against the provider. It was valid. Not "barely hanging on" valid. Good for another two weeks.
Read that again. The system had marked a perfectly healthy credential dead, then politely built a workaround around the corpse. Ten days of missing data, all because one job made a guess and the rest of the stack trusted that guess without question.
This is the kind of failure that does not show up in a stack trace. It shows up in a quarterly review when someone asks why the numbers look off. By then you are not debugging code. You are doing forensics on data you can never fully recover.
The trigger was small. The blast radius was not. And the whole thing came down to a single catch block that told a lie.
The Catch Block That Told a Lie
Here is the anti-pattern in plain OAuth terms. The refresh job hit the token endpoint. The endpoint returned a 400. The catch block did exactly one thing:
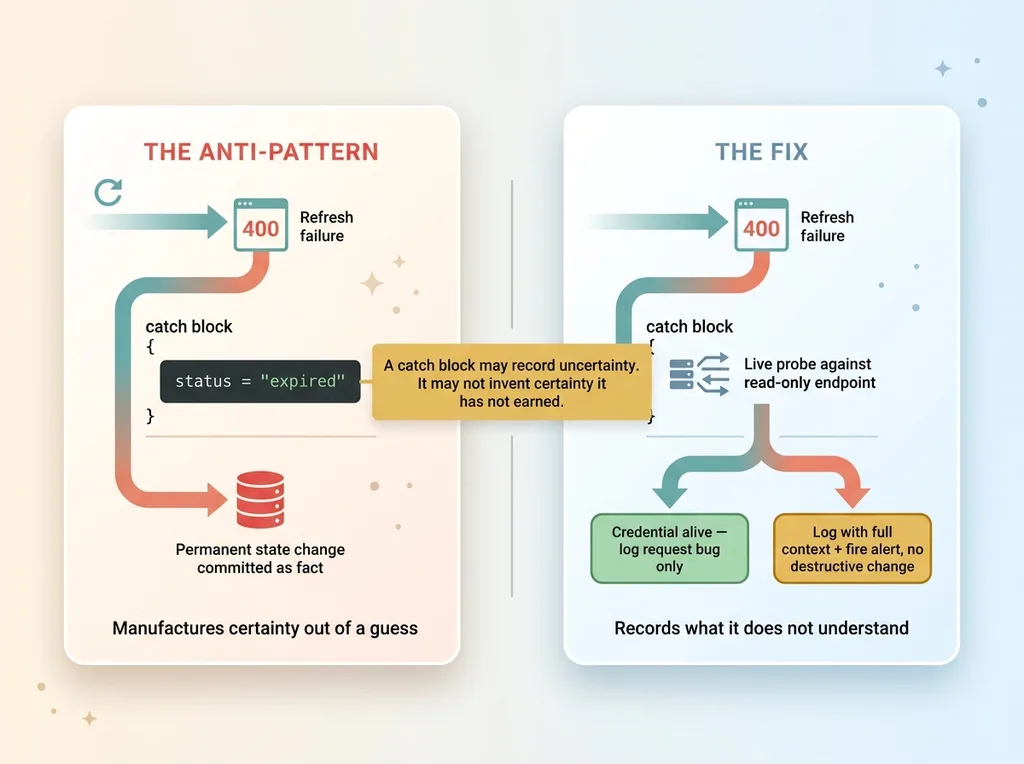 The catch block anti-pattern: guess vs verify
The catch block anti-pattern: guess vs verify
status = "expired"
That's it. The logic assumed that any failure during a refresh meant the credential was dead. That single assumption is the entire bug.
A 400 can mean a hundred different things. Malformed request. Wrong parameter. Missing field. Bad content type. Yes, sometimes it means the grant was revoked. But "the request was wrong" and "the credential is dead" are completely different diagnoses, and the catch block treated them as identical.
In this case the 400 meant the request was malformed. The token itself was never even evaluated by the provider. The request failed before the credential got a chance to prove it was alive.
But the catch block didn't know that, and worse, it didn't care. It took an unverified guess and committed it to the database as fact. From that moment on, the system believed the credential was expired because it had written that belief down, and nothing ever questioned the written record.
