AI Decision Making With Business Rules: Money Stays Safe
How I keep money-moving decisions safe with rules-first AI: a deterministic engine makes the call, an LLM only annotates edge cases and defaults to hold.
By Mike Hodgen
The Decision That Made Me Stop Trusting the LLM
A return comes in at my DTC fashion brand in San Diego. Something has to decide what happens next. Restock it. Send it back to the customer (return-to-sender). Or hold it for review. And separately: do we issue store credit or not.
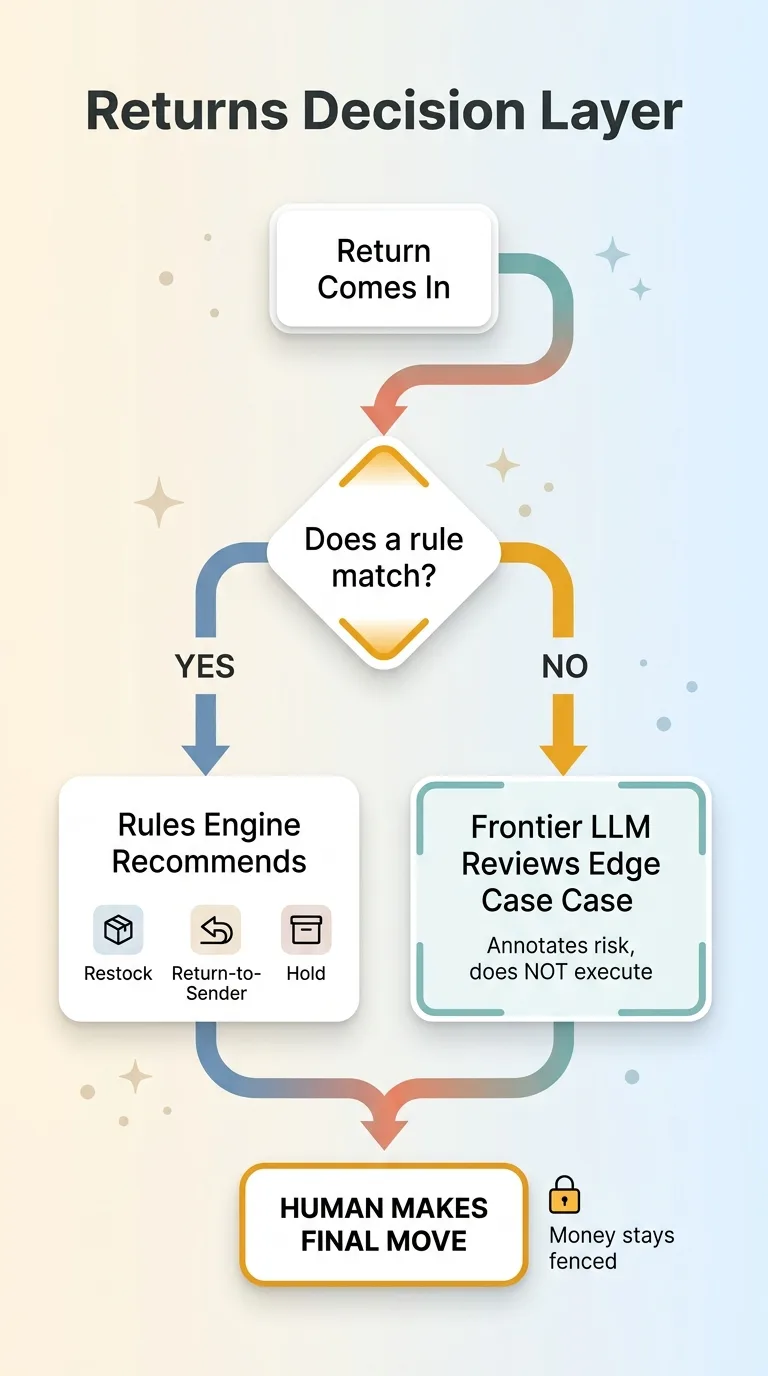 Returns decision layer: rules first, AI for edges, human on trigger
Returns decision layer: rules first, AI for edges, human on trigger
Every one of those moves is real money.
