AI Social Media Scheduling: A Beam Search for Instagram
How I built AI social media scheduling that plans a cohesive Instagram week with hard adjacency rules and beam search, not greedy slot-picking slop.
By Mike Hodgen
The Day My Scheduler Posted the Same Bodysuit Five Times
I run a DTC fashion brand out of San Diego. Everything is handmade, which means every piece I shoot is precious, and the feed is the storefront. So when I built my first AI social media scheduling system, I did what every engineer does on the first pass: I optimized.
I scored every asset by quality. Engagement potential, image clarity, product margin, freshness. Then I told the scheduler to fill each open slot with the highest-scoring asset available. Clean. Logical. Greedy.
The result was a disaster.
The same bodysuit ran five posts in a row. Same garment, same model, same flat-lay format, almost the same dominant color. Each individual post scored beautifully. The week, as a sequence, looked like a glitch. Anyone scrolling would assume something broke.
Here is the lesson I learned that day, and it is the whole point of this article: a scheduler that optimizes each slot in isolation has no sense of sequence. It picks the best thing five times because the best thing is, by definition, the best thing. It has no idea that a human experiences the feed in order, top to bottom, and that repetition reads as broken.
This is the exact fear most marketers have about AI scheduling. They think it produces repetitive slop. Identical posts, robotic captions, a feed that feels machine-generated.
That fear is correct about naive scheduling. It is completely wrong about the fix.
The fix is not abandoning AI. The fix is treating the week as a sequence problem, not a ranking problem. Once I did that, the same system that embarrassed me started producing weeks that looked deliberately art-directed. Let me show you how.
Why Greedy Picking Breaks Content Calendars
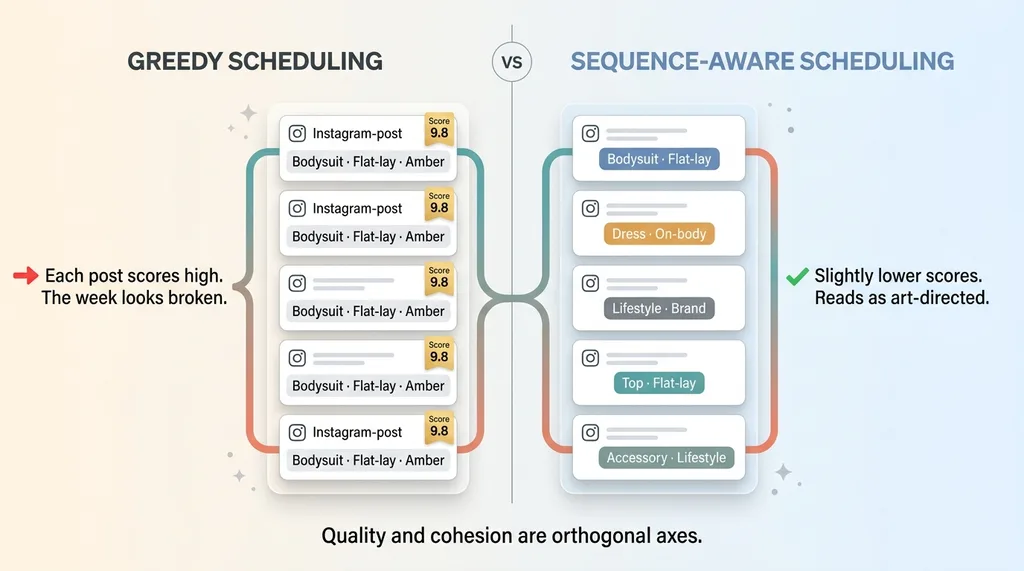 Greedy scheduling vs sequence-aware scheduling (the five-bodysuit problem)
Greedy scheduling vs sequence-aware scheduling (the five-bodysuit problem)
The scoring trap
Greedy scheduling is simple to explain. You rank every candidate asset by a quality score, then drop the top one into each open slot. Slot one gets your best asset. Slot two gets your second best. And so on.
