Free API + Cron: Auto-Updating a Live Sports App
How I built free API cron automation to keep a live-scoring app current: a free public API, a 10-minute cron, auto-grading, and manual override.
By Mike Hodgen
The problem: weeks of matches, zero budget for a feed
I built a live-scoring app for a month-long tournament. Dozens of matches, spread across weeks, with users making picks before each one and a leaderboard that had to stay accurate the whole time.
The data problem hit me before I wrote a line of feature code. I had two bad options.
Option one: type in scores by hand. Open the app, watch the match, update the score, mark it final, grade everyone's picks, recompute standings. Multiply that by dozens of matches over a month. That is not a side project, that is a part-time job. And the moment I missed the live window, the app felt dead.
Option two: buy a commercial sports data feed. Recurring cost, a contract, an integration to maintain. For a side project that was never going to make money, that is absurd. It is buying a freight truck to move one box.
Here is the assumption I want to kill, because it is the same one I hear from CEOs every week: people believe live data means an expensive vendor plus a human babysitting the output. Both of those feel mandatory. Neither one is.
What I actually did was wire a free api cron automation into the app and let it run itself for the entire tournament. Free public data source on one end. A scheduled job on the other. My own logic in the middle doing the work a vendor would charge me for.
This is a clean example of a pattern I use constantly across my paid work, so I want to walk through it concretely. No client here, just my own app and my own problem. By the end you will see why "free data, self-running" is a real option and where it stops being the right call.
The free public API: what a public data source actually gives you
Public sports APIs exist. They return live scores and final results, for free, with rate limits and no SLA. You sign up, get a key, and start pulling.
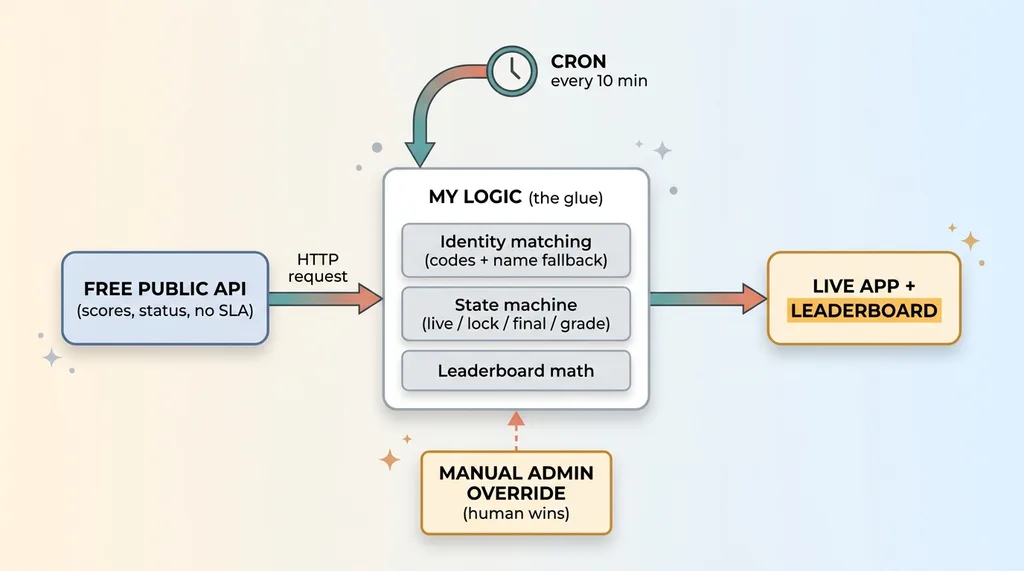 The reusable architecture pattern: free API + cron self-running stack
The reusable architecture pattern: free API + cron self-running stack
That is the whole foundation of this build. I did not pay anyone for the scores.
What's reliable
The core data is there and it is good enough. Live scores update within a few seconds of reality. Final results land reliably. Match status (scheduled, in progress, finished) is reported clearly. For the thing I actually needed, knowing the score and whether a match was done, the free feed delivered.
What's missing or messy
The tradeoffs are real and you have to design around them.
Data can lag a few seconds. Team naming is inconsistent between feeds and even within one. There is no SLA, so if the API has a bad day, that is your problem, not theirs. Rate limits cap how often you can ask.
None of that killed the project, because I never expected the API to do my thinking for me.
This is exactly the point I make in pay for primitives, build the logic. The API is a primitive. It hands me raw scores. The matching, the grading, the state transitions, the leaderboard math, that is all mine. The vendor sells you a finished integration at a premium because they bundle the logic in. But the logic is the part you can actually build, and it is the part that fits your specific app.