This is the catch block anti-pattern in its purest form. A catch block exists to handle uncertainty. The job of error handling is to narrow uncertainty, to figure out what actually went wrong and respond proportionally. This catch block did the opposite. It manufactured certainty out of a guess.
A failed refresh is a question: "why didn't this work?" The catch block answered "the token is dead" without checking. It converted an open question into a destructive, permanent state change, then walked away.
The rule I now repeat to myself every time I write error handling: a catch block is allowed to record what it does not understand. It is not allowed to invent certainty it has not earned.
Why the Refresh Actually Failed
The root cause was upstream of the catch block, and it was almost embarrassingly simple.
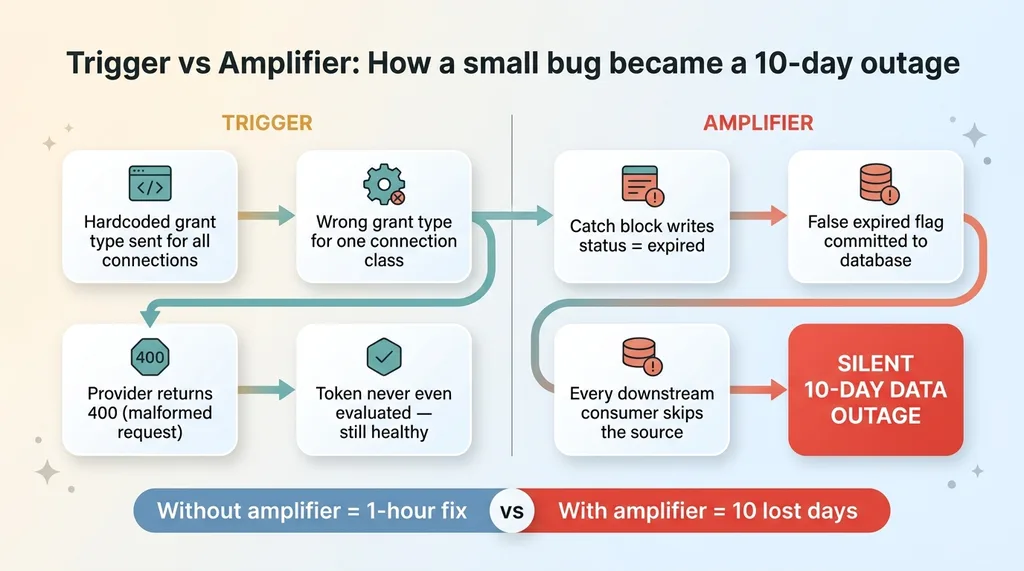 Trigger vs Amplifier: How a small bug became a 10-day outage
Trigger vs Amplifier: How a small bug became a 10-day outage
This integration supported more than one class of connection. And those classes did not all use the same OAuth grant type. Some used one grant type, one specific class used another. That is normal. Providers offer different grant types for different connection scenarios all the time.
The refresh job didn't account for that. It sent a single hardcoded grant type for every connection it touched.
For most connections, that hardcoded value was correct, so refreshes worked fine for months. For one class of connection, it was wrong. The instant that request hit the token endpoint with the wrong grant type, the provider returned a 400. It rejected the request as malformed before it ever looked at the credential.
So the token was never tested. It was healthy the entire time. The provider was effectively saying "I can't process this request," and our code heard "this token is dead."
The bug had two layers, and you need to see both.
The trigger was the wrong grant type. That was the actual defect, the thing that caused the refresh to fail. On its own, a failed refresh is recoverable. You retry, you fix the request, you move on.
The amplifier was the catch-and-mislabel. That is what turned a recoverable, fixable error into a silent ten-day outage. Without the amplifier, I would have seen retry failures and fixed the grant type in an hour. With it, the failure got buried under a false "expired" flag and disappeared.
Most production disasters work this way. The trigger is mundane. The amplifier is what makes it expensive. Defensive error handling mistakes are almost always the amplifier, because they take a small, loud problem and make it large and quiet.
How One Bad Status Flag Spreads
Here is why a single mislabeled flag did so much damage.