The trap is hiding in plain sight. Your best three assets this week might all be the same SKU, shot the same way, in the same color story. They score high because they are genuinely good. But putting them next to each other looks terrible.
Quality and cohesion are not the same axis. They are orthogonal. A high score tells you a post is good on its own. It tells you nothing about whether it belongs next to the post before it.
Sequence is a different problem than quality
This is where most content calendar automation quietly fails. It treats a week as a bag of independent decisions when it is actually a sequence a person scrolls through in order.
Consider the real numbers from my brand. I post seven times a week. For each slot I have dozens of candidate assets, drawn from a library of hundreds of shot products. Even with modest numbers, the permutation space for ordering a week is enormous. You cannot eyeball the best ordering. No human can.
So you have two genuinely hard problems stacked on top of each other. First, which posts are good. Second, what order makes the feed read as intentional rather than chaotic. Greedy scheduling solves the first and ignores the second entirely.
The marketers who get burned by AI scheduling got sold a tool that only knew how to rank. Ranking is the easy half. The sequencing is where the value lives, and it is the half almost nobody builds.
The Cohesion Layer: 7 Hard Rules and a Set of Soft Penalties
Once I understood the problem was sequence, the fix became mechanical. Instagram grid cohesion is mostly mechanical, so I mechanized it. I built a cohesion layer that sits between the quality scores and the final schedule.
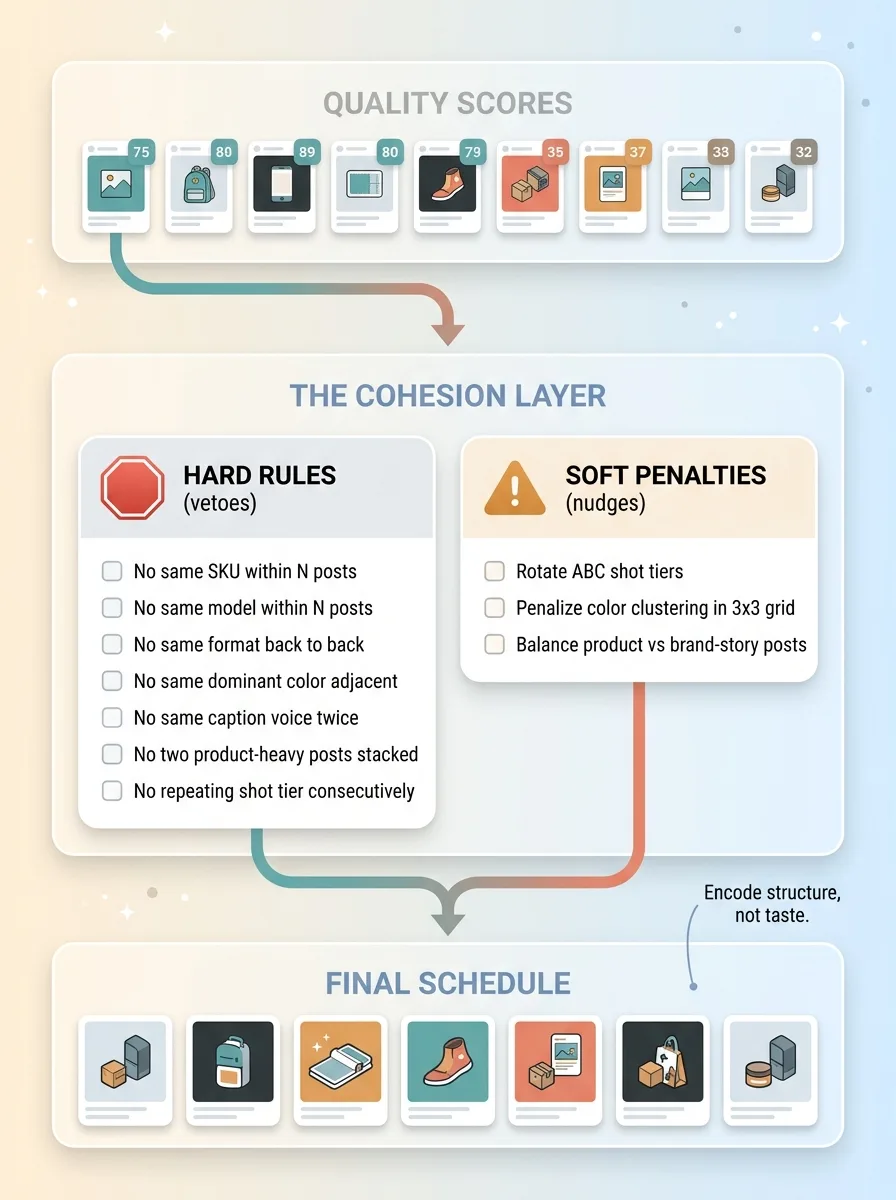 The Cohesion Layer: 7 hard rules and soft penalties
The Cohesion Layer: 7 hard rules and soft penalties
Hard adjacency rules (the non-negotiables)
Hard rules are vetoes. The system can never cross them, no matter how high an asset scores. I have seven:
- No same SKU within N posts
- No same model appearing within N posts
- No same format (flat-lay, on-body, lifestyle) back to back
- No same dominant color adjacent
- No same caption voice twice in a row
- No two product-heavy posts stacked without a breather
- No repeating the same shot tier in consecutive slots
These came from researching what makes a feed read as deliberate versus accidental. The five-bodysuit week violated four of these at once. If the cohesion layer had existed then, that schedule would have been illegal from the start.
Soft penalties (the taste nudges)
Hard rules are too blunt for everything. Some things you want to discourage, not ban outright. So I layered soft penalties on top. These are scored discouragements, not vetoes.