For a side project, or honestly for plenty of real products at modest volume, a free source plus your own glue beats a paid integration on every axis that matters: cost, control, and fit. You only outgrow it when volume or reliability requirements force the issue.
Matching live events to my fixtures: team codes with a name fallback
The hard part of this build was not pulling data. Pulling data is one HTTP request.
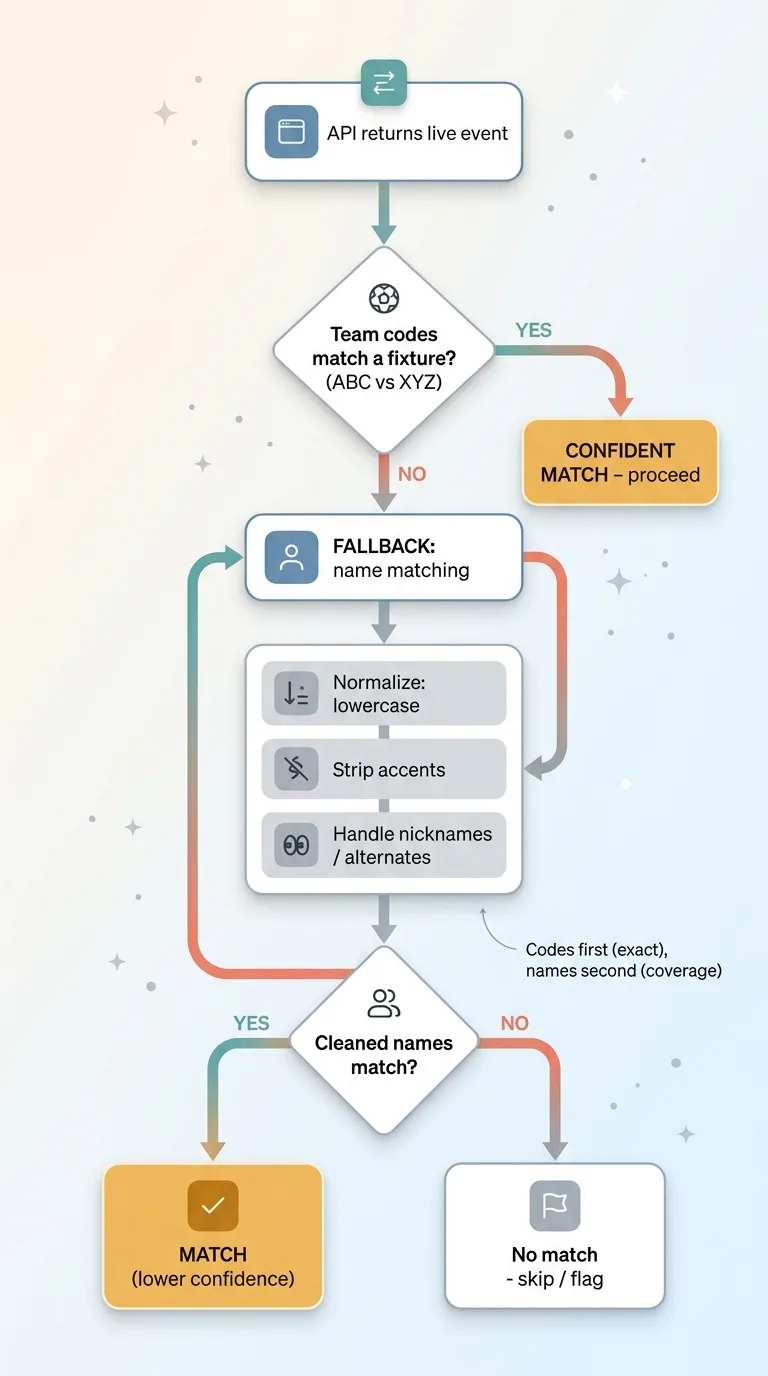 Two-layer identity resolution: team code primary, fuzzy name fallback
Two-layer identity resolution: team code primary, fuzzy name fallback
The hard part was identity resolution. The API sends me an event for a match happening in the real world. My app has a fixture, a record that says "these two teams play at this time, and these users picked it." I have to connect the API's event to the right fixture in my database, every time, without supervision.
Get this wrong and you grade the wrong match, lock the wrong picks, and corrupt the leaderboard. So I built it in two layers.
Primary match: team code
The primary key is standardized team codes, the three-letter abbreviations. When I create a fixture I store the codes. When the API returns an event, I read its codes and match them against my fixtures.
Codes are precise. There is no ambiguity in matching ABC versus XYZ. When the codes line up, I have a confident match and I move on.