Restock a final-sale item by mistake and you've put something back into inventory you were never supposed to take back. Double-credit an exchange chain (where the customer already got value earlier in the swap) and you've handed out money twice for the same garment. Issue credit on a made-to-order piece that was never eligible and that's cash out the door that does not come back.
When I sat down to build the returns decision layer, I had a moment of clarity that shaped everything after it. I did not want a language model deciding, by itself, where the money goes.
That is the whole fear, stated plainly. Not "AI is bad." Not "models hallucinate." Just: this thing is probabilistic, and accounting is not. I am not comfortable handing the keys to the till to a system that gives me a slightly different answer depending on how I phrase the question.
So I built the thing the opposite way. This is the core of AI decision making with business rules: rules run first. The AI only gets pulled in for the genuinely weird cases. And when anything is unclear, the system defaults to holding, not to crediting.
That single design choice has kept money safe through thousands of returns. Here's exactly how it works, and how to apply the same thinking to any decision in your business that touches cash.
Why a Rules Engine Beats an LLM for Money Decisions
The rules engine vs llm debate gets framed as a battle. It isn't. It's a division of labor, and once you see the division clearly, the choice for any given decision becomes obvious.
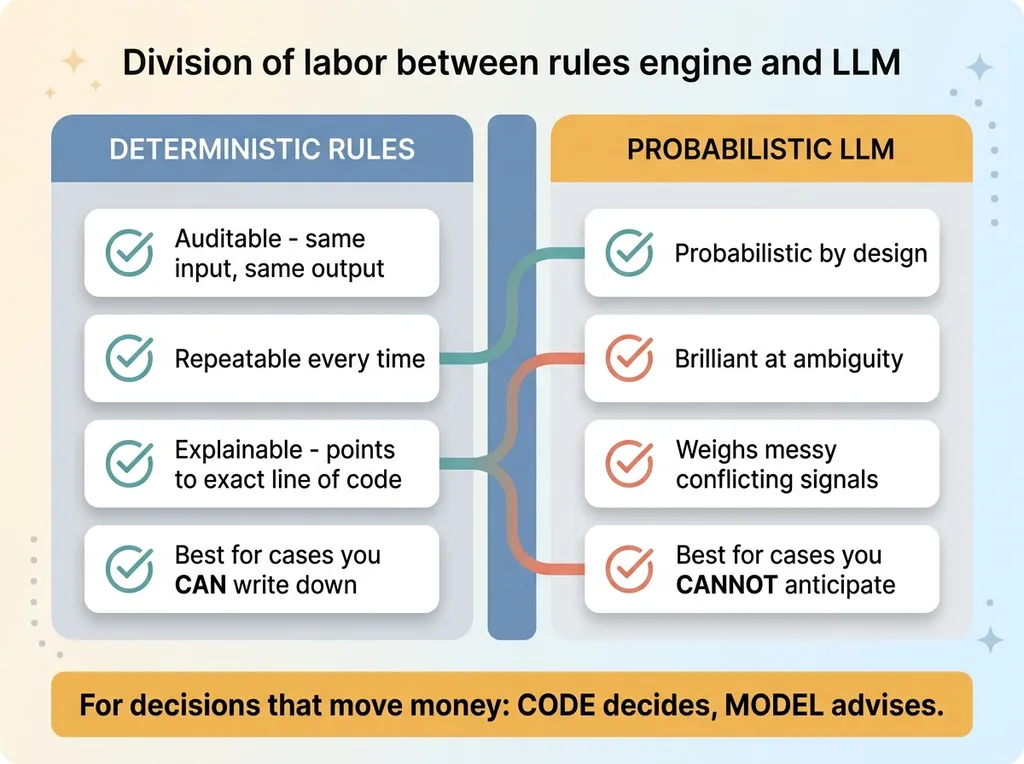 Rules engine vs LLM division of labor
Rules engine vs LLM division of labor
What rules are good at
A deterministic rule is auditable, repeatable, and explainable.
Give it the same input and it gives you the same output every single time. When someone asks "why did the system restock this instead of crediting it," I can point at the exact line of code that made the call. No interpretation. No "the model probably weighed these factors." A specific rule, a specific result.
That is what accounting demands. Money decisions need a paper trail you can defend to a CFO, a customer, or yourself at 11pm when something looks wrong. Rules give you that trail for free because the logic is the trail.