The system rotates ABC shot tiers so your hero shots are spaced out instead of clustered. It penalizes color clustering across the visible grid, the three-by-three block a visitor sees first. It nudges toward a balance between product posts and brand-story posts so the feed does not feel like a catalog.
A soft penalty does not kill a candidate. It just makes that ordering score worse, so the system prefers a better-spaced alternative if one exists.
Here is the design principle that matters. I did not encode taste. I encoded structure. The decision about whether a creative is beautiful, on-brand, worth shooting at all, stayed entirely human. Only the sequencing logic got mechanized.
This is the same split I use in every system I build: let the model judge and the code compute. Scoring quality is fuzzy judgment work. Enforcing "no same color adjacent" is deterministic math. Mixing those two responsibilities is exactly how you get systems nobody trusts.
Treating a Campaign Arc as a First-Class Object
Most schedulers think in single posts. Real brand marketing thinks in arcs.
A launch is not one post. It is a teaser, a build, a reveal, a follow-up. The story only works if the pieces land in order across days or weeks. A scheduler that treats every post as independent will happily scramble that order, because it does not know the order matters.
So I built the campaign arc as its own object the scheduler is aware of. On my brand this was a multi-week campaign arc running 21 days, with a defined beginning, build, and payoff. The scheduler knows which posts belong to the arc and weights them so the story unfolds in sequence across three weeks instead of scattering randomly into whatever slot scores highest.
Why does this matter so much? Picture the failure. A teaser post that runs after the reveal is worse than useless. It confuses the audience, it kills the payoff, and it makes the whole campaign look amateur. A greedy scheduler would absolutely do this if the teaser happened to score well in a later slot.
The arc object prevents it. The scheduler treats arc ordering as a constraint, the same way it treats the hard adjacency rules. Arc post three can never run before arc post two.
This is the difference between a calendar that fills slots and one that tells a story. Filling slots is what software does by default. Telling a story across three weeks is what a marketer does on a whiteboard, and it is exactly the part I wanted the system to protect rather than break.
Beam Search: How AI Plans the Whole Week at Once
Here is the core of the system, and it borrows directly from chess engines.
What beam search actually does
A chess engine does not pick the single best move and commit. It evaluates sequences of moves, keeps the most promising lines alive, and looks ahead. Beam search content planning applies that same idea to a content calendar.
