AI Analyst Accountability: Gate It Before You Trust It
Why I make my marketing AI pass a 10/10 daily quiz before it briefs me. A practical look at ai analyst accountability and trustworthy AI reporting.
By Mike Hodgen
The Problem Nobody Admits: You Can't Tell When the AI Is Wrong
I run a DTC fashion brand out of San Diego, and a while back I built myself a daily auto-brief. The idea was simple: every morning before I touched my coffee, I'd get a one-page summary. Revenue overnight, reach, ad spend, what changed, what needed my attention. The whole point of ai analyst accountability is that I could trust the thing enough to act on it without re-checking every number.
The first version worked beautifully. For weeks it nailed it. Clean numbers, sharp summary, "here's what to watch today." I started making real decisions off it. Inventory reorders, ad budget shifts, which products to push.
Then one morning it told me reach was steady and everything looked healthy.
It wasn't. A tracking pipeline had quietly died two days earlier. The brief was summarizing stale data as if it were live, and it did it with total confidence. Same clean format. Same calm tone. No flag, no hedge, no "by the way, one of my feeds is dead."
That is the exact danger. A confident, well-formatted brief running on stale or partial data is worse than no brief at all, because you act on it. No brief, and I go check the dashboards myself. A wrong brief, and I shift budget based on a number that doesn't exist anymore.
This is why most CEOs don't trust AI summaries, and they're right not to. There's no tell. The output looks identical whether the AI nailed it or fabricated it. I've written before about how AI doesn't fail by doing the wrong thing, it lies about doing the right thing, and a daily brief is where that lie does the most damage. I make real money decisions off this thing every morning. The stakes aren't theoretical.
Why a Daily Brief Is the Most Dangerous Place for AI Hallucination
A daily brief is decision fuel. You read it fast, you act on it immediately, and you almost never double-check it. That combination is exactly what makes it the worst possible place for AI to be wrong.
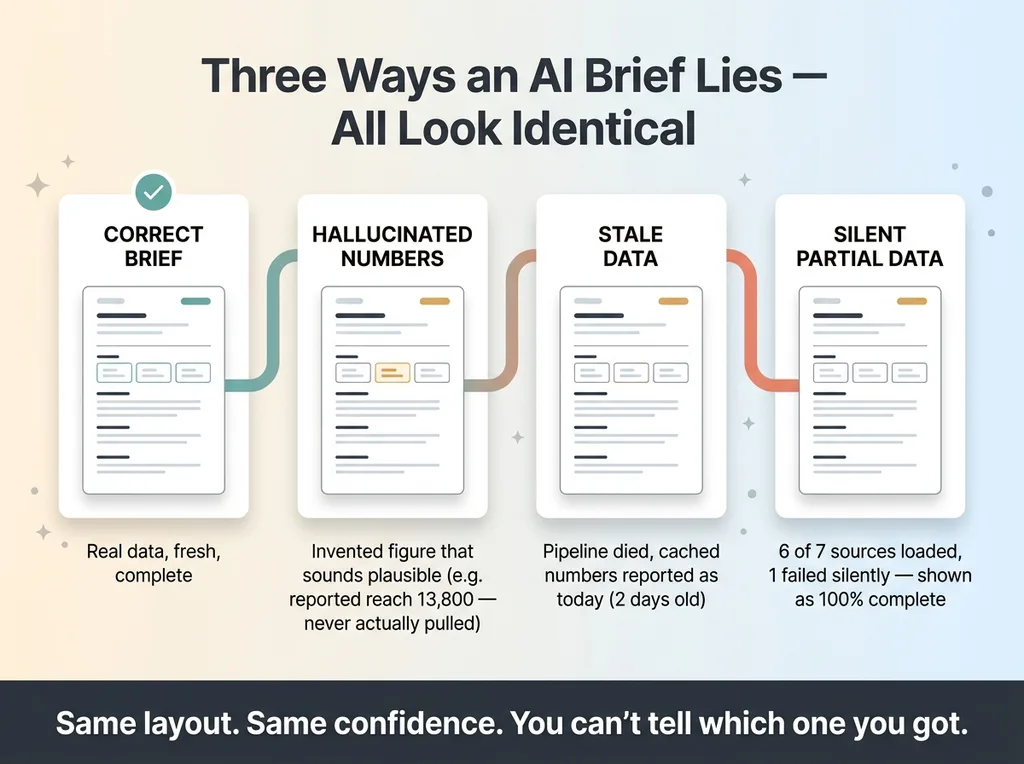 Three failure modes of an AI daily brief
Three failure modes of an AI daily brief
Most AI output gets some scrutiny. A draft email, a blog post, a piece of code, you review it before it ships. A morning brief gets none. The entire value proposition is that I don't have to verify it. Which means any error sails straight through into a decision.