What LLMs are good at
An LLM is probabilistic by design. That's the entire point of it.
It's brilliant at ambiguity. Hand it a messy, never-before-seen situation with conflicting signals and it'll reason through it better than any rule you could write in advance. That flexibility is exactly what makes it useless as an accountant. The same trait that lets it handle the weird case is the trait that makes it unsafe for the routine one.
So the split writes itself. Rules handle the cases you can write down. LLMs handle the cases you can't anticipate.
I go deeper on this in let the model judge and let the code compute, but here's the snippet-able version: for any decision that moves money, the default owner should be code, not a model. The model can advise. Code decides.
The Common Cases Are Rules, Not AI
Here's what most people get wrong about their own operations. They assume the hard part is the edge cases, so they reach for the most powerful tool. But the volume isn't in the edge cases. The volume is in the same handful of patterns repeating over and over.
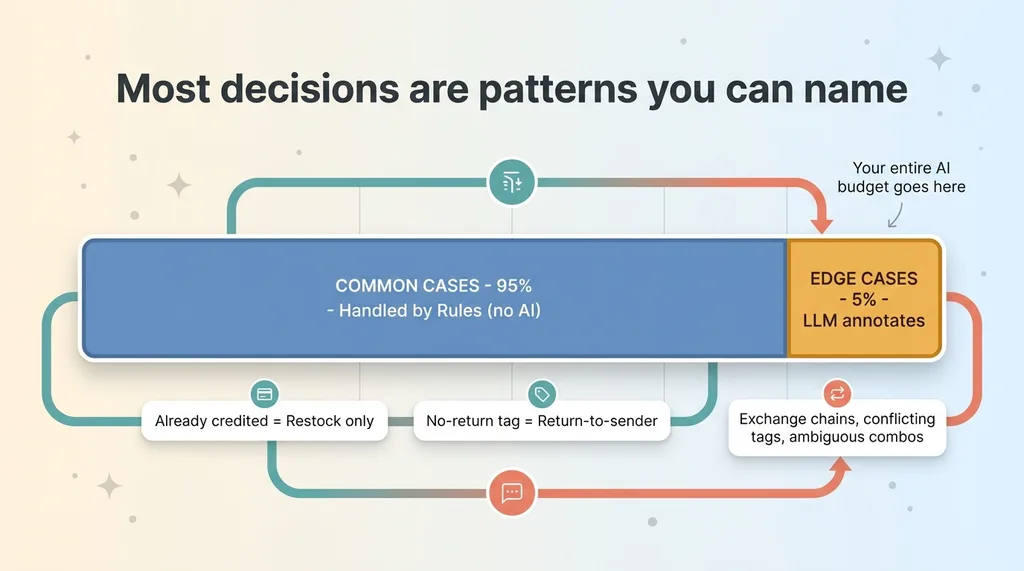 Common cases are rules, edge cases go to AI (volume distribution)
Common cases are rules, edge cases go to AI (volume distribution)
In my returns layer, I built a "Recommended" banner. It surfaces a suggested disposition to whoever's processing the return. Most of the time, no AI touches it at all. It's pure rules.
Already-credited means restock only
If the order was already credited earlier in its life, the only valid disposition is restock. Never credit again.
This is not a judgment call. It's a fact about the order's history. Crediting twice is just wrong, full stop. So the rule fires, the banner says restock, and no model gets consulted because there's nothing to reason about.
No-return tag means return-to-sender
If the item carries a no-return tag (final sale, certain made-to-order categories), the recommendation is return-to-sender. The garment goes back to the customer because we never agreed to take it back.
Again, no ambiguity. The tag is on the product. The rule reads the tag and recommends accordingly.
These two patterns cover the overwhelming majority of returns that come through. They're high-volume, they're unambiguous, and they should never, ever touch an LLM. Spending model calls on them would be slower, more expensive, and less reliable than a rule.
Encode the common cases once and your entire AI budget goes to the genuinely hard 5 percent. That's the discipline. Most decisions in any business are not edge cases. They're patterns you can name.
One more thing: the banner is a recommendation surfaced to a human. It does not auto-execute. Even on the dead-simple rule-based cases, a person makes the final move.
Where the Frontier LLM Is Actually Allowed In
So when does the model earn its keep? When the rules run out.