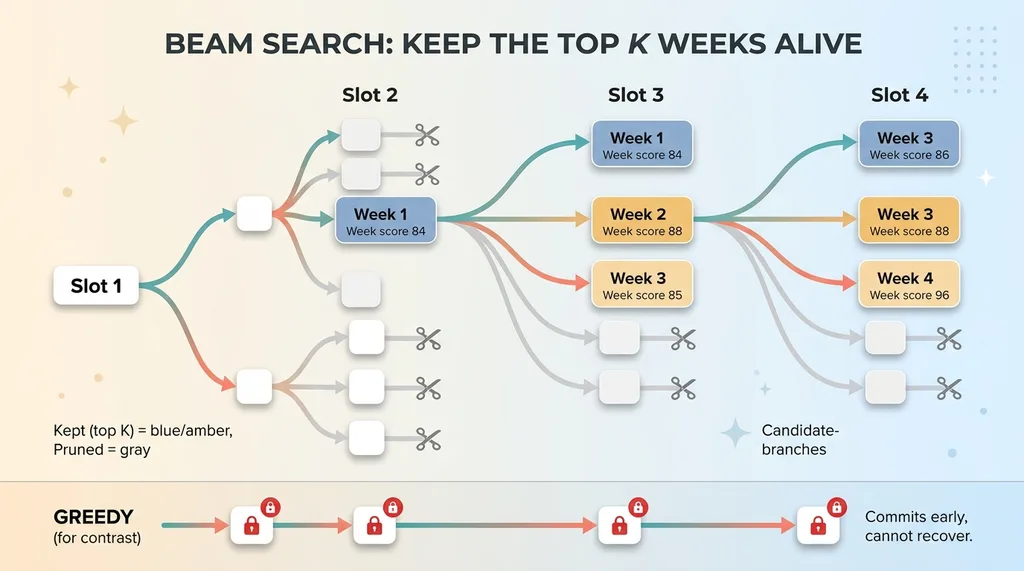 Beam search planning the whole week vs greedy commitment
Beam search planning the whole week vs greedy commitment
Instead of locking in slot one's best pick and marching forward, the system keeps the top K partial weeks alive at each step. It extends each candidate week with possible next posts, re-scores the whole sequence so far, then prunes back down to the top K strongest partial weeks. Repeat until the week is full.
K is small enough to stay fast and large enough to explore real alternatives. The system is essentially holding several plausible versions of your week in its hand at once and only discarding the weak ones.
Scoring a week, not a slot
The crucial shift is what gets scored. Greedy scores a single slot. Beam search scores an entire week as one object.
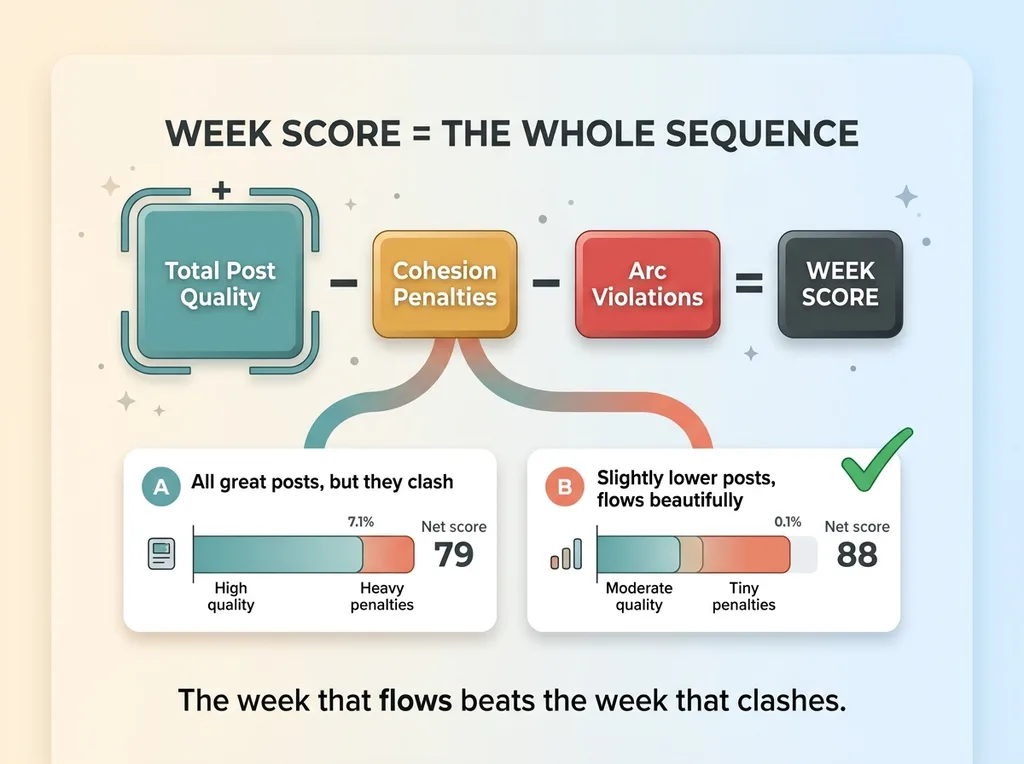 Scoring a week as one object (quality minus penalties)
Scoring a week as one object (quality minus penalties)
The week's score is total post quality, minus cohesion penalties, minus any arc violations. A week full of great posts that all clash gets a worse score than a week of slightly-less-perfect posts that flow beautifully. That is exactly the tradeoff a human art director makes intuitively, now made explicit and computable.
Contrast it directly with greedy. Greedy commits early and cannot recover. If slot one's pick poisons slots two through four because of color or SKU collisions, greedy is stuck. Beam search keeps options open. It can sacrifice a slightly better slot-one pick to win a far better overall week.
That is the entire reason the five-bodysuit problem disappeared. The system stopped asking "what is the best single post" and started asking "what is the best week."