Fallback: fuzzy name match
Codes are precise but not universal. Different feeds spell and abbreviate teams differently, and sometimes the codes simply do not line up. If I stopped at codes, those matches would silently fail.
So when the code match comes up empty, I fall back to matching on team names. But raw names are messy, so I normalize first: lowercase everything, strip accents, and handle known alternate names and nicknames. Then I compare the cleaned-up names.
The order matters. Codes go first because they are exact and rarely misfire. Names go second because they catch the gaps codes miss, but fuzzy matching can occasionally pair the wrong records, so you never want it as your primary signal.
Two layers gives me the best of both: precision when codes agree, coverage when they do not. That combination is what let the sync run for a month without me manually fixing mismatches.
What the sync actually does on each run
Every time the job fires, it walks a state machine. Each fixture is in one of a few states, and the sync moves it forward based on the matched event.
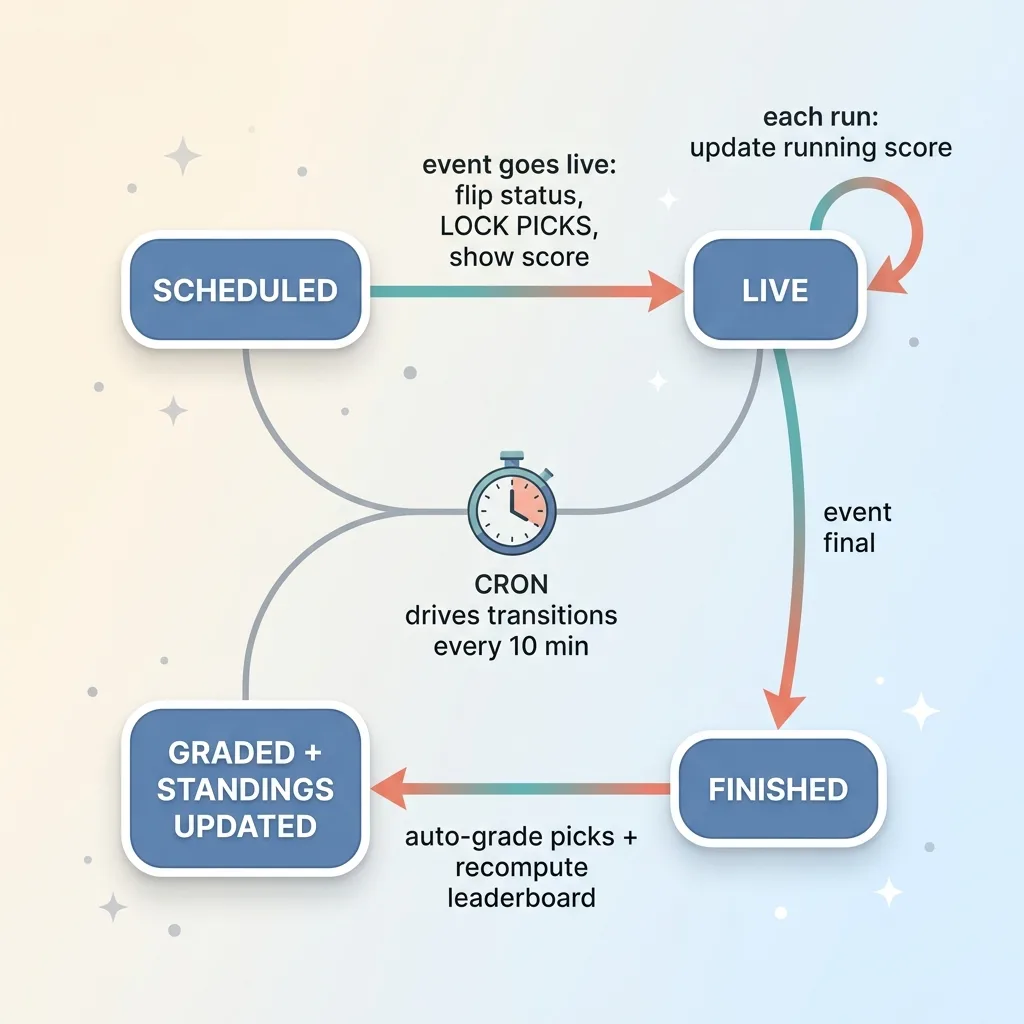 The fixture state machine the sync walks each run
The fixture state machine the sync walks each run
Flip to live and lock picks
When a fixture's matched event goes live, three things happen at once.
The match flips to live status. User picks lock, so nobody can change a guess after kickoff. And the app starts showing the running score.