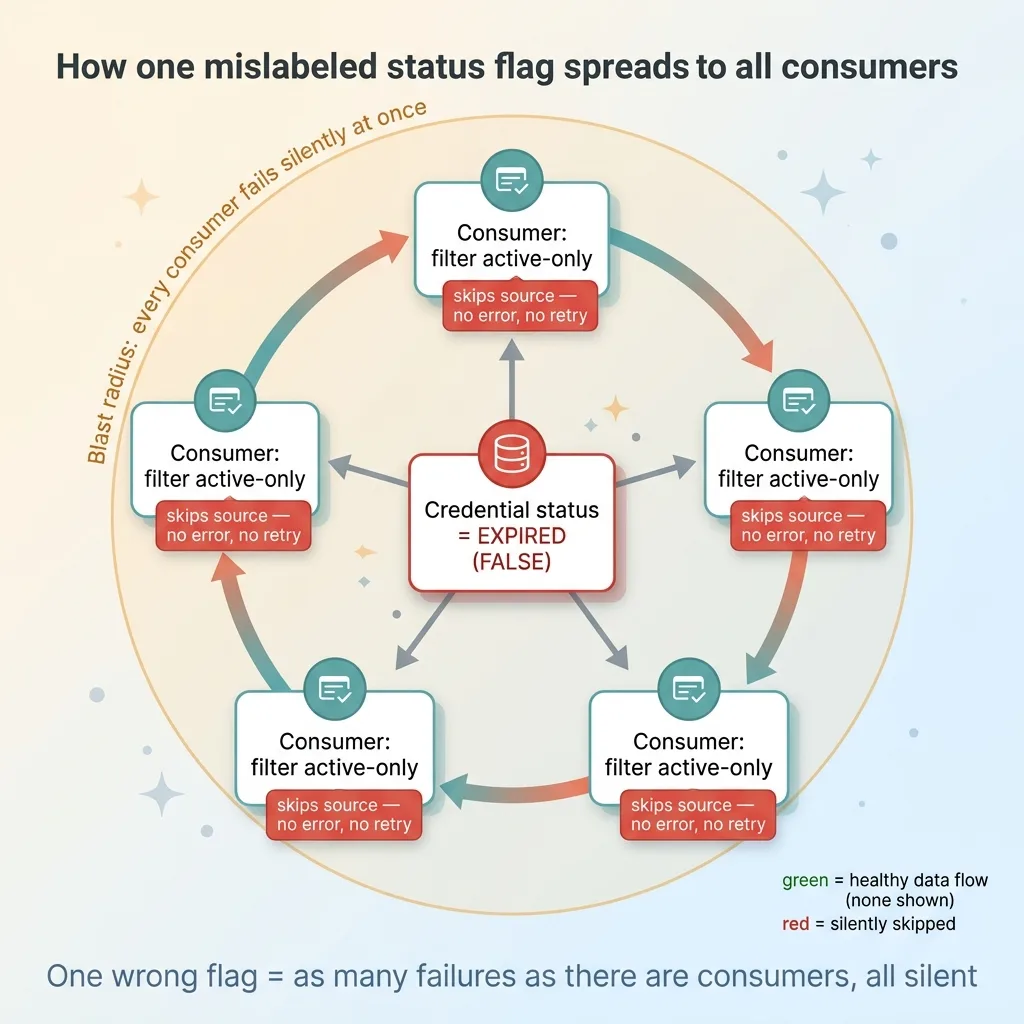 How one mislabeled status flag spreads to all consumers
How one mislabeled status flag spreads to all consumers
Every downstream consumer filtered for active credentials only. That is correct, sensible, defensive behavior. You don't want your pipeline trying to pull data with a credential you believe is dead. Filtering for active is exactly what a careful system should do.
But that careful behavior is precisely what made the failure invisible. The moment the credential got wrongly marked expired, every single consumer agreed to ignore it. No complaints. No errors. No retries. They all just quietly skipped the source, because as far as they knew, that was the responsible thing to do.
The system failed closed and silent. And failing closed feels safe. It feels like the conservative choice. But for data integrity, fail-closed-and-silent is the worst failure mode there is, because nothing breaks loudly enough to get noticed. The dashboard showed zeros and nobody noticed, which is exactly the pattern I wrote about when the dashboard showed zeros and nobody noticed.
A system that fails loud gets fixed in an hour. A system that fails silent gets discovered in a quarterly review, after the damage is already irreversible.
The deeper lesson is about derived state. When a single piece of derived state, like a status flag, is trusted blindly by everything downstream, the cost of getting that one value wrong gets multiplied by every consumer that reads it.
One wrong flag did not cause one problem. It caused as many problems as there were consumers, all at once, all silently. The credential status was a single point of truth, and when that truth was a lie, the entire downstream agreed to it without a fight.
The Fix: Probe Before You Bury
The fix came in three parts. None of them are clever. All of them are about refusing to make destructive decisions on a guess.
Pick the grant type by connection type
The first change addresses the trigger. Instead of hardcoding one grant type for all connections, the refresh job now selects the grant type based on the connection class.
This is obvious in hindsight. The bug existed because the code assumed all connections were the same when they weren't. Mapping the grant type to the connection class means the request is correct for every class, and the 400 that started this whole mess never fires.
Verify the credential before downgrading state
The second change is the one that matters most. We never mark a credential expired off a failed refresh alone. Not ever.
Before any downgrade, the system runs a live probe against a cheap, read-only endpoint using the existing token. If that probe succeeds, the credential is alive, full stop. The refresh failure was a bug in our request, not a dead token, and we log it as exactly that instead of nuking the credential's status.
A refresh failure and a dead credential are two different facts. The probe is how you tell them apart. Costs one extra API call. Saved me from another ten-day hole.
Treat a refresh 400 as a question, not a verdict
The third change rewrote the catch block itself. It no longer mutates state on failure. When something unexpected happens, the catch logs it with full context and fires an alert. That's all.
A catch block is allowed to say "I don't understand what just happened, and here is everything I know about it." It is not allowed to make a destructive, permanent decision on a hunch and then bury that decision in the database.
Here is the rule you can steal: no automated process downgrades the status of anything without independent verification. If a job wants to mark something dead, broken, or expired, it has to prove it with evidence the job collected itself, not infer it from the failure of an unrelated operation.
That single rule would have prevented the entire incident. The grant type bug would still have happened, but it would have shown up as a loud, fixable alert instead of a silent data outage. Validate before marking expired is not a nice-to-have. It is the difference between a one-hour bug and a ten-day one.
The Anti-Pattern Hiding in Fast-Built Integrations
Catch-and-mislabel is everywhere. It is endemic in quickly built integrations, and it is especially common in AI-assisted code, because the happy path gets all the attention and the catch block is an afterthought whose only job is to make the error go away.
And that is exactly the danger. It makes errors go away. A catch block that swallows a problem feels like progress. The code runs clean, no exceptions bubble up, the demo works. Nobody notices that you've traded a loud, recoverable error for a silent, destructive one.
Fail-closed-and-silent is a default that looks responsible and is actually negligent. It wears the costume of careful engineering while quietly destroying your data integrity in the background. This is a big part of the security and quality debt hiding inside fast AI builds, the stuff that ships looking finished and rots underneath.
I am not above this. I shipped this bug in my own brand's systems. The reason I caught it at all is that I run real systems where this exact failure costs real revenue, so I have learned to be paranoid about any line of code that changes state based on an assumption.
That paranoia is earned. When you've lost ten days of data to a single mislabeled flag, you stop trusting error handling that "just works." You start reading every catch block and asking what it actually decides.
When I audit integrations, error handling is the first place I look. Not the happy path, not the architecture diagram. The catch blocks. Because that is where the silent landmines live, and api integration failures almost always trace back to a catch block that made a decision it had no business making.
What I Check in Every Integration Now
After this, I rebuilt how I think about state transitions. Three rules govern everything I ship.
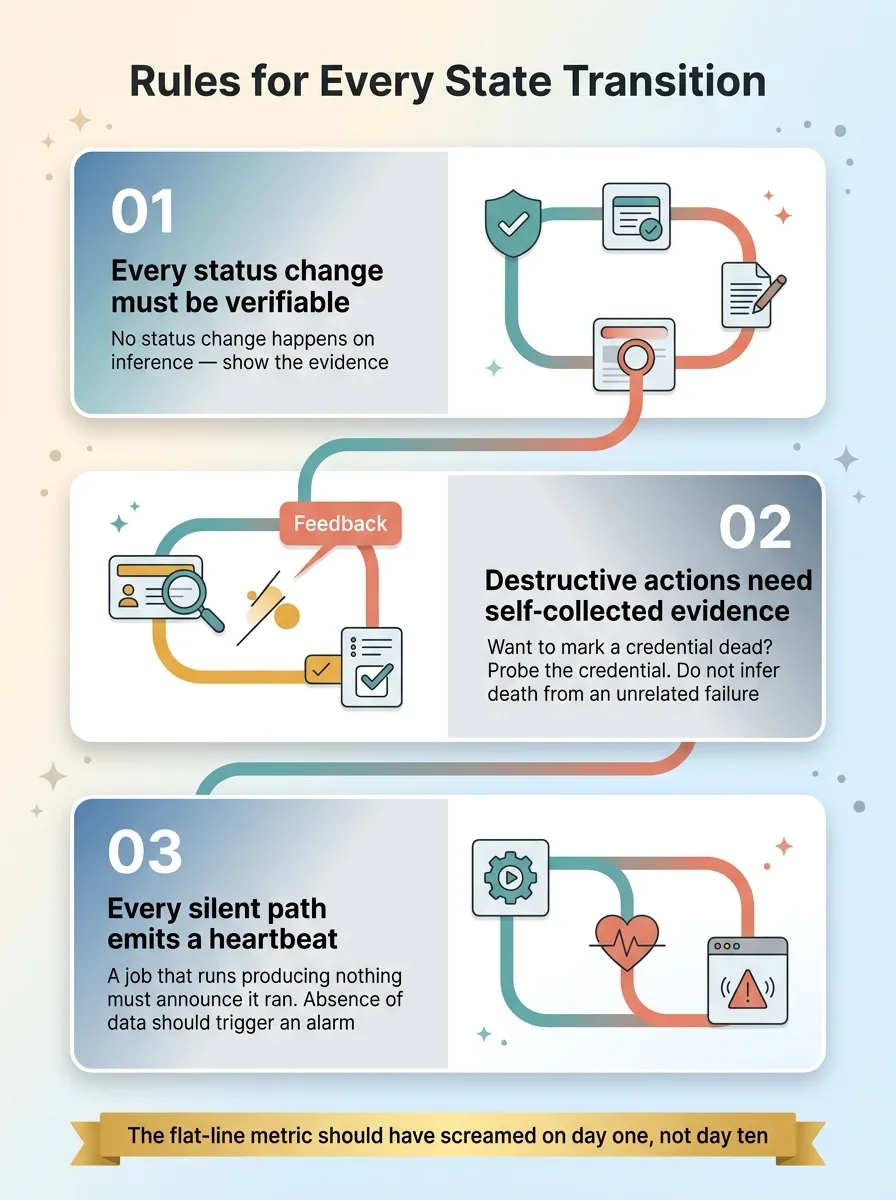 Three rules for safe state transitions
Three rules for safe state transitions
Every status change has to be verifiable. If a process changes the state of something, it has to be able to show the evidence. No status change happens on inference.
Every destructive action requires evidence the process collected itself. A failed operation is not evidence about an unrelated thing. If you want to mark a credential dead, probe the credential. Don't infer its death from something else failing.
Every silent path emits a heartbeat. If a job can run successfully while producing nothing, it has to announce that it ran. Absence of data should trigger an alarm, not silence. The flat-line metric should have screamed on day one, not waited for me to notice it on day ten.
That last one ties into how I design everything now. Every system I ship stops for a human at the points where a wrong decision is expensive and hard to reverse. A machine marking a credential dead is exactly that kind of decision.
Here is the plain truth. Most of the brittle error handling I find lives in integrations that got shipped fast and were never audited. They work fine until the day they don't, and the day they don't, they fail in the quietest, most expensive way possible.
If you have OAuth connections, data pipelines, or vendor integrations holding your business together, and nobody has stress-tested how they fail, that is worth an afternoon. I'll have me audit your integrations and find the silent landmines before they cost you ten days of data, or worse.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call