The System Proposes Three Weeks, a Human Picks One
This is the part that resolves the trust question, so I want to be precise about it.
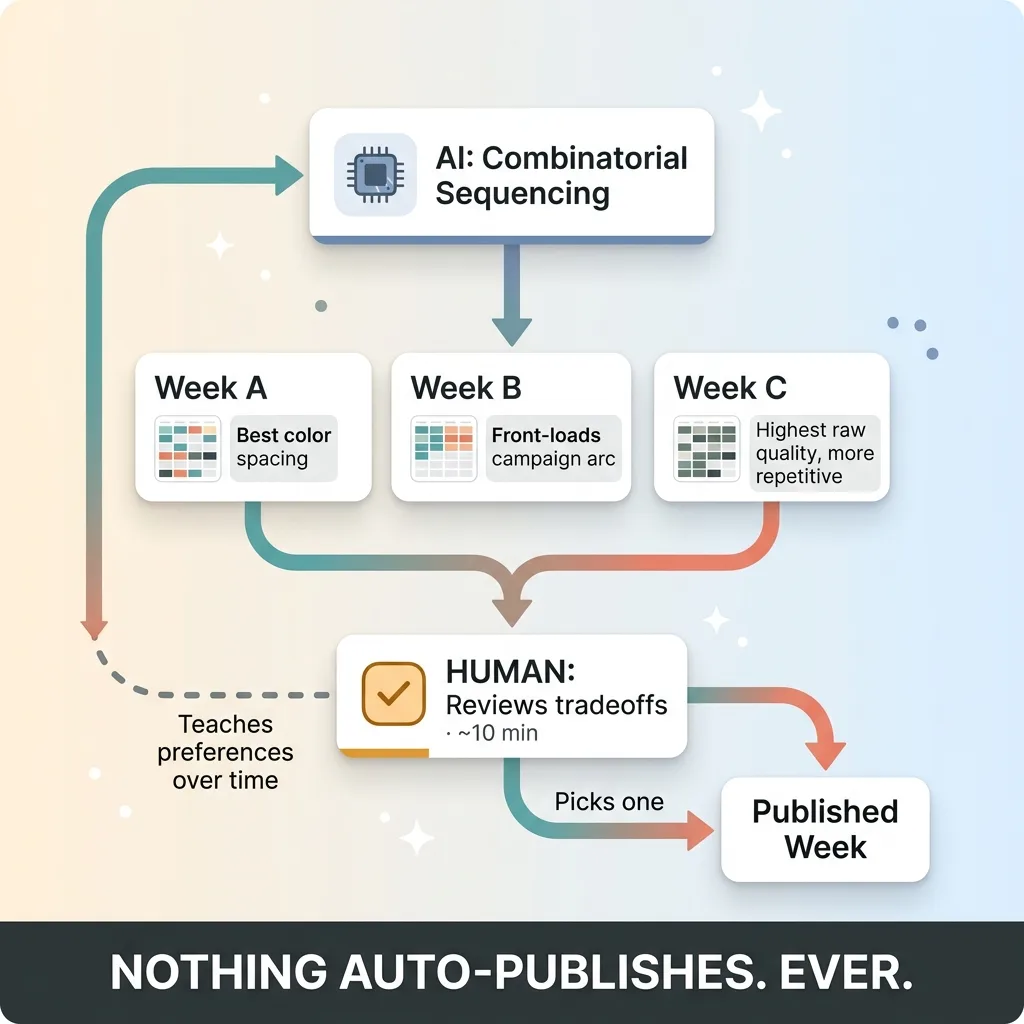 System proposes three weeks, human picks one (division of labor)
System proposes three weeks, human picks one (division of labor)
The scheduler does not pick a winner and publish it. It surfaces the top three candidate weeks and shows me the deltas between them. One week trades a slightly lower average post score for noticeably better color spacing across the grid. Another front-loads the campaign arc so the build starts earlier. A third keeps the highest raw quality but feels a touch more repetitive.
I read the three options, see the tradeoffs spelled out, pick one, and adjust if I want. The whole review takes about ten minutes. My pick also teaches the system over time which tradeoffs I tend to favor.
Nothing auto-publishes. Ever. This is true of every system I ship stops for a human, and content scheduling is no exception.
Here is the clean division of labor. The AI handles the combinatorial sequencing problem no human wants to do by hand, the one with too many permutations to eyeball. The human keeps full control of taste and the final say.
And I will be honest about the limitation, because pretending it does not exist is how vendors lose your trust. The system cannot tell you whether a creative is actually on-brand. It enforces variety and structure. It does not have taste. If you feed it ten mediocre assets, it will arrange them into a beautifully-spaced week of mediocre assets.
Taste is still a human input, scored by humans. The machine only protects the structure around it.
What This Means for Your Marketing Calendar
This is a fashion example, but the problem is not specific to fashion. Any brand posting regularly on a major social platform faces the same split: quality of individual posts versus cohesion of the sequence. The two pull against each other, and humans are bad at solving them simultaneously across dozens of candidates.
The win here is not replacing the marketer. I want to be clear about that, because the fear of repetitive AI slop is the fear of a marketer being cut out of the loop. That is the opposite of what this does.
The win is removing the tedious permutation work and the embarrassing repetition while keeping human judgment exactly where it belongs. Planning a week of posts used to eat a manual afternoon on my brand. Now it is a ten-minute review of three pre-scored options, each with the tradeoffs explained. The taste call stays mine. The math is done before I sit down.
This scheduler is one piece of a larger AI marketing scheduler approach across the brand, which connects to the rest of the broader AI playbook for DTC brands. The same logic that mechanized my product pipeline and pricing engine applies to the content calendar.
If your content calendar is eating hours every week, or producing posts that feel repetitive even though each one looked fine on its own, that is exactly the kind of problem worth mechanizing. Not to remove your judgment, but to stop wasting it on permutations. Tell me where your marketing is eating hours and we can look at whether this fits.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call