Locking picks the instant the match starts is not optional. If picks stayed open after kickoff, someone could wait until a team scored and then "predict" it. The cron enforces the deadline far more reliably than I ever could by hand.
Update running scores
While a match is live, every run updates the running score. The sync fires, reads the current score from the API, writes it to the fixture, and the app reflects it.
This is what makes the app feel alive during a match. Users open it and see the score moving, not a stale number from an hour ago.
Auto-grade finals and recompute standings
When the event reaches final, the real work happens.
The sync marks the match as finished and auto-grades every user's pick against the actual result. Right picks score, wrong picks do not, according to the rules I encoded. Then it recomputes standings across every participant so the leaderboard is correct the moment the match ends.
No one waits for me to "post results." The result posts itself.
This is the entire point. The app runs itself for a month. I built the grading to run as part of the scheduled job, which I broke down in detail in auto-scoring on a cron. Picks lock on time, scores update during play, finals grade automatically, standings stay current. The combination of free data plus a state machine plus a schedule turned a month of manual labor into zero.
The 10-minute cron and the secret that guards it
The whole thing is driven by a vercel cron job that hits an internal endpoint every 10 minutes. That endpoint runs the sync I just described. That is the scheduled data sync in one sentence.
Why 10 minutes
Ten minutes is a deliberate compromise.
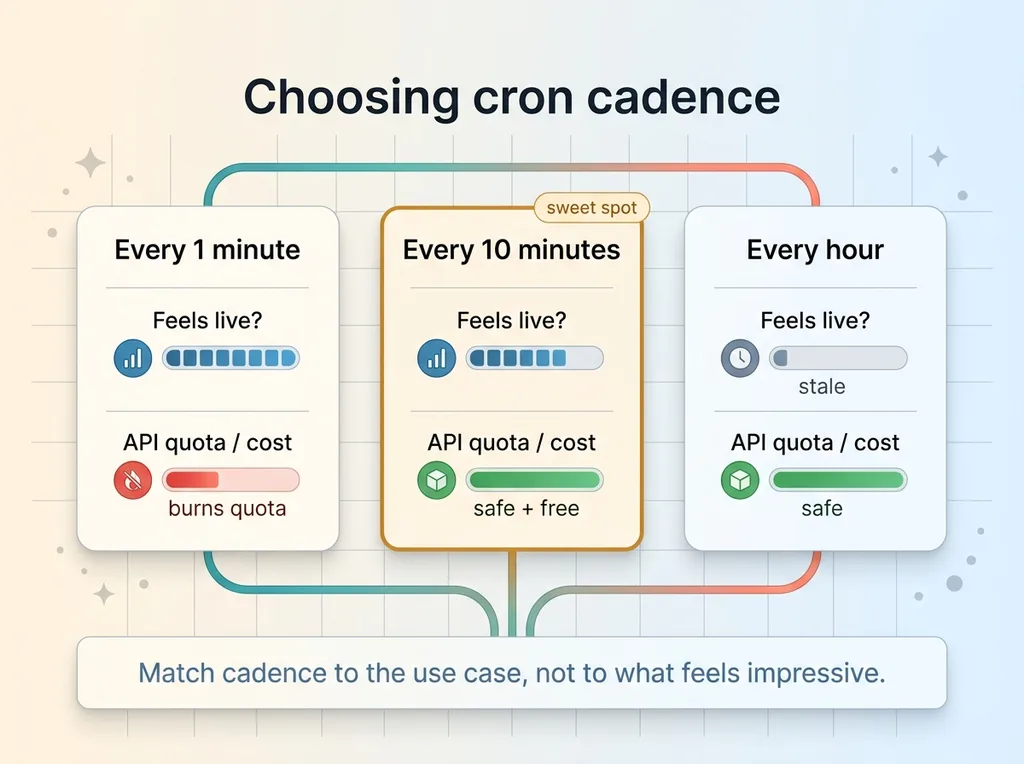 Choosing cron cadence: why 10 minutes
Choosing cron cadence: why 10 minutes
Frequent enough that live scores feel current and picks lock close to kickoff. A user is not staring at a score that is half an hour old. Infrequent enough that I stay well inside the free API's rate limits and pay nothing.
I could have run it every minute. It would have felt slightly more live and burned through my quota for no real benefit. Ten minutes hit the sweet spot for a pick-em app where the score moving every few minutes is plenty.
Match your cadence to what the use case actually needs, not to what feels impressive.
Securing the endpoint with a secret
Here is the part quick builds skip and live to regret.