The edge cases worth a model's attention
There's a slice of returns the rule set can't fully reason about. Final-sale and made-to-order tags that interact in ways I didn't foresee. Exchange chains where credit may have already moved at some earlier step and it's not obvious from a single field. Ambiguous combinations of conditions the original logic never imagined.
This is llm edge case handling in its proper place. These are exactly the situations where writing another rule would be brittle and the model's ability to weigh messy, conflicting signals is genuinely valuable.
When the rules can't produce a confident recommendation, the frontier LLM gets pulled in. It looks at the full context, reasons through the ambiguity, and offers a read on what's probably going on.
It annotates, it doesn't decide
Here is the line I will not cross.
The model weighs in. It does not execute.
It writes an annotation on the banner. Something like "this looks like an exchange chain where credit may have already been issued at step one, recommend verifying before crediting." It flags the ambiguity. It surfaces the risk in plain language. Then it stops.
The human still acts. The model has thought out loud about a hard case, and a person reads that thinking, checks it, and decides.
This is the answer to the fear I opened with. The AI is allowed to reason on the cases that are too weird for rules. It is fenced off from pulling the trigger on the money. Every system I build works this way, and I wrote about why in every system I ship stops for a human. The model's job is to make the human faster and sharper, not to replace the human on the decisions that matter most.
Bias Toward Hold: The Default That Saves Money
If I could only keep one design choice from this whole system, it'd be this one.
 Bias toward hold: asymmetric cost of mistakes
Bias toward hold: asymmetric cost of mistakes
When anything is uncertain, the system defaults to hold. Not credit. Hold.
This is the deterministic ai fallback, and it works because of an asymmetry in cost. Holding a return for human review costs minutes. Someone looks at it, makes a call, moves on. Wrongly issuing store credit costs the full value of the item, and store credit is genuinely hard to claw back once it's in someone's account.
So the safe failure mode is to do nothing and wait. Never to act.
When the rules are confident, they recommend. When they're not, the fallback is hold. And the LLM is biased the exact same way: when it's unsure on an edge case, its annotation argues for holding rather than crediting. Uncertainty always resolves toward the cheap mistake, never the expensive one.
That's the principle I'd put in front of any CEO thinking about AI. Design your system so the expensive mistake is the one it's structurally prevented from making. Not "trained to avoid." Not "usually avoids." Structurally prevented, by the default itself.
Holding too often is annoying. Someone reviews a return that probably could've been auto-restocked. That's the cost of safety, and it's a rounding error next to the cost of crediting something you shouldn't have. I cover how I draw these hard boundaries in the kill-switches I build into every system. The bias toward hold is one of them.