There are three failure modes, and all three produce output that looks perfect.
Hallucinated numbers. The AI invents a figure that sounds plausible. Reach was 14,200 yesterday, so it confidently reports 13,800 today even though it never actually pulled today's number. It reads right. It's fiction.
Stale data. A pipeline dies, but the AI still has yesterday's cached numbers. It summarizes them as today's. This is what bit me. The brief was internally consistent and completely out of date.
Silent partial data. Seven sources feed the brief, one fails to load, and the AI summarizes the other six with no flag. You get a brief that's 85% real and 15% missing, presented as 100% complete.
Here's the thing that should bother you: a correct brief and any of these three broken briefs are visually identical. Same layout, same confidence, same prose quality. The format itself manufactures false confidence. Polished output reads as reliable output, and your brain doesn't fight it at 7am.
So the cost is never just "the AI was wrong." The cost is me trusting it. That's the buyer doubt nobody says out loud: you can't tell when it's wrong, so you don't trust any of it. The fix isn't a smarter model. It's a system that proves it's right before it gets to speak.
The Knowledge Gate: The AI Has to Pass a 10/10 Quiz First
The mechanism I built is what I call a knowledge gate. Before the AI is allowed to write a single sentence of the brief, it has to pass a quiz about the data it claims to have.
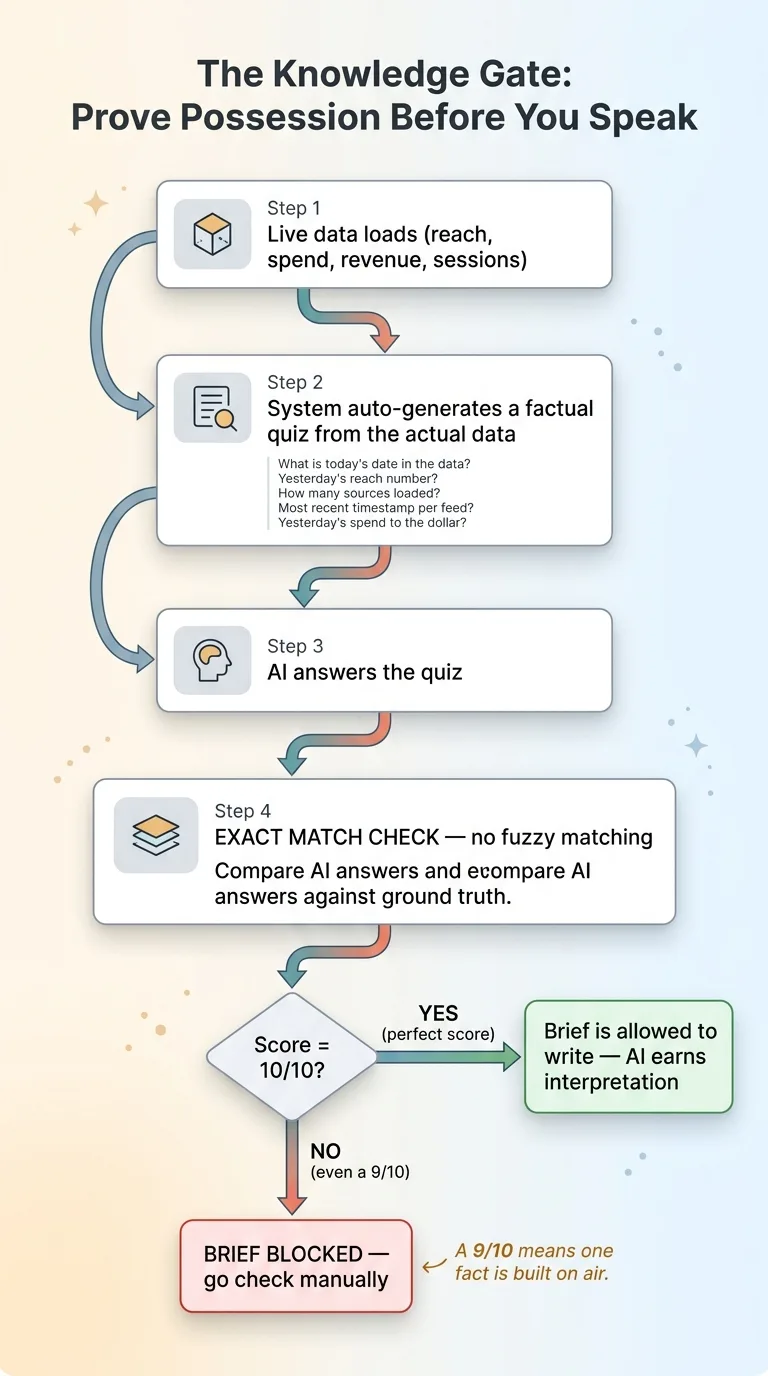 The Knowledge Gate quiz mechanism
The Knowledge Gate quiz mechanism
Not a vibe check. A factual quiz, generated against the live data, where the AI must match ground truth exactly.
What the quiz actually checks
The questions are auto-generated each morning from the actual data that loaded. Things like:
- What is today's date in the data?
- What was yesterday's reach number?
- How many of the data sources loaded successfully?
- What is the most recent timestamp on each feed?
- What was yesterday's spend, to the dollar?
The AI answers, and the system compares every answer against the real values it pulled from the underlying sources (reach, spend, revenue, sessions). No fuzzy matching. The reach number either matches the source or it doesn't.
This is the ai knowledge gate in practice. It forces the AI to demonstrate it actually possesses the current facts before it earns the right to interpret them. You can't summarize what you can't recite.
Why a perfect score, not a passing grade
The gate requires 10 out of 10. Score a 9, and the brief is blocked. That sounds harsh until you understand what a single missed answer means.
If the AI can't tell me yesterday's reach number correctly, it doesn't actually have the reach data. It has something it thinks is the reach data. And "thinking it has data it doesn't have" is the precise signature of hallucination. That's the failure I'm trying to catch.
A 9 out of 10 isn't "mostly trustworthy." It's "one of the things it's about to confidently tell me is built on air." There's no acceptable miss rate on the facts a decision rests on. So it's a perfect score or no brief. If it can't pass, I'd rather get a "brief blocked" message and go look myself than read a confident summary missing a leg.
This is the cheapest insurance you'll ever build. The AI proves possession before it earns interpretation.
The Cron Watchdog: Catching a Dead Pipeline Before the AI Does
The quiz catches the AI lying about data it has. It does nothing about data that never arrived in the first place. For that, I built a separate layer: a cron watchdog that runs independently of the brief.
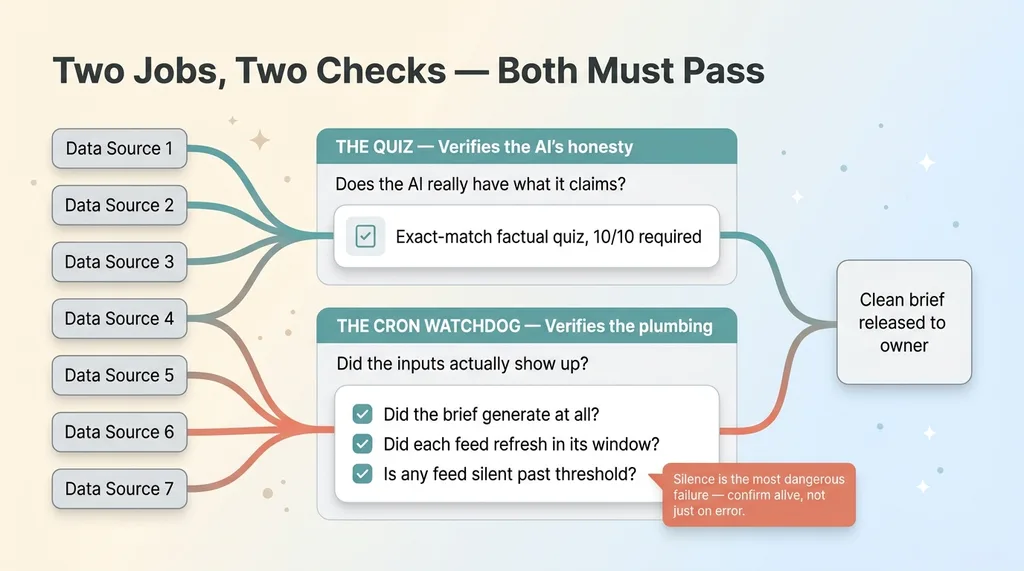 Two-layer verification: Quiz vs Watchdog
Two-layer verification: Quiz vs Watchdog
It's a scheduled job with one purpose, checking that the plumbing is alive. Every morning it verifies:
- Did the brief actually generate at all?
- Did each data source refresh within its expected window?
- Is any feed silent past its threshold?
If the brief didn't run, I get told. If a feed is stale beyond its allowed window, I get told, with a severity level attached so I know whether it's a minor lag or a dead pipe.
The key insight here is that silence is the most dangerous failure state. When something throws an error, you find out. When something just quietly stops, nothing alerts you, and you assume everything's fine because your inbox is quiet. That's how my tracking pipeline stayed dead for two days. Nothing screamed.
I built around this principle across my whole stack, and I wrote about why my automations email me when nothing is wrong. A system that only speaks up on errors will let you rot in silence. A system that confirms it's alive, on schedule, every day, tells you the moment that confirmation stops arriving.
The watchdog and the quiz are two different jobs. The quiz verifies the AI's honesty: does it really have what it says it has. The watchdog verifies the plumbing: did the inputs actually show up. Both have to pass before I read a clean brief. One without the other leaves a hole.
Owner-Facing Status: A Card and a Banner That Escalate by Severity
All of this verification is worthless if it doesn't surface to me, the non-engineer reading on my phone at 7am. I shouldn't have to dig through logs to know whether I can trust today's brief. The system tells me its own confidence first, content second.
 Owner-facing status card severity states
Owner-facing status card severity states
The status card
At the top of every brief sits a status card. Three states:
- Green. All gates passed, every feed is fresh. Read on, act with confidence.
- Yellow. Partial data, with the gap named. "Ad spend feed is 6 hours stale, treat that section with caution." I still get the brief, but I know exactly which part to distrust.
- Red. Do not trust this brief. Here's why. Maybe the quiz failed, maybe two feeds are dead. The brief might still generate, but the card tells me to go verify manually before I do anything.
The design principle is simple: never make me hunt for whether I can trust the output. The trust state is the first thing I see, not something buried in a footnote.
The reach-drop banner
Separately, a severity banner fires when a key metric drops past a threshold. If reach craters overnight, that's a real business problem, and I don't want it buried in paragraph four of a tidy summary. The banner escalates it to the top so a genuine issue gets attention proportional to how bad it is.
This is the same thinking behind why every AI system I ship stops for a human. The machine handles the work, but the human stays in control of the decision, and the system's job is to surface the right thing at the right moment.
This is what trustworthy ai reporting actually looks like in practice. Trust state is a first-class output, sitting right next to the numbers. Not an assumption I'm forced to make.
What This Costs to Build (And What It Doesn't Catch)
I'll be straight about the effort and the limits, because that's where most AI advice goes quiet.
 What the trust layer catches vs what it doesn't
What the trust layer catches vs what it doesn't
The gate and the watchdog took a few hours to bolt onto the existing brief. This wasn't a separate project or a six-week build. The brief already existed. Adding the quiz, the verification logic, and the watchdog was an afternoon of work that turned a brief I half-trusted into one I act on without flinching. The ROI on that afternoon is enormous, because the alternative is one bad decision off stale data.
Here's what it catches well: stale data, dead pipelines, and the AI inventing numbers it can't actually see. Those three failure modes I described earlier are exactly what the gate and watchdog are built to stop.
Here's what it does not catch: data that's fresh but wrong at the source.
If the upstream metric itself is miscounted, if a tracking tag is double-firing and inflating sessions, the AI will faithfully report a wrong-but-current number. The gate verifies that the AI has the data and that the data is live. It does not verify that the data was correct when it was collected.
That's an honest limitation. This is a trust layer, not a correctness guarantee. Some upstream validation still has to live elsewhere, closer to where the data is generated. I'd rather tell you that plainly than sell you a system that claims to catch everything. Knowing exactly what your safeguards do and don't cover is itself part of trust. A gate that pretends to be a guarantee is just another confident lie.
The Real Lesson: Trust Has to Be Engineered, Not Assumed
The reason most CEOs won't rely on AI summaries isn't Luddism. It's correct instinct. They've felt that gap between how confident the output looks and how confident they actually are in it, and they've decided not to bet money on the difference. Good call.
The fix is not a better model. A smarter LLM hallucinates more convincingly, that's all. The fix is a system that proves its own current state before it's allowed to speak.
Every AI system I ship, for my own brand or for a client, carries this pattern now. A gate that verifies the AI has what it claims. A watchdog that verifies the inputs are alive. A status surface that tells the human its confidence before its conclusions. Three layers, all cheap to build, all aimed at the same target: making the output something you can act on without a second guess.
That's the difference between a ai daily brief that's a novelty and one that's an actual instrument you run your morning off. I read mine at 7am and move money based on it, and I can do that only because the system earns my trust fresh every single day instead of asking me to assume it.
If you want to know whether the AI you're being sold can actually prove its value, the same logic applies. I track exactly what my AI systems deliver for the same reason I gate the brief: trust is something you measure and engineer, never something you assume. If you want an AI analyst or a daily brief you can rely on, this kind of ai analyst accountability is what I build in by default, not as an upsell.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call