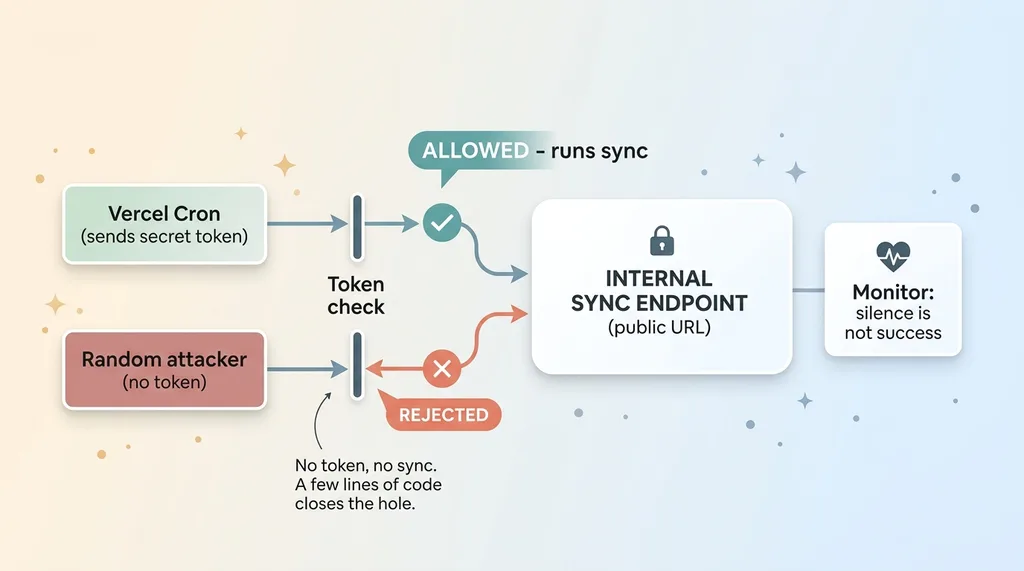 Securing the cron endpoint with a secret token
Securing the cron endpoint with a secret token
A cron endpoint is a public URL. Vercel calls it on a schedule, but so could anyone who finds it. Without protection, a stranger could trigger your sync repeatedly, hammer your free API quota into the rate limit, and break the app for everyone.
So I guard it with a secret token. The scheduler passes the token on every call. The endpoint checks for it and rejects anything that does not match. No token, no sync. It is a few lines of code and it closes the hole completely.
One more thing: silence is not success. If the cron quietly stops firing, your app looks fine until someone notices the scores froze. I want to know the job is actually running, which is why I monitor it the way I describe in automations that email me when nothing is wrong. A self-running system you cannot observe is a system you do not actually trust.
Manual admin override stays the authority
Automation is the default. It is not the dictator.
I kept a manual admin override that can correct any score, re-grade a match, or force a status change. And when the admin sets a value, the admin wins. The API does not get to overwrite a human correction.
This matters because public feeds get things wrong. A match gets postponed and the feed does not catch up. The matching logic hits an edge case I did not anticipate. A score comes through garbled. With no SLA, none of that is anyone's fault but mine to handle.
The override is how I handle it. When something breaks, I fix it directly, and the automation respects the fix instead of stomping on it.
This is not a sports thing. It is how I build everything. Every system I ship stops for a human where it counts. The machine does the boring, repetitive 99% so I do not have to, and a human keeps final authority over the 1% that matters.
So when a skeptical buyer asks "but what if the free data is wrong," this is the answer. You design for it. The human stays in the loop on purpose, not as an afterthought.
What this pattern means for your business
Strip away the sports and here is the reusable pattern.
A free or cheap data primitive. Your own matching logic to tie external records to your internal ones. A state machine that knows what to do at each stage. A scheduled sync that runs it on a cadence. A secured endpoint so randoms cannot trigger it. And a manual override so a human keeps authority.
That stack applies almost anywhere you have external data that should update on its own. Syncing competitor pricing. Monitoring market or competitor signals. Pulling shipment and tracking statuses. Refreshing any external dataset your team currently copies into a spreadsheet by hand.
The lesson for a time-starved CEO is simple. "Live data" and "self-running" do not require an expensive vendor and a person babysitting a tab all day. A lot of what you are paying for, or paying staff to do manually, is the glue, and the glue is buildable.
Now the honest limit. Free APIs have no SLA. For mission-critical flows where the data moves real money in real time, you may well pay for reliability, and that is the right call there. I am not telling you to run your billing system on a free feed. But for a huge number of real use cases, internal dashboards, picks, monitoring, refreshes, status checks, free-plus-glue is genuinely the better choice on cost and control.
If you are paying a vendor for data you could pull yourself, or you have someone manually updating something that should update itself, tell me what you're trying to automate. That is usually the fastest place to find money sitting on the table.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call