How to Decide What Gets Fenced in Your Business
The returns example is specific to my brand, but the framework is portable. For any decision in your operation, run it through two questions.
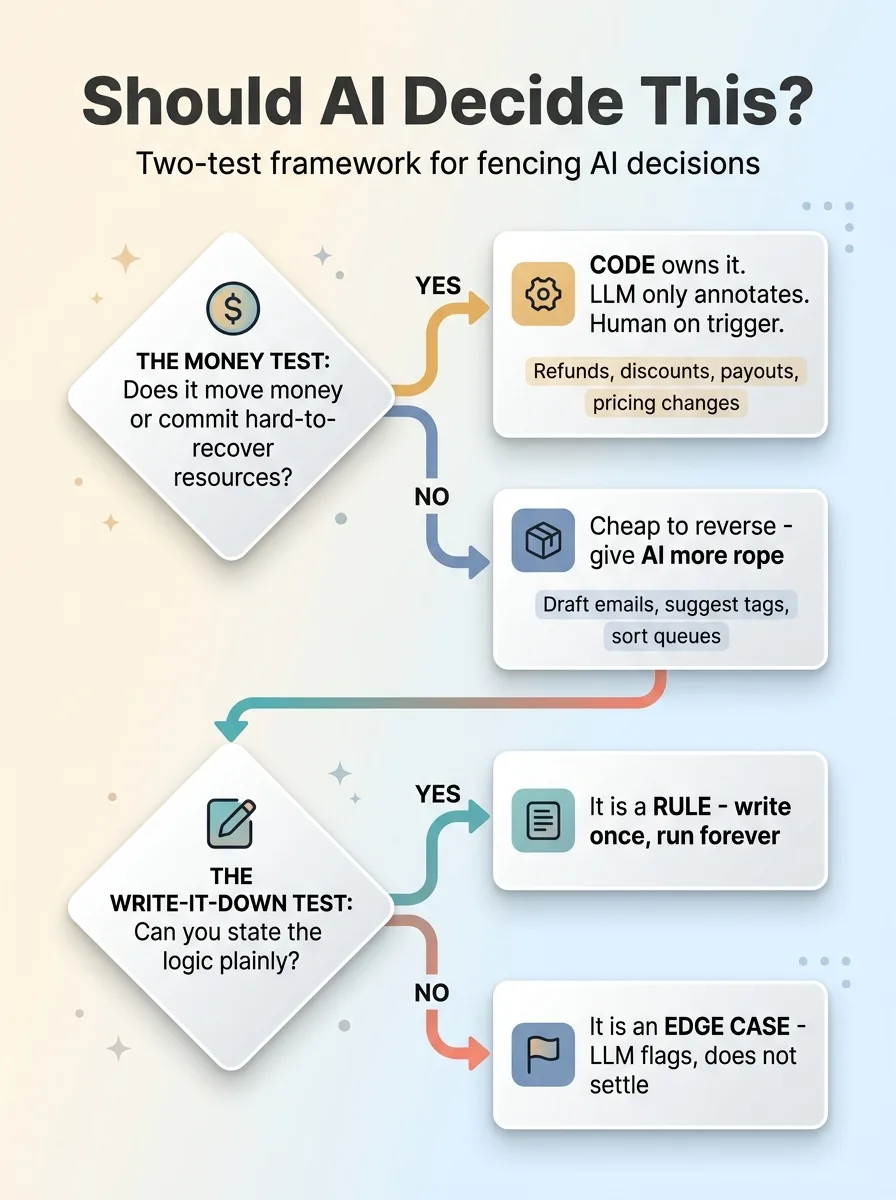 Two-test framework for fencing AI decisions
Two-test framework for fencing AI decisions
The money test
Does this decision move money or commit a resource that's hard to recover?
If yes, code owns the decision. The LLM only annotates. Refunds, discounts, credit approvals, vendor payouts, pricing changes, anything that spends, commits, or gives away value. These are the decisions where probabilistic gets you in trouble. Write the rules, let the model flag the weird ones, keep a human on the trigger.
If a decision is cheap to reverse (drafting an email, suggesting a tag, sorting a queue), you can give the AI a lot more rope. The stakes are low and speed matters more than precision.
The 'can I write the rule down' test
Can you state the logic plainly?
If yes, it's a rule, not an AI job. "Already credited means restock only" is a rule. "Orders over a certain value need manager approval" is a rule. Write it once, run it forever, get the same answer every time.
If you can't write it down, if the decision genuinely depends on weighing factors you can't enumerate in advance, that's an edge case. Hand it to the model to flag, not to settle.
Here's the honest part. This approach means more upfront work than just handing everything to a model and hoping. You have to actually map your decisions, write the rules, and define the edges. That's not a bug. That's the value. The discipline of figuring out which decisions are rules and which are edge cases is most of what keeps your money safe. The model is the easy part.
The Real Question Isn't Whether to Use AI, It's Where
The CEOs who get burned by AI aren't the ones who used it. They're the ones who didn't draw the line.
They handed a probabilistic system a decision that needed a deterministic one. They let a model pull the trigger on money when it should have only been allowed to comment. The failure wasn't the AI. It was the missing fence.
The real skill here isn't prompting. It's knowing which decisions a model is allowed to make and which it's only allowed to annotate. That judgment is the whole job.
I run 29 automation modes in production across my brand. And the ones that touch money are the most heavily fenced, not the most autonomous. The returns layer I described, the pricing engine on 564 products, anything that moves cash. Rules first, AI for the edges, human on the trigger, default to the cheap mistake. The autonomy lives in the low-stakes work. The money decisions are wrapped in constraints.
That's not me being cautious for its own sake. It's me having watched exactly which mistakes are expensive and structurally preventing them.
If you're trying to figure out where AI should actually act in your business and where it should be fenced off, that's the conversation I have with operators all day. Tell me where AI should be fenced in your business and we'll map it